本文根据ODPS十五周年·年度升级发布实录整理而成,演讲信息如下:
陈守元(巴真):阿里云智能集团计算平台事业部大数据产品总监
活动:【数据进化·AI启航】ODPS年度升级发布
今年是阿里云飞天 ODPS 的 15 周年,我们将重新定义 ODPS。在AI时代,ODPS 不仅仅是一个云原生的大数据平台,它更是一个为 AI 而生的大数据平台。
今天的分享主要分为三部分:第一部分将回顾 ODPS 作为云原生大数据平台如何帮助阿里集团实现数据时代的算力巅峰,并帮助客户从线下 IDC 迅速过渡到云原生的大数据;第二部分将探讨在 AI 时代下大数据 5V 的新定义;第三部分将重点阐述 ODPS 平台,这不仅仅是一个云原生平台,我还会详细阐述在 AI 时代下为 AI 而生的大数据平台应该具备的形态。
阿里云云原生大数据ODPS发展的阶段和成果
ODPS 大数据平台伴随着整个大数据的发展,完成了从线下到云上、从 Cloud-Native 到 AI-Native 转换。根据业界大数据发展历程,ODPS 演进也分为 4 个阶段。
第一阶段是数据库时代,数据处理引擎主要服务于在线业务(如金融、制造业、银行业务)的 TP 系统。第二阶段是数据仓库时代,数据不仅服务于在线业务,还更多地服务于企业数据分析和数据洞见,进而产生业务价值。随着云计算的诞生,大数据迅速过渡到了 Cloud-Native 时代。整个大数据处理从线下的 IDC 和数据仓库迅速过渡到云上的分布式大数据处理时代。这个时代我们将面对超大规模的计算和存储。以阿里云 ODPS 平台为代表的云计算平台,将帮助用户应对超大规模计算和存储挑战。最后一个阶段是现在的 AI-Native 时代。在这个时代,大数据平台不仅仅是做云原生的大数据处理,它会更多地帮助用户在 AI 时代更好地利用数据,让数据发挥更大的价值。
此外,我们可以看到整个业界从开源社区和技术的发展来看,已经从单一的 Hadoop 技术逐步过渡到多模态、多范式的大数据处理。阿里云紧跟社区和业界的最新技术,发布了 EMR、Elasticsearch、Flink 等产品。我们不仅仅是拥抱开源,更是在开源的基础上超越了开源。
ODPS 平台最初诞生于 MaxCompute。MaxCompute 从支持 5K 开始,正式宣告了它迈向全球一流的大数据平台。最终,MaxCompute 联合其他大数据处理引擎,包括 Flink、Hologres、Dataworks,构建了新一代 ODPS 处理平台。这个平台帮助用户迅速完成从 Cloud-Native 时代到 AI 时代处理范式的转型,帮助用户在 AI 时代最大化发挥数据价值。
