目录
2.std::list::remove和std::list::remove_if的使用
3.1std::list::unique的第二个函数的简单介绍
5.std::list::sort函数以及std::sort(list)的使用
[1. 输入迭代器 (input_iterator_tag)](#1. 输入迭代器 (input_iterator_tag))
[2. 输出迭代器 (output_iterator_tag)](#2. 输出迭代器 (output_iterator_tag))
[3. 前向迭代器 (forward_iterator_tag)](#3. 前向迭代器 (forward_iterator_tag))
[4. 双向迭代器 (bidirectional_iterator_tag)](#4. 双向迭代器 (bidirectional_iterator_tag))
[5. 随机访问迭代器 (random_access_iterator_tag)](#5. 随机访问迭代器 (random_access_iterator_tag))
[1. 序列容器 (Sequence Containers)](#1. 序列容器 (Sequence Containers))
[2. 关联容器 (Associative Containers)](#2. 关联容器 (Associative Containers))
[3. 无序关联容器 (Unordered Associative Containers)](#3. 无序关联容器 (Unordered Associative Containers))
std::unordered_set/std::unordered_multiset
std::unordered_map/std::unordered_multimap
[4. 容器适配器 (Container Adaptors)](#4. 容器适配器 (Container Adaptors))
[std::stack 和 std::queue](#std::stack 和 std::queue)

1.std::list::splice的使用
该函数是list新增的一个函数,所以需要进行额外的奖金:

splice这个函数翻译过来是:拼接、粘接的意思,也就是说可以在该list对象的position位置粘接一部分东西,但是它必须是另外一个list对象的一部分或者全部,这里是它的每个函数的用法简介:

所以说这个函数的功能还是比较多的,但是这个位置position我们需要注意:这个position我们不能直接和vector和string那样写的,所以我们如果拼接数据不是在头部或者尾部的情况下我们不能用l1.begin()+n的方式,因为这种方式是没定义的。我们可以用之前我们学过的insert的那种方式,这里讲解一下如何使用:
第一个函数的使用:
cpp
//splice函数的使用
int main()
{
list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });
list<int> l2({ 6,3,1,8,0 });
cout << "l1粘接之前:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2粘接之前:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
//(1)
//不能这样写
//l2.splice(l1.begin() + 1, l1);
//要这样写
auto i1 = std::next(l1.begin(), 1);
l1.splice(i1, l2);
cout << "l1第一次粘接之后:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2第一次粘接之后:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么最终运行结果为:
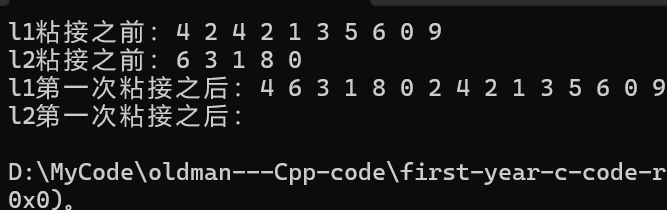
