逻辑回归的介绍
线性回归
线性回归的基本思想是通过拟合最佳直线(也就是线性方程),来描述自变量和因变量之间的关系。这条直线被称为回归线,其目的是使得所有数据点到这条直线的垂直距离(即残差)的平方和最小。这个最小化过程通常称为最小二乘法。
学习二元一次方程时,我们通常将y视为因变量,x视为自变量,从而得到方程:
y=ax+b
其中, a 是斜率,表示自变量 x 对因变量 y 的影响程度; b 是截距,表示当 x = 0 时 y 的值。线性回归的目标就是找到最佳的参数 a 和 b,使得预测值 y '与实际值 y 之间的差异(通常是平方差)最小。
当我们只用一个x来预测y,就是一元线性回归,也就是在找一个直线来拟合数据。比如,我有一组数据画出来的散点图,横坐标代表广告投入金额,纵坐标代表销售量,线性回归就是要找一条直线,并且让这条直线尽可能地拟合图中的数据点。
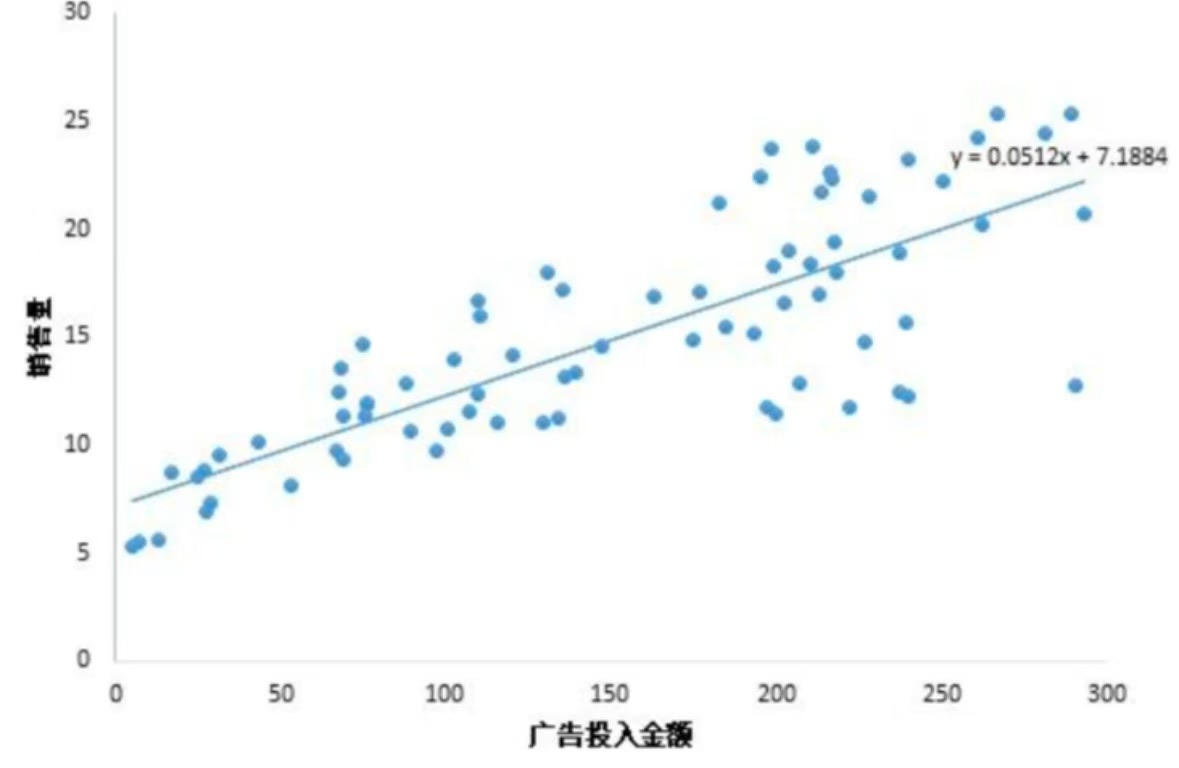
这里我们得到的拟合方程是y = 0.0512x + 7.1884,此时当我们获得一个新的广告投入金额后,我们就可以用这个方程预测出大概的销售量。
线性回归模型不仅可以用于简单的一元线性回归问题,还可以推广到多元线性回归,即有多个自变量的情况。二维空间的直线,转化为高维空间的平面。
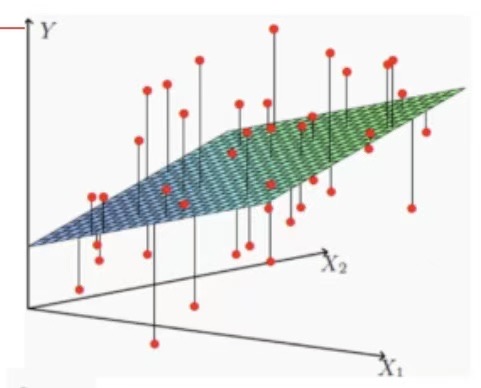
方程如下:
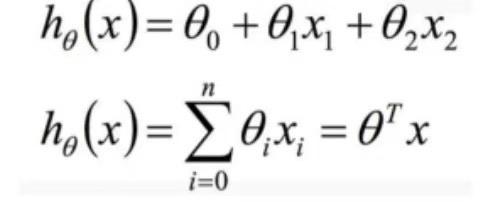
逻辑回归
逻辑回归的输入
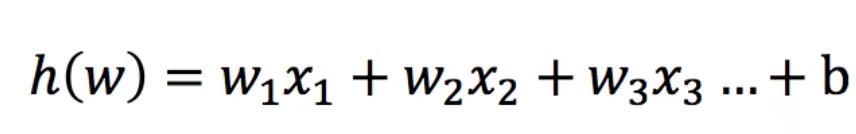
逻辑回归的输入就是一个线性回归的结果。
线性回归可以预测连续值,但是不能解决分类问题,我们需要根据预测的结果判定其属于正类还是负类。所以逻辑回归就是将线性回归的 ( − ∞ , + ∞ ) 的结果,通过sigmoid函数映射到(0,1)之间。
