上一篇文章讲了层次聚类,今天再来说一下K均值(K-mean)聚类。虽然说目的都是为了聚类,但是他们的原理和展示方式都截然不同。其工作原理是K均值聚类的核心原理是:先指定要分成K类,然后通过迭代优化,让每个点归到离它最近的类中心,最后让类中心尽可能地代表这一类的数据点。
01 K均值聚类示例
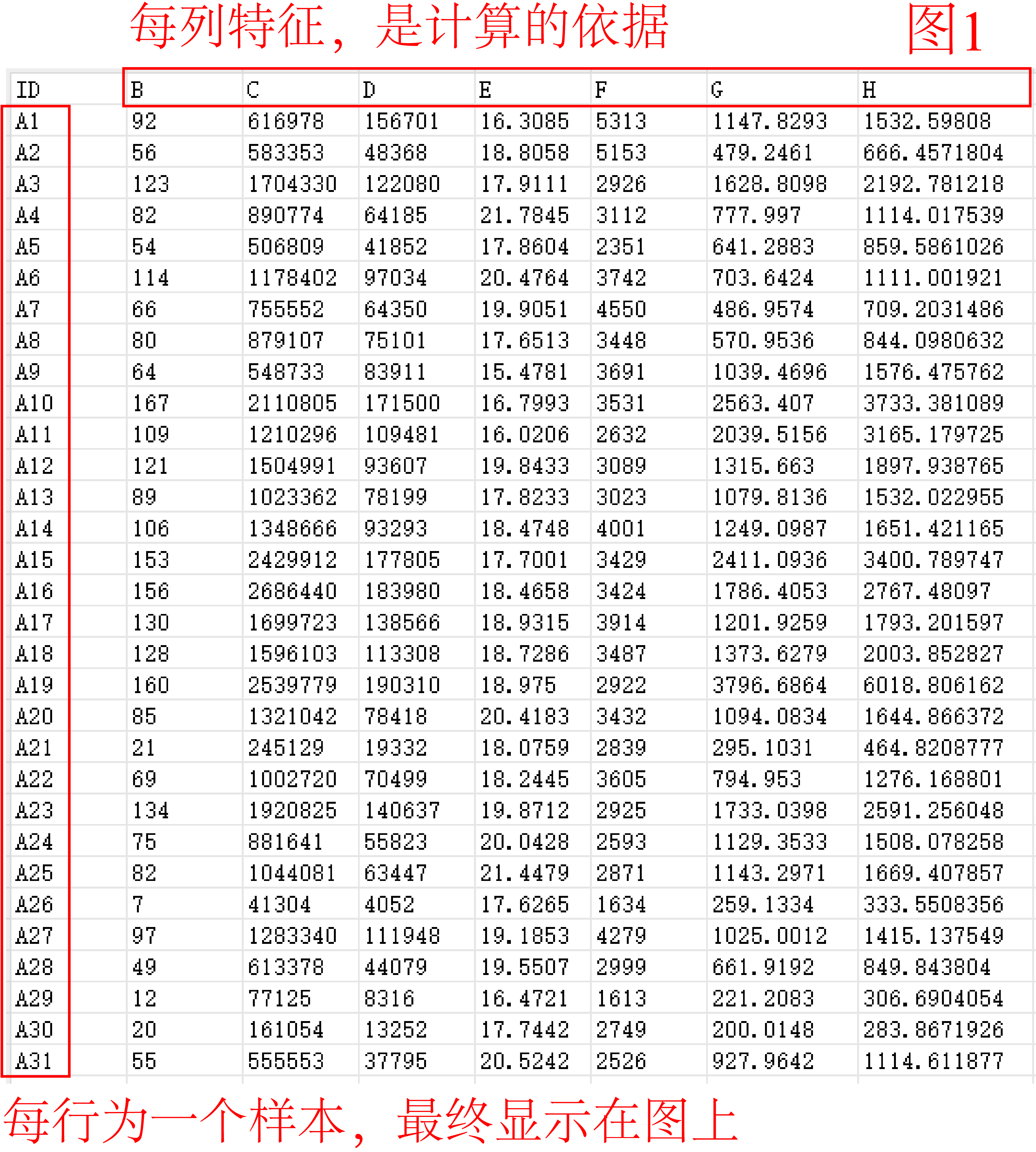
在图1示例数据中,每一列为一个特征,是聚类计算的依据;每行为一个样本,需要对它们进行分类。
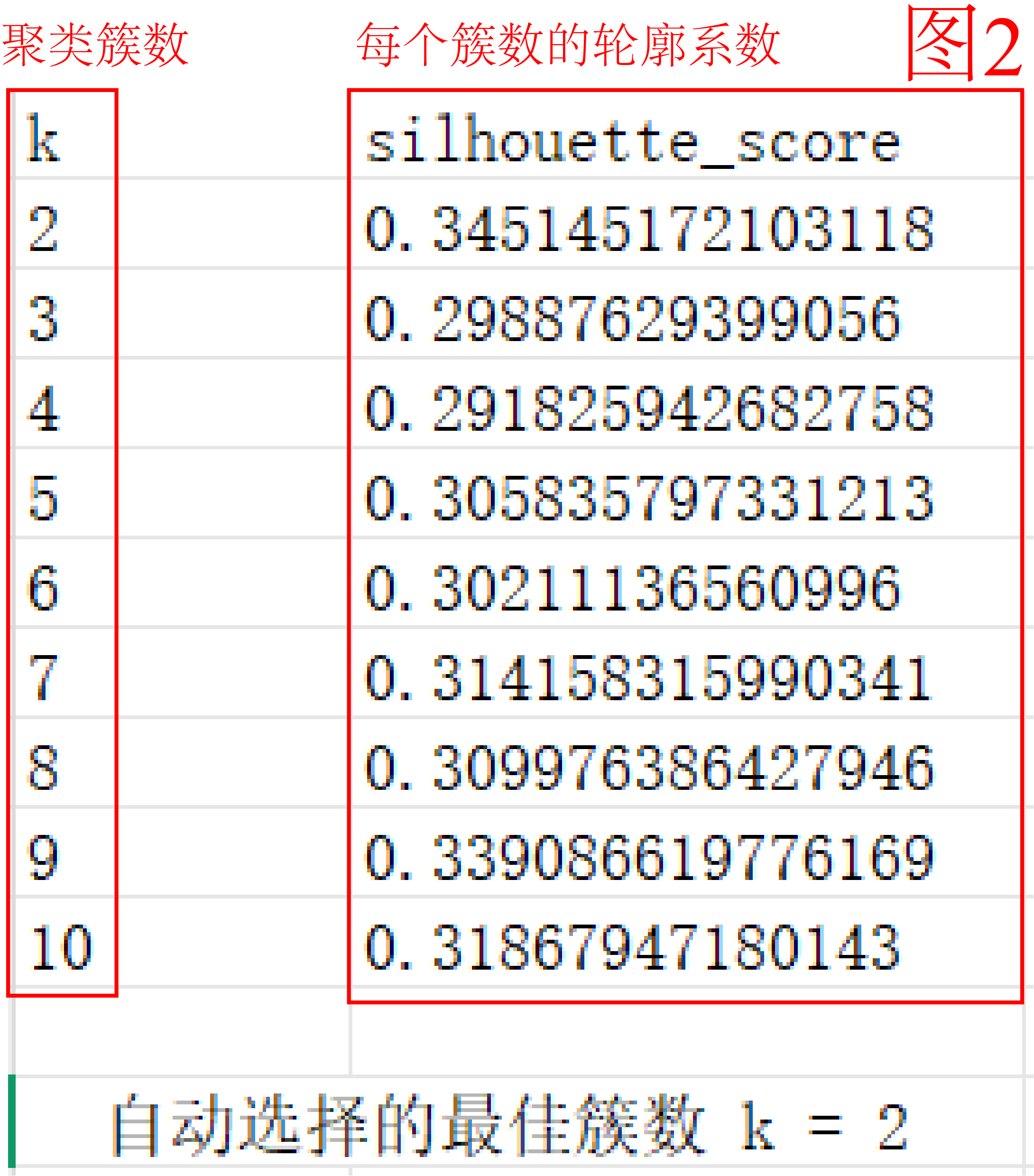
