要求:
输入文件的按照空格、逗号、点号、双引号等分词
输入文件的大写字母全部换成小写
文件输出要求按照value值降序排序
Hadoop给的wordcount示例代码以及代码理解
基于map reduce的word count个人理解:输入的文件经过map reduce框架处理后,将文件分成几份,对于每份文件由独立的job来执行,针对每个job,输入的文件由map按行处理得到相应的输出,中间经过一次shuffle操作,最后经过reduce操作得到输出,输出是按照key的升序排列的。
一、创建项目
1、打开idea
bash
cd export/servers/IDEA/bin #然后回车
./idea.sh2、创建项目
3、配置项目以及写项目
目录结构
Wordcount/
├── .idea/ # IDE(IntelliJ)配置文件(无需手动修改)
├── src/
│ ├── main/
│ │ ├── java/ # 主代码目录
│ │ │ └── org/example/
│ │ │ ├── SortReducer # 排序Reducer类
│ │ │ ├── WordCount # 主程序入口
│ │ │ ├── WordCountMapper # Mapper类
│ │ │ └── WordCountReducer # Reducer类
│ │ └── resources/ # 配置文件目录(如log4j.properties)
│ └── test/ # 测试代码目录(可选)
├── target/ # 编译输出目录(由Maven自动生成)
│ ├── classes/ # 编译后的.class文件
│ └── generated-sources/ # 生成的代码(如Protocol Buffers)
├── .gitignore # Git忽略规则
└── pom.xml # 项目依赖和构建配置
配置pom.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.7.7</hadoop.version>
</properties>
<dependencies>
<!-- Hadoop 2.7.7 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>org.example.WordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- 必须添加的仓库配置 -->