但是如果我们想要插入尾结点那么就不能l1.end()了,因为
l1.end() 是指向 尾后位置(one-past-the-last element) 的迭代器,它并不指向任何实际元素。根据C++标准:
-
splice函数的第三个参数(要剪切的元素位置)必须指向一个有效的元素 -
end()迭代器不指向任何实际元素,因此不能用于剪切操作
所以我们如果想插入尾结点不能直接l1.end(),而应该提前一个才是:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//splice函数的使用2
int main()
{
list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });
list<int> l2({ 6,3,1,8,0 });
cout << "l1粘接之前:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2粘接之前:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
//(2)
//或者
auto i2 = l2.begin();
//l2的第四个位置粘接
std::advance(i2, 3);
//错误
//l2.splice(i2, l1, l1.end());
//正确
l2.splice(i2, l1, std::prev(l1.end()));
cout << "l1第二次粘接之后:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2第二次粘接之后:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么最终运行结果为:
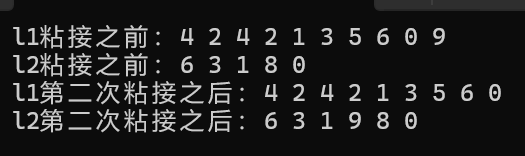
第三个函数的用法如下:
cpp
//splice函数的使用3
int main()
{
list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });
list<int> l2({ 6,3,1,8,0 });
cout << "l1粘接之前:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2粘接之前:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
//(3)
//也可以
auto i3 = l2.begin();
//在l2的第四个位置开始粘接
std::advance(i3, 3);
l2.splice(i3, l1, l1.begin(), l1.end());
cout << "l1第三次粘接之后:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
cout << "l2第三次粘接之后:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么最终运行结果如下:
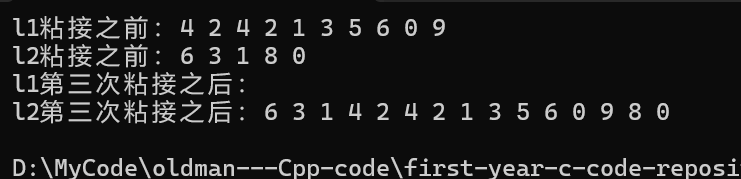
为什么这次没报错,因为:
-
splice的范围版本接受的是 [first, last) 半开区间 -
标准明确规定
last可以是end()迭代器 -
这表示"从 first 开始到容器末尾的所有元素"
而且基本上迭代器的last指针通常是不插入这个位置的数据的(可能没有数据)。
可以看到:splice函数看似简单,但是我们需要注意的地方还是比较多的,我们还是要注意它的用法,否则很容易报错,而且我们在写i1、i2的时候我们要注意如果i1指向l1的结点,那么就是l1.splice(i1,......),不然可能会报错(自己粘接自己),如果是粘接一段迭代器区间,那么可以自己粘接自己!
2.std::list::remove和std::list::remove_if的使用

