欢迎来到啾啾的博客🐱。
记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。
欢迎评论交流,感谢您的阅读😄。
目录
- 引言
- Kafka与消息
-
- 生产者发送消息到Kafka
- 消息在Kafka的存储
-
- [Kafka Cluster\Broker\Topic\Partition](#Kafka Cluster\Broker\Topic\Partition)
- 消息怎么过期(移除)
- 消息者消费消息
- Kafka为什么快
引言
在上一篇【Java微服务组件】异步通信P1---消息队列基本概念中已经简单介绍了MQ。
目前主流的消息队列应该就是Kafka与RocketMQ了。在RocketMQ官网中有讲解其与Kafka的区别,如下:
| 消息产品 | 客户端 SDK | 协议与规范 | 顺序消息 | 定时消息 | 批量消息 | 广播消息 | 消息过滤 | 服务端触发重投递 | 消息存储 | 消息回溯 | 消息优先级 | 高可用与故障转移 | 消息轨迹 | 配置方式 | 管理与运维工具 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kafka | Java, Scala 等 | 拉模型 (Pull Model), 支持 TCP 协议 | 保证分区内消息有序 | 不支持 | 支持, 通过异步生产者实现 | 不支持 | 支持, 可使用 Kafka Streams 进行消息过滤 | 不支持 | 高性能文件存储 | 支持, 通过偏移量 (offset) 定位 | 不支持 | 支持, 依赖 ZooKeeper 服务 | 不支持 | Kafka 使用键值对格式进行配置。这些值可以通过文件或编程方式提供。 | 支持, 使用终端命令暴露核心指标 |
| RocketMQ | Java, C++, Go | 拉模型 (Pull Model), 支持 TCP, JMS, OpenMessaging 协议 | 保证严格顺序消息, 且能优雅地水平扩展 | 支持 | 支持, 通过同步模式避免消息丢失 | 支持 | 支持, 基于 SQL92 的属性过滤表达式 | 支持 | 高性能、低延迟文件存储 | 支持, 通过时间戳和偏移量 (offset) 两种方式定位 | 不支持 | 支持, 主从模型, 无需额外组件 | 支持 | 开箱即用, 用户只需关注少量配置 | 支持, 丰富的 Web 界面和终端命令暴露核心指标 |