<repositories>
<!-- 阿里云镜像(优先) -->
<repository>
<id>aliyun</id>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
<!-- Apache 归档仓库(备用) -->
<repository>
<id>apache-releases</id>
<url>https://repository.apache.org/content/repositories/releases/</url>
</repository>
</repositories>
</project>有些要改成自己的hadoop版本 我的是hadoop2.7.7版本 可以把这个代码复制然后问ai帮你改一下版本 改成你hadoop的版本
然后先点右边的maven 更新配置 先卸载clean,再点install
然后再打开idea控制栏 然后选择Terminal
安装Maven
bash
cd ~/.m2/repository/org/apache/hadoop
sudo yum install maven
#完成后
mvn -v
#查看安装好了没有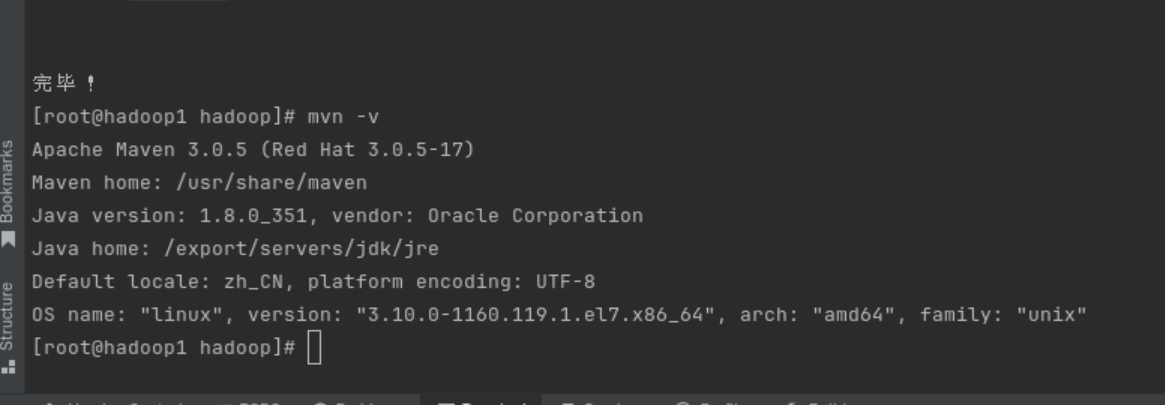
在src/main/org.example下面创建五个类
分别为:WordCountMapper、WordCountReducer、SortMapper、SortReducer、WordCount
java
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Mapper类:负责分词和初步统计
* 输入:<行号, 行内容>
* 输出:<单词, 1>
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private final Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 定义分词分隔符:空格、逗号、点号、双引号等
String delimiters = " \t\n\r\f\",.:;?![](){}<>'";
// 将整行转为小写
String line = value.toString().toLowerCase();
