前言:
Oracle Real Application Clusters (RAC) 集群依赖于各节点间的心跳检测与缓存融合等机制,这些机制对节点间的时钟同步性有极高的要求。如果集群内不同节点之间存在显著的时间偏差,可能会导致整个集群运行异常。在较早版本的RAC中,节点时间的一致性通常通过主机层面的NTP(Network Time Protocol)或Chrony服务来维护。
自Oracle 11g版本起,引入了专门用于增强集群内部时间同步能力的ctssd进程。尽管如此,由于配置不当等原因,在实际运维过程中仍然会遇到节点间时间不同步的问题。本文选取了几种典型的因时间不同步引起的情况进行了深入分析与测试。
测试环境:
|-------|-----------|-----------------|
| | 操作系统 | 集群版本 |
| node1 | Centos7.5 | Oracle 11.2.0.4 |
| node2 | Centos7.5 | Oracle 11.2.0.4 |
测试内容:
测试1:在集群启动的情况下,修改两个节点主机的时区
当前两个节点时区为EDT,实际上我们应该使用CST
[root@rhel75-node1 ~]# date
Fri Mar 14 10:46:49 EDT 2025
[root@rhel75-node2 ~]# date
Fri Mar 14 10:48:06 EDT 2025操作:
先修改节点2的:
rm -rf /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
这个时候节点一依旧使用EDT
观察:
结果集群没有脑裂,查看集群的ctss日志也未发现有时间不同步问题,如下:
一节点(时间同步主节点)
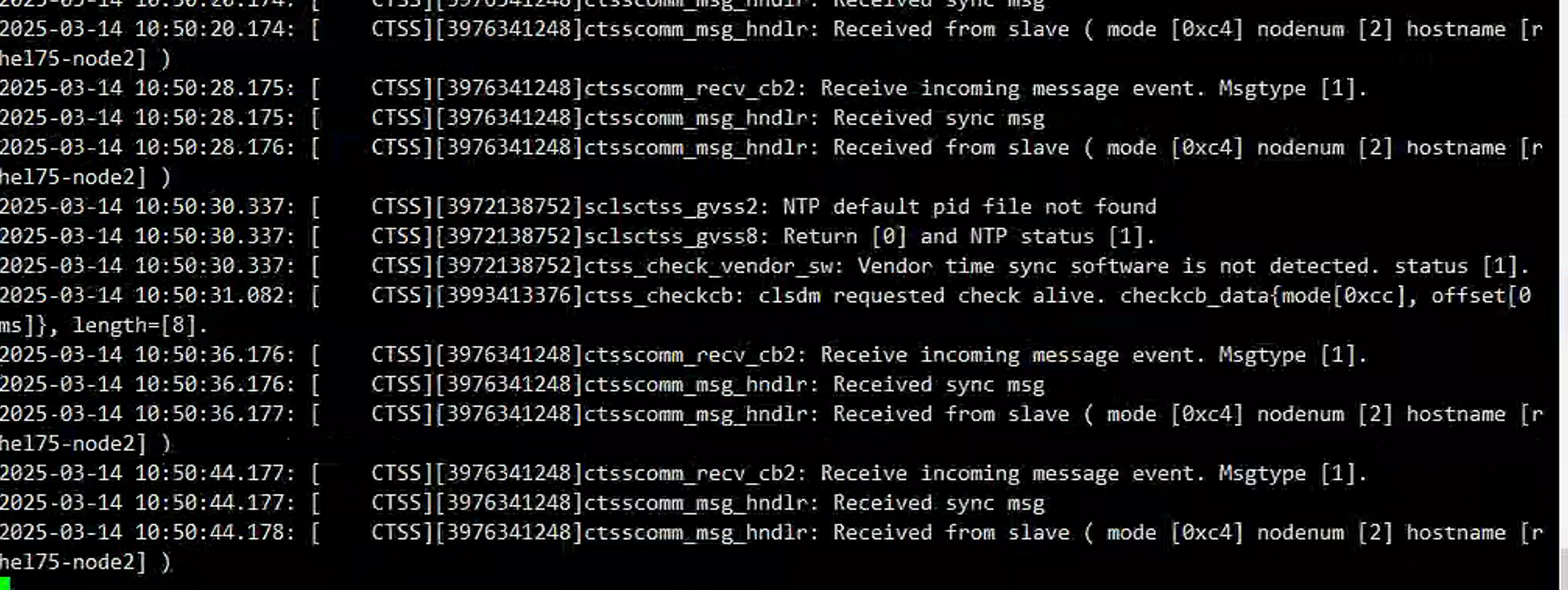
