引言
在自然语言处理(NLP)领域,2018年Google推出的BERT(Bidirectional Encoder Representations from Transformers)框架无疑是一场革命。作为基于Transformer架构的双向编码器表示模型,BERT通过预训练学习丰富的语言表示,并在各种NLP任务中取得了显著的成绩。本文将详细介绍BERT的核心原理、技术特点以及实际应用。
一、BERT框架简介
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer编码器的预训练语言模型。与传统的单向语言模型(如GPT)不同,BERT采用双向结构,能够同时考虑文本中的上下文信息,从而更准确地捕捉语义特征。
1. 模型结构
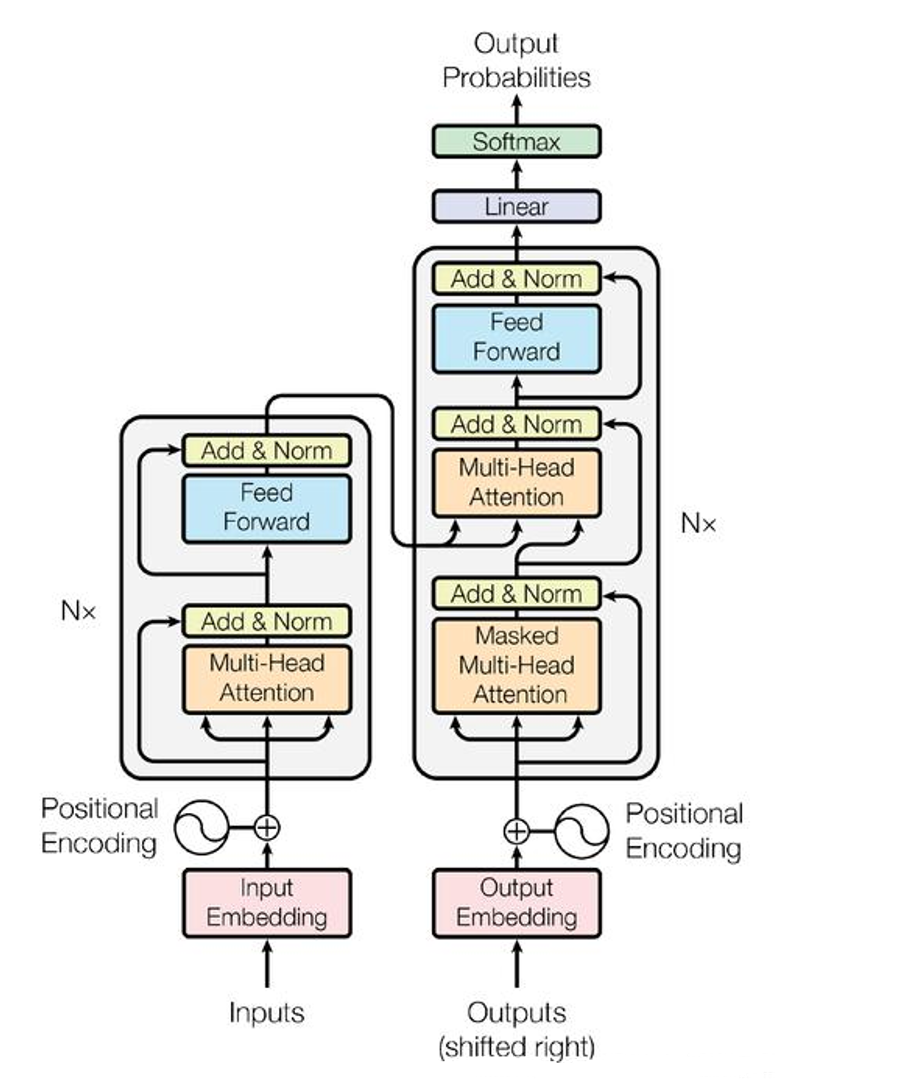
BERT基于Transformer的编码器部分,主要由以下组件构成:
- 自注意力机制(Self-Attention):通过计算词与词之间的匹配程度,动态分配权重,捕捉上下文关系。
- 多头注意力机制(Multi-Head Attention):使用多组注意力头(通常为8个)生成多种特征表达,增强模型的表达能力。
- 前馈神经网络(Feed Forward Network):对注意力机制的输出进行进一步处理。
- 位置编码(Positional Encoding) :通过三角函数为词向量添加位置信息,解决Transformer无法直接处理序列顺序的问题。