但今天我们还是先深入了解Kafka的设计与功能。因为Kafka快。
资料引用自《Kafka权威指南》、https://developer.confluent.io/courses/architecture/broker/
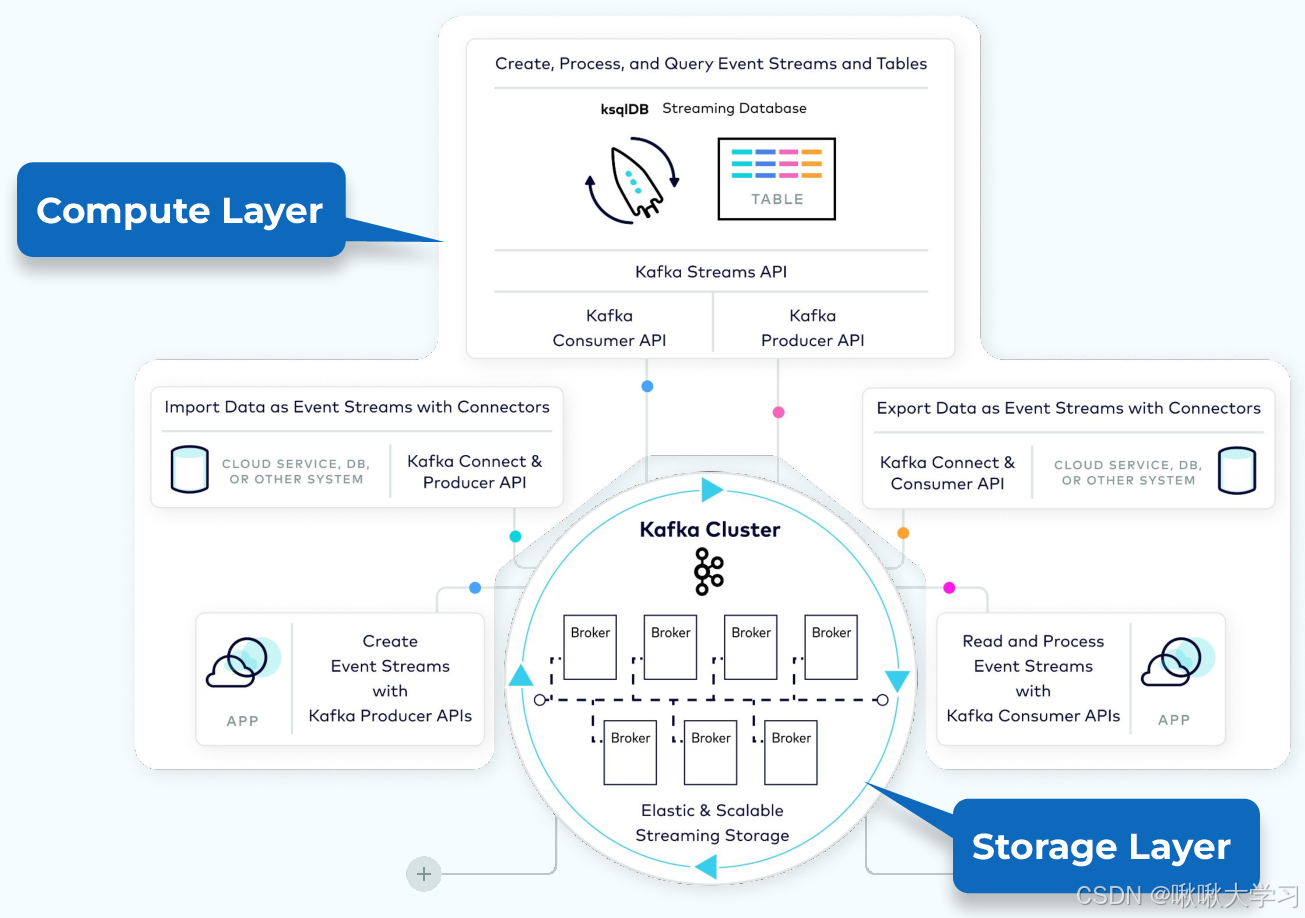
Kafka与消息
生产者发送消息到Kafka
怎么可靠、高效地发送消息到Kafka呢?
批处理发送设计
如果每一条消息都单独穿行于网络中,那么就会导致大量的网络开销,把消息分成批次传输可以减少网络开销。
所以,Kafka Producer 的核心设计之一就是客户端批处理。生产者会将多条消息收集到一个批次 (Batch) 中,然后一次性将整个批次发送给对应的Broker。
为此,Kafka Producer 内部有一个缓冲区 (Accumulator / RecordAccumulator)。消息在缓冲区按照目标的Topic-Partition进行组织,满足以下任一条件后随批次发送给Broker:
- batch.size: 某个批次的消息累积大小达到了配置的 batch.size(默认16KB)。
- linger.ms : 距离该批次第一条消息进入缓冲区的时间超过了配置的 linger.ms(默认0ms,但实际中为了启用批处理,通常会设置一个大于0的值,比如5ms, 10ms)。即使批次未满 batch.size,到达 linger.ms 后也会发送,以避免消息在缓冲区停留过久导致延迟。
- producer.flush()被调用: 应用程序显式要求将所有缓冲区的消息立即发送。
- producer.close()被调用: 在关闭生产者之前,会确保所有缓冲区的消息都被发送出去。
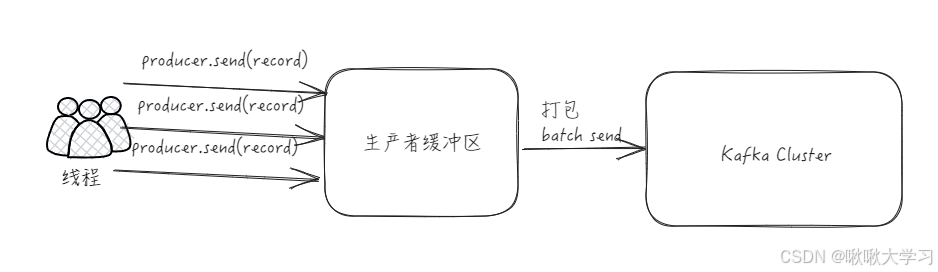
批处理设计通过牺牲一点点单条消息的即时性,节省网络开销(TCP/IP开销、传输数据量)、磁盘开销,从整体提升消息吞吐量、网络效率、资源利用率。
对于大多数高吞吐量的消息系统场景来说,这样做是非常值得的。
消息的幂等信息
Q:怎么保证Kafka存储(收到)的消息是唯一的?
