GC 的 STW 问题
GC,垃圾回收器,本质上是一种能够自动管理自己分配的内存的生命周期的内存分配器。这种方法被大多数流行编程语言采用,然而当你使用垃圾回收器时,你会失去对应用程序如何管理内存的控制。C# 允许在自动控制内存的基础之上局部对内存进行手动控制,但是自动控制仍然是主要的场景。
然而 GC 总是需要暂停程序的运行以遍历和识别存活的对象,从而删除无效对象以及进行维护操作(例如通过移动对象到更紧凑的内存区域以减少内存碎片,这个过程也叫做压缩)。GC 暂停整个程序的行为也叫做 STW(Stop-The-World)。这个暂停时间越长,对应用的影响越大。
长期以来,.NET 的 GC 都一直在朝着优化吞吐量性能和内存占用的方向不断优化,这对于 Web 应用以及跑在容器中的服务而言非常适合。而在客户端、游戏和金融领域,开发人员一直都需要格外注意代码中的分配问题,例如使用对象池、值类型以及非托管内存等等,避免产生大量的垃圾和各种 GC 难以处理的反模式,以此来减少 GC 的单次暂停时间。例如在游戏中,要做到 60fps,留给每一帧的时间只有 16ms,这其中如果 GC 单次暂停时间过长,用户就会观察到明显的掉帧。
Workstation GC?Server GC?DATAS GC?
.NET 一直以来都有两种 GC 模式 ------ Workstation GC 和 Server GC。
Workstation GC 是 .NET 最古老的 GC 模式,其目标之一是最小化内存占用,以适配资源有限的场景。在 Workstation GC 中,它只会利用你一个 CPU 核心,因此哪怕你有多核的计算资源,Workstation GC 也不会去使用它们来优化分配性能,虽然 Workstation GC 同样支持后台回收,但即使开启后台回收,Workstation GC 也之多只会用一个后台线程。这么一来其性能发挥就会受到不小的限制。面对大量分配和大量回收场景时 Workstation GC 则显得力不从心。不过,当你的应用很轻量并且不怎么分配内存的时候,Workstation GC 将是一个很适合的选择。
而之后诞生的 Server GC 则可以有效的利用多核计算资源,根据 CPU 核心数量来控制托管堆数量,大幅度提升了吞吐量。然而 Server GC 的缺点也很明显------内存占用大。另外,Server GC 虽然通过并发 GC 等方式将一部分工作移动到 STW 之外,从而使得 GC 和应用程序可以同时运行,让 STW 得到了不小的改进,然而 Server GC 的暂停时间仍然称不上优秀,虽然在 Web 服务等应用场景下表现得不错,然而在一些极端情况下则可能需要暂停上百毫秒。
为了进一步改善 Server GC 的综合表现,.NET 9 引入了新的 DATAS GC,试图在优化内存占用的同时提升暂停时间表现。这个 GC 通过引入各种启发算法自适应应用场景来最小化内存占用的同时,也改善了暂停时间。测试表明 DATAS GC 相比 Server GC 虽然牺牲了个位数百分比的吞吐量性能,却成功的减少了 70%~90% 的内存占用的同时,暂停时间也缩减到 Server GC 的 1/3。
然而,这仍然不能算是完美的解决方案。开发者们都是抱着既要又要还要的心理,需要的是一个既能做到大吞吐量,暂停时间又短,同时内存占用还小的 GC。
因此,.NET 全新的 GC ------ 在 .NET Runtime 核心成员几年的努力下诞生了!这就是接下来我要讲的 Satori GC。
Satori GC
为了让 GC 能够正确追踪对象,在不少语言中,编译器会给存储操作插入一个写屏障。在写屏障中 GC 会更新对象的引用从而确保每一个对象都能够正确被追踪。这么做的好处很明显,相比读操作而言,写操作更少,将屏障分担到每次的写操作里显然是一个更有效率的方法。然而这么做的坏处也很明显:当 GC 需要执行压缩操作时不得不暂停整个程序,避免代码访问到无效的内存地址。
而 JVM 上的一些低延时 GC 则放弃了写屏障,转而使用读屏障,在每次读取内存地址的时候通过插入屏障来确保始终拿到的是最新的内存地址,来避免无效地址访问。然而读操作在应用中非常频繁,这么做虽然能够使得 GC 执行压缩操作时不再需要暂停整个程序,却会不可避免地带来性能的损失。
GC 执行压缩操作虽然开销很大,但相对于释放操作而言只是少数,为了少数的操作能够并发执行拖慢所有的读操作显得有些得不偿失。另外,在 .NET 上,由于 .NET 支持内部指针和固定对象的内存地址,因此读屏障在 .NET 上实现较为困难,并且会带来吞吐量的严重下降,在许多场景下难以接受。
.NET 的新低延时高吞吐自适应 GC ------ Satori GC 仍然采用 Dijkstra 风格的写屏障设计,因此吞吐量性能仍然能够匹敌已有的 Server GC。
另外,Satori GC 采用了分代、增量并发回收设计,所有与堆大小成比例的主要 GC 阶段都会与应用程序线程并发执行,完全不需要暂停应用程序,除了压缩过程之外。不过,压缩仅仅是 GC 可以执行但不是必须执行的一个可选项。例如 C++/Rust 的内存分配器也不会进行压缩,但仍能正常运行;Go 的 GC 也不会进行压缩。
除了标准模式之外,Satori GC 还提供了低延时模式。在这个模式下 Satori GC 直接关闭了压缩功能,通过牺牲少量的内存占用来获取更低的延时。在某些情况下,因为垃圾回收发生得更快,或者压缩本身并没有带来太多实际收益,内存占用反而会变得更小。例如在一些 Web 场景,大量对象只存活在单次请求期间,然后很快就会被清除。既然这些对象很快都会变成垃圾,那为什么要进行压缩呢?