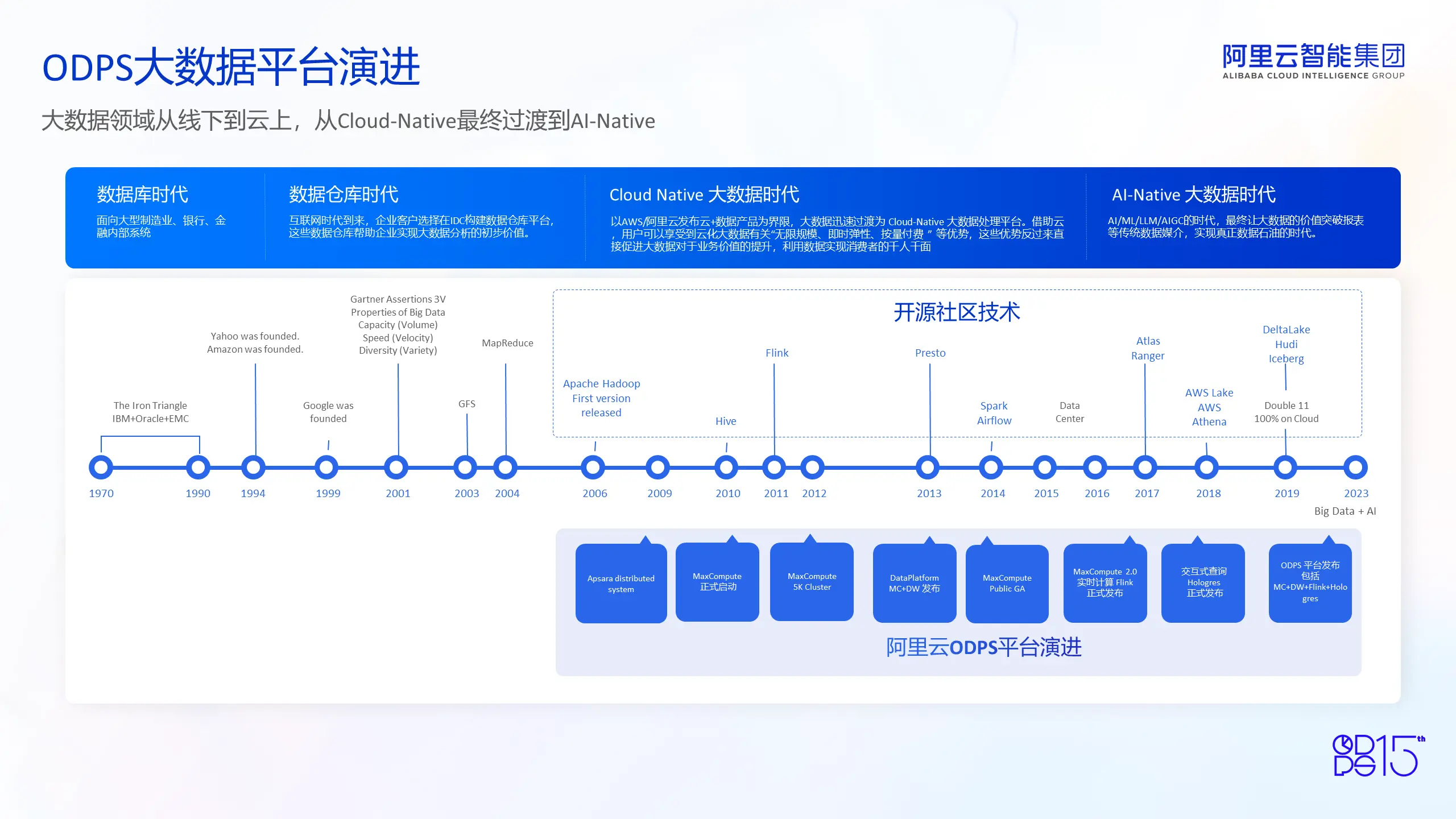
回顾 ODPS 整个发展历程和最终的业务成果,在云原生时代,ODPS 作为全球一流的大数据处理引擎,最终成就了中国大数据的算力巅峰。ODPS 平台在云上拥有数十万台集群规模,沉淀了数以 EB 级别的数据存储,同时支撑了最高峰值 50 亿的数据处理,这是它的算力规模。同时在业务支撑上,在阿里集团内部,ODPS 支撑了电商、金融、物流以及阿里云自身的云计算业务。这些 360 行的业务,在阿里集团和阿里云上,都基于 ODPS 大数据平台帮助到集团内部的业务和客户,最终完成了大数据价值的变现。

整个云原生大数据处理系统在 ODPS 的范围内实现了中国算力巅峰,那么现在整个业界都已经迅速过渡到了 AI 时代,我们也在思考如何在 AI 时代下面定义一套大数据处理系统。
整体上来说,我们认为有三个趋势。
- 第一,整个业界从 Cloud-Native 时代快速过渡到 AI-Native 时代。因此,我们的用户不仅仅需要一个云原生的大数据处理系统,更需要一个 AI 原生的大数据系统。从支持 AI 的处理到 AI 赋能大数据的转型。
- 第二,我们看到未来关键业务的变现已经从单纯的数据变现转变为 AI 帮助数据和业务进行变现。业务的关键在于 AI,而 AI 的关键在于数据。数据质量的好坏直接决定了 AI 的价值和业务的价值。
- 第三,以往业界认为数据的价值变现困难是因为数据被应用起来很困难。但在 AI 时代,AI 将直接桥接数据和业务的价值,极大地催化了数据的使用。
在这三个趋势下,我们能看到 AI 给数据带来了巨大的变化。那么在 AI 时代如何定义 Data Infrastructure,如何定义数据平台?ODPS 在 AI 时代下重新做了阐述和定义。

Bigdata 5V for AI: AI 时代,最大化数据价值
在大数据时代和云原生时代,Data 5V 概念已经被所有用户熟知。但我们认为,从 Cloud-Native 时代过渡到 AI 时代,这五个概念在定义上会有较大的变化。虽然总体提纲和思路不会变,但内容需要重新阐释和定义。从 Volume、Variety、Velocity、Varacity 和 Value 方面都会产生新的定义。