2. 预训练任务
BERT通过两个无监督任务进行预训练:
-
遮蔽语言模型(Masked Language Model, MLM):随机遮蔽输入句子中15%的词汇,让模型预测被遮蔽的词。例如:
输入:我 [MASK] 天 去 [MASK] 试 预测:今, 面 -
下一句预测(Next Sentence Prediction, NSP):判断两个句子是否连续。例如:
输入:[CLS] 我 今天 去 面试 [SEP] 准备 好 了 简历 [SEP] 标签:Yes
3. 双向性
BERT的核心优势在于其双向性。传统模型(如RNN或GPT)只能单向处理文本(从左到右或从右到左),而BERT通过自注意力机制同时考虑前后上下文,显著提升了语义理解能力。
二、BERT的核心技术
1.自注意力机制 self.attention
BERT基于Transformer的编码器部分,其核心是自注意力机制。以下是自注意力的计算流程:
-
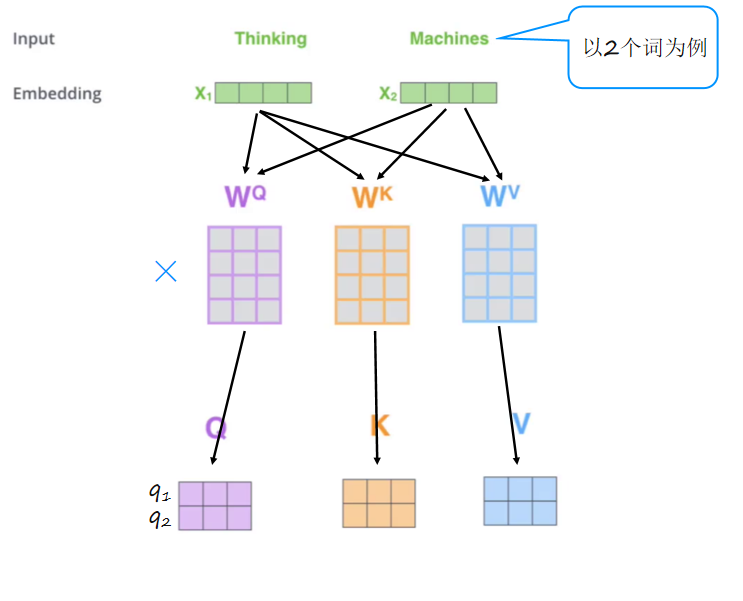
输入编码 :将词向量与三个矩阵(WQ, WK, WV)相乘,得到查询(Q)、键(K)和值(V)矩阵。
-
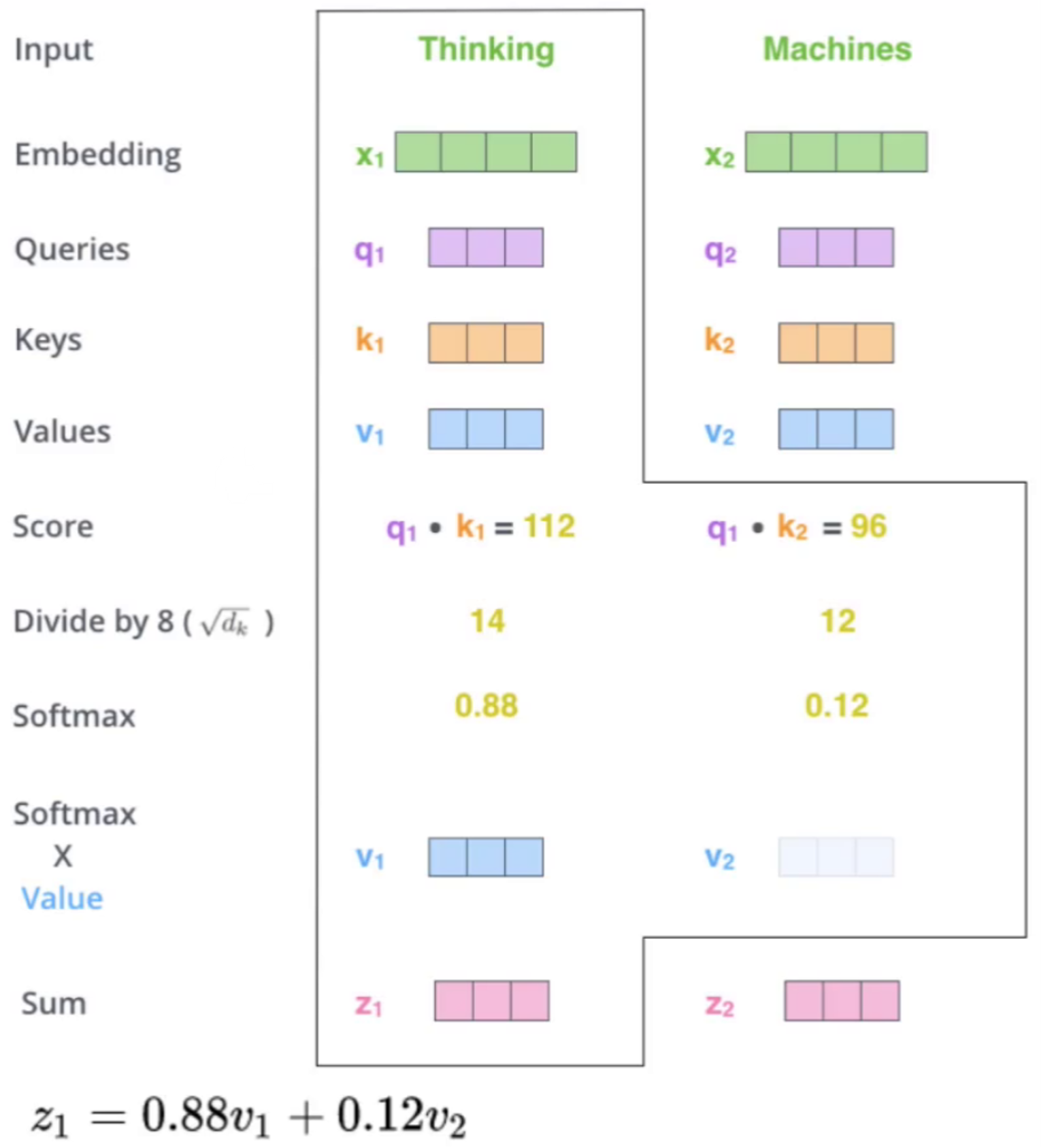
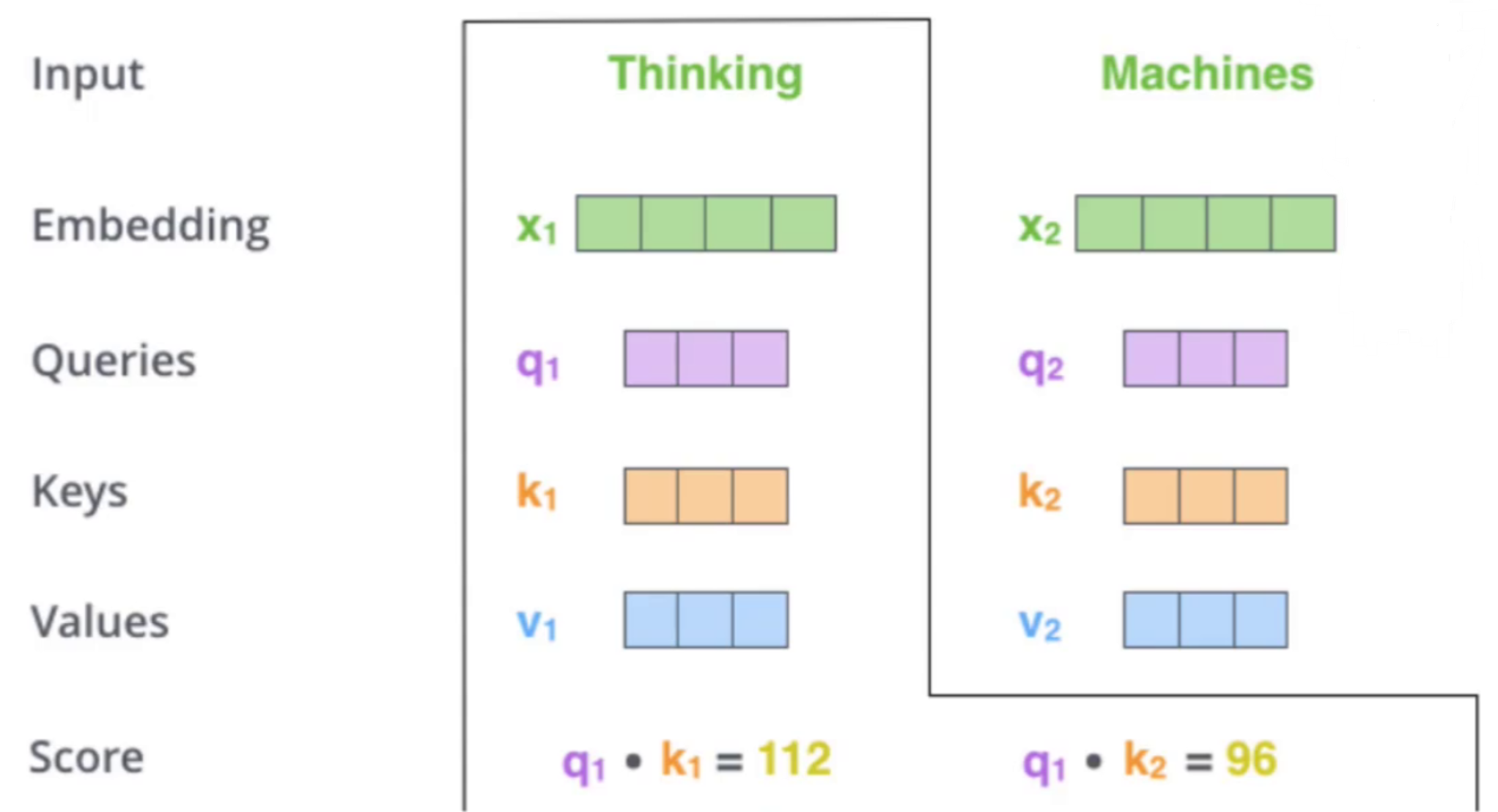
注意力得分计算 :通过Q与K的点积计算词与词之间的匹配程度。
-