这个函数也是在list容器中新增的一个函数,所以需要额外介绍一下它用法,我们来看一下它的用法:

也就是说它可以删除值为val的所有结点,在该函数的介绍中也能了解它的很多东西,所以这里就不做解释了。

这个函数我们又有些看不懂了,如果按照正常思维,我们也应该是满足值为val且满足pred的条件就可以了,为什么这个是模板?我们来看一下它的介绍:

这个函数我们还是没看懂它如何用的,那我们还是问一下deepseek吧!(以下是deepseek的生成结果,如果不想看的话可以跳到2.2)
2.1remove_if函数的简单介绍
std::list::remove_if 是 C++ STL 中 list 容器的一个成员函数,用于根据特定条件移除列表中的元素。
基本用法
cpp
#include <list>
#include <iostream>
int main() {
std::list<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 移除所有偶数
numbers.remove_if([](int n) { return n % 2 == 0; });
// 输出结果: 1 3 5 7 9
for (int n : numbers) {
std::cout << n << " ";
}
return 0;
}函数原型
cpp
template <class Predicate>
void remove_if(Predicate pred);-
red: 一元谓词(接受一个元素作为参数并返回 bool 的函数或函数对象) -
返回类型: void(直接修改原列表)
使用函数对象作为谓词
cpp
struct IsGreaterThan {
int value;
IsGreaterThan(int v) : value(v) {}
bool operator()(int n) const { return n > value; }
};
int main() {
std::list<int> numbers = {5, 12, 3, 8, 15, 7};
// 移除所有大于10的元素
numbers.remove_if(IsGreaterThan(10));
// 输出结果: 5 3 8 7
for (int n : numbers) {
std::cout << n << " ";
}
return 0;
}使用普通函数作为谓词
cpp
bool isNegative(int n) {
return n < 0;
}
int main() {
std::list<int> numbers = {-2, -1, 0, 1, 2, -3};
// 移除所有负数
numbers.remove_if(isNegative);
// 输出结果: 0 1 2
for (int n : numbers) {
std::cout << n << " ";
}
return 0;
}注意事项
-
remove_if会遍历整个列表,时间复杂度为 O(n) -
被移除的元素会被销毁,内存被释放
-
与
std::remove_if算法不同,list 的成员函数remove_if会真正删除元素,而不只是移动元素 -
在遍历过程中修改列表是安全的,因为这是 list 的特性
复杂对象示例
cpp
#include <list>
#include <string>
struct Person {
std::string name;
int age;
};
int main() {
std::list<Person> people = {
{"Alice", 25},
{"Bob", 17},
{"Charlie", 30},
{"David", 16}
};
// 移除所有未成年人(年龄<18)
people.remove_if([](const Person& p) { return p.age < 18; });
// 剩下的都是成年人
for (const auto& p : people) {
std::cout << p.name << " (" << p.age << ")\n";
}
return 0;
}std::list::remove_if 是一个高效的方式来根据条件删除 list 中的元素,特别适合与 lambda 表达式结合使用。
2.2remove与remove_if的简单使用
在刚刚的remove_if的众多用法中我们只要掌握最基本的用法即可,建议还是传递一个返回值为bool的进去。简单来说就是remove_if能删除链表中若把链表所存储的值代入结果为true的值,所以remove_if函数在之后的用法还是比较多的,至于那个基本用法中的\[\]......我们暂时用这种方式即可,它是Lambda表达式,这个感兴趣的可以去搜索资料。
那么我在这里演示一下两个函数的用法,两个函数都是删除链表中的一些元素:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//remove和remove_if的使用
bool isou(int a)
{
return a % 2 == 0;
}
int main()
{
//remove
list<int> l1({ 4,2,4,6,76,3,2,1,9,0,3,5 });
cout << "remove之前:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
l1.remove(3);
cout << "remove之后:";
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
//remove_if
list<int> l2({ 2,4,6,3,1,7,9,0,8,5,7 });
cout << "remove_if之前:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
l2.remove_if(isou);
cout << "remove_if之后:";
for (const auto& e : l2)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么最终运行结果为:
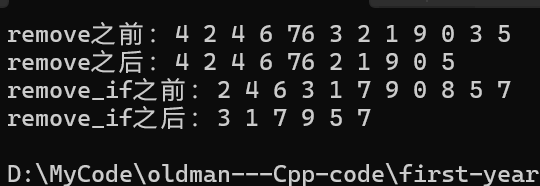
3.std::list::unique的使用

unique也是在string和vector之后新增的一个函数,我们可以通过它函数名的意思知道这个函数大概是什么意思,这个函数的意思是单独的,那么来看一下它的介绍吧:

也就是说它可以删除连续的重复的元素,然后使每个结点与它的前后结点(除只有一个结点外)所存的值都不相同,这个函数也经常结合sort函数即排序后使用,所以这是第一个函数的用法;第二个函数和remove_if差不多,但是也有些不同,以下是deepseek的搜索结果:
3.1std::list::unique的第二个函数的简单介绍
std::list::unique 的带谓词版本允许你自定义判断相邻元素是否"唯一"的标准,而不仅仅是简单的相等比较。
基本语法
cpp
template <class BinaryPredicate>
void unique(BinaryPredicate binary_pred);-
binary_pred:一个二元谓词(接受两个元素作为参数并返回 bool 的函数或函数对象) -
功能:移除所有满足
binary_pred的连续重复元素
基本示例
cpp
#include <list>
#include <iostream>
int main() {
std::list<int> numbers = {1, 2, 2, 3, 4, 4, 4, 5, 6, 6, 7};
// 使用默认比较(operator==)
numbers.unique();
// 结果:1, 2, 3, 4, 5, 6, 7
// 使用自定义谓词 - 当两数差的绝对值小于等于1时视为相同
numbers = {1, 2, 4, 5, 7, 8, 10};
numbers.unique([](int a, int b) { return std::abs(a - b) <= 1; });
// 结果:1, 4, 7, 10
return 0;
}使用函数对象作为谓词
cpp
struct AreConsecutive {
bool operator()(int a, int b) const {
return b == a + 1;
}
};
int main() {
std::list<int> nums = {1, 2, 4, 5, 7, 8, 10};
nums.unique(AreConsecutive());
// 移除后一个元素是前一个元素+1的相邻元素
// 结果:1, 4, 7, 10
return 0;
}处理自定义类型
cpp
struct Person {
std::string name;
int age;
bool operator==(const Person& other) const {
return name == other.name && age == other.age;
}
};
int main() {
std::list<Person> people = {
{"Alice", 25},
{"Alice", 25}, // 重复
{"Bob", 30},
{"Bob", 31}, // 不同
{"Charlie", 40},
{"Charlie", 40} // 重复
};
// 移除姓名和年龄完全相同的连续记录
people.unique();
// 剩余: Alice(25), Bob(30), Bob(31), Charlie(40)
// 自定义谓词 - 只比较姓名
people.unique([](const Person& a, const Person& b) {
return a.name == b.name;
});
// 剩余: Alice(25), Bob(30), Charlie(40)
return 0;
}注意事项
-
只移除连续重复项 :
unique只检查相邻元素,不相邻的重复元素不会被移除cppstd::list<int> nums = {1, 2, 1, 2, 1}; nums.unique(); // 不会有任何变化,因为没有连续重复 -
谓词要求:谓词应该是等价关系(自反、对称、传递的)
-
排序后再使用:如果需要移除所有重复项(不仅是连续的),应先排序
cppstd::list<int> nums = {1, 2, 1, 2, 1}; nums.sort(); nums.unique(); // 结果: 1, 2 -
性能:时间复杂度为 O(n),因为 list 的迭代器是双向的
-
与
std::unique的区别:-
std::list::unique是成员函数,真正删除元素 -
std::unique是算法,只移动元素到容器末尾,不改变容器大小
-
这个带谓词的 unique 版本提供了极大的灵活性,让你可以定义什么样的元素应该被视为"重复"的。
3.2std::list::unique函数的使用
第二个重载的函数的参数与remove_if函数的不同就是:它所需要传的参数需要两个,因为这样才满足需要删除的条件是什么,才好进行删除。至于:

这个需要自己去搜索结果了,这里没办法细讲!
知道了这么多,我在这里演示一下两个函数的用法:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//unique的使用
bool panduan(int a, int b)
{
//判断绝对值是否小于2
//小于2则认为相同
return abs(a - b) < 2;
}
int main()
{
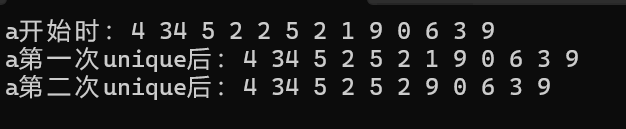
list<int> a({ 4,34,5,2,2,5,2,1,9,0,6,3,9 });
cout << "a开始时:";
for (const auto& e : a)
{
cout << e << " ";
}
cout << endl;
a.unique();
cout << "a第一次unique后:";
for (const auto& e : a)
{
cout << e << " ";
}
cout << endl;
a.unique(panduan);
cout << "a第二次unique后:";
for (const auto& e : a)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么运行结果为:
4.std::list::merge的使用

该函数还是list新增的一个函数,这里我们先看一下它的介绍:

这个函数用得很少,在这里就只演示用法即可(第一个是默认排成升序的,第二个是可以排成降序的):
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//merge的使用
int main()
{
list<int> l1({ 3,4,52,5,1,9,90,8,7,3 });
list<int> l2({ 4,2,4,6,2,1,8,0,2,6 });
//先排序
l1.sort();
l2.sort();
//(1)
//再merge
//merge后仍然是有序的
l1.merge(l2);
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
//(2)
list<int> l3({ 5,6,3,2,4,9,20,97 });
//排成降序不能这样写
//l3.sort();
//我们想要排成降序就这样写(了解基本用法,之后会讲)
greater<int> gt;
//sort函数等下讲
l3.sort(gt);
l1.sort(gt);
//第二个参数还是要加上的!
l1.merge(l3, gt);
for (const auto& e : l1)
{
cout << e << " ";
}
cout << endl;
return 0;
}那么运行结果为:

5.std::list::sort函数以及std::sort(list)的使用

这个函数第一个是排成升序,第二个是排成降序,但是我们第二个函数的参数现阶段只要知道用这种方式即可:greater<int> gt;l1.sort(gt);但是记得gt的类型也要和l1一样。

这个函数也是专门针对list设计的swap函数,这个就是为了防止之后我们调用了算法库里面的函数,这个可以见我的string的模拟实现4的博客!
这个函数就不讲解它的用法了,我在这里只讲解为什么我们不用算法库里面的sort函数?
这个其实涉及到迭代器的继承关系,其中子类时特殊的父类,而在算法库的sort函数的参数是RandomAccessIterator,是最特殊的子类,只能传递随机迭代器。
6.C++迭代器(非常重要)
我在这里讲解的继承关系现在只是皮毛!!!因为这涉及到子父类的继承关系,这些将会在C++的继承博客中进行更详细讲解,这里我们只要在平常别乱用容器本身的迭代器与算法库里面的迭代器即可:
我们在C++官网中搜索:iterator,则会有:

这5个迭代器是以下迭代器:

我们是看不懂这个箭头的,也是很难理解的,我们只要知道这些分类即可。
所以以下是deepseek对它们比较简单的讲解:
这五个迭代器类别代表了C++中迭代器的不同能力和层级关系,它们构成了一种继承层次结构,从功能简单到功能强大依次是:
1. 输入迭代器 (input_iterator_tag)
-
能力:只读、单向
-
支持操作:
-
++(前缀和后缀) -
*(解引用,只能读取) -
==/!=比较
-
-
典型用途 :从数据流中读取数据(如
istream_iterator) -
限制:只能单次遍历,不能回退
2. 输出迭代器 (output_iterator_tag)
-
能力:只写、单向
-
支持操作:
-
++(前缀和后缀) -
*(解引用,只能写入)
-
-
典型用途 :向数据流写入数据(如
ostream_iterator) -
限制:不能读取,不能回退,通常只能单次遍历
3. 前向迭代器 (forward_iterator_tag)
-
能力:可读可写、单向
-
支持操作:
-
包含输入迭代器的所有功能
-
可以多次遍历同一序列
-
-
典型用途 :单向链表(如
std::forward_list的迭代器) -
特点:比输入/输出迭代器更强,支持多遍遍历
4. 双向迭代器 (bidirectional_iterator_tag)
-
能力:可读可写、双向移动
-
支持操作:
-
包含前向迭代器的所有功能
-
--(前缀和后缀,可以回退)
-
-
典型用途 :双向链表(如
std::list的迭代器) -
特点:可以向前和向后移动
5. 随机访问迭代器 (random_access_iterator_tag)
-
能力:可读可写、随机访问
-
支持操作:
-
包含双向迭代器的所有功能
-
+/-整数(跳跃式移动) -
[]下标访问 -
<,>,<=,>=比较
-
-
典型用途 :数组/向量(如
std::vector、std::array的迭代器) -
特点:功能最强大的迭代器类型
6.每个容器所对应的迭代器以及注意事项
以下是deepseek的搜索结果:
面是C++标准库中主要容器及其对应的迭代器类别:
1. 序列容器 (Sequence Containers)
std::array
-
迭代器类别 :随机访问迭代器 (
random_access_iterator_tag) -
说明 :支持所有随机访问操作,包括
+、-、[]等
std::vector
-
迭代器类别 :随机访问迭代器 (
random_access_iterator_tag) -
说明:与数组类似,支持高效随机访问
std::deque (双端队列)
-
迭代器类别 :随机访问迭代器 (
random_access_iterator_tag) -
说明:虽然内部结构比vector复杂,但仍提供随机访问能力
std::list (双向链表)
-
迭代器类别 :双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
支持
++和--操作 -
不支持随机访问(不能使用
+、-或[])
-
std::forward_list (单向链表)
-
迭代器类别 :前向迭代器 (
forward_iterator_tag) -
说明:
-
只支持
++操作 -
不支持
--操作
-
2. 关联容器 (Associative Containers)