从 Kafka 3.0.0 版本开始,Kafka 生产者内置了幂等性支持。幂等可以防止因Broker未及时响应ack导致消息在Broker重复存储。
配置默认为true。
yaml
spring.kafka.producer.enable-idempotence=true它通过为每个生产者分配一个唯一的生产者ID (PID) 和为发送到每个分区的每条消息分配一个序列号来实现。Broker 会跟踪这些 (PID, Partition, SequenceNumber) 组合,并丢弃重复的写入尝试。
需要注意的时,幂等启动时,除非用户显示配置了其他值,retries 会被设置为 Integer.MAX_VALUE,acks 会被设置为 all,max.in.flight.requests.per.connection 会被限制为 <= 5 (默认为5)。
确保消息送达
生产者发送消息的producer.send() 方法本身是异步的,它将消息放入生产者的发送缓冲区,并由一个后台线程负责批量发送(哪怕linger.ms 配置为0)。
生产者有以下方式来确保消息送达。
acks配置
这个参数决定了生产者在认为一个请求完成之前需要等待多少个 Broker 副本的确认。它有三个主要的值:
- acks=0
完全没有送达保证。 - acks=1
Leader确认后则认为送达。 - acks=all
Leader Broker 在自己写入并且所有ISR都向它报告已写入后,才向生产者发送确认响应。
一般配置acks=all,虽然会略微增加延迟,但数据不丢失通常是更重要的考量。
acks一般还与min.insync.replicas一起使用,min.insync.replicas默认值通常是1,这意味着只要有一个副本(包括leader副本)已经接收并同步了消息,就可以认为该消息是成功写入的。
所以配置acks=all时,一般推荐min.insync.replicas=2,即有两个副本同步了消息。
send()方法返回
producer.send(record) 方法会返回一个 java.util.concurrent.Future<RecordMetadata> 对象。常用的KafkaTemplate.send()则返回一个ListenableFuture<SendResult<K, V>>,两者都可以用于等待返回结果(阻塞或非阻塞)。
java
// 阻塞等待
try {
SendResult<String, String> result = kafkaTemplate.send("myTopic", "key", "value").get();
RecordMetadata metadata = result.getRecordMetadata();
log.info("Sent message to topic " + metadata.topic() +
" partition " + metadata.partition() +
" offset " + metadata.offset());
} catch (InterruptedException | ExecutionException e) {
// 处理发送失败,e.getCause() 通常是 KafkaException
log.error("Failed to send message: " + e.getMessage());
}
// 非阻塞
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("myTopic", "key", "value");
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
RecordMetadata metadata = result.getRecordMetadata();
log.info("Successfully sent message to topic " + metadata.topic() +
" partition " + metadata.partition() +
" offset " + metadata.offset());
}
@Override
public void onFailure(Throwable ex) {
// 处理发送失败
log.error("Failed to send message: " + ex.getMessage());
}
});retries配置
Kafka 生产者客户端内置了重试机制,用于处理可恢复的错误(如网络抖动、Leader 切换等)。
spring.kafka.producer.retries一般设置3或者5。
另外还有控制重试等待时间的spring.kafka.producer.properties.retry.backoff.ms。
控制producer.send() 和 producer.flush() 调用完成的总时间的spring.kafka.producer.properties.delivery.timeout.ms。这个时间包括消息在缓冲区等待的时间+网络传输时间+Broker确认时间+所有重试时间。如果超过这个时间,send()返回的Future会报超时。
默认的两分钟通常是够的。
yaml
spring.kafka.producer.retries=3
spring.kafka.producer.properties.retry.backoff.ms=1000 # 例如设置为1秒
spring.kafka.producer.properties.delivery.timeout.ms=120000
# 如果开启幂等性 (通常推荐)
spring.kafka.producer.enable-idempotence=true
# 当 enable-idempotence=true 时,retries 默认为 Integer.MAX_VALUE, acks 默认为 all
# max.in.flight.requests.per.connection 默认为 5消息在Kafka的存储
消息在Kafka是怎么存储的,怎么保证数据安全可靠?