特征分配 :根据得分对V进行加权求和,得到每个词的最终特征表示。
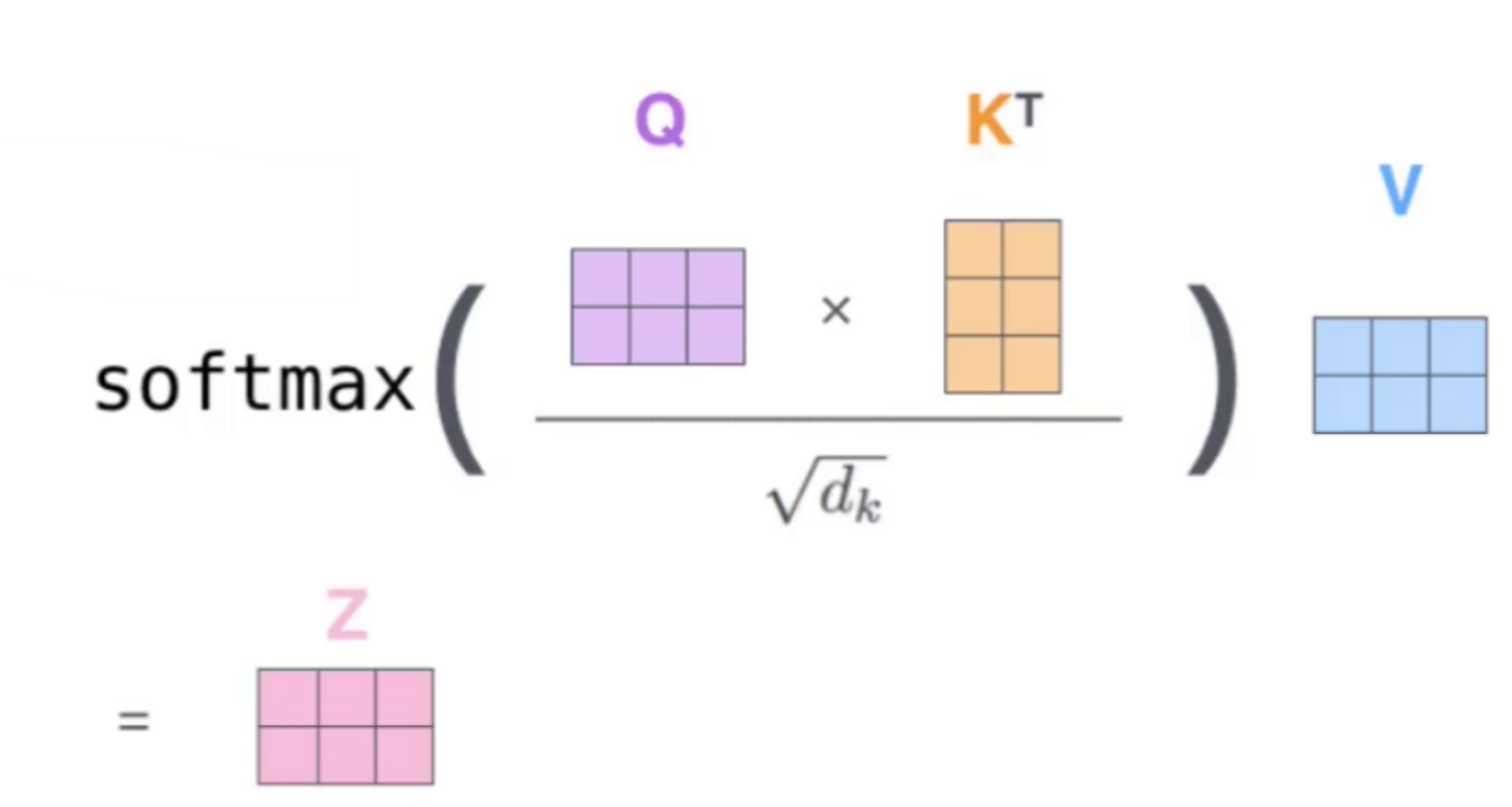
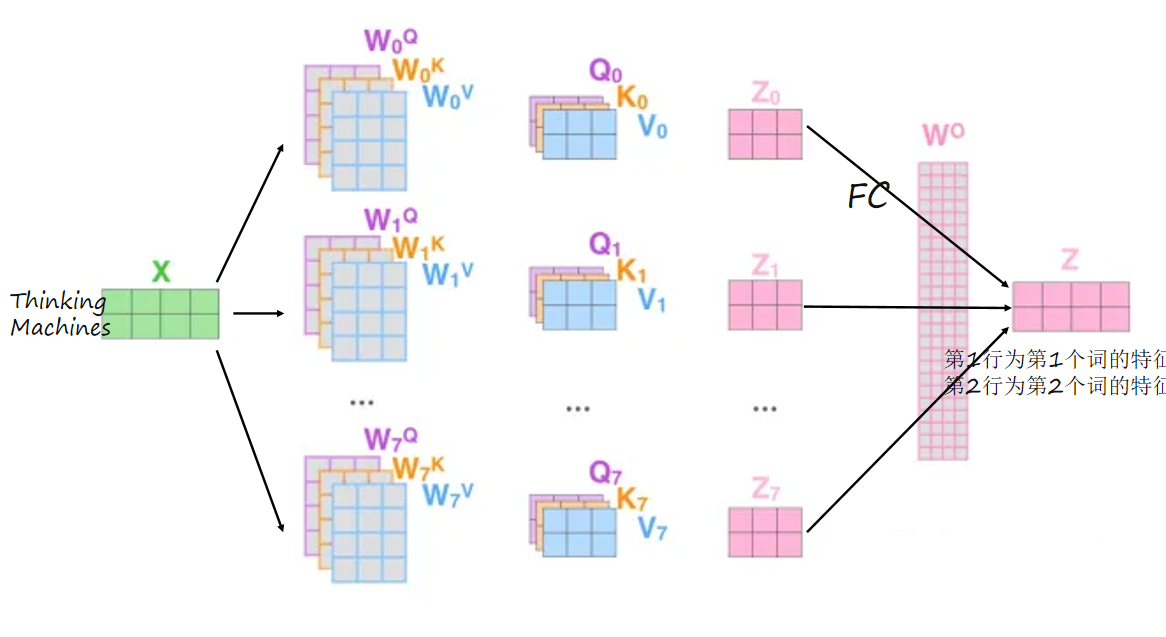
2. 多头注意力机制 multi-headed
通过多组注意力头,BERT能够从不同角度捕捉词与词之间的关系。例如:
- 一个注意力头可能关注语法关系,另一个可能关注语义关系。
- 最终将所有头的输出拼接并通过全连接层降维。
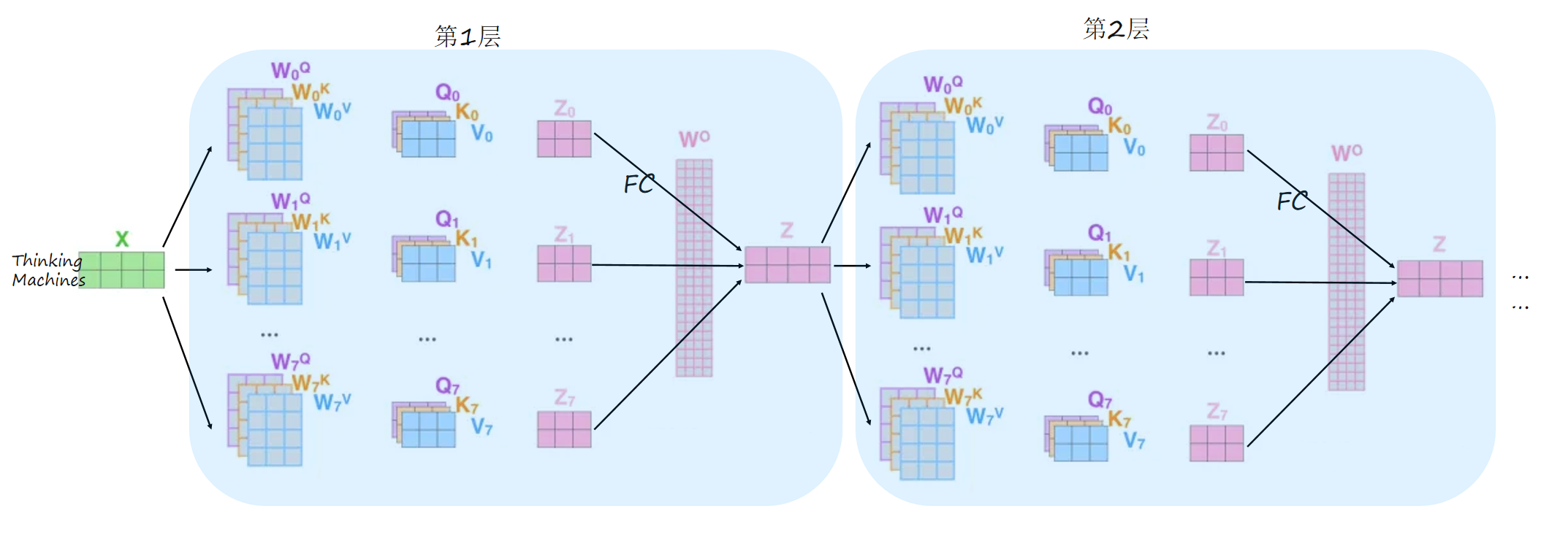
3. 多层堆叠
BERT的核心是由多层Transformer编码器堆叠而成的深度神经网络结构:
4. 位置编码