第一部分是 Volume ,我们认为在 AI 时代会有爆发式超大规模的数据存储和数据计算,特别是偏爆发式的算力响应需求会变得愈加迫切。
第二部分是 Variety,这里更多强调的是多模态数据。在传统的云原生时代,我们的数据结构大部分是 Structure Data(结构化数据)。但在 AI 时代,我们将面临更多的多模态数据处理。半结构化、非结构化数据会出现爆发式增长。这方面带来了巨大多模态数据存储和多模态计算需求。
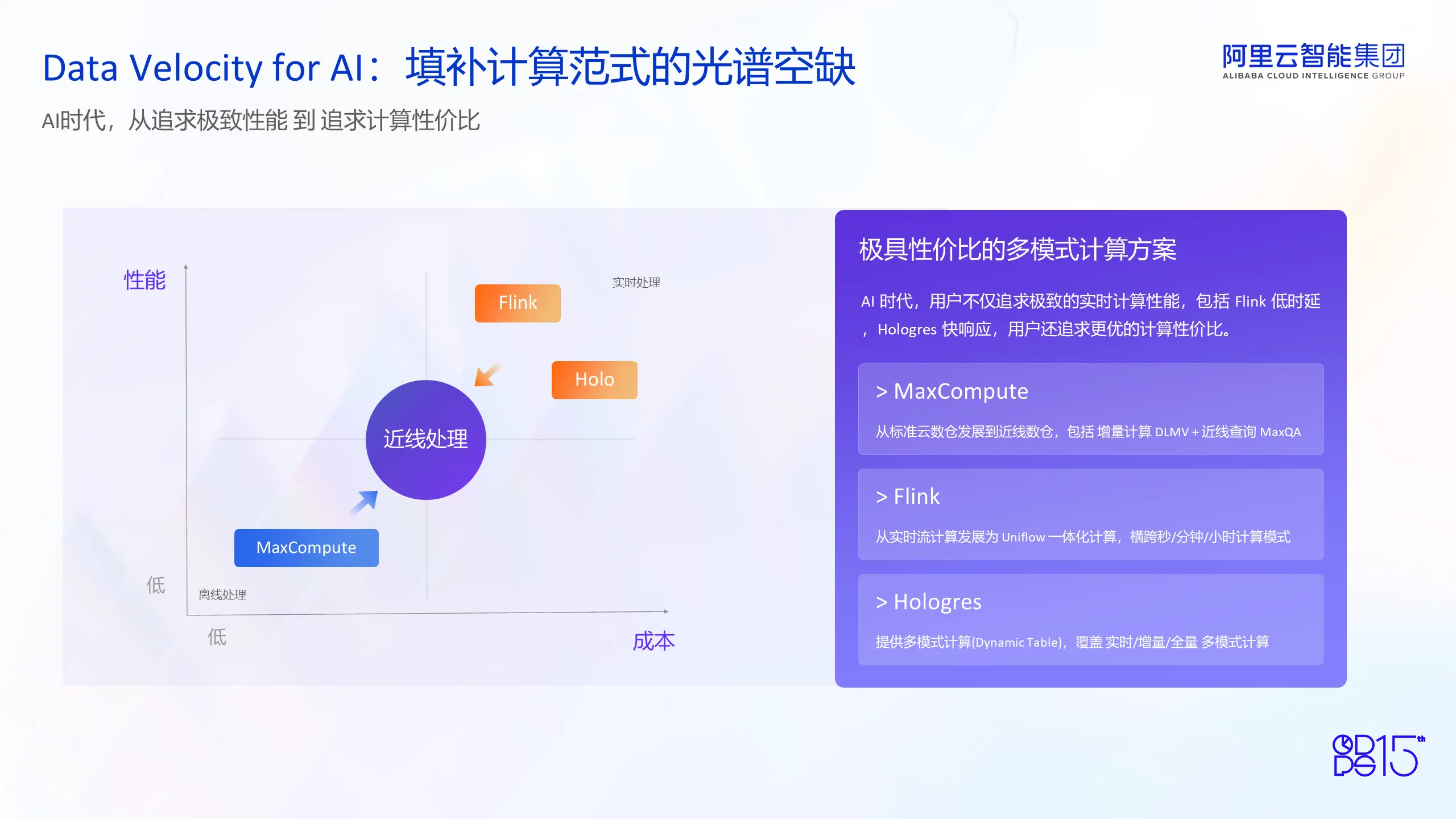
第三部分是 Velocity,用户从追求极致性能拓展为追求极致性价比。用户不仅需要一个性能好的系统,还要追求一个极致性价比的系统。AI 将这些极致性价比的系统直接带给用户。用户可以用非常低廉的价格或极高的性价比来使用大数据。
第四部分是 Varacity,这里更多强调稳定性,包括容灾、安全和稳定。ODPS 全系列产品推出了容灾方案,包括同城容灾、跨区域容灾以及数据备份功能,帮助用户放心地将核心数据与业务资产放在阿里云上。
最后一个是 Value,这更多地强调价值。前面提到,在大数据时代,很多用户认为数据变现比较困难。那么在 AI 时代下,这一部分会更多地由 AI 帮助用进行数据价值表达。我们认为数据的石油最终会通过 AI 和 LLM 来进行表达。

Data Volume for AI: 超大规模数据、超大规模计算
前面已经提到,在Al时代下,超大规模的数据存储和计算将会爆发。为什么这个场景会很突出呢?因为在LLM基础模型的训练中,往往突发需求会有数十万的CPU、数千PB和数万的GPU,即超大规模的算力消耗。这些算力消耗往往是爆发式的。用户在基模训练过程中,每隔一周、每隔几天、每隔半个月,会有一次集中式的算力爆发。而用户不需要为这种算力爆发长期锁定资源,他们需要一个按量付费、即开即用的算力系统。
以通义千问为例,通义是一套世界级的 Al 大模型。通义在使用 MaxCompute 时进行了大规模网页数据处理,为后续的大规模语言处理提供了加工语料。通义团队不定期需要数十万规模的 CU 算力,MaxCompute 这类云原生超大数仓计算服务正好满足其不定期算力需求,提供了数十万的超大规模算力,按需供应。同时,为了方便通义的使用,它无需预留资源,即开即用,整体上为其节省了 50%以上的成本。

Data Variety for AI:多模态数据->多模态存储