Kafka Cluster\Broker\Topic\Partition
Cluster
一个 Kafka Cluster 由一个或多个 Broker 组成。这些 Broker 协同工作,提供消息的存储、读取和高可用性。
可以通过增加Broker来扩展集群的处理能力和存储容量。集群之间的数据共享(通信)早起是ZooKeeper,现在是KRaft控制器。
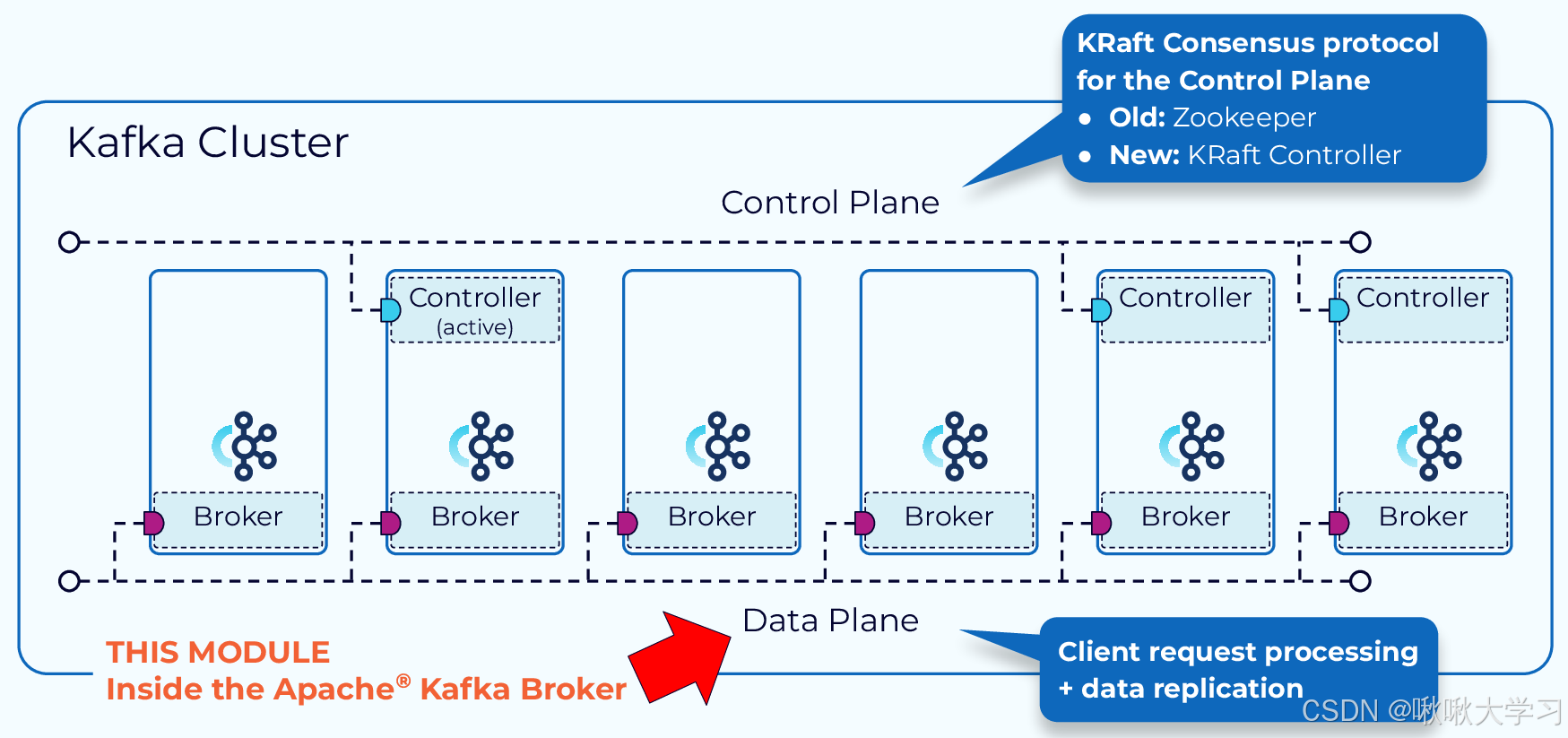
Broker
集群中的一个服务器实例就是一个Broker,每个Broker有唯一的数字ID。 Broker 负责接收来自生产者的消息,并将它们存储在磁盘上(以分区的形式)。
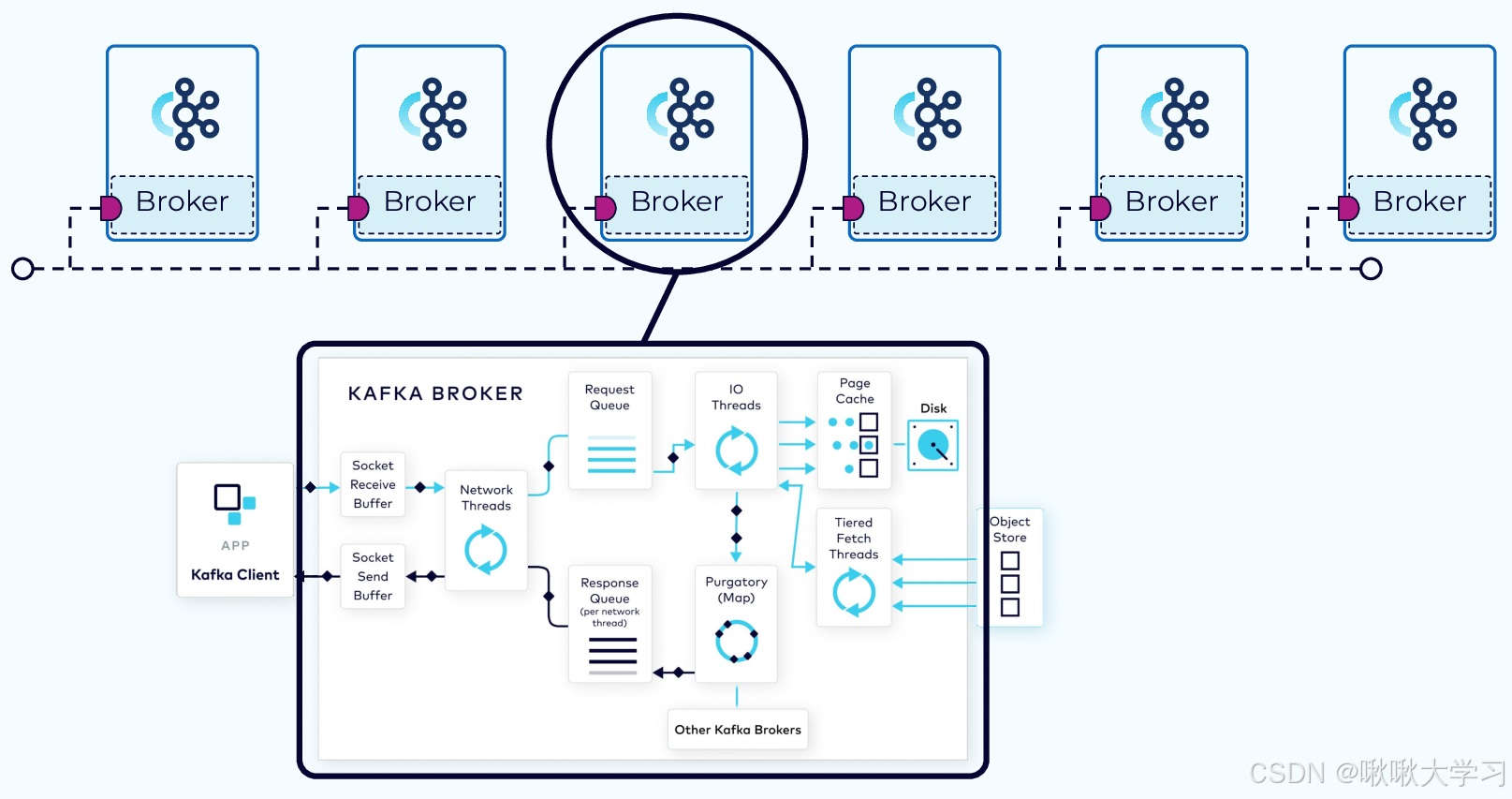
生产者请求到Broker后进入请求队列,然后由I/O线程验证并存储批次最后持久化到磁盘。
Kafka利用了操作系统本身的Page Cache,即,Kafka的读写操作基本上是基于系统内存的,读写性能得到了极大的提升。
同时,Broker使用了零拷贝技术,消费取消息时不走用户空间缓存区,数据从磁盘读取到内存空间page cache后,直接复制到socket缓冲区。避免了内核空间到用户空间的来回拷贝,也极大提升了性能。
集群中会有一个 Broker被选举为 Controller。Controller 负责管理集群的元数据,例如创建/删除 Topic、分区分配、Leader 选举等。
Broker的Leader-Follower只负责管理Kafka Cluster的集群元数据、监控Broker状态、执行管理操作、发起Leader选举。并不进行消息读写管理。
Topic/Partition
Kafka的消息通过Topic进行分类,生产者将消息发布到特定的 Topic,消费者订阅特定的 Topic 来消费消息。
Topic是一个逻辑概念,会通过分散到集群的多个Broker上。