Transformer本身不具备处理序列顺序的能力,因此BERT引入了三角函数位置编码:
- 公式:
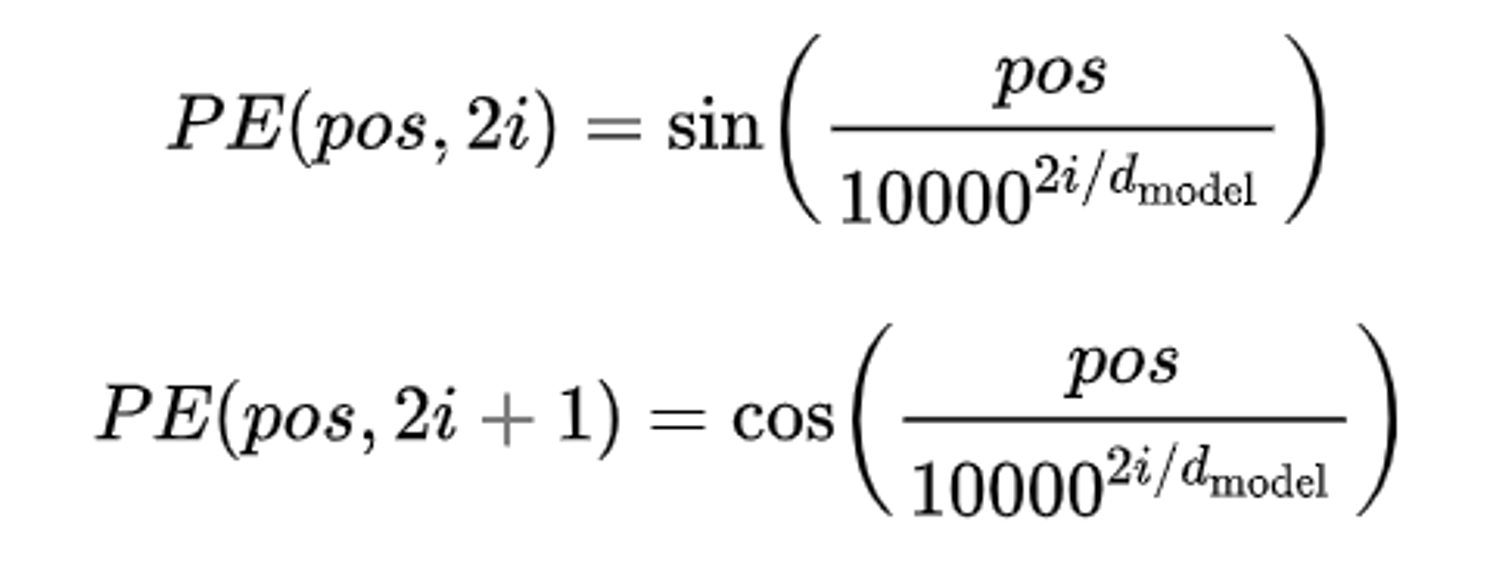
pos:指当前字符在句子中的位置(如:"你好啊",这句话里面"你"的pos=0),
dmodel:指的是word embedding的长度(例"民主"的word embedding为1,2,3,4,5,则dmodel=5),
2i 表示偶数,2i+1表示奇数。取值范围:i=0,1,...,dmodel−1。偶数使用公式,奇数时使用公式。
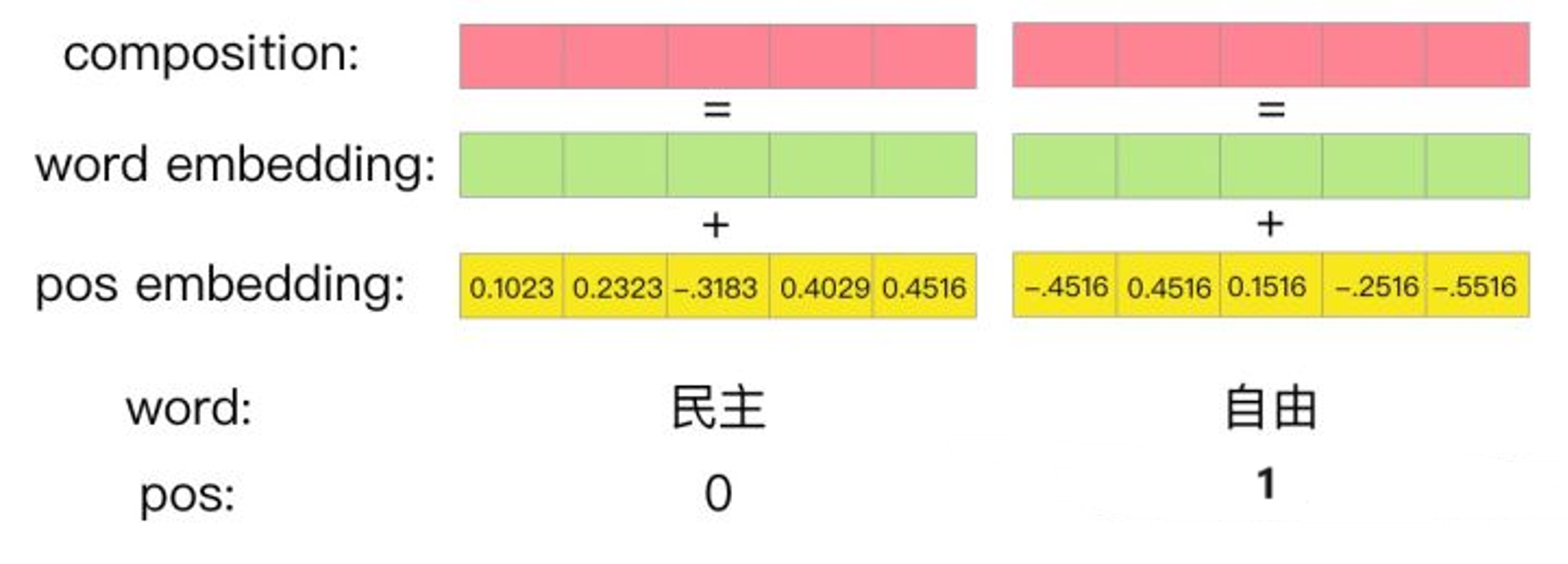
word embedding :是词向量,由每个词根据查表得到