接下来是Variety。这里更多强调的是多模态数据处理。在大数据时代,其实更多的是以结构化数据为主。但是在AI时代,我们将面临更多的多模态数据处理。半结构化、非结构化数据会出现爆发式增长。这方面带来了巨大多模态数据存储和多模态计算需求。
在AI时代下,数据从结构化向多模态的变迁,带来了大量的用户需求和用户痛点。不少用户反馈,对于像MaxCompute这样的云厂商自研系统,其实缺乏开放性。那么针对这两个需求,一个是多模态数据处理,另外一个是开放性,ODPS-MaxCompute 提供了一个湖仓一体的方案,解决多模态数据存储及数据的开放性问题。
以客户数禾为例,数禾通过使用MaxCompute+DLF+EMR构建了一个湖仓一体方案。这套方案帮助用户实现了统一的元数据管理、统一的存储管理、统一的权限管理,真正实现了湖仓的自由流动,为企业内部数据的高速发展提供了一个很好的助力。通过使用MaxCompute的湖仓方案,整个数禾的开发效率提高了30%,其内部安全管理流程效率提高了70%。同时在此基础上,它的成本降幅达到50%,整体的查询性能也提升了3-5倍。这是我们湖仓一体方案给数禾带来的价值。

Data Variety for AI:多模态数据->多模态计算
提到了多模态数据存储,必然会提到多模态数据计算,因为数据模态变迁一定会带来计算的变迁。为了应对这种多模态数据计算的需求变化,我们认识到传统的SQL主要针对结构化数据处理,并不能完全满足当前AI时代下围绕多模态数据计算的编程需求。因此,MaxCompute推出了MaxFrame解决方案。
以MaxFrame的标杆客户无限光年为例,无限光年在使用 MaxCompute MaxFrame 进行数据处理时,充分利用了MaxCompute底层的超大规模资源。此外,通过上层集成的如Minhash、fastText等算子,用户能够基于MaxFrame和SQL体系,构建灵活的数据处理 pipeline。与传统基于Ray自建引擎的方法相比,这套方案的性能提高了约40%。同时,得益于弹性算力供给和全托管运维平台的支持,该方案帮助用户整体成本降低了50%以上,整体性价比提升了接近两倍。这就是MaxCompute MaxFrame为无限光年这个大模型客户带来的价值。

Data Variety for AI:填补计算范式的光谱空缺
接下来是Velocity,也就是我强调的数据性价比。在 AI 时代下,Velocity 更多的会填补计算范式的光谱空缺。在云原生的时代,很多用户会追求极致的性能。我们的Hologres 和 Flink 都提供了非常极致的性能,都是非常好的系统。但是过渡到大数据,过渡到 AI 时代之后,用户不仅仅追求极致性能,还会追求极致性价比。因为 AI 带来大量的算力消耗,用户需要在大规模的算力消耗上严控成本。