Topic被分为若干个Partition,一个Partition就是一个提交日志。
- Partition日志
Partition日志并不是一个无限大的文件,而是一系列的日志短文件(LOg Segment Files)组成的。
一般用文件中第一条消息的offset命名,如00000000000000000000.log,00000000000000170123.log 等。
每个日志文件都有两个索引文件:偏移量索引与时间戳索引。- 偏移量索引 (.index): 存储相对偏移量(相对于该段的基准偏移量)到消息在 .log 文件中物理位置(字节偏移)的稀疏映射。这使得 Kafka 可以通过 Offset 快速定位到消息在日志段中的大致位置,然后顺序扫描一小段来找到确切的消息。
- 时间戳索引 (.timeindex): 存储时间戳到消息相对偏移量的稀疏映射。这使得 Kafka 可以通过时间戳快速定位到某个时间点附近的消息。
消息会以追加的方式被写入Partition,然后按照先入先出的顺序读取。一个Partition只能有一个Leader位于某个Broker上,且所有读写都在Leader上进行,其他Follower用于保障数据安全。
具体关系如下:
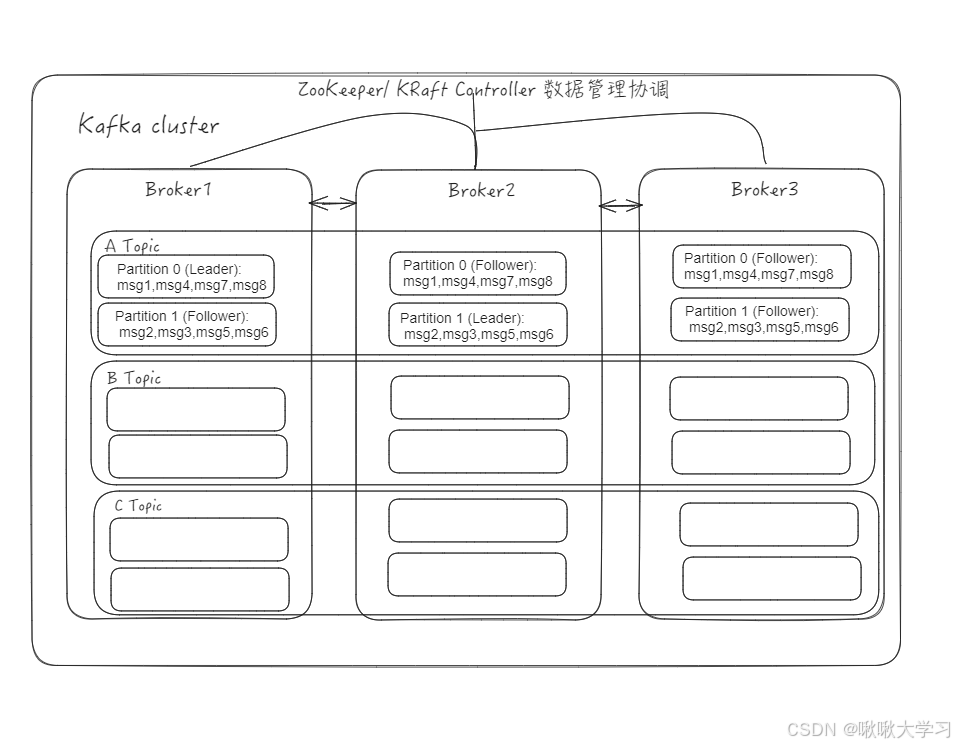
一个 Topic 的不同分区(及其副本)会分布到集群中的不同 Broker 上。Kafka可以保证消息在当前Partition的顺序。
Kafka Producer可以指定消息发送到哪个Topic,也可以指定到哪个Partition。没有指定Partition时,Kafka Producer会使用分区器 Partitioner来决定消息应该到哪个partition,策略以前是轮询,2.4版本后是"粘性分区"(简单来说就是先选一个分区一直发,然后换一个一直发)。
决定消息发往哪个Partition后,生产者会讲消息发给Partition中的Leader。然后Follower从Partition拉去信息同步进自己的文件中。