与 Go 的彻底不进行压缩的 GC 不同,Satori GC 可以在运行时动态切换压缩的开关状态,以适应不同的应用场景。想要开启低延时模式,只需要执行 GCSettings.LatencyMode = GCLatencyMode.LowLatency 即可。在需要极低延时的场景(例如高帧率游戏或金融实时交易系统)中,这一设置可以有效减少 GC 暂停时间。
Satori GC 还允许开发者根据需要关闭 Gen 0:毕竟不是所有的场景/应用都能从 Gen 0 中获益。当应用程序并不怎么用到 Gen 0 时,为了支持 Gen 0 在写屏障中做的额外操作反而会拖慢性能。目前可以通过设置环境变量 DOTNET_gcGen0=0 来关闭 Gen 0,不过在 Satori GC 计划中,将会实现根据实际应用场景自动决策 Gen 0 的开启与关闭。
性能测试
说了这么多,新的 Satori GC 到底疗效如何呢?让我们摆出来性能测试来看看。
首先要说的是,测试前需要设置 <TieredCompilation>false</TieredCompilation> 关闭分层编译,因为 tier-0 的未优化代码会影响对象的生命周期,从而影响 GC 行为。
测试场景 1
Unity 有一个 GC 压力测试,游戏在每次更新都需要渲染出一帧画面,而这个测试则模拟了游戏在每帧中分配大量的数据,但是却不渲染任何的内容,从而通过单帧时间来反映 GC 的实际暂停。
代码如下:
cs
class Program
{
const int kLinkedListSize = 1000;
const int kNumLinkedLists = 10000;
const int kNumLinkedListsToChangeEachFrame = 10;
private const int kNumFrames = 100000;
private static Random r = new Random();
class ReferenceContainer
{
public ReferenceContainer rf;
}
static ReferenceContainer MakeLinkedList()
{
ReferenceContainer rf = null;
for (int i = 0; i < kLinkedListSize; i++)
{
ReferenceContainer link = new ReferenceContainer();
link.rf = rf;
rf = link;
}
return rf;
}
static ReferenceContainer[] refs = new ReferenceContainer[kNumLinkedLists];
static void UpdateLinkedLists(int numUpdated)
{
for (int i = 0; i < numUpdated; i++)
{
refs[r.Next(kNumLinkedLists)] = MakeLinkedList();
}
}
static void Main(string[] args)
{
GCSettings.LatencyMode = GCLatencyMode.LowLatency;
float maxMs = 0;
UpdateLinkedLists(kNumLinkedLists);
Stopwatch totalStopWatch = new Stopwatch();
Stopwatch frameStopWatch = new Stopwatch();
totalStopWatch.Start();
for (int i = 0; i < kNumFrames; i++)
{
frameStopWatch.Start();
UpdateLinkedLists(kNumLinkedListsToChangeEachFrame);
frameStopWatch.Stop();
if (frameStopWatch.ElapsedMilliseconds > maxMs)
maxMs = frameStopWatch.ElapsedMilliseconds;
frameStopWatch.Reset();
}
totalStopWatch.Stop();
Console.WriteLine($"Max Frame: {maxMs}, Avg Frame: {(float)totalStopWatch.ElapsedMilliseconds/kNumFrames}");
}
}测试结果如下:
| GC | 最大帧时间 | 平均帧时间 | 峰值内存占用 |
|---|---|---|---|
| Server GC | 323 ms | 0.049ms | 5071.906 MB |
| DATAS GC | 139 ms | 0.146ms | 1959.301 MB |
| Workstation GC | 23 ms | 0.563 ms | 563.363 MB |
| Satori GC | 26 ms | 0.061 ms | 1449.582 MB |
| Satori GC (低延时) | 8 ms | 0.050 ms | 1540.891 MB |
| Satori GC (低延时,关 Gen 0) | 3 ms | 0.042 ms | 1566.848 MB |
可以看到 Satori GC 在拥有 Server GC 的吞吐量性能同时(平均帧时间),还拥有着优秀的最大暂停时间(最大帧时间)。
测试场景 2
在这个测试中,代码中将产生大量的 Gen 2 -> Gen 0 的反向引用让 GC 变得非常繁忙,然后通过大量分配生命周期很短的临时对象触发大量的 Gen 0 GC。
cs
using System.Diagnostics;
using System.Runtime;
using System.Runtime.CompilerServices;
object[] a = new object[100_000_000];
var sw = Stopwatch.StartNew();
var sw2 = Stopwatch.StartNew();
var count = GC.CollectionCount(0) + GC.CollectionCount(1) + GC.CollectionCount(2);
for (var iter = 0; ; iter++)
{