pos embedding :就是位置编码。
composition:word embedding和pos embedding逐点相加得到,既包含 语义信息又包含位置编码信息的最终矩阵。
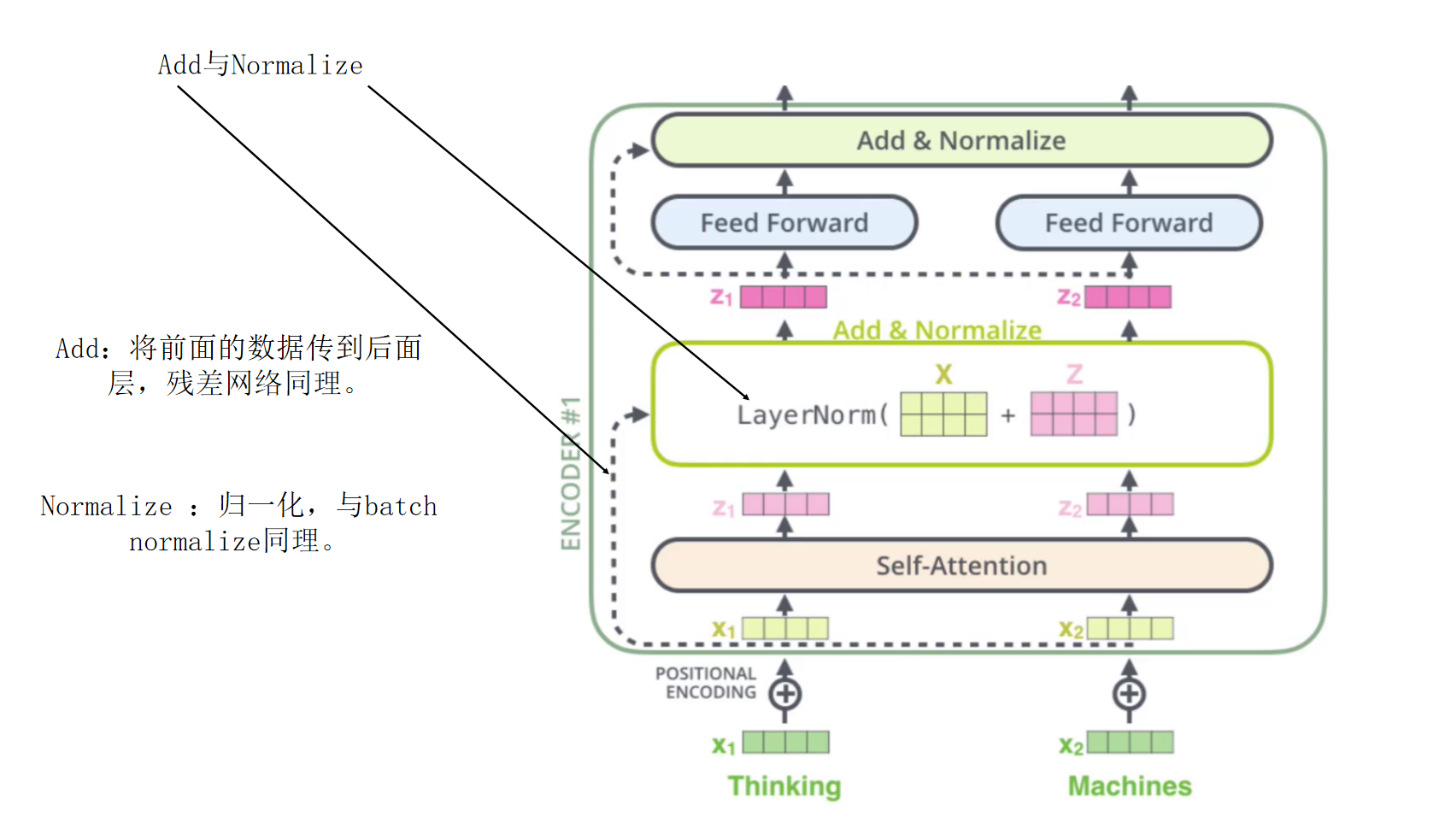
5. Add与Normalize
6.outputs(shifted right)
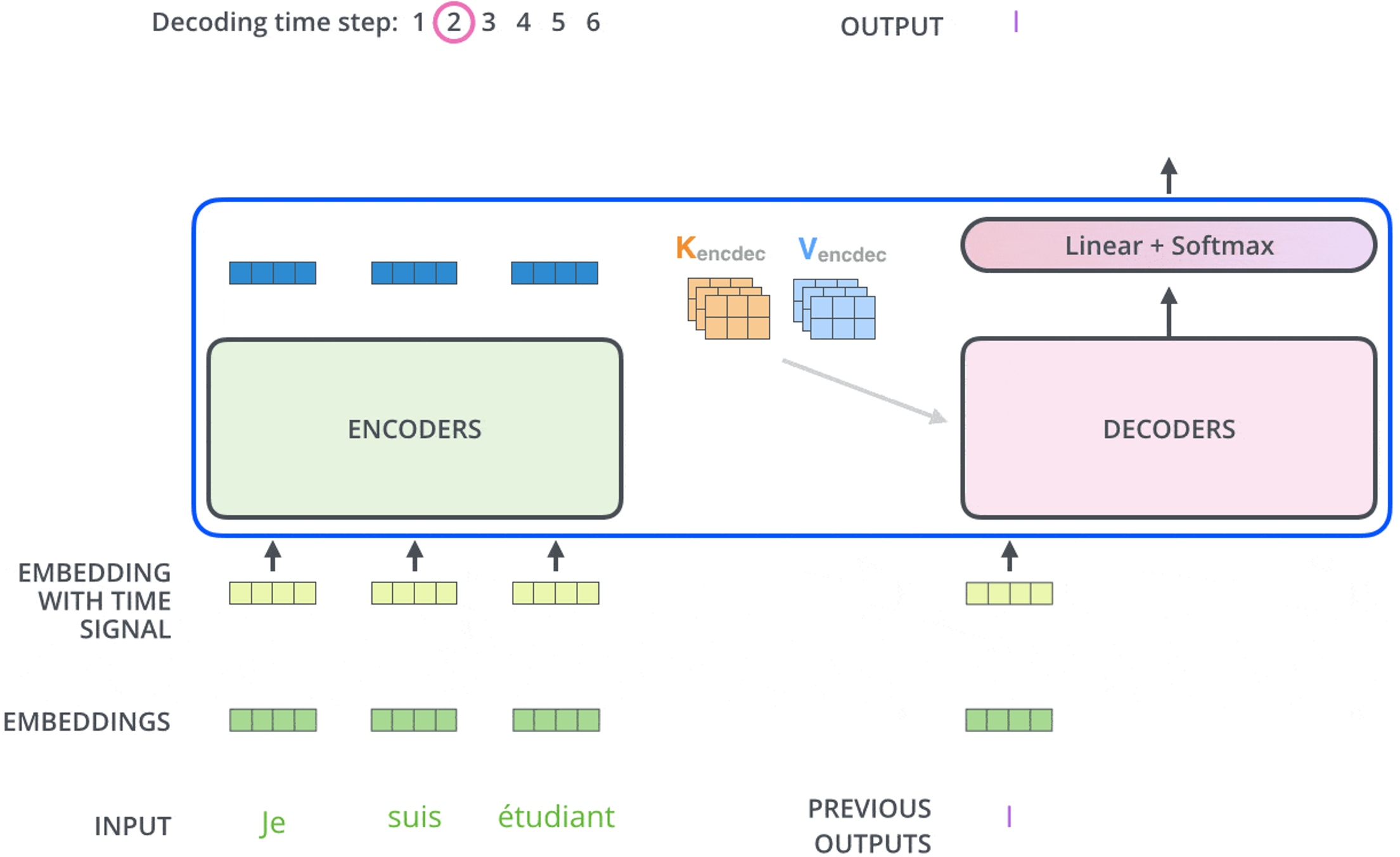
outputs(shifted right) :指在解码器处理过程中,将之前的输出序列向右移动一位,并在最左侧添加一个新的起始符(如 'SOS' 或目标序列开始的特殊token)作为新的输入。这样做的目的是让解码器在生成下一个词时,能够考虑到已经生成的词序列。
作用:通过"shifted right"操作,解码器能够在生成每个词时,都基于之前已经生成的词序列进行推断。这样,解码器就能够逐步构建出完整的输出序列。
三、BERT的优势与影响
- 解决RNN的局限性:RNN需要串行计算,训练时间长;BERT通过并行计算大幅提升效率。
- Word2Vec的静态词向量:Word2Vec生成的词向量无法适应不同语境;BERT通过动态上下文编码解决这一问题。
四、总结
BERT通过双向Transformer架构和预训练任务,彻底改变了NLP领域的游戏规则。它不仅解决了传统模型的诸多局限,还为后续研究奠定了坚实基础。无论是学术研究还是工业应用,BERT都是当今NLP领域不可或缺的工具。