在此背景下,我们会提供了类似于近线处理的方案,不仅仅为用户提供接近实时计算的性能,同时还以非常低廉的成本帮助用户实现计算处理实时响应的需求。以两个方案为例:
第一个方案是 MaxCompute。MaxCompute 从标准的云数仓,从离线处理逐步过渡到近线数仓。主要的核心功能包括增量计算和MaxQA。增量计算在原有的批处理基础上发展了增量计算引擎,使用MicroBatch的方式,能帮助用户以离线的成本实现接近于实时或在线的性能延迟。MaxQA是在MaxCompute传统的Batch处理基础上提供了一个在线查询的方案,帮助用户以离线的成本实现在线近线的查询。
第二个方案是 Flink Uniflow,从实时处理逐步过渡到近实时或近线处理。本身Flink是一个实时流处理引擎,通过Uniflow,用户可以通过定义一个Flink Uniflow的materialized view,从完全实时化的处理过渡到Uniflow的一体化计算。这可以帮助用户实现秒级、分钟级甚至小时级别的计算模式。只需要用户设置不同的Latency delay,就可以帮助作业实现秒、分钟、小时甚至天级别的计算范式的迁移,而不需要修改任何代码。
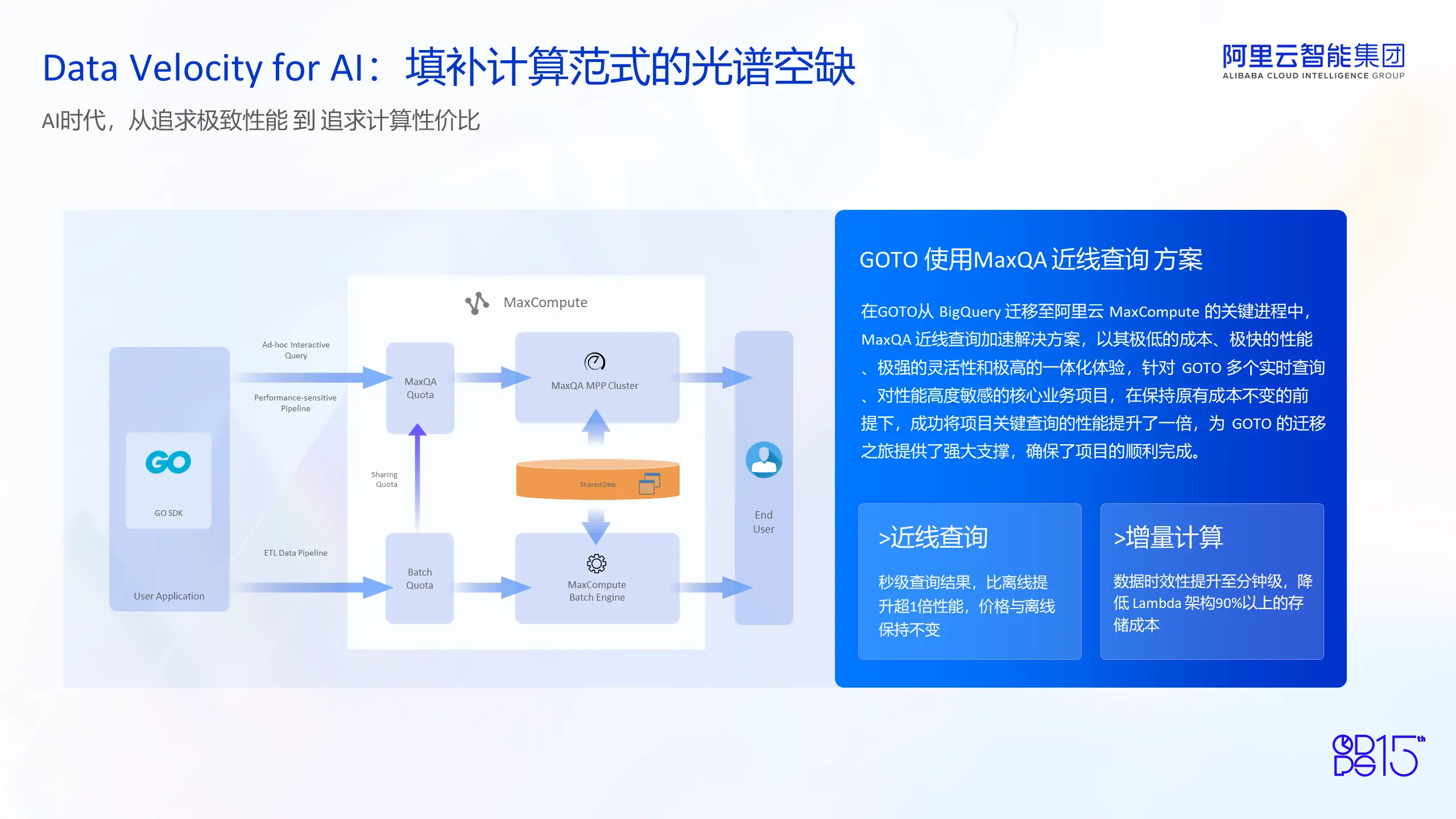
GoTo是东南亚领先的数字经济APP,覆盖了出行、电商和金融三大领域,是东南亚数字经济的巨头。在从BigQuery迁移到阿里云MaxCompute的关键历程中,GoTo采用了MaxCompute MaxQA近线查询引擎方案。这一方案使得用户能够以完全离线的成本实现接近实时的查询性能,同时还能享受到离线一体化的体验。用户使用同一套平台,同一套数据存储,只是通过不同的模式切换,就实现了以较低成本享受到极低的查询延迟。针对GoTo的实时查询及对性能敏感的核心项目,在保持原有成本不变的情况下,实现了性能翻倍,为GoTo的迁移提供了强有力的支持,确保了其从BigQuery到MaxCompute的平稳过渡。
Data Varacity for AI:容灾 安全 稳定