二节点报告与主节点时间延迟在7us级别
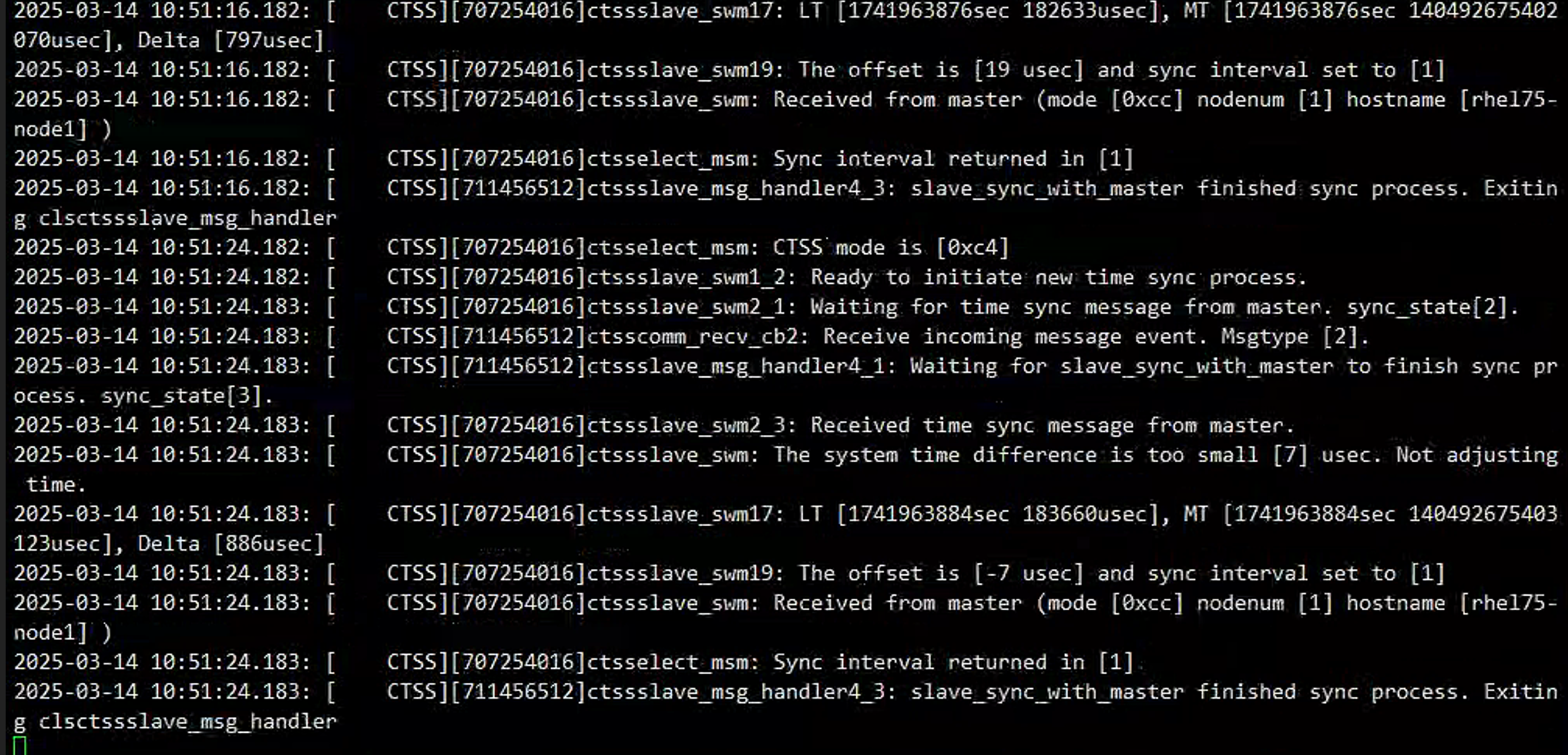
顺势将一节点上的时区也调整为CST,后续也未发现异常
结论:
两个节点使用不同时区也不会对集群同步产生影响,前提是两个节点换算到同一时区时,时间相差不大(分钟级别)。
测试2:同时把两个节点时间向前调整10小时
操作:
使用如下命令调整主机操作系统时间
先修改一节点的,再修改二节点上:
date -s "2025-03-14 14:55:00"观察:
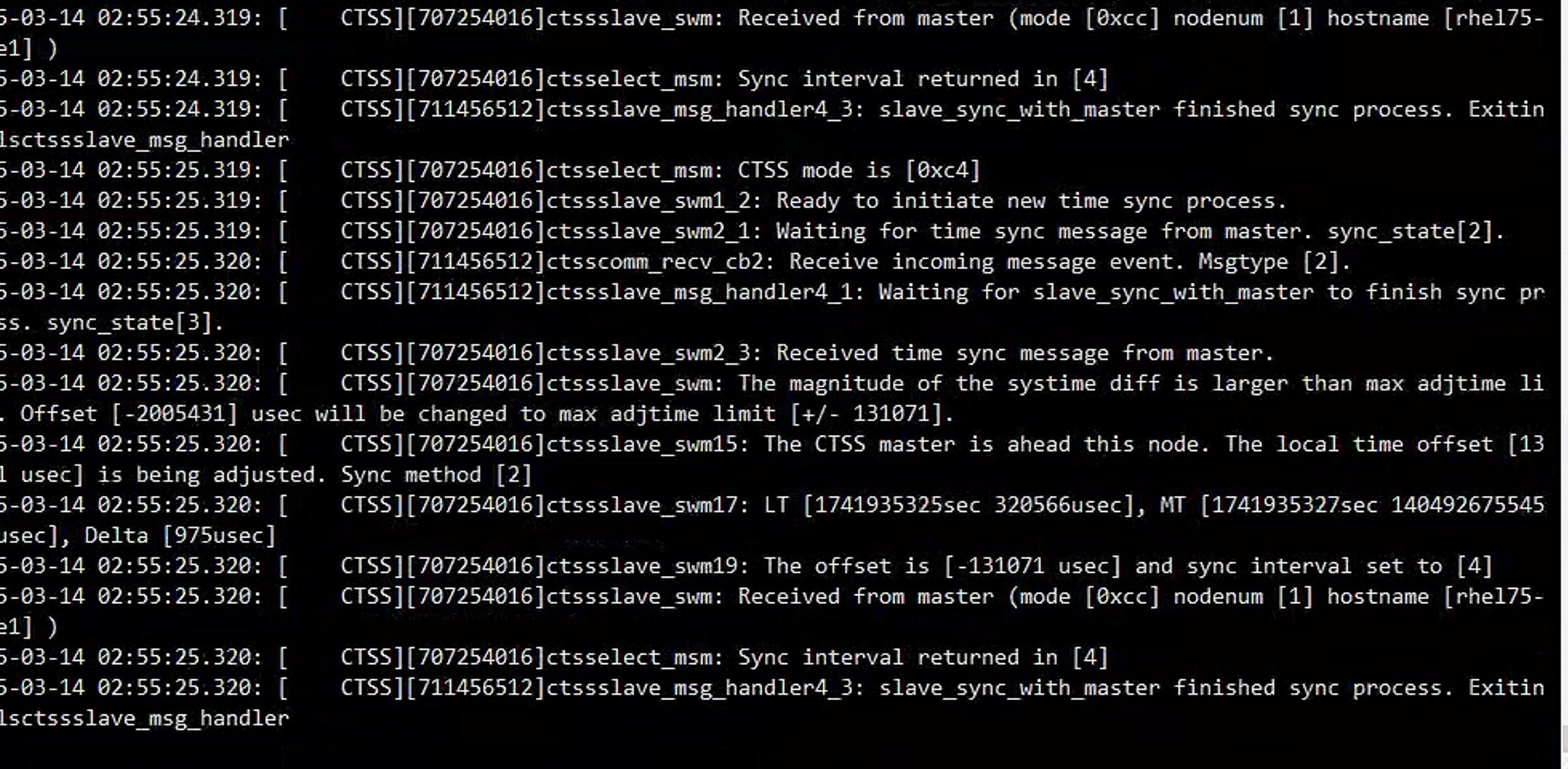