消费者也是连接Leader进行消费。
通常会把一个Topic的数据看成一个流。
数据冗余与分布式协调带来可靠
Kafka通过acks和min.insync.replicas配置防止消息发送失败,然后通过将数据冗余(数据副本)存放到多个 Follower Partition以及分布式共识选举机制来保障数据的可靠。
零拷贝和操作系统内存利用是高吞吐的核心
Kafka的读写操作基本上是基于系统内存的,读写性能得到了极大的提升。同时使用零拷贝技术,提升了消费的速率。
消息怎么过期(移除)
Kafka的数据过期(移除)和消费者是否消费完消息没有直接关系。消息移除主要由Topic级别配置的数据保留策略(Retention Policy)决定。
主要的数据保留策略如下:
- 基于时间
配置参数: retention.ms (毫秒) 或 retention.hours (小时) 或 retention.days (天,较老版本,retention.ms 更精确且优先)。
时间从消息写入开始算。 - 基于大小
配置参数: retention.bytes (字节)。每个Partition日志文件的最大总大小。
当一个 Partition 的日志文件总大小超过这个配置值时,Kafka 会从日志的最旧端开始删除消息段 (Log Segments),直到该 Partition 的大小回落到配置的限制以下。 - 日志压缩
配置参数: cleanup.policy=compact (默认是 delete)。
对于启用了日志压缩的 Topic,Kafka 会保留每个消息 Key 的最新版本的值。旧版本的消息(具有相同 Key 的旧值)会被删除。这主要用于构建状态存储、变更数据捕获 (CDC) 等场景,而不是传统的队列消息传递。
消息滞后风险
因此,kafka存在消息滞后风险,如果长时间没有消费消息,消息可能丢失。
因此,监控消费情况、设计兜底很重要。
消息者消费消息
Q:消费者该怎么消费?