Varacity 这部分实际上是我们云上产品的一个关键特性,客户将最核心的生命资产托付给阿里云,因此我们必须提供一个稳定、安全且可靠的平台。今年,ODPS全系列产品线进行了容灾能力升级,包括不同级别的容灾和稳定性保障。例如,同城容灾支持同城多 AZ 容灾方式,包含计算同城容灾和存储同城容灾。同城级别在多 AZ 可以进行冗余的备份。跨地域容灾则提供更高规格的容灾方式,允许将数据远程备份至另一个区域,从而解决 Region 级别或者城市级别的服务宕机,更好的帮助用户实现数据服务、AI 服务的高可用。本地备份则让客户能以相对低廉的价格将数据备份至当前产品,以及在本地域的其他产品的数据介质上,满足单个产品或业务的容灾需求。通过这些不同规格与价格的容灾备份方案,用户可以根据自身业务需求和成本考量做出最佳选择,帮助他们以更低或更贴近业务价值的方式实现更好的容灾效果。

Data Value for AI: Data价值, AI表达
最后是Value,即数据价值。在 AI 时代,数据价值可以更好地帮助用户进行变现。那么在 AI 时代下,AI 如何帮助大数据业务进行更好的开发以及降本提效?在 ODPS 平台,我们提供了三个方案。
- Data+AI一体化开发:DataWorks DataStudio 基于 VSCode+Notebook构建,并结合 MaxCompute MaxFrame 以及 PAI 实现大数据AI一体化开发,打破两边业务的技术边界,极大降低了用户的开发成本。
- DataWorks Copilot:帮助用户以自然语言的方式在DataWorks上实现数据ETL编排、数据集成等,相当于半自动驾驶,帮助用户以更好或者更有效率的方式,在 DataWorks 上进行数据开发。
- DataWorks DataAgent:重构了人机协作模式,将数据开发从"专业工具"转化为"智能伙伴",实现数据的民主化与组织智力沉淀。让更多的非数据开发专业人员,例如产品经理、市场营销人员和销售人员,都能通过 DataWorks DataAgent 实现数据的提速和组织数据价值呈现。
ODPS 平台通过上述三个方案,帮助用户以 AI 化的方式实现快速降本提效。

Open Data for AI: 源于开源 超越开源
ODPS 作为自研大数据平台,很好的对接了阿里云开源大数据平台。两边的平台能够紧密地合作,构建类似湖仓一体、Data+AI 大数据一体化的平台。
在开源方面,阿里云一直积极地参与开源社区,拥抱开源、贡献开源。分享三个非常典型的产品在开源技术上面的优化。
第一个是 Flink,Flink 不仅仅在大数据引擎上做了优化。在方案层面也提供了更新、更优于开源的方案。包含 Flink Fluss 流湖一体的存储解决方案,Flink Uniflow 流/批/近线的一体化数据方案。