// 使用StringTokenizer分词
StringTokenizer tokenizer = new StringTokenizer(line, delimiters);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one); // 输出<单词, 1>
}
}
}
java
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer类:统计词频
* 输入:<单词, [1,1,...]>
* 输出:<单词, 总次数>
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // 输出<单词, 总次数>
}
}
java
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SortMapper extends Mapper<LongWritable, Text, IntWritable, Text> {
private final IntWritable count = new IntWritable();
private final Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 输入格式: word\tcount
String[] parts = value.toString().split("\t");
if (parts.length == 2) {
word.set(parts[0]);
count.set(Integer.parseInt(parts[1]));
context.write(count, word); // 输出: <count, word>
}
}
}
java
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
public class SortReducer extends Reducer<IntWritable, Text, Text, IntWritable> {
// 使用List+自定义排序替代TreeMap,解决相同词频被覆盖的问题
private final List<WordFrequency> wordFrequencies = new ArrayList<>();
private final Text outputKey = new Text();
private final IntWritable outputValue = new IntWritable();
// 自定义数据结构存储单词和词频
private static class WordFrequency {
final String word;
final int frequency;
WordFrequency(String word, int frequency) {
this.word = word;
this.frequency = frequency;
}
}
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) {
int frequency = key.get();
// 处理相同词频的不同单词
for (Text val : values) {
wordFrequencies.add(new WordFrequency(val.toString(), frequency));
// 内存保护:限制最大记录数(根据集群内存调整)
if (wordFrequencies.size() > 100000) {
context.getCounter("SORT", "TRUNCATED_RECORDS").increment(1);
break;
}
}
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
// 按词频降序、单词升序排序
Collections.sort(wordFrequencies, new Comparator<WordFrequency>() {
@Override
public int compare(WordFrequency wf1, WordFrequency wf2) {
int freqCompare = Integer.compare(wf2.frequency, wf1.frequency);
return freqCompare != 0 ? freqCompare : wf1.word.compareTo(wf2.word);
}
});
// 输出结果(可限制Top N)
int outputCount = 0;
for (WordFrequency wf : wordFrequencies) {