结论:
集群并没有崩,但是实际不建议这么做。
测试3:在ctss未启用的情况下,将一节点调整为当前时间快7分钟,二节点与当前时间持平
操作:
使用如下命令在两个节点上生产ntp.conf文件,但是不用配置ntp
两个节点生产一个ntp.conf文件
touch /etc/ntp.conf观察:
再次查看两个节点ctss进程已经进入观察者模式了,并且二节点和一节点时间差距在1.8s左右
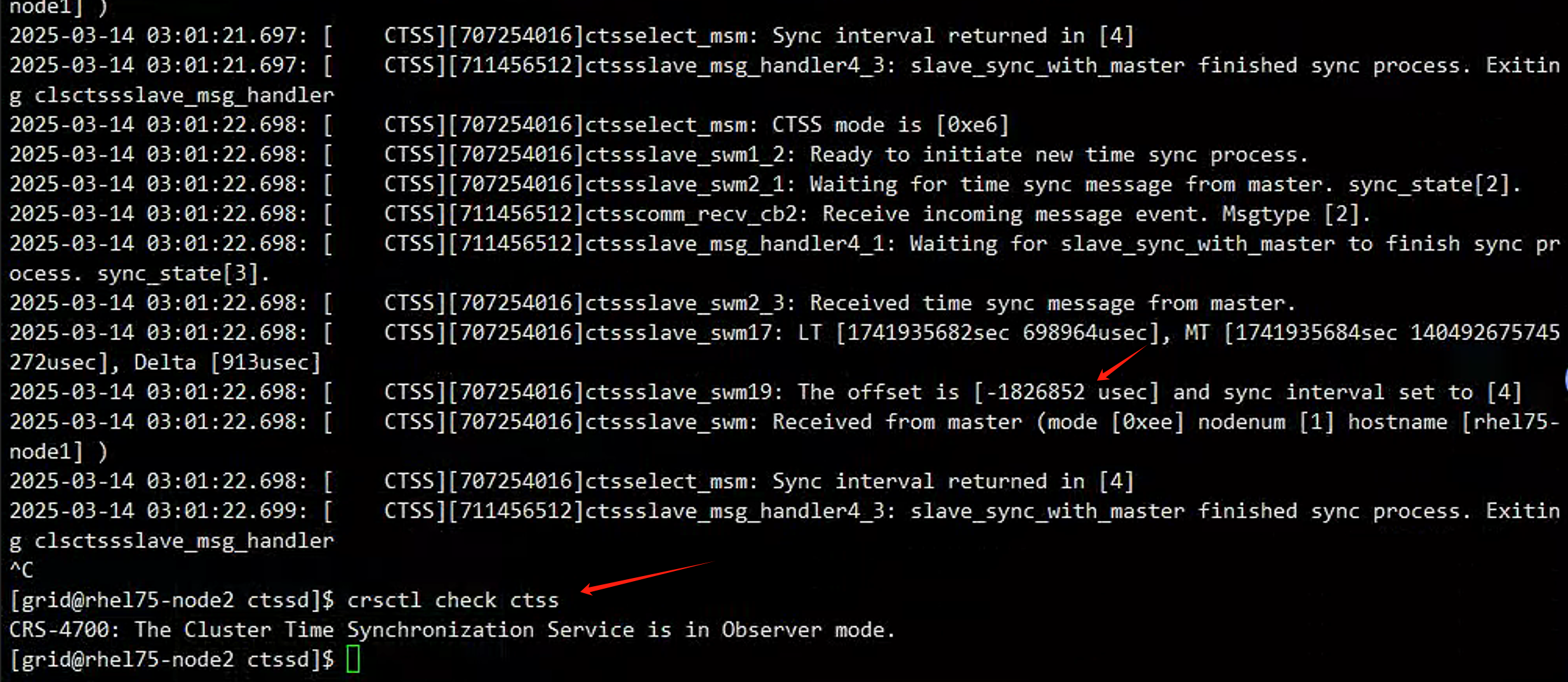
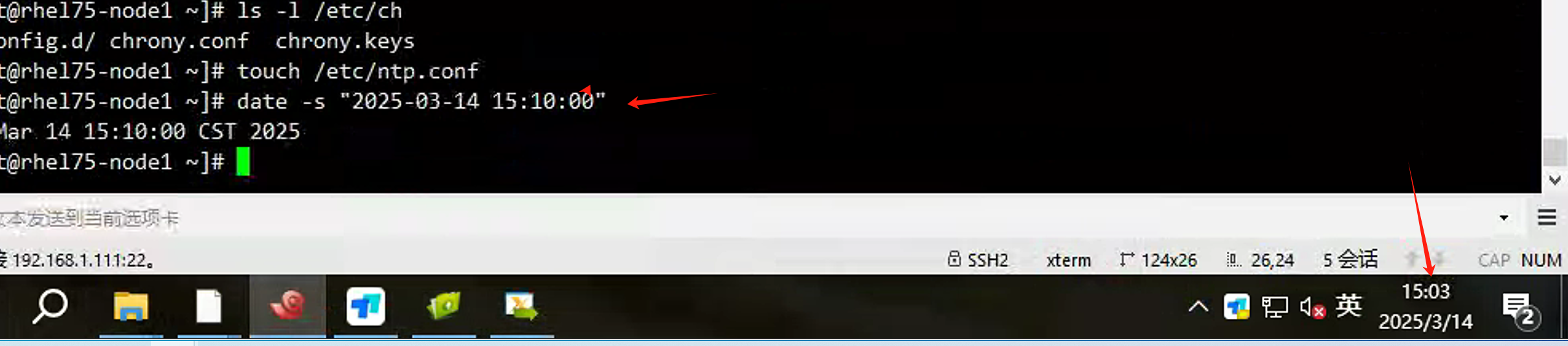