// Create a lot of Gen2 -> Gen0 references to keep the GC busy
object o = new object();
for (int i = 0; i < a.Length; i++)
{
a[i] = o;
}
sw.Restart();
// Use the object to keep it alive
Use(a, o);
// Create a lot of short lived objects to trigger Gen0 GC
for (int i = 0; i < 1000; i++)
{
GC.KeepAlive(new string('a', 10000));
}
var newCount = GC.CollectionCount(0) + GC.CollectionCount(1) + GC.CollectionCount(2);
if (newCount != count)
{
Console.WriteLine($"Gen0: {GC.CollectionCount(0)}, Gen1: {GC.CollectionCount(1)}, Gen2: {GC.CollectionCount(2)}, Pause on Gen0: {sw.ElapsedMilliseconds}ms, Throughput: {(iter + 1) / sw2.Elapsed.TotalSeconds} iters/sec, Max Working Set: {Process.GetCurrentProcess().PeakWorkingSet64 / 1048576.0} MB");
count = newCount;
iter = -1;
sw2.Restart();
}
}
[MethodImpl(MethodImplOptions.NoInlining)]
static void Use(object[] arr, object obj) { }由于这个测试主要就是测试 Gen 0 的回收性能,因此测试结果中将不包含关闭 Gen 0 的情况。
| GC | 单次暂停 | 吞吐量 | 峰值内存占用 |
|---|---|---|---|
| Server GC | 59 ms | 7.485 iter/s | 1286.898 MB |
| DATAS GC | 60 ms | 6.362 iter/s | 859.722 MB |
| Workstation GC | 1081 ms | 0.804 iter/s | 805.453 MB |
| Satori GC | 0 ms | 4.448 iter/s | 801.441 MB |
| Satori GC (低延时) | 0 ms | 4.480 iter/s | 804.761 MB |
这个测试中 Satori GC 表现得非常亮眼:拥有不错的吞吐量性能的同时,做到了亚毫秒级别的暂停时间:可以说在这个测试中 Satori GC 压根就没有暂停过我们的应用程序!
测试场景 3
这次我们使用 BinaryTree Benchmark 进行测试,这个测试由于会短时间大量分配对象,因此对于 GC 而言是一项压力很大的测试。
cs
using System.Diagnostics;
using System.Diagnostics.Tracing;
using System.Runtime;
using System.Runtime.CompilerServices;
using Microsoft.Diagnostics.NETCore.Client;
using Microsoft.Diagnostics.Tracing;
using Microsoft.Diagnostics.Tracing.Analysis;
using Microsoft.Diagnostics.Tracing.Parsers;
class Program
{
[MethodImpl(MethodImplOptions.AggressiveOptimization)]
static void Main()
{
var pauses = new List<double>();
var client = new DiagnosticsClient(Environment.ProcessId);
EventPipeSession eventPipeSession = client.StartEventPipeSession([new("Microsoft-Windows-DotNETRuntime",
EventLevel.Informational, (long)ClrTraceEventParser.Keywords.GC)], false);
var source = new EventPipeEventSource(eventPipeSession.EventStream);
source.NeedLoadedDotNetRuntimes();
source.AddCallbackOnProcessStart(proc =>
{
proc.AddCallbackOnDotNetRuntimeLoad(runtime =>
{
runtime.GCEnd += (p, gc) =>
{
if (p.ProcessID == Environment.ProcessId)
{
pauses.Add(gc.PauseDurationMSec);
}
};
});
});
GC.Collect(GC.MaxGeneration, GCCollectionMode.Aggressive, true, true);
GC.WaitForPendingFinalizers();
GC.WaitForFullGCComplete();
Thread.Sleep(5000);
new Thread(() => source.Process()).Start();
pauses.Clear();
Test(22);
source.StopProcessing();
Console.WriteLine($"Max GC Pause: {pauses.Max()}ms");
Console.WriteLine($"Average GC Pause: {pauses.Average()}ms");
pauses.Sort();
Console.WriteLine($"P99.9 GC Pause: {pauses.Take((int)(pauses.Count * 0.999)).Max()}ms");