sigmoid函数
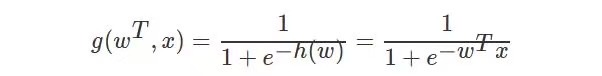
回归的结果输入到sigmoid函数当中
输出结果:0, 1区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。
损失函数
我们来看下图(下图中,设置阈值为0.6)

如何衡量逻辑回归的预测结果与真实结果的差异呢?
因此我们引入逻辑回归的损失,称之为对数似然损失,公式如下:
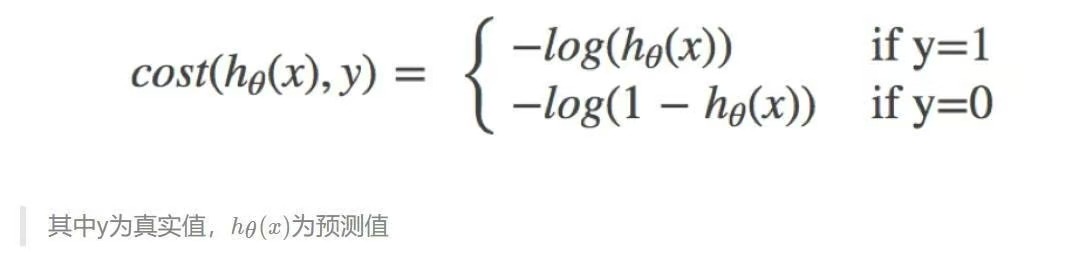
怎么理解单个的式子呢?这个要根据log的函数图像来理解
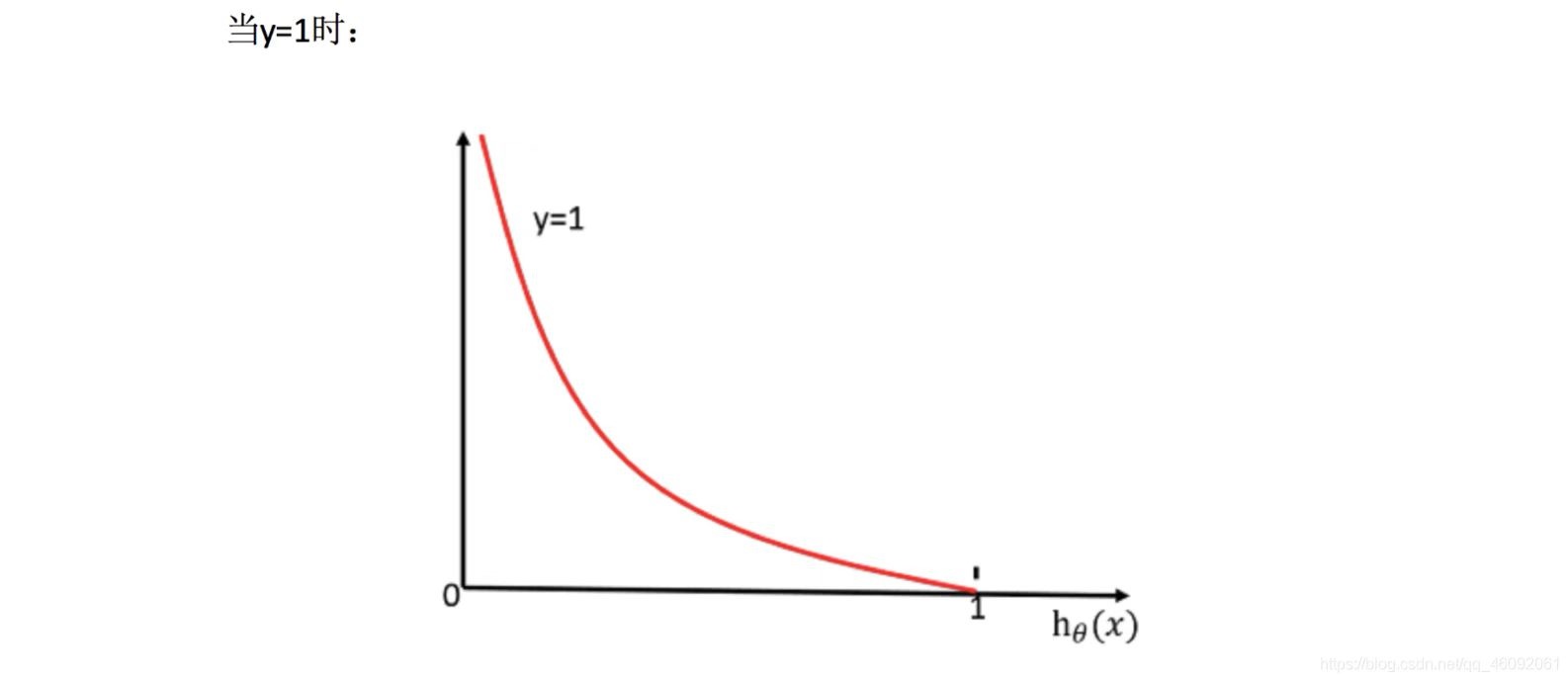
无论何时,我们都希望损失函数值,越小越好
分情况讨论,对应的损失函数值:
当y=1时,我们希望 h θ (x)值越大越好;
当y=0时,我们希望 h θ (x)值越小越好;
综合完整损失函数
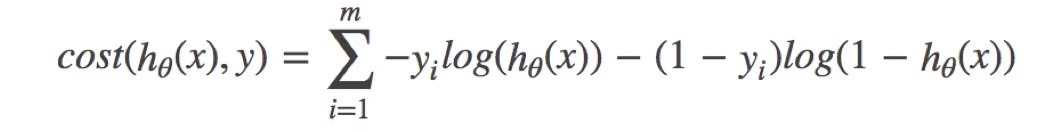
代入以上式子来计算:

我们已经知道,log( P ), P值越大,结果越小,所以我们可以对着这个损失的式子去分析
优化
使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
梯度下降法是逻辑回归模型中常用的优化算法之一,用于最小化损失函数,找到能够最小化损失函数的参数值 β 。
其基本思想是沿着损失函数的负梯度方向更新模型参数,逐步接近最优解。
梯度下降法的参数更新公式为:
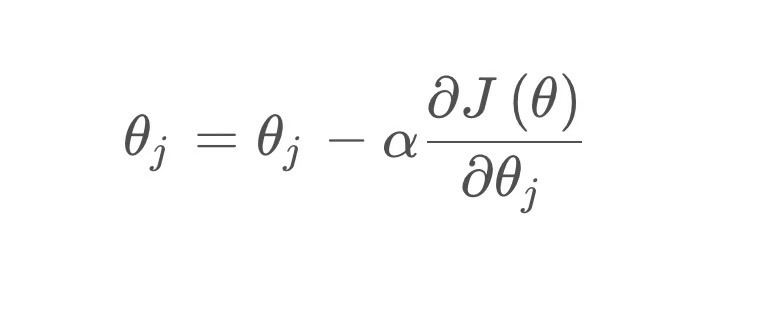
每次迭代时,模型的参数根据损失函数的梯度进行调整,直到损失函数收敛到最小值。
代码实现
python