图2是轮廓系数,轮廓系数用于评估每个簇数的聚类质量,越高质量越好。
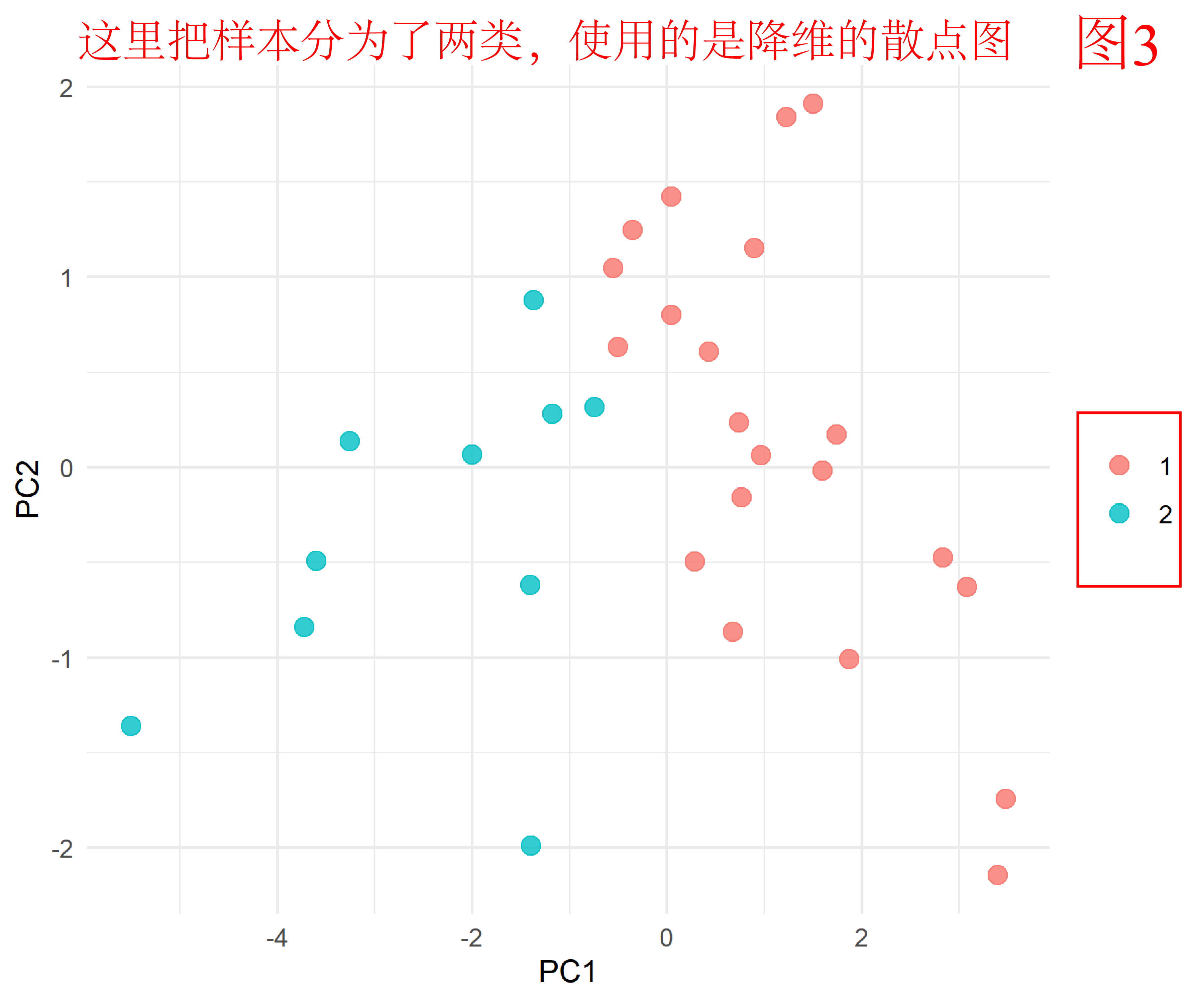
图3是K均值聚类结果,与层次聚类不同,K均值聚类采用展示方法的是降维散点图。
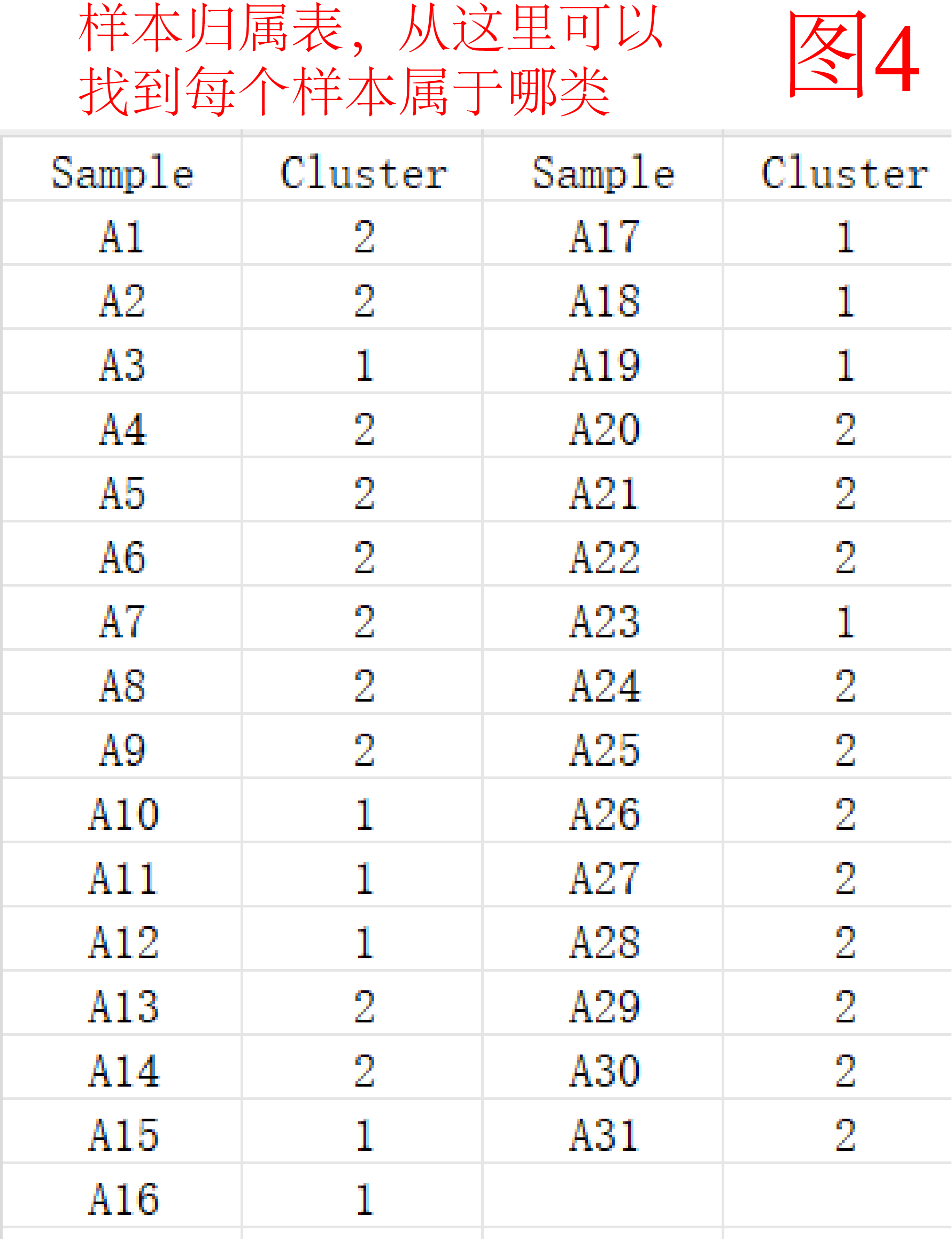
图4则展示了每个样品的聚类归属。
02 K均值聚类和层次聚类孰优孰劣?
K均值聚类的优点:效率高,速度快,适用于大样本数据,特别是当样本数量上千上万时,K均值能迅速完成聚类,适合大规模聚类。