Console.WriteLine($"P99 GC Pause: {pauses.Take((int)(pauses.Count * 0.99)).Max()}ms");
Console.WriteLine($"P95 GC Pause: {pauses.Take((int)(pauses.Count * 0.95)).Max()}ms");
Console.WriteLine($"P90 GC Pause: {pauses.Take((int)(pauses.Count * 0.9)).Max()}ms");
Console.WriteLine($"P80 GC Pause: {pauses.Take((int)(pauses.Count * 0.8)).Max()}ms");
using (var process = Process.GetCurrentProcess())
{
Console.WriteLine($"Peak WorkingSet: {process.PeakWorkingSet64} bytes");
}
}
static void Test(int size)
{
var bt = new BinaryTrees.Benchmarks();
var sw = Stopwatch.StartNew();
bt.ClassBinaryTree(size);
Console.WriteLine($"Elapsed: {sw.Elapsed.TotalMilliseconds}ms");
}
}
public class BinaryTrees
{
class ClassTreeNode
{
class Next { public required ClassTreeNode left, right; }
readonly Next? next;
ClassTreeNode(ClassTreeNode left, ClassTreeNode right) =>
next = new Next { left = left, right = right };
public ClassTreeNode() { }
internal static ClassTreeNode Create(int d)
{
return d == 1 ? new ClassTreeNode(new ClassTreeNode(), new ClassTreeNode())
: new ClassTreeNode(Create(d - 1), Create(d - 1));
}
internal int Check()
{
int c = 1;
var current = next;
while (current != null)
{
c += current.right.Check() + 1;
current = current.left.next;
}
return c;
}
}
public class Benchmarks
{
const int MinDepth = 4;
public int ClassBinaryTree(int maxDepth)
{
var longLivedTree = ClassTreeNode.Create(maxDepth);
var nResults = (maxDepth - MinDepth) / 2 + 1;
for (int i = 0; i < nResults; i++)
{
var depth = i * 2 + MinDepth;
var n = 1 << maxDepth - depth + MinDepth;
var check = 0;
for (int j = 0; j < n; j++)
{
check += ClassTreeNode.Create(depth).Check();
}
}
return longLivedTree.Check();
}
}
}这一次我们使用 Microsoft.Diagnostics.NETCore.Client 来精准的跟踪每一次 GC 的暂停时间。
测试结果如下:
| 性能指标 | Workstation GC | Server GC | DATAS GC | Satori GC | Satori GC (低延时) | Satori GC (关 Gen 0) |
|---|---|---|---|---|---|---|
| 执行所要时间 (ms) | 63,611.3954 | 22,645.3525 | 24,881.6114 | 41,515.6333 | 40,642.3008 | 13528.3383 |
| 峰值内存占用 (bytes) | 1,442,217,984 | 4,314,828,800 | 2,076,291,072 | 1,734,955,008 | 1,537,855,488 | 1,541,136,384 |
| 最大暂停时间 (ms) | 48.9107 | 259.9675 | 197.7212 | 6.5239 | 4.0979 | 1.2347 |
| 平均暂停时间 (ms) | 6.117282383 | 12.00785067 | 3.304014164 | 0.673435691 | 0.437758553 | 0.1391 |
| P99.9 暂停时间 (ms) | 46.8537 | 243.2844 | 172.3259 | 5.8535 | 3.6835 | 0.9887 |
| P99 暂停时间 (ms) | 44.0532 | 207.3627 | 57.4681 | 5.2661 | 3.2012 | 0.5814 |
| P95 暂停时间 (ms) | 39.4903 | 48.7269 | 8.92 | 3.0054 | 1.3854 | 0.3536 |
| P90 暂停时间 (ms) | 23.1327 | 21.4588 | 2.8013 | 1.7859 | 0.9204 | 0.2681 |
| P80 暂停时间 (ms) | 8.3317 | 4.7577 | 1.7581 | 0.8009 | 0.6006 | 0.1942 |
这一次 Satori GC 的标准模式和低延时模式都做到了非常低的延时,而关闭 Gen 0 后 Satori GC 更是直接卫冕 GC 之王,不仅执行性能上跑过了 Server GC,同时还做到了接近 Workstation GC 级别的内存占用,并且还做到了亚毫秒级别的最大 STW 时间!