A:Kafka限定消费者实例必须属于一个消费者组(有group.id)。
通常同一个消费者组内的所有实例应该订阅相同的Topic,让每个消费者组专注于自己需要处理的Topic集合。
java
consumer.subscribe(Collection<String> topics)不同的消费者组 消费消息表现得像发布-订阅模式。每个消费者组会独立跟踪自己的消费进度。
而在同一个 消费者组内部,一个 Topic 的一个 Partition 在同一时间只会被该组内的一个消费者实例消费。
为同组消费者实例分配不同Partition的机制是Rebalance 。机制有负载均衡的效果,将工作分散到多个实例上,提高整体的吞吐量。
所以设计上推荐消费者指定到具体的Topic即可,然后利用Rebalance机制提高吞吐。
即,消费者逻辑上属于一个消费组然后消费指定的Topic,且同一个消费者组内不同消费者消费不同Partition。
Q:消费者怎么确定消费倒哪了?
A:每个消费者组都会追踪自己订阅的Topic的自己的消费记录------偏移量。
每个消息都有一个整数偏移量。
消费者组在消费完消息后,会发送一个Offset Commit请求到Broker。由Broker记录消费者组消费到的最新偏移量(以前是zk)。
Kafka消费者采用的是拉模型 (Pull Model)。消费者根据自己的处理能力和节奏,向 Kafka Broker 发送 Fetch 请求来获取消息。
在拉取消息前,消费者需要向负责所属消费者的Broker(Group Coordinator)询问自己被分配了哪些Topic(尽管订阅指定了Topic,还是需要重新获取)和Partition,然后Broker返回之前消费到的最新偏移量。
消费者群组
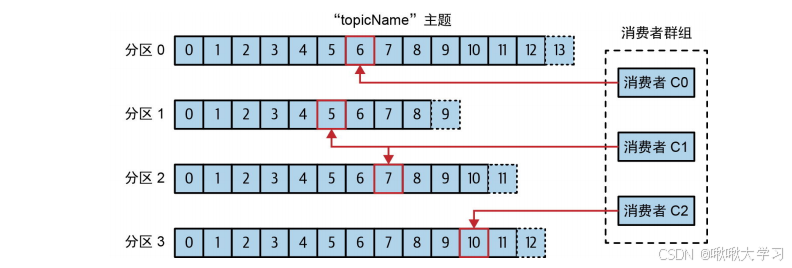