第二个是 Spark,Spark 是一个在开源社区非常成熟,使用面非常广的大数据处理引擎。在云上我们提供了基于开源 Spark 的 Native 引擎优化,相比于开源向量引擎性能提升2倍,能够让用户以更低的价格和更高的性能去实现业务价值。
最后是 StarRocks,我们基于StarRocks 开源引擎提供了相应的 Native 算子优化,相比开源性能提升 2-4 倍,帮助用户在 AI 时代下提供更好的在线分析和在线检索能力。

阿里云 ODPS:为 AI 而生的数据平台
在AI时代,ODPS将完全为AI而生,构建下一代技术平台。今年是 ODPS 十五周年,ODPS平台在面对AI 浪潮做了全新升级,推出面向 Data+AI 的新一代数智一体计算平台,融合Data和AI双引擎。我们分成四个层次进行解读。

**基础设施层:**整合阿里云计算、网络、存储等核心资源,支撑上层大数据和 AI 分布式架构的稳定运行。
**计算服务层:**在计算引擎层提供多种离线/实时/AI计算资源,在保障云端数据加工与AI算力调度能力之外,Data和AI也进行了深层的融合。MaxCompute融合大模型,围绕大模型提供超大规模数据预处理能力。Hologres通过 MCP 协议能够将湖仓中的海量数据转化为实时可查询的服务。这一层的存和算,形成了统一的 Data+AI 计算平台。实现了统一数据、统一存储、统一计算,帮助用户实现 Data+AI 一体化平台,打破数据孤岛,让数据处理更高效,模型训练更敏捷。
**平台管理层:**提供了统一 Data+AI 数据治理体系,用户可通过DataWorks Copilot智能助手即可调用模型,通过自然语言交互实现数据开发、数据分析与治理全流程。将 AI 能力赋能到大数据E2E 的管理流程,显著提升了数据工程的开发与运维效率,为数据开发者提效。
**应用场景层:**当前数智一体计算平台已覆盖RAG增强检索、LLM大模型训练、MLOps运维等多种AI工程化场景及需求。我们希望企业可以基于平台之上便捷地获取数据与AI的能力,真正实现"数据驱动业务,AI创造价值"。让AI放大数据价值,让数据无应用不价值。AI 让数据价值从"人分析数据"到"AI直接变现业务价值",让数据价值更加显性化。
在AI Native时代,数据与AI的融合已不再是选择题,而是必答题。阿里云将持续深耕Data+AI双引擎,助力企业加速智能化落地,共同迈向数智未来。