测试场景 4
这个场景来自社区贡献的 GC 测试:https://github.com/alexyakunin/GCBurn
这个测试包含三个不同的重分配的测试项目,模拟三种场景:
- Cache Server:使用一半的内存(大约 16G),分配大约 1.86 亿个对象
- Stateless Server:一个无状态 Web Server
- Worker Server:一个有状态的 Worker 始终占据 20% 内存(大约 6G),分配大概 7400 万个对象
测试结果由其他社区成员提供。
首先看分配速率:
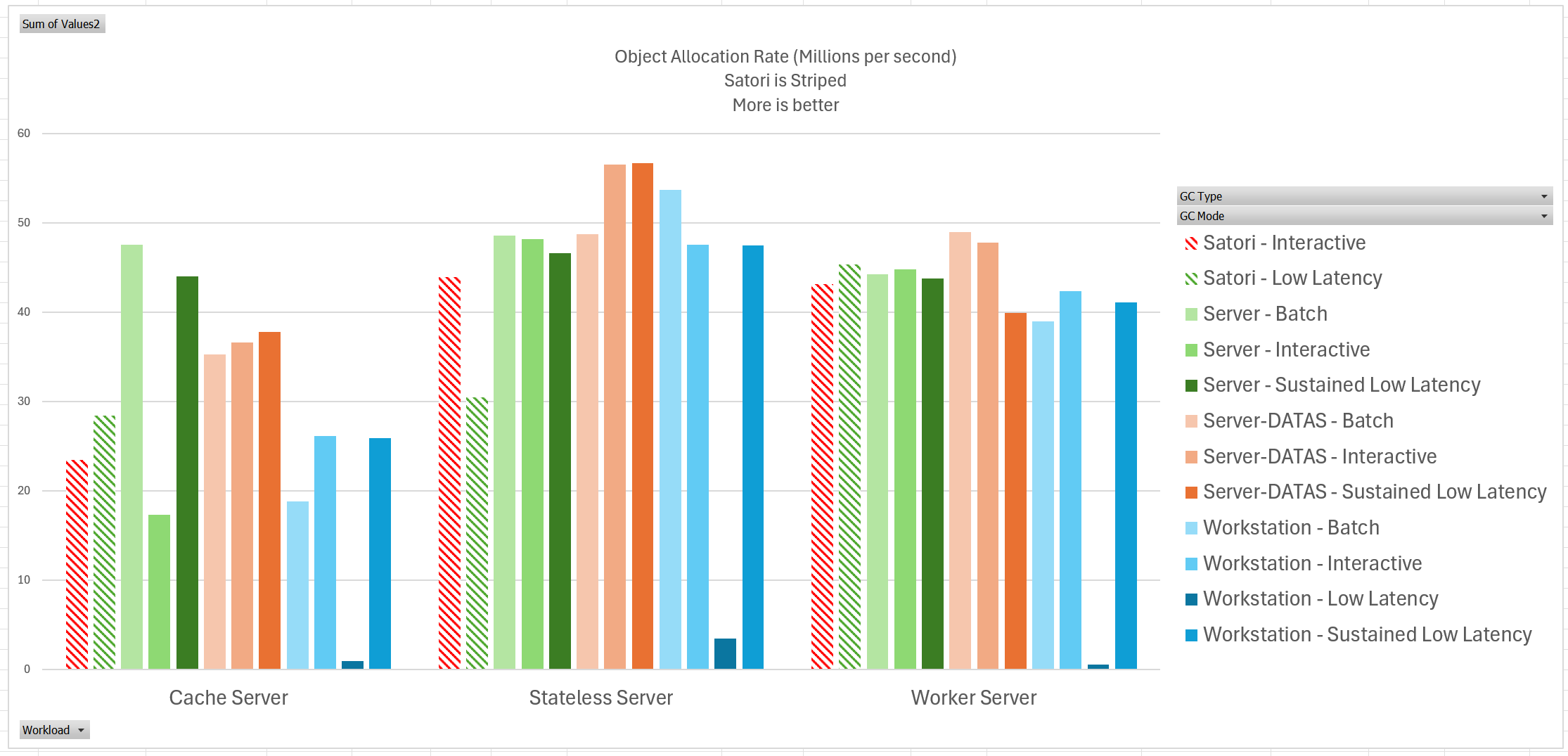
Server GC 是针对吞吐量进行大量优化的,因此做到最高的吞吐量性能并不意外。Satori GC 在 Cache Server 场景有所落后,但是现实中并不会有在一秒内分配超过 2 千万个对象的场景,因此这个性能水平并不会造成实际的性能瓶颈。
然后看暂停时间:
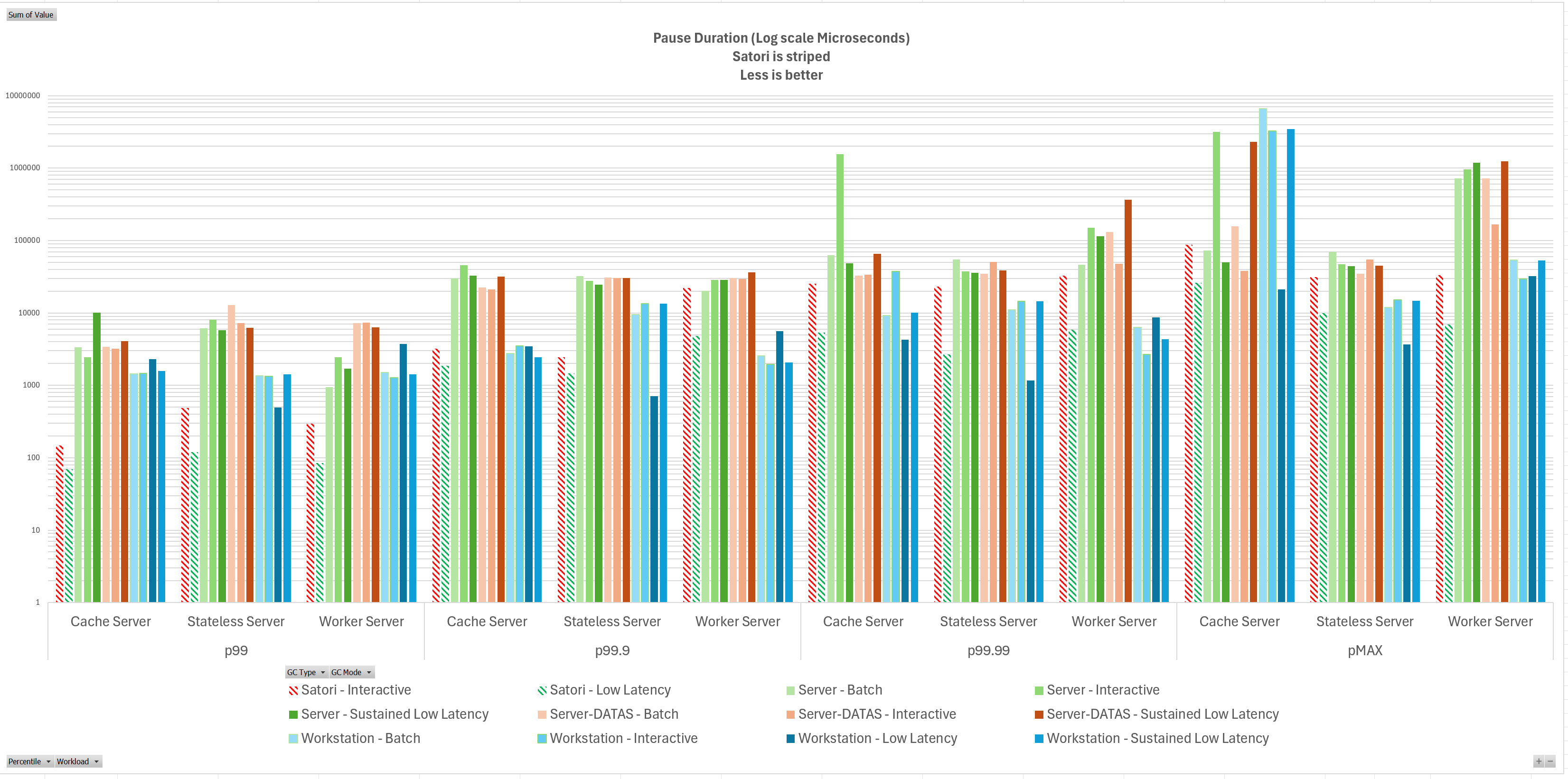
注意时间的单位是微秒(0.001ms),并且纵坐标进行了对数缩放。Satori GC 成功地做到了亚毫秒(小于 1000 微秒)级别的暂停。