if (outputCount++ >= 1000) break; // 可选:限制输出数量
outputKey.set(wf.word);
outputValue.set(wf.frequency);
context.write(outputKey, outputValue);
}
// 调试信息
context.getCounter("SORT", "TOTAL_WORDS").increment(wordFrequencies.size());
context.getCounter("SORT", "UNIQUE_FREQUENCIES").increment(
wordFrequencies.stream().mapToInt(wf -> wf.frequency).distinct().count()
);
}
}
java
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Arrays;
public class WordCount {
public static void main(String[] args) throws Exception {
System.out.println("Received args: " + Arrays.toString(args));
// 参数处理:取最后两个参数
if (args.length < 2) {
System.err.println("Usage: hadoop jar YourJar.jar [mainClass] <input path> <output path>");
System.exit(-1);
}
String inputPath = args[args.length - 2];
String outputPath = args[args.length - 1];
Configuration conf = new Configuration();
Path tempOutput = new Path("/temp_wordcount_output");
try {
// ========== Job1: 词频统计 ==========
Job job1 = Job.getInstance(conf, "Word Count");
job1.setJarByClass(WordCount.class);
job1.setMapperClass(WordCountMapper.class);
job1.setCombinerClass(WordCountReducer.class);
job1.setReducerClass(WordCountReducer.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job1, new Path(inputPath));
FileOutputFormat.setOutputPath(job1, tempOutput);
if (!job1.waitForCompletion(true)) {
System.exit(1);
}
// ========== Job2: 排序 ==========
Job job2 = Job.getInstance(conf, "Word Count Sort");
job2.setJarByClass(WordCount.class);
job2.setMapperClass(SortMapper.class);
job2.setReducerClass(SortReducer.class);
// 关键修改:设置正确的类型
job2.setMapOutputKeyClass(IntWritable.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job2, tempOutput);
FileOutputFormat.setOutputPath(job2, new Path(outputPath));
System.exit(job2.waitForCompletion(true) ? 0 : 1);
} finally {
try {
tempOutput.getFileSystem(conf).delete(tempOutput, true);
} catch (Exception e) {
System.err.println("警告: 临时目录删除失败: " + tempOutput);
}
}
}
}4、idea打包java可执行jar包
方法一:打包Jar包
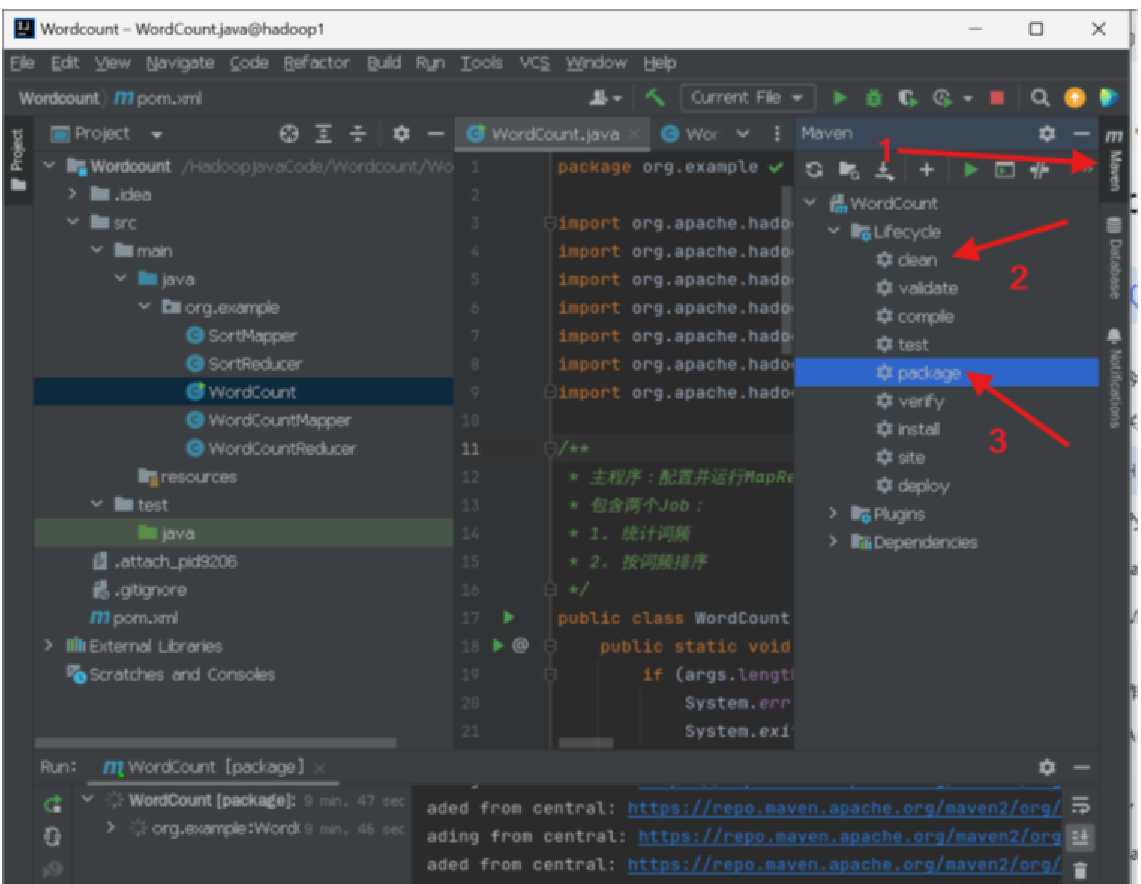
这样就打包好了
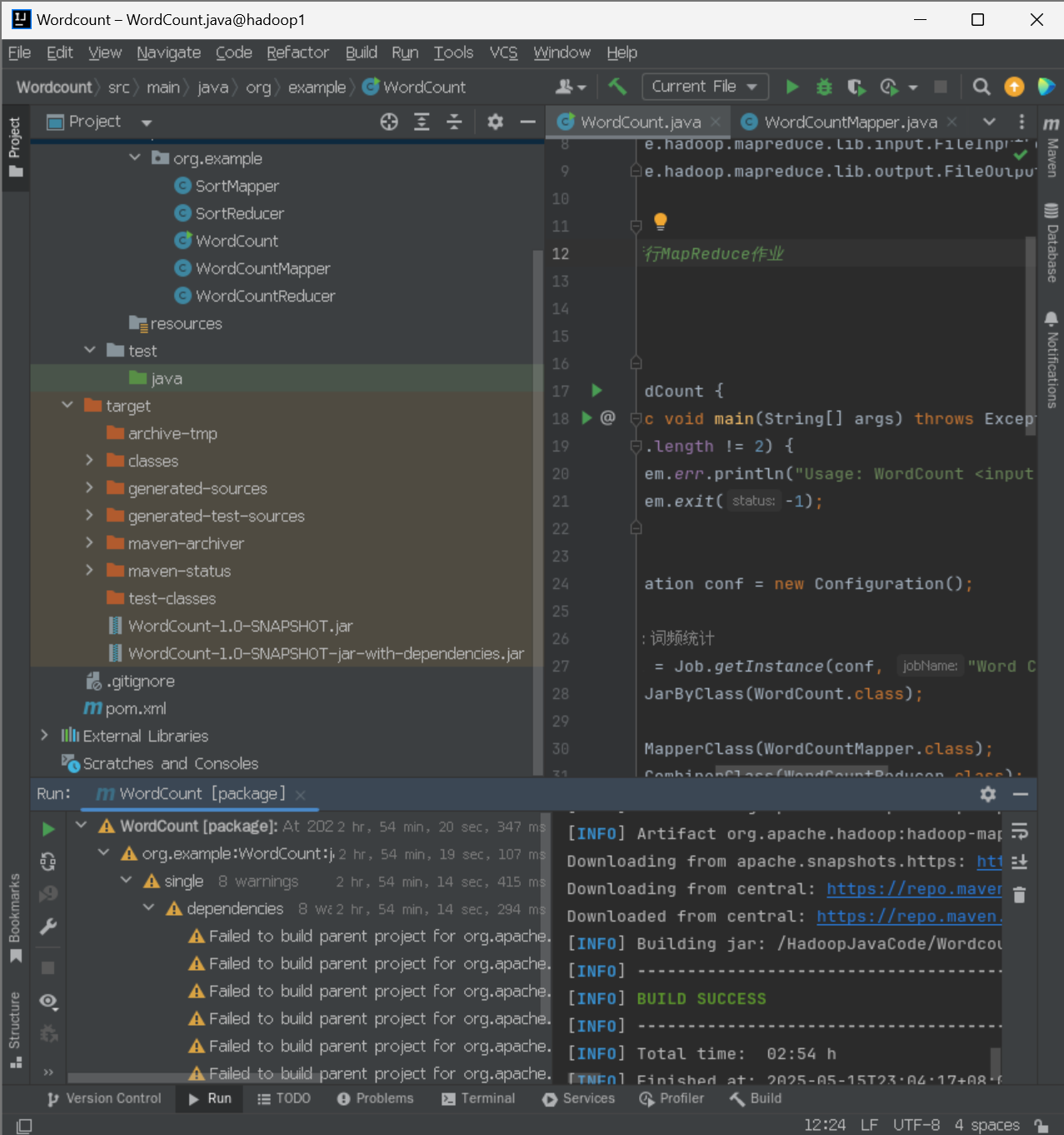
5、运行jar包
5.1启动hadoop集群