K均值聚类的局限:必须自己设定聚类簇数,就像文中我们选取了轮廓系数最高的簇数;想要追踪样品归属的类别需要输出结果文件。
层次聚类的优点:层次可以不设定聚类数(也可以事先设定),首先生成一整棵树状图(dendrogram),你可以之后再决定切成几类,灵活性更高;可以观察到样本之间的聚类的过程以及具体归属,适合小样本精细分组分析。
层次聚类聚类的局限:不适合大规模数据集,当数据太多时,树状图展示的可读性就变得十分差。
03 如何选择聚类方法?
思考这三个问题,可以帮你快速决策:
一、数据量大吗?
大量样本 → 优先考虑K均值;
小数据、讲究解释性 → 可选层次聚类;
二、你是否希望保留层级结构信息?
如果你关心"谁和谁最像"、"谁是后来才分开的" → 层次聚类更合适。
三、你知道应该分几类吗?
知道 → K均值更快捷;
不知道 → 层次聚类搭配树状图更直观。
当然,无论哪种方法,轮廓系数都是一个推荐的聚类质量评价指标,可以辅助选择最合适的簇数。
TomatoSCI科研数据分析平台,欢迎大家来访!数据分析无需登录,专业在线客服答疑,还可在线传输文件,五折优惠码"tomatosci"开放使用中。PCA、RDA、PCoA、层次聚类等方法等你就位。
