机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- [机器学习(Machine Learning)](#机器学习(Machine Learning))
- [机器学习之深度学习神经网络中 TensorFlow 初步代码实现学习笔记](#机器学习之深度学习神经网络中 TensorFlow 初步代码实现学习笔记)
机器学习之深度学习神经网络中 TensorFlow 初步代码实现学习笔记
一、引言
在机器学习蓬勃发展的今天,深度学习凭借强大的特征提取与模式识别能力,成为计算机视觉、自然语言处理等前沿领域的核心技术。而 TensorFlow 作为业界广泛应用的开源深度学习框架,以其灵活的架构和丰富的 API,为开发者构建神经网络模型提供了高效工具。
二、实例分析
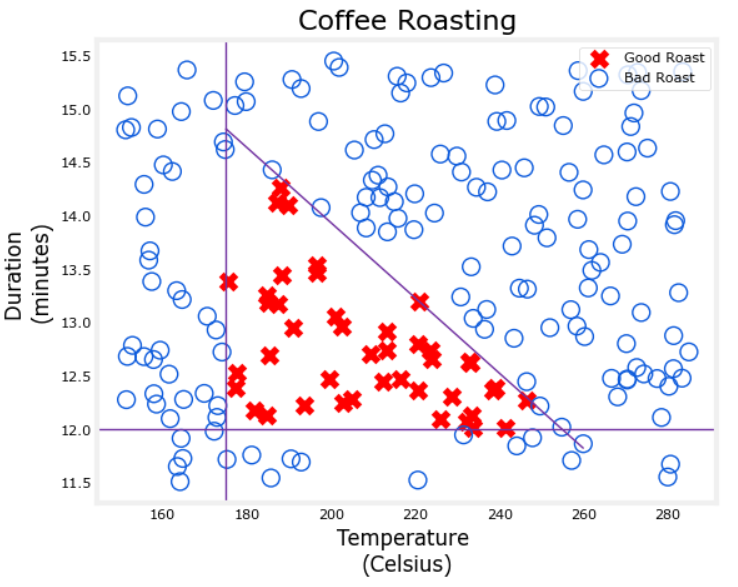
(一)咖啡烘焙程度预测模型
模型原理:该模型聚焦咖啡烘焙场景,以温度(Temperature)和烘焙时长(Duration)为核心特征,通过神经网络构建二维平面上的决策边界,将烘焙结果划分为烘焙不足(undercooked)、烘焙过度(overcooked)和优质咖啡(good coffee)三类。
数学表达 :设输入特征向量 x ⃗ = x 1 , x 2 \vec{x} = x_1, x_2 x =x1,x2,其中 x 1 x_1 x1 代表温度, x 2 x_2 x2 代表时长。经神经网络计算得到输出 a 1 2 a^{2}_1 a12 ,以阈值 0.5 0.5 0.5 为判断标准:当 a 1 2 ≥ 0.5 a^{2}_1 \geq 0.5 a12≥0.5 时,预测结果 y ^ = 1 \hat{y} = 1 y^=1(优质咖啡);反之, y ^ = 0 \hat{y} = 0 y^=0 。
代码实现
python
import numpy as np
import tensorflow as tf
# 输入特征,形状为(1, 2),表示1个样本,2个特征
x = np.array([[200.0, 17.0]])
# 第一层全连接层,配置3个神经元,采用sigmoid激活函数,将输入映射到非线性空间
layer_1 = tf.keras.layers.Dense(units=3, activation='sigmoid')
a1 = layer_1(x)
# 第二层全连接层,单神经元输出,sigmoid激活后得到最终预测概率
layer_2 = tf.keras.layers.Dense(units=1, activation='sigmoid')
a2 = layer_2(a1)
# 根据预测概率进行类别判定
if a2 >= 0.5:
yhat = 1
else:
yhat = 0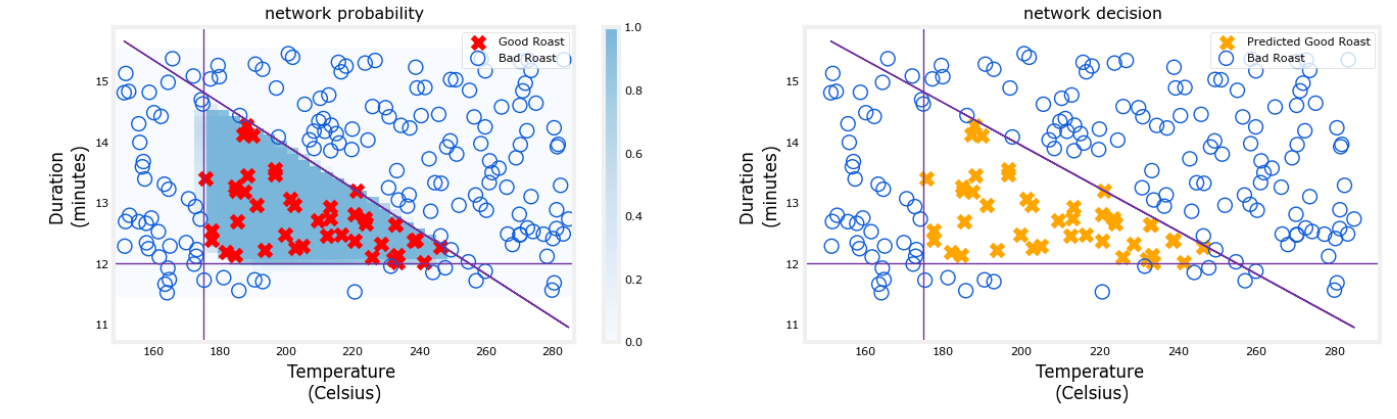
左图是蓝色阴影表示的最后一个图层的原始输出。这覆盖在 X 和 O 表示的训练数据上。
右图是决策阈值后网络的输出。这里的 X 和 O 对应于网络做出的决策。
(二)数字分类模型
模型结构 :构建一个包含三层的全连接神经网络,输入层接收特征向量 x ⃗ \vec{x} x ,依次经过 25 个神经元的第一层、15 个神经元的第二层,最终由单神经元的第三层输出分类结果。每层均采用 sigmoid 激活函数引入非线性。
数学公式 :设输入向量为 x ⃗ \vec{x} x ,各层输出分别为 a 1 a^{1} a1 、 a 2 a^{2} a2 、 a 3 a^{3} a3 。通过矩阵乘法与激活函数运算生成最终输出 a 1 3 a^{3}_1 a13 ,同样以 0.5 0.5 0.5 为阈值判断预测类别 y ^ \hat{y} y^ 。