bash
#启动h1
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车
#启动h1
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车
#启动h3
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车5.2 运行jar包
首先在/export/data下上传这个文件 wordcount.txt
bash
cd /export/data #然后上传这个文件 wordcount.txt
#创建目录
hadoop fs -mkdir -p /input
#上传到hdfs上
hadoop fs -put /export/data/wordcount.txt /input/
#验证上传
hadoop fs -ls /input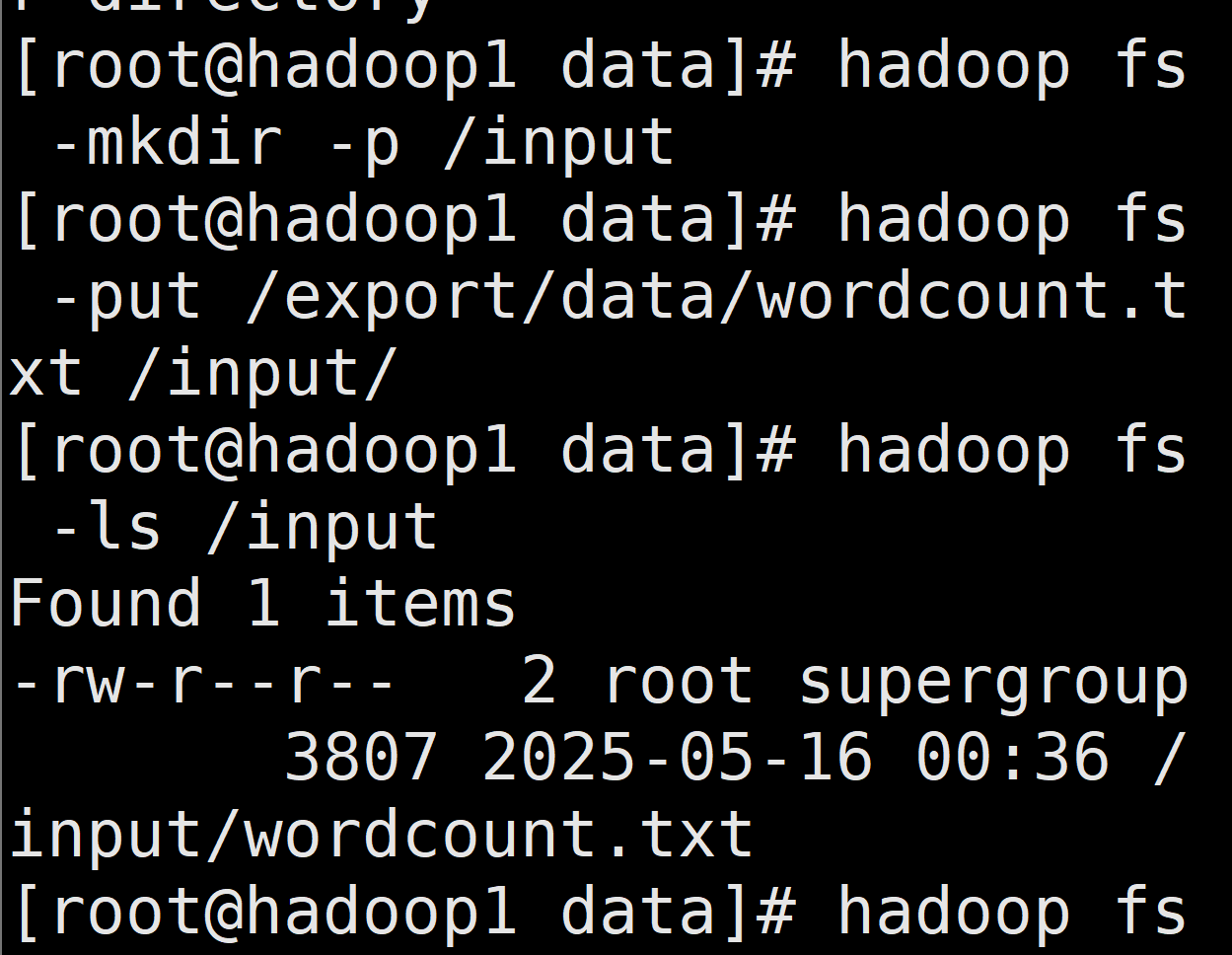
切换目录
bash
cd /HadoopJavaCode/Wordcount/Wordcount清理并打包jar包:
bash
mvn clean package确保HDFS目录:
bash
hadoop fs -rm -r /temp_wordcount_output # 删除可能存在的临时目录
hadoop fs -ls /input/wordcount.txt # 确认输入文件存在运行作业:
bash
hadoop jar target/WordCount-1.0-SNAPSHOT-jar-with-dependencies.jar \
org.example.WordCount \
/input/wordcount.txt \
/output_wordcount
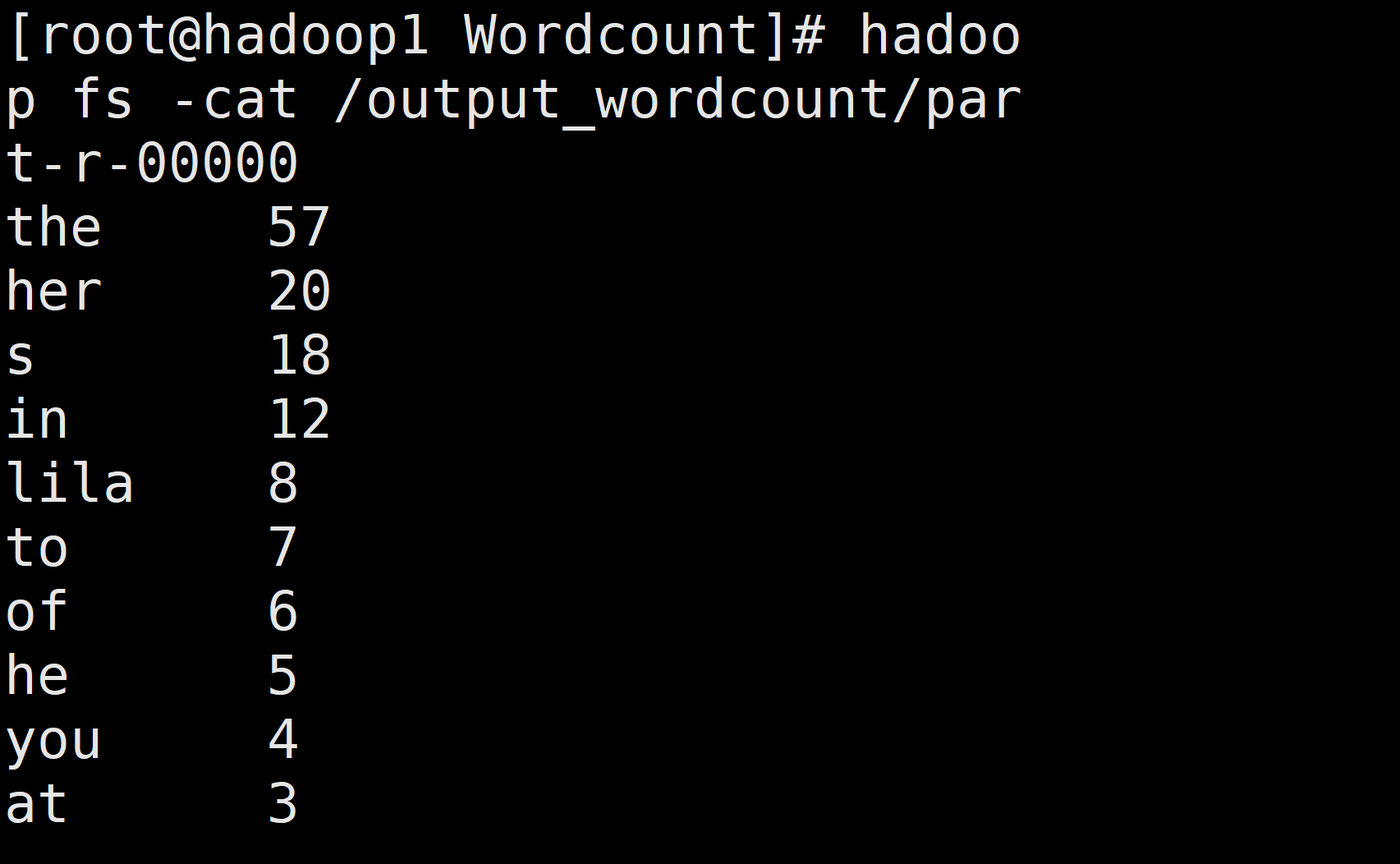
查看结果
bash
# 查看输出目录内容
hadoop fs -ls /output_wordcount
# 查看实际结果(显示前20行)
hadoop fs -cat /output_wordcount/part-r-00000 | head -20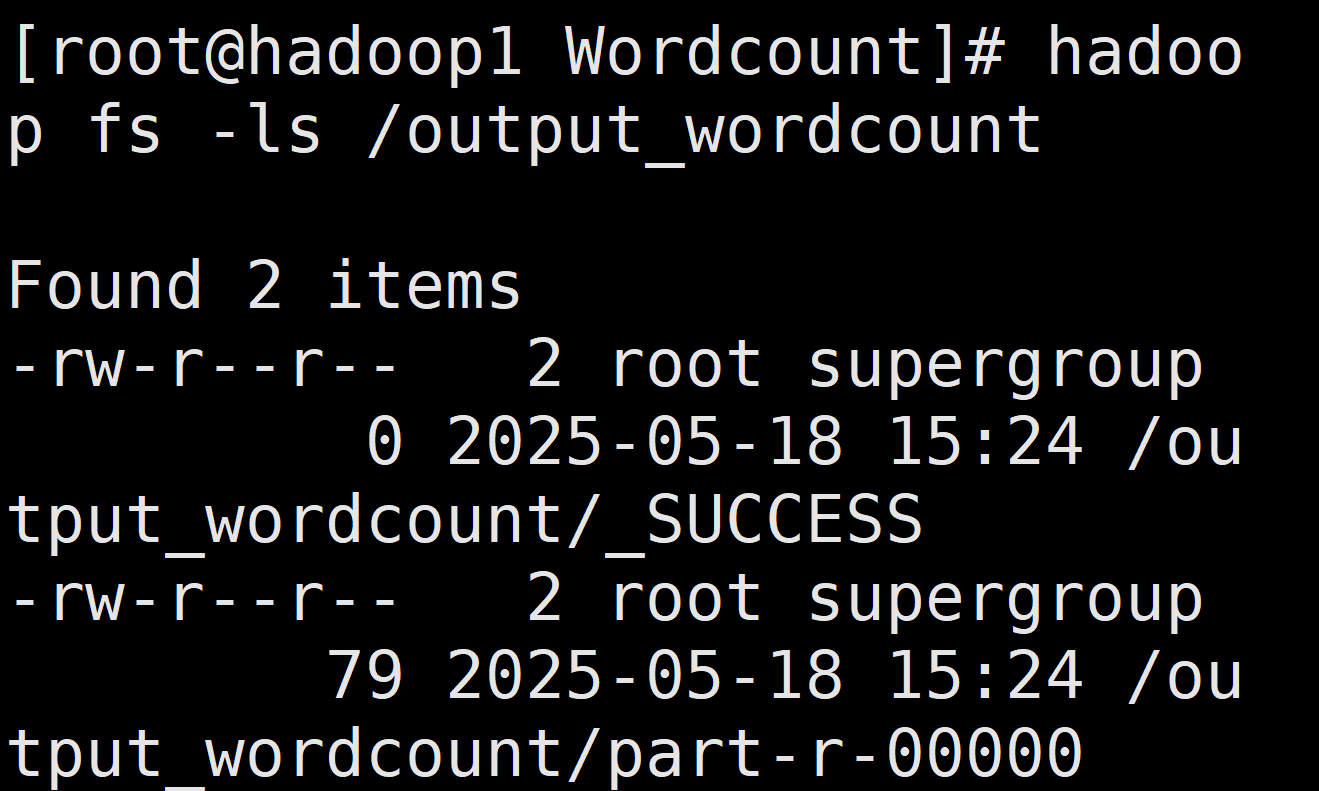
查看结果
bash
hadoop fs -cat /output_wordcount/part-r-00000