最后看峰值内存占用:
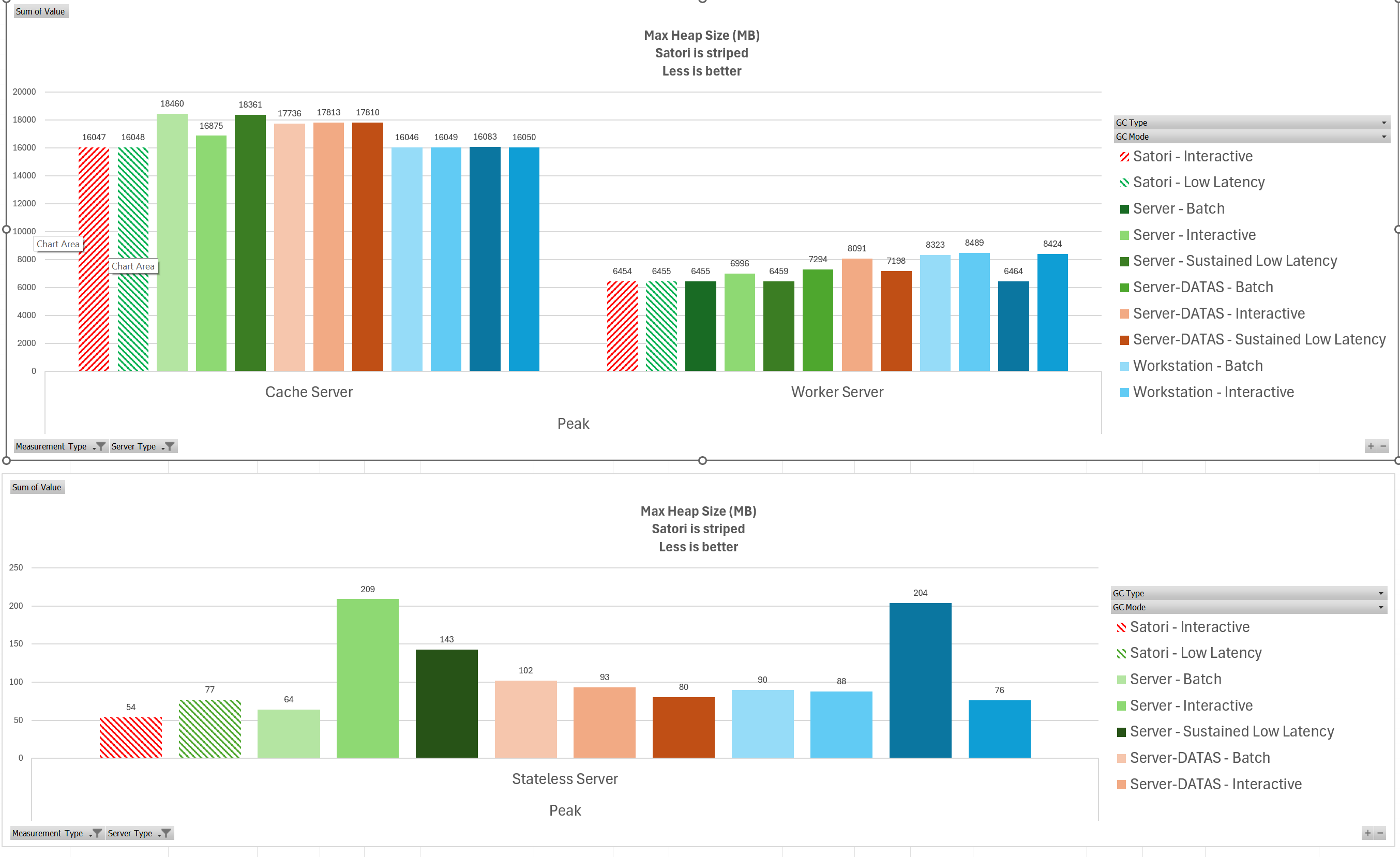
可以看到 Satori GC 相比其他 GC 而言有着出色的内存占用,在所有测试结果中几乎都是那个内存占用最低的。
综合以上三点,我们可以看到 Satori GC 在牺牲少量的吞吐量性能的同时,做到了亚毫秒级别的延时和低内存占用。只能说:干得漂亮!
大量分配速率测试
这同样是来自其他社区成员贡献的测试结果。在这个测试中,代码使用一个循环在所有的线程上大量分配对象并立马释放。
测试结果如下:
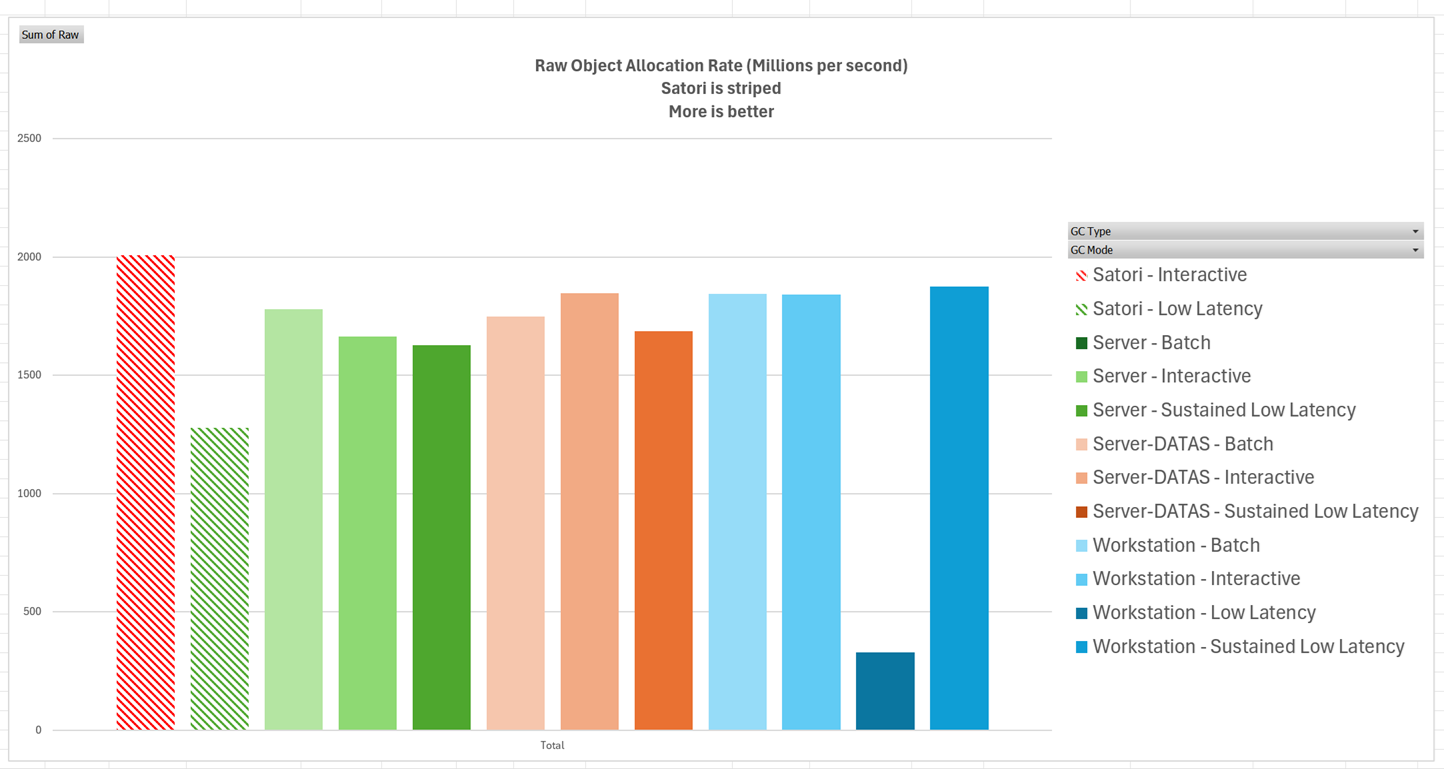
可以看到 Satori GC 的默认模式在这个测试中做到了最好的分配吞吐量性能,成功做到每秒分配 20 亿个对象。
总结
Satori GC 的目标是为 .NET 带来了一种全新的低延时高吞吐自适应 GC,不仅有着优秀的分配速率,同时还能做到亚毫秒级别的暂停时间和低内存占用,与此同时做到 0 配置开箱即用。
目前 Satori GC 仍然处于实验性阶段,还有不少的课题需要解决,例如运行时自动决策 Gen 0 的开关、更好的策略以均衡吞吐量性能和内存占用以及适配更新版本的 .NET 等等,但是已经可以用于真实世界应用了,想要试用 Satori GC 的话可以参考下面的方法在自己的应用中启用。