import numpy as np
import matplotlib.pyplot as plt
# 加载数据集
data = np.genfromtxt(r'D:\testSet.txt') # 使用原始字符串避免路径问题
X = data[:, :-1]
y = data[:, -1]
# 添加偏置项
X = np.insert(X, 0, 1, axis=1)
# 初始化权重
def initialize_weights(dim):
return np.zeros(dim)
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 计算梯度
def compute_gradient(X, y, weights):
m = len(y)
h = sigmoid(np.dot(X, weights))
gradient = np.dot(X.T, (h - y)) / m
return gradient
def gradient_descent(X, y, alpha=0.1, iterations=10000):
weights = initialize_weights(X.shape[1])
for _ in range(iterations):
gradient = compute_gradient(X, y, weights)
weights -= alpha * gradient
return weights
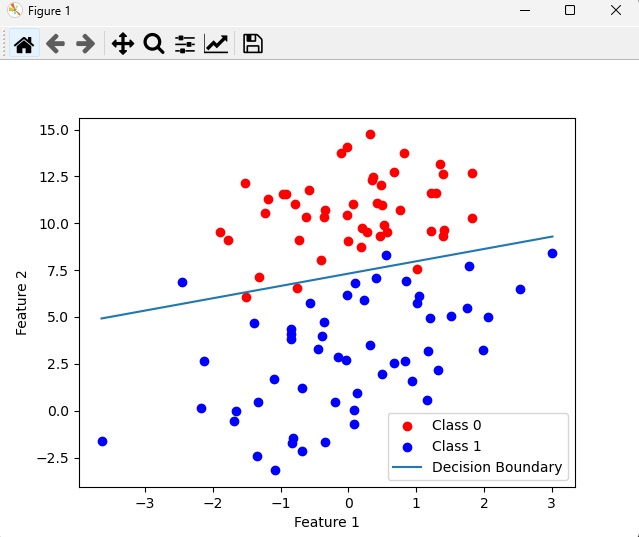
def plot_classification(X, y, weights):
plt.figure()
plt.scatter(X[y == 0, 1], X[y == 0, 2], color='red', label='Class 0')
plt.scatter(X[y == 1, 1], X[y == 1, 2], color='blue', label='Class 1')
x_values = np.array([np.min(X[:, 1]), np.max(X[:,1])])
y_values = - (weights[0] + weights[1] * x_values) / weights[2]
plt.plot(x_values, y_values, label='Decision Boundary')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
# 预测样本
def predict_sample(X_sample, weights):
X_sample = np.insert(X_sample, 0, 1) # 添加偏置项
prediction = sigmoid(np.dot(X_sample, weights))
return 1 if prediction >= 0.5 else 0
# 训练逻辑回归模型
weights = gradient_descent(X, y, alpha=0.01, iterations=100000)
plot_classification(X, y, weights)
# 给定一个新样本
new_label = [0, 1] # 示例新样本,包含两个特征,假设这与数据集特征一致
new_sample = np.array(new_label)
# 使用训练好的模型进行预测
predicted_class = predict_sample(new_sample, weights)
if predicted_class == 1:
print("新样本为类别1")
else:
print("新样本为类别0")运行结果