std::set/std::multiset
-
迭代器类别 :双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
元素已排序
-
支持双向遍历
-
std::map/std::multimap
-
迭代器类别 :双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
键值对已按键排序
-
支持双向遍历
-
3. 无序关联容器 (Unordered Associative Containers)
std::unordered_set/std::unordered_multiset
-
迭代器类别 :前向迭代器 (
forward_iterator_tag) -
说明:
-
元素无序存储
-
只支持单向遍历
-
std::unordered_map/std::unordered_multimap
-
迭代器类别 :前向迭代器 (
forward_iterator_tag) -
说明:
-
键值对无序存储
-
只支持单向遍历
-
4. 容器适配器 (Container Adaptors)
std::stack 和 std::queue
-
迭代器类别:不提供迭代器
-
说明:这些适配器专门设计为限制访问模式,不支持迭代
特殊迭代器
std::string
-
迭代器类别 :随机访问迭代器 (
random_access_iterator_tag) -
说明 :行为与
std::vector<char>类似
std::string_view
-
迭代器类别 :随机访问迭代器 (
random_access_iterator_tag) -
说明:提供对字符串的视图,支持随机访问
迭代器类别对算法的影响
不同算法对迭代器有不同要求:
-
需要随机访问迭代器的算法:
-
std::sort -
std::binary_search -
std::nth_element
-
-
需要双向迭代器的算法:
-
std::reverse -
std::unique(带谓词版本) -
std::list::sort(成员函数)
-
-
只需要前向迭代器的算法:
-
std::search -
std::adjacent_find
-
-
只需要输入迭代器的算法:
-
std::find -
std::count -
std::accumulate
-
7.简单解释
这个迭代器的分类对我们之后是用算法库里面的函数还是用容器的函数都有很多注意的地方,比如:我们不能用算法库的sort,因为list是双向迭代器即:bidirectional_iterator_tag。这个迭代器可以支持++、---的操作,但是不支持+、-的操作,因此若用算法库里面的可能会导致有些问题。
对于如何理解父子类的继承行为,我们可以认为:子类是特殊的父类,父类有的特征子类都有,我们若把子类认为是正方形,父类是长方形,这个就很容易理解了。
所以在用每个算法库里面的函数的时候还是要注意它的迭代器的类别:
如果有迭代器类型的参数且类型是Input_Iterator那么我们就只可读,也就是说只能传递Input类别的迭代器;同理对于参数是Output_Iterator类别的,那么就只能传递Output类别的迭代器;如果是单向迭代器,那么就能传递Input_Iterator、Output_Iterator和单向迭代器;如果是双向迭代器,那么可以传递除随机迭代器外的所有迭代器;如果参数类型是随机迭代器,那么就可以传递任意类型的迭代器!
我按照常用的容器,给出大概分类:vector、string、deque是随机迭代器;list、map、set是双向迭代器、forward_list、unodered_map、unordered_set是单向迭代器。
所以算法库里面的sort函数是不能用来进行list的排序的!所以我们要注意!
7.总结
list的重要函数的使用已经全部讲完了,那些比较运算符的重载、逆置函数、得到一个迭代器这些都不重要,就不讲解了,我们主要是要懂得每个函数所对应的用法,已经一些注意事项。这个我用deepseek的也是比较多,因为我自己学的不是很深入,如果照着笔记讲还不如不写博客,所以我觉得还是用deepseek更全面一些,也方便我之后复习用!
好了,C++list的使用就到这里了,下讲将讲解:list的底层。不过下讲内容可能需要下周去了,因为这周四天更新了这是第8篇了,身体有些吃不消了,已经赶得上我的笔记内容了。
喜欢的可以一键三连哦,下讲再见!
