第一部分:数据处理
python
import kagglehub
# Download latest version
path = kagglehub.dataset_download("dylanjcastillo/7k-books-with-metadata")
print("Path to dataset files:", path)自动下载该数据集的 最新版本 并返回本地保存的路径
python
import pandas as pd
books = pd.read_csv(f"{path}/books.csv")
books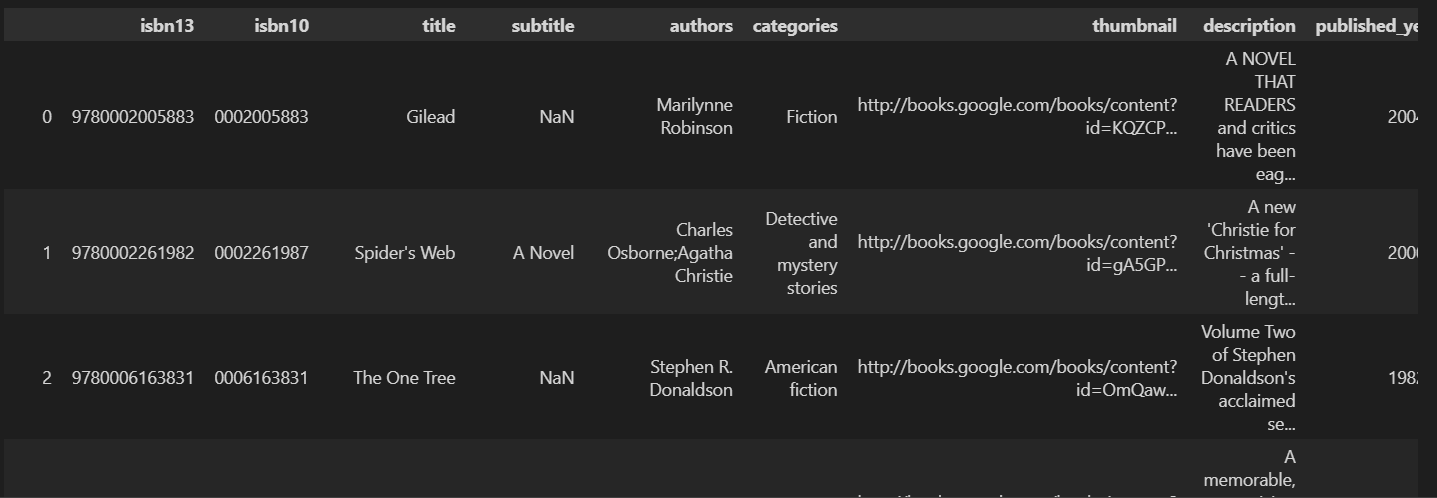
python
import seaborn as sns
import matplotlib.pyplot as plt
ax = plt.axes()
sns.heatmap(books.isna().transpose(), cbar=False, ax=ax)
plt.xlabel("Columns")
plt.ylabel("Missing values")
plt.show()创建一个 Matplotlib 的坐标轴对象(AxesSubplot),用于后续绘图。
books.isna() 会生成一个布尔矩阵,显示每个单元格是否为缺失值(NaN)。
.transpose() 将 DataFrame 转置 ------ 把行列调换,使每一列(字段)显示在 y 轴,每一行(记录)显示在 x 轴。
sns.heatmap(...) 会绘制一个热力图,白色通常表示缺失,深色表示非缺失。
cbar=False 关闭颜色条(color bar)。
ax=ax 指定使用我们前面创建的坐标轴。
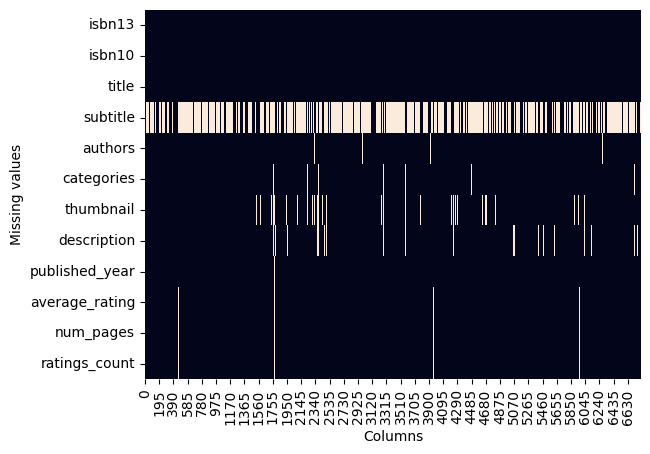
X 轴表示数据记录(行)
Y 轴表示数据字段(列)是否缺失(因为之前做了转置)
python
import numpy as np
books["missing_description"] = np.where(books["description"].isna(), 1, 0)