osu! 作为一款从引擎到游戏客户端都是纯 C# 开发的游戏,已经开始提供使用 Satori GC 的选项。在选歌列表的滚动测试中,Satori GC 成功将帧数翻了一倍,从现在的 120 fps 左右提升到接近 300 fps。
相信等 Satori GC 成熟正式作为 .NET 默认 GC 启用后,将会为 .NET 带来大量的性能提升,并扩展到更多的应用场景。
启用方法
截至目前(2025/5/22),Satori GC 仅支持在 .NET 8 应用中启用。考虑到这是目前最新的 LTS 稳定版本,因此目前来看也足够了,另外 Satori GC 的开发人员已经在着手适配 .NET 9。
osu! 团队配置了 CI 自动构建最新的 Satori GC,因此我们不需要手动构建 .NET Runtime 源码得到 GC,直接下载对应的二进制即可使用。
对于 .NET 8 应用:
- 使用
dotnet publish -c Release -r <rid> --self-contained发布一个自包含应用,例如dotnet publish -c Release -r win-x64 --self-contained - 从 https://github.com/ppy/Satori/releases 下载对应平台的最新 Satori GC 构建,例如
win-x64.zip - 解压得到三个文件:如果是 Windows 平台就是
coreclr.dll、clrjit.dll和System.Private.CoreLib.dll;而如果是 Linux 则是libcoreclr.so、libclrjit.so和System.Private.CoreLib.dll - 找到第一步发布出来的应用(一般在
bin/Release/net8.0/<rid>/publish文件夹里,例如bin/Release/net8.0/win-x64/publish),用第三步得到的三个文件替换掉发布目录里面的同名文件
然后即可享受 Satori GC 带来的低延时体验。
反馈渠道
如果在使用过程中遇到了任何问题,可以参考:
- GitHub 讨论贴:https://github.com/dotnet/runtime/discussions/115627
- Satori GC 代码仓库:https://github.com/VSadov/Satori