Kafka限定消费者实例必须属于一个消费者组(有group.id)。一个消费者组内的所有实例应该订阅相同的Topic,让每个消费者组专注于自己需要处理的Topic集合。
偏移量
偏移量:偏移量是一种元数据,不断递增的整数值。由Broker(Leader)在消息被成功写入Partition时,分配并添加到消息的元数据中,仅在当前Partition唯一。
消息的元数据有:offset、timestamp、key、partition 、Headers、topic
消费者会按照消息写入Partition的顺序读取消息,并通过检查消息的偏移量来区分已经读取过的消息。
消费者会定期或在消费完成后向 Kafka(或外部存储)提交(commit)它所消费的偏移量。
当消费者重启或因故障切换时,可以从上次提交的偏移量之后开始继续消费。
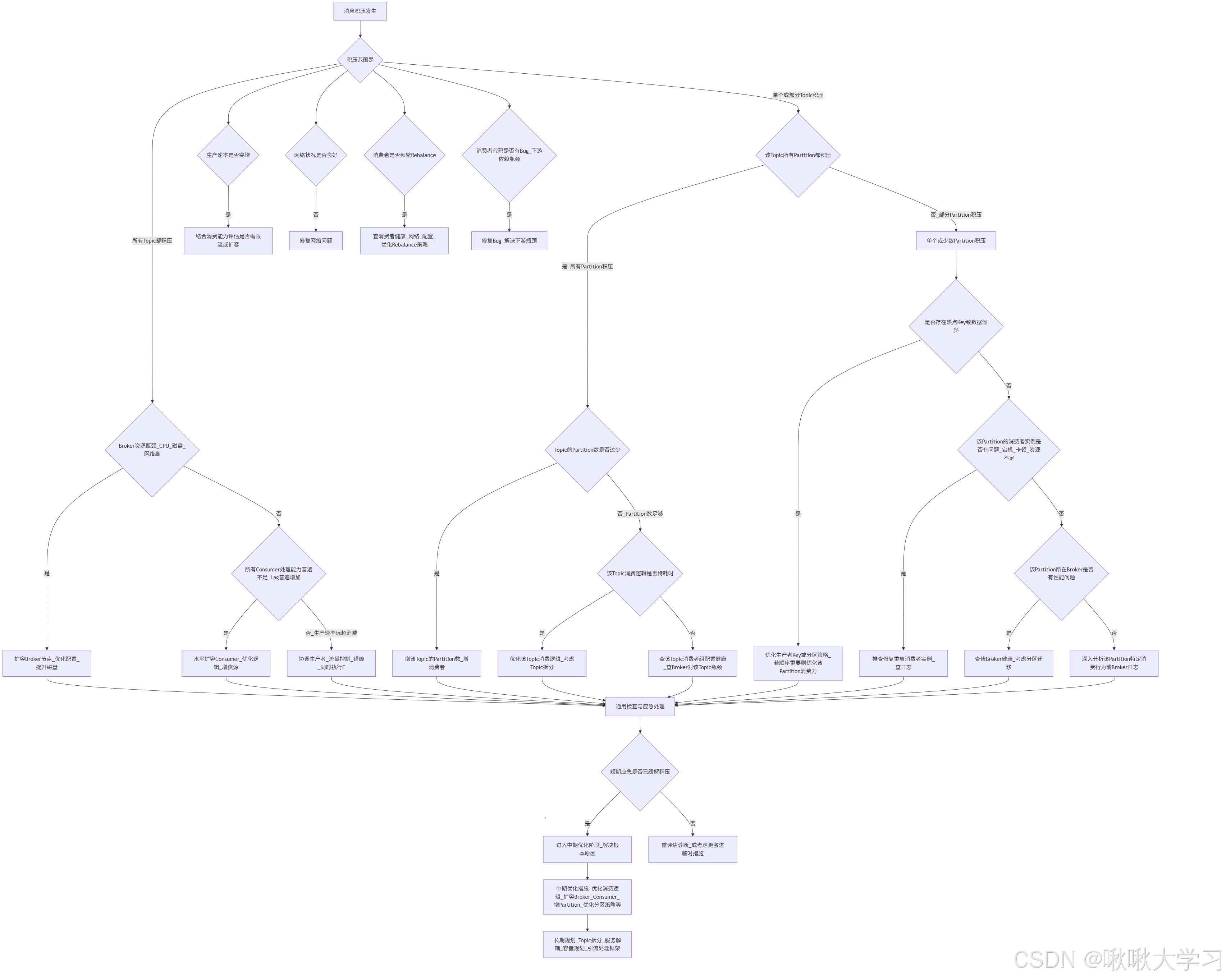
消息积压怎么处理
首先,检查消费速率,看是否消费者代码异常。
代码是否有bug,性能需要优化?
然后,检查生产者消息,是否消息过大?是否需要优化传输效率?
再然后,检查积压情况,看是怎么积压的?
积压情况关键指标------Consumer Lag (消费滞后量) :
表示某个 Partition 最新消息的 Offset 与消费者已提交 Offset 之间的差值。
如果是所有Topic都积压,则需要考虑扩容提Broker和Consumer。垂直扩容、水平扩容。
如果是单个Topic积压,则要从生产者做Topic、Partition的消费拆分。
单个Partition积压,则拆具体生产者消息。全部Partition积压,则拆Topic。
具体情况具体分析:
Kafka为什么快
-
发的快
设计有批量发送+与服务端轻量高效的通信协议,整体吞吐快。
-
存的快
利用了系统内存page cache+磁盘顺序读写,Kafka存的快。
-
消息取的快
文件分区分段且有索引+零拷贝,给消费者取消息取的快。