books["age_of_book"] = 2025 - books["published_year"]books"description".isna() 会返回一个布尔数组,指示每一行中 description 是否为缺失值(NaN)。
np.where(condition, x, y) 是一个三元选择函数:
- 如果 condition 为 True,则取 x(即 1)
- 否则取 y(即 0)
创建新的一列 age_of_book,表示书籍出版到 2025 年的时间跨度
python
columns_of_interest = ["num_pages", "age_of_book", "missing_description", "average_rating"]
correlation_matrix = books[columns_of_interest].corr(method = "spearman")
sns.set_theme(style="white")
plt.figure(figsize=(8, 6))
heatmap = sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap="coolwarm",
cbar_kws={"label": "Spearman correlation"})
heatmap.set_title("Correlation heatmap")
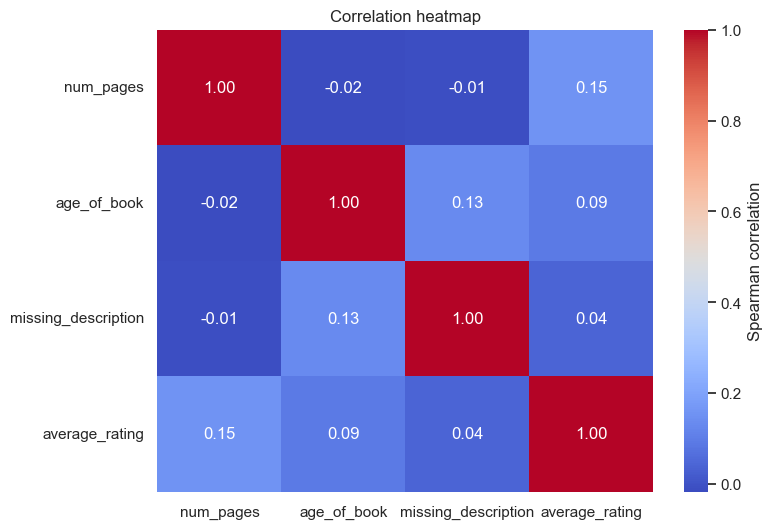
plt.show()定义感兴趣的字段列表:
-
"num_pages":图书页数
-
"age_of_book":图书出版的年限(之前计算得出)
-
"missing_description":是否缺失描述(之前创建的标志位)
-
"average_rating":图书的平均评分
计算这四个字段之间的 相关系数矩阵,使用 Spearman 等级相关系数
bookscolumns_of_interest 提取这几个字段组成新的 DataFrame
.corr(method="spearman") 表示使用 Spearman 方法来计算相关性(适用于非线性或非正态分布的数据)。
结果是一个 4x4 的矩阵,数值范围在 -1, 1 之间,表示变量之间的相关程度:
-
1 表示完全正相关
-
-1 表示完全负相关
-
0 表示无相关性
设置 Seaborn 图表主题为白色背景。
绘制热力图:
-
correlation_matrix:输入数据为相关系数矩阵
-
annot=True:在每个格子里显示数值
-
fmt=".2f":格式保留两位小数
-
cmap="coolwarm":颜色映射(红-蓝渐变,红色代表正相关,蓝色代表负相关)
-
cbar_kws={"label": "Spearman correlation"}:给右侧颜色条加上标签
python
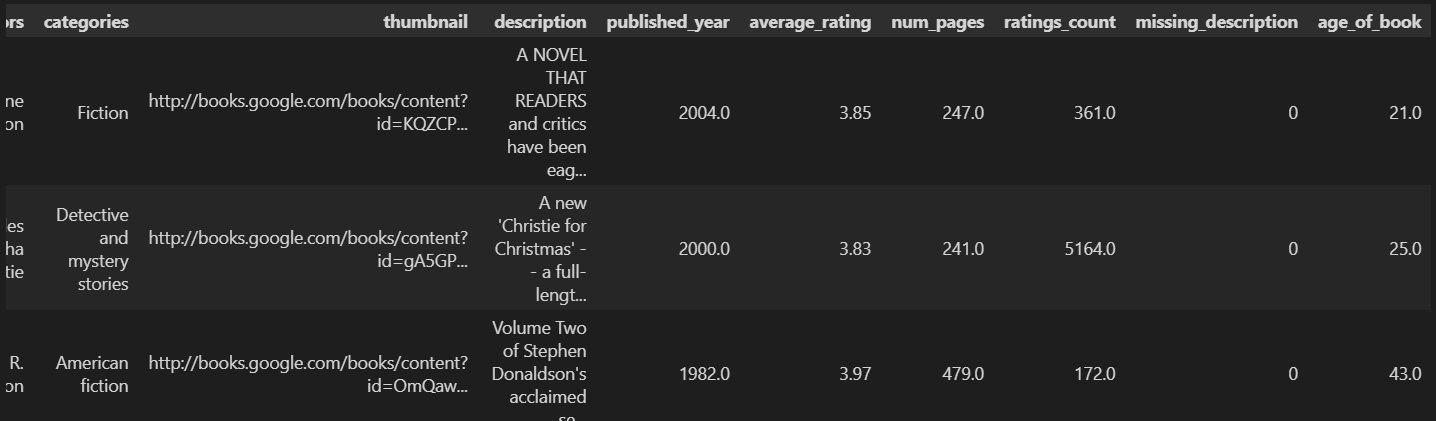
book_missing = books[~(books["description"].isna()) &
~(books["num_pages"].isna()) &
~(books["average_rating"].isna()) &
~(books["published_year"].isna())
]
book_missingbooks"description".isna():检查 description 字段是否为缺失(NaN)
~(...):逻辑"非"(NOT),表示"不是缺失的"
描述、页数、评分、出版年份 四个字段都不是缺失值。
python
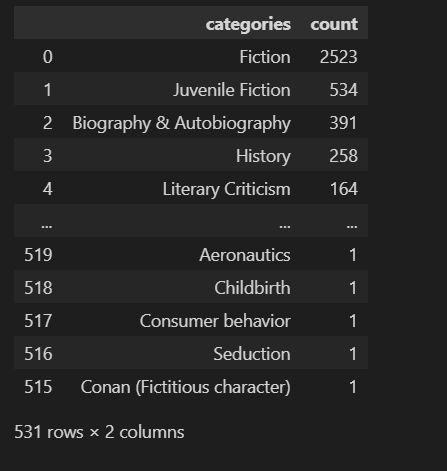
book_missing["categories"].value_counts().reset_index().sort_values("count", ascending=False)对 book_missing 数据集中 categories 列进行 计数(统计每种类别出现的次数)
返回结果是一个 Series,索引是类别名称,值是出现次数
将 value_counts() 的结果从 Series 变成一个 DataFrame,原本的索引(分类名)被变成一列(通常是 index 列)
找出哪些图书类别最常出现
python
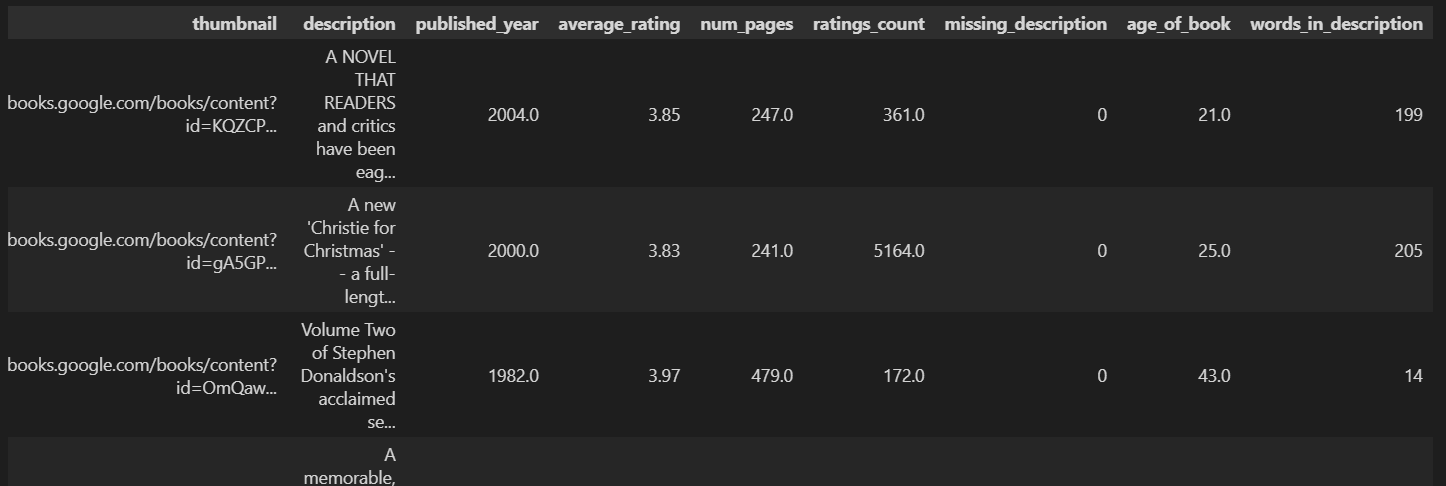