代码实现
python
import numpy as np
import tensorflow as tf
# 输入特征,实际应用中需填充完整样本数据
x = np.array([[0.0,...,245,...,240,...0]])
# 第一层全连接层,25个神经元扩展特征维度
layer_1 = tf.keras.layers.Dense(units=25, activation='sigmoid')
a1 = layer_1(x)
# 第二层全连接层,进一步提炼特征
layer_2 = tf.keras.layers.Dense(units=15, activation='sigmoid')
a2 = layer_2(a1)
# 第三层全连接层,输出最终预测概率
layer_3 = tf.keras.layers.Dense(units=1, activation='sigmoid')
a3 = layer_3(a2)
# 预测结果判定
if a3 >= 0.5:
yhat = 1
else:
yhat = 0(三)numpy 数组相关要点
在 TensorFlow 开发中,numpy 数组是处理数据的重要载体,其创建方式与形状特性对模型输入输出影响显著:
| 创建方式 | 示例代码 | 数组形状 | 说明 |
|---|---|---|---|
| 标准二维数组 | x = np.array([[1, 2, 3], [4, 5, 6]]) |
2 × 3 2 \times 3 2×3 | 构建 2 行 3 列的矩阵,常用于批量样本特征存储 |
| 多样本特征数组 | x = np.array([[0.1, 0.2], [-3.0, -4.0], [-0.5, -0.6], [7.0, 8.0]]) |
4 × 2 4 \times 2 4×2 | 表示 4 个样本,每个样本含 2 个特征 |
| 单行样本数组 | x = np.array([[200, 17]]) |
1 × 2 1 \times 2 1×2 | 单样本双特征,需保持二维结构适配模型输入 |
| 单列特征数组 | x = np.array([[200], [17]]) |
2 × 1 2 \times 1 2×1 | 常用于表示含 2 个样本的单特征数据 |
| 一维向量 | x = np.array([200,17]) |
一维 | 本质为向量,在特定场景下需转换为二维结构 |
(四)激活向量相关
以咖啡烘焙模型第二层计算为例,深入理解激活向量机制:
-
层定义 :
layer_2 = Dense(units=1, activation='sigmoid')构建单神经元输出层,sigmoid 函数将输出值域压缩至 (0, 1) 区间,便于概率解释。 -
激活计算 :
a2 = layer_2(a1)基于上一层输出 a 1 a^{1} a1 计算当前层激活向量 a 2 a^{2} a2 。假设输出为 a 2 = \[ 0.8 ] a^{2} = \[0.8] a2=\[0.8] ,其形状为 ( 1 , 1 ) (1, 1) (1,1) ,在 TensorFlow 中以tf.Tensor类型存储。如需与 numpy 协同处理,可调用a2.numpy()转换为 numpy 数组。
三、总结
通过咖啡烘焙预测与数字分类两个典型案例,我们系统学习了 TensorFlow 构建神经网络的基础流程,涵盖数据输入处理、网络层搭建、激活函数应用及结果判定。同时,掌握了 numpy 数组在数据组织中的关键作用,以及激活向量的计算与数据类型转换。
continue...