直接修改一节点时间比现在快7分钟:
再次查看二节点上的ctss日志,发现两个节点延迟在381005686 usec,大概就是7分钟
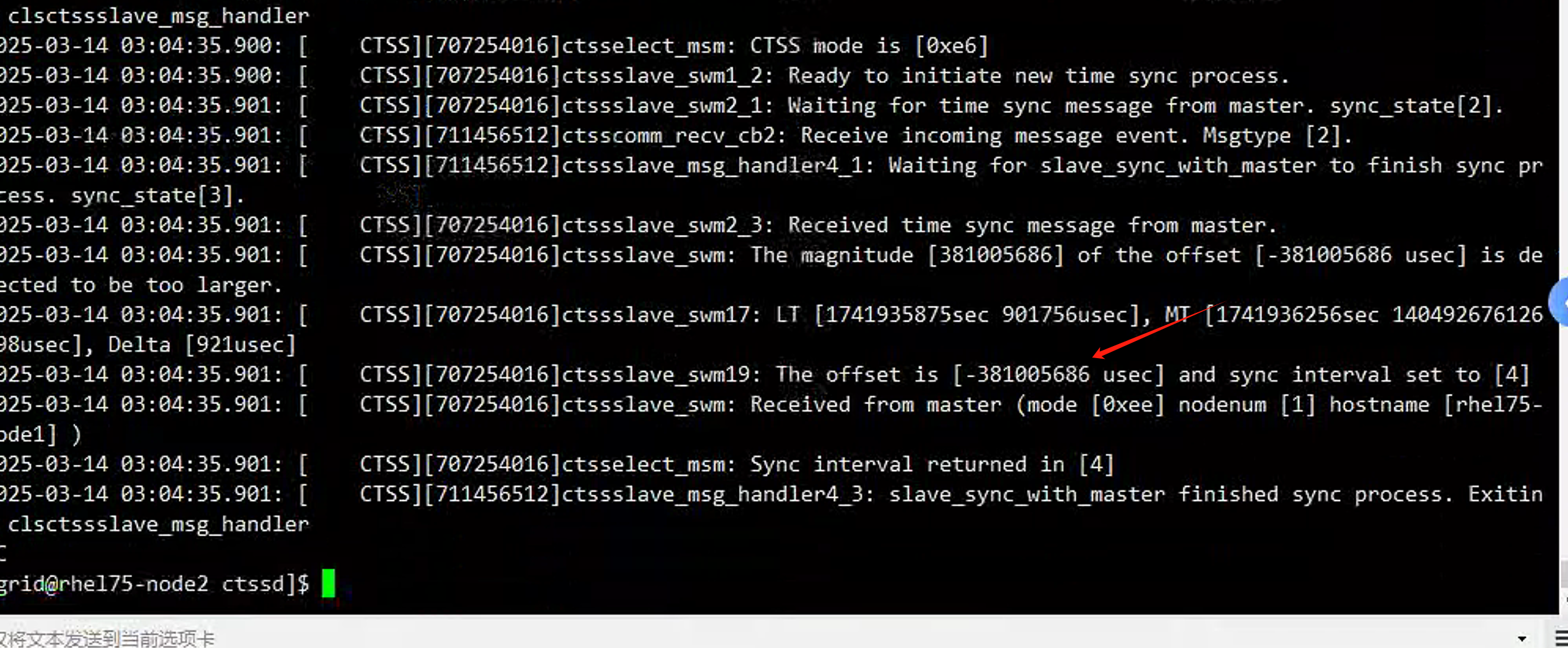
结论:
这个时候集群依旧正常,没有脑裂的迹象。这个时间业务的数据应该出现了错乱的情况,需要进行时间调整。
测试4:在测试3的基础上,单节点修改时间操作
操作:
这个时候我们只把一节点上的集群关闭:
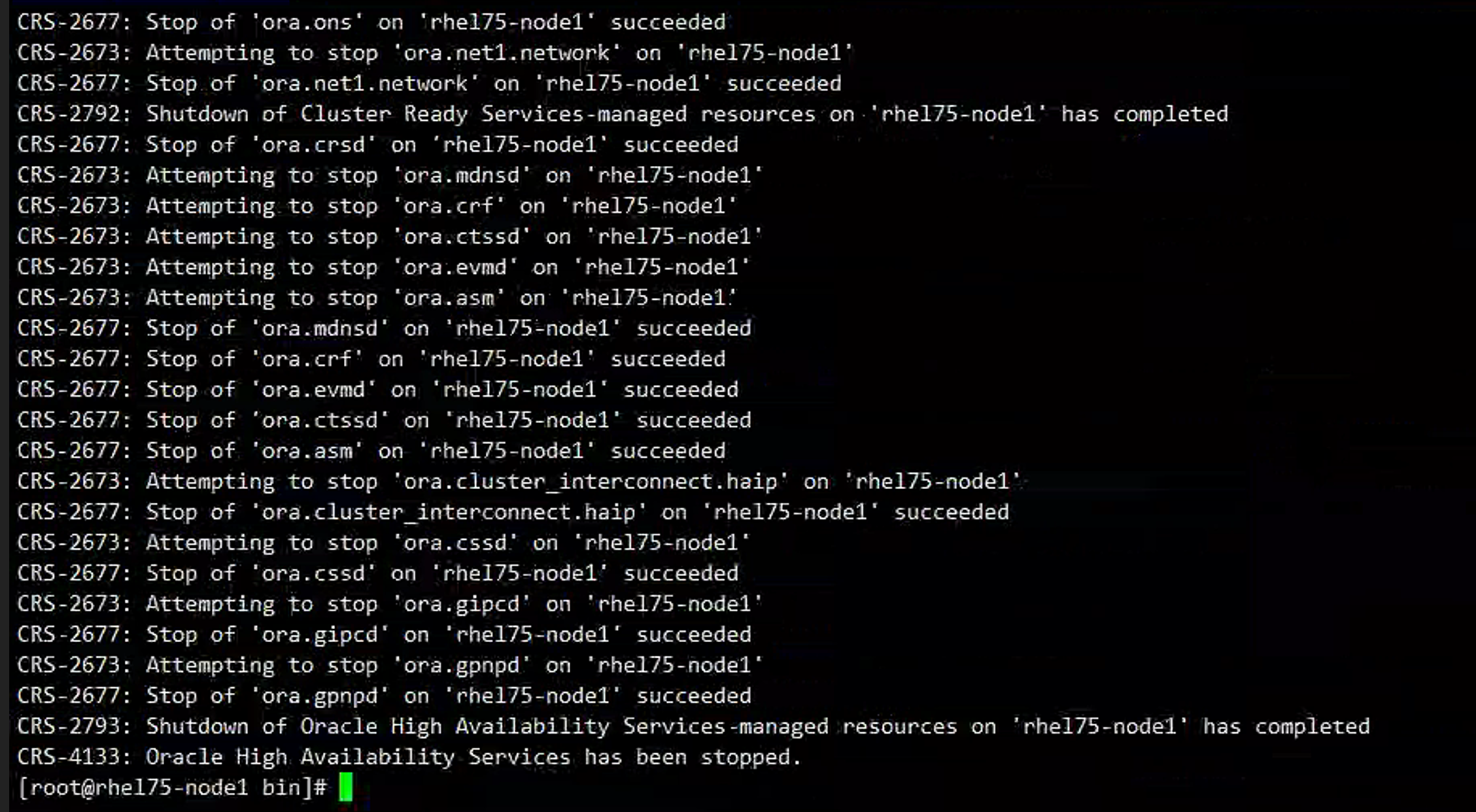
观察:
然后二节点就成为了ctss的master节点,这个时候是不存在脑裂的问题的,同时二节点也可以作为集群服务的主节点对外提供服务,业务不会中断。
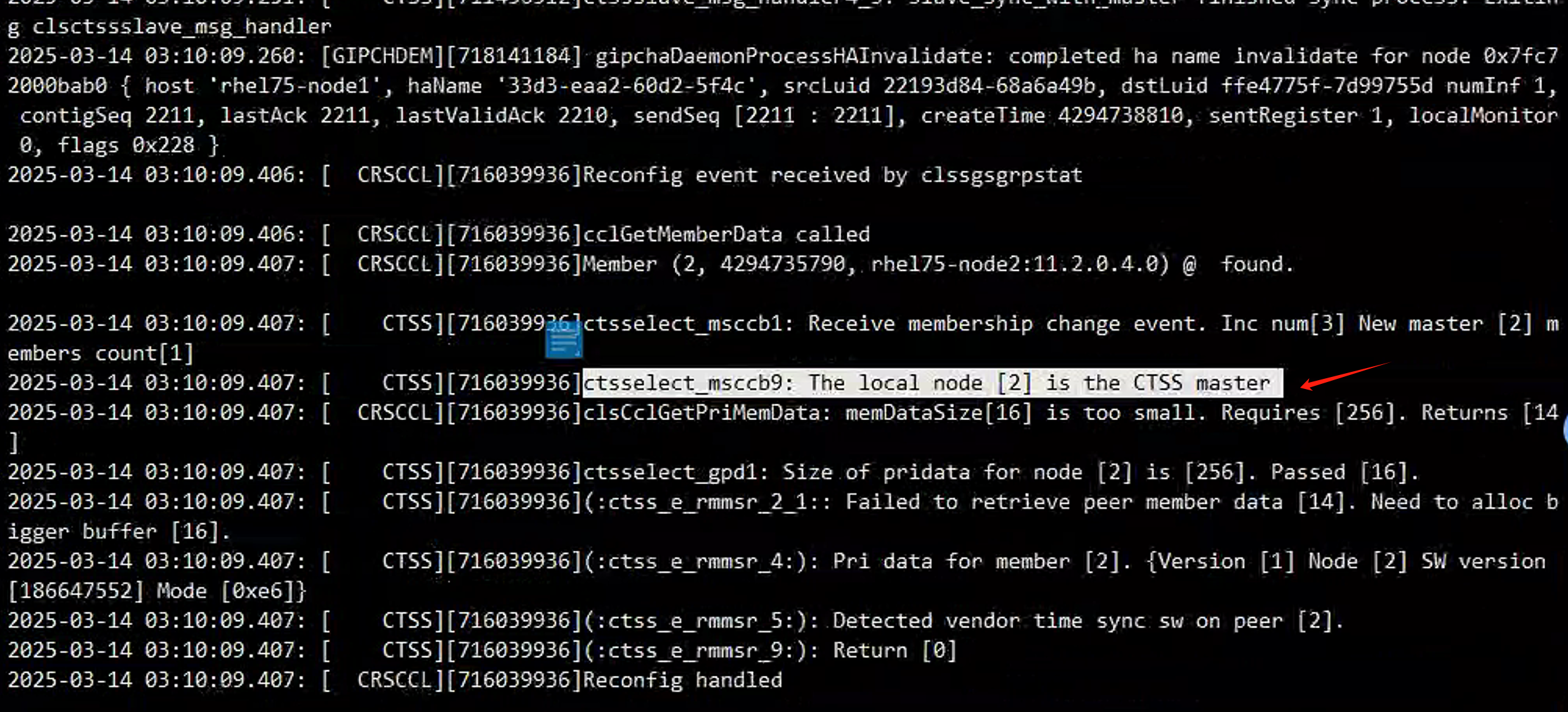
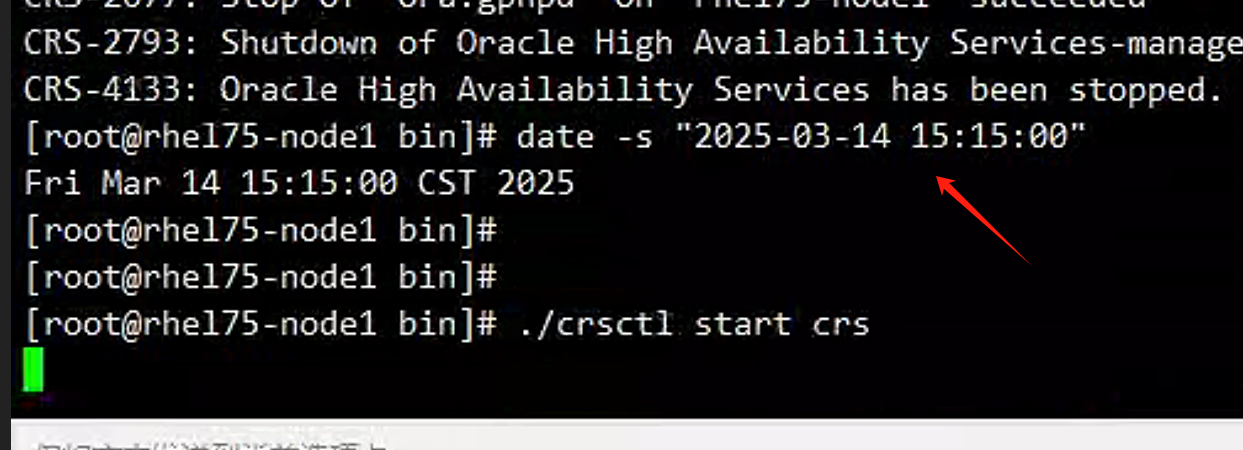
需要等7分钟(这里等7分钟主要是为了避免7分钟内起来导致新写入的业务数据比之前的业务数据还旧),然后把一节点上的时间修正过来,之后再启动一节点集群:
一节点起来之后大概和二节点相差19秒,这个时候其实还好
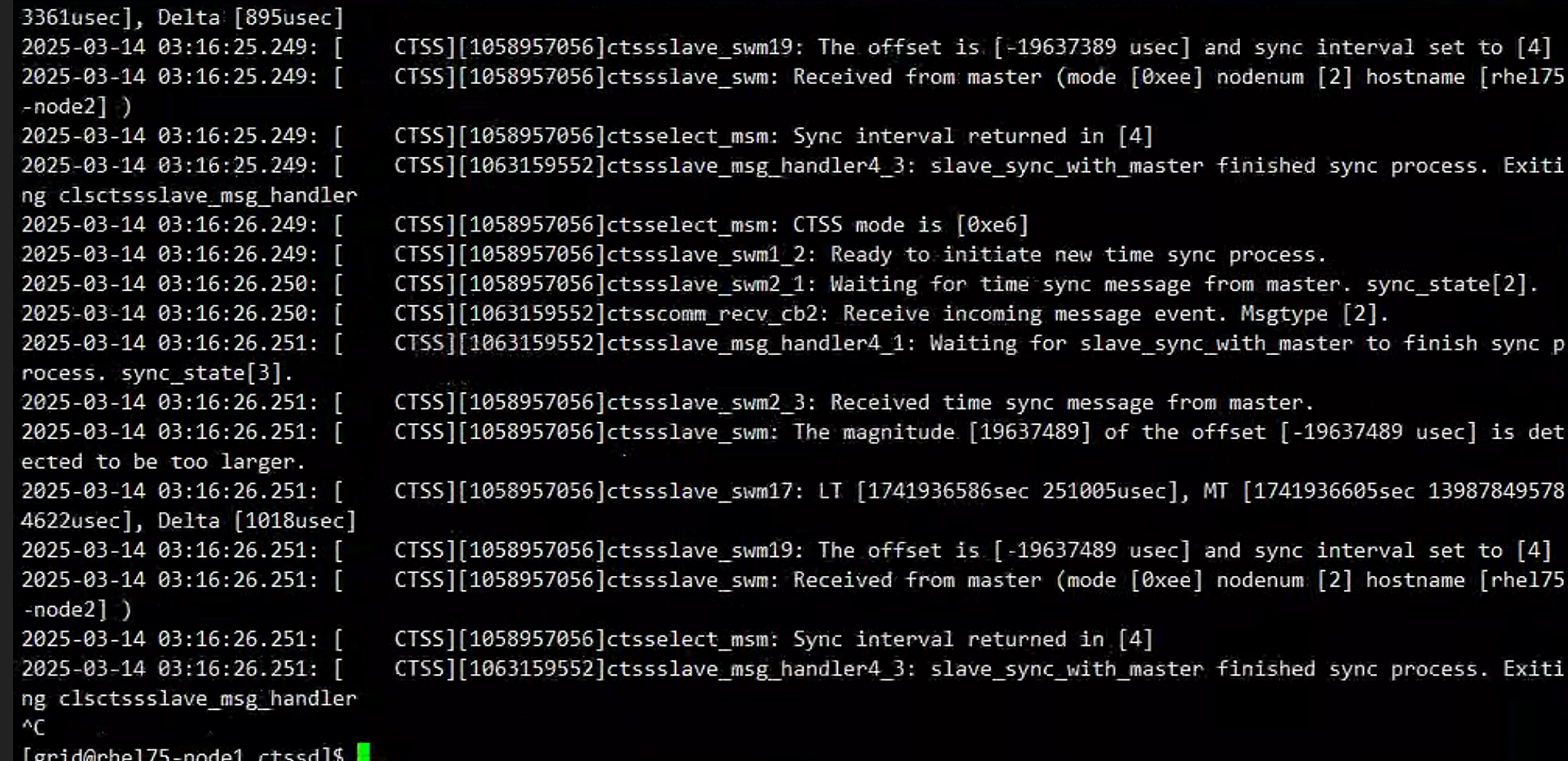
如果想要把这19秒的时间追平,有两个选择:
1、为两个节点配置同一个可用的ntp时间源,随着两个节点各自向同一个时间源做时间同步,彼此时间差也会越来越小。
2、移除/etc/ntp.conf文件,集群自动启用ctss作为时间同步,此时一节点会向二节点做时间同步操作。
我们这里选择第二个方案,执行如下命令移除两个节点上的ntp配置文件:
mv /etc/ntp.conf /etc/ntp.conf.bak再次查看octssd.log日志,发现一节点已经识别与二节点的时间差距,并以每次0.13秒的进度追赶