book_missing["words_in_description"] = book_missing["description"].str.split().str.len()
book_missing计算每本书的简介(description)中包含了多少个单词,并将结果保存到一个新列 words_in_description 中。
str.split() 是 Pandas 的字符串处理方法,用于将每本书的简介字符串按空格 分割成单词列表。
对每一行分割后的列表计算长度,也就是列表中单词的数量。
创建新列 words_in_description,其值是每条 description 中的单词数(即单词总数或长度)。
python
book_missing_25_words = book_missing[book_missing["words_in_description"] >= 25]
book_missing_25_words从 book_missing 数据集中筛选出简介(description)中包含 不少于 25 个单词 的图书记录,并保存到 book_missing_25_words 中。
这是一个布尔表达式,检查每本书的 words_in_description(简介的单词数)是否 大于等于 25
变量 book_missing_25_words 包含的是那些 简介长度 ≥ 25 个单词 的图书记录。
python
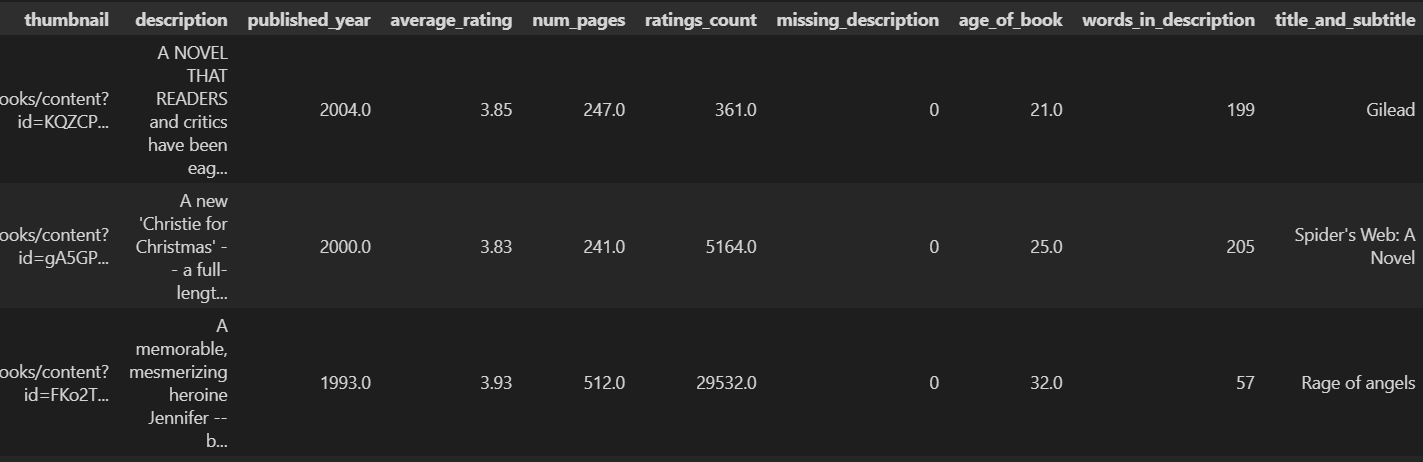
book_missing_25_words["title_and_subtitle"] = (
np.where(book_missing_25_words["subtitle"].isna(), book_missing_25_words["title"],
book_missing_25_words[["title", "subtitle"]].astype(str).agg(": ".join, axis=1))
)
book_missing_25_words为每本书生成一个新的字段 title_and_subtitle,内容是"书名: 副标题"(如果有副标题),否则就只用书名。
判断副标题是否缺失(NaN),返回一个布尔序列。
这是 NumPy 的条件选择函数:np.where(condition, value_if_true, value_if_false)
- 如果 subtitle 是 NaN,就取 title
- 否则,组合 title 和 subtitle 成 "title: subtitle" 形式
对每一行(axis=1)将 title 和 subtitle 用 ": " 连接。
这段代码的目的是构建一个统一的"完整书名"字段,结合书名和副标题
python
book_missing_25_words["tagged_description"] = book_missing_25_words[["isbn13", "description"]].astype(str).agg(" ".join, axis=1)
book_missing_25_words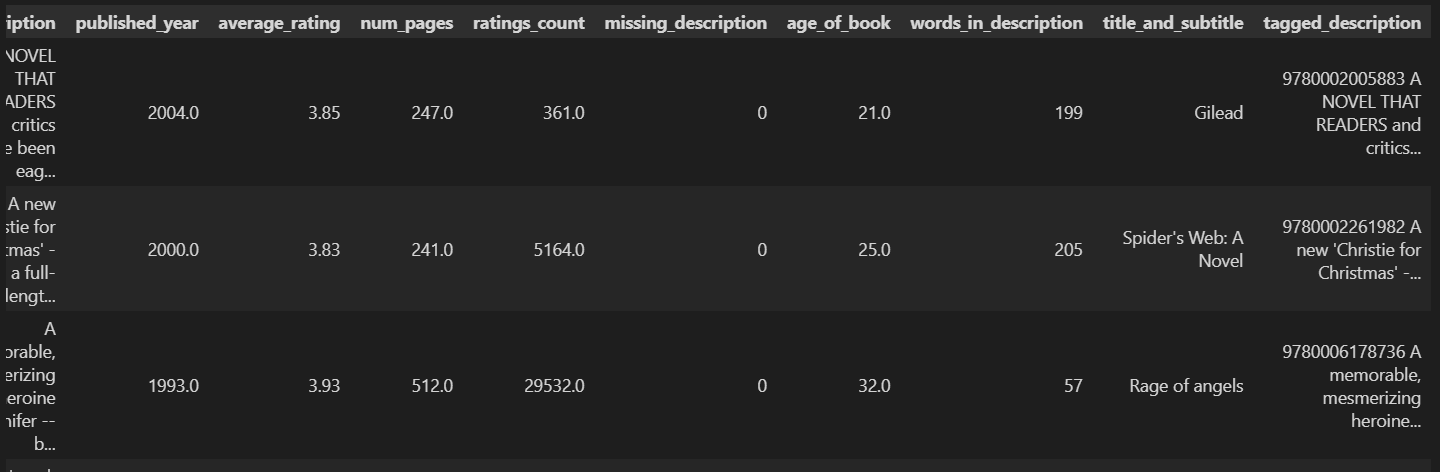
python
(
book_missing_25_words
.drop(["subtitle", "missing_description", "age_of_book", "words_in_description"], axis=1)
.to_csv("books_cleaned_new.csv", index = False)
)对 book_missing_25_words 数据框进行清理(删除一些不再需要的列),然后将结果保存为一个新的 CSV 文件 books_cleaned_new.csv。
删除指定的列:
-
"subtitle":副标题(因为我们已经合并为 title_and_subtitle,原列可删除)
-
"missing_description":布尔值字段(描述是否缺失),此时已无用
-
"age_of_book":出版年份转化来的字段,不再需要
-
"words_in_description":简介单词数,之前用于筛选,现在可以移除
.drop(..., axis=1) 表示按列(axis=1)进行删除。
将处理后的数据保存为 CSV 文件
index=False 表示不要把 DataFrame 的索引保存到文件中(只保存列和数据)
数据分析流程中 "导出清洗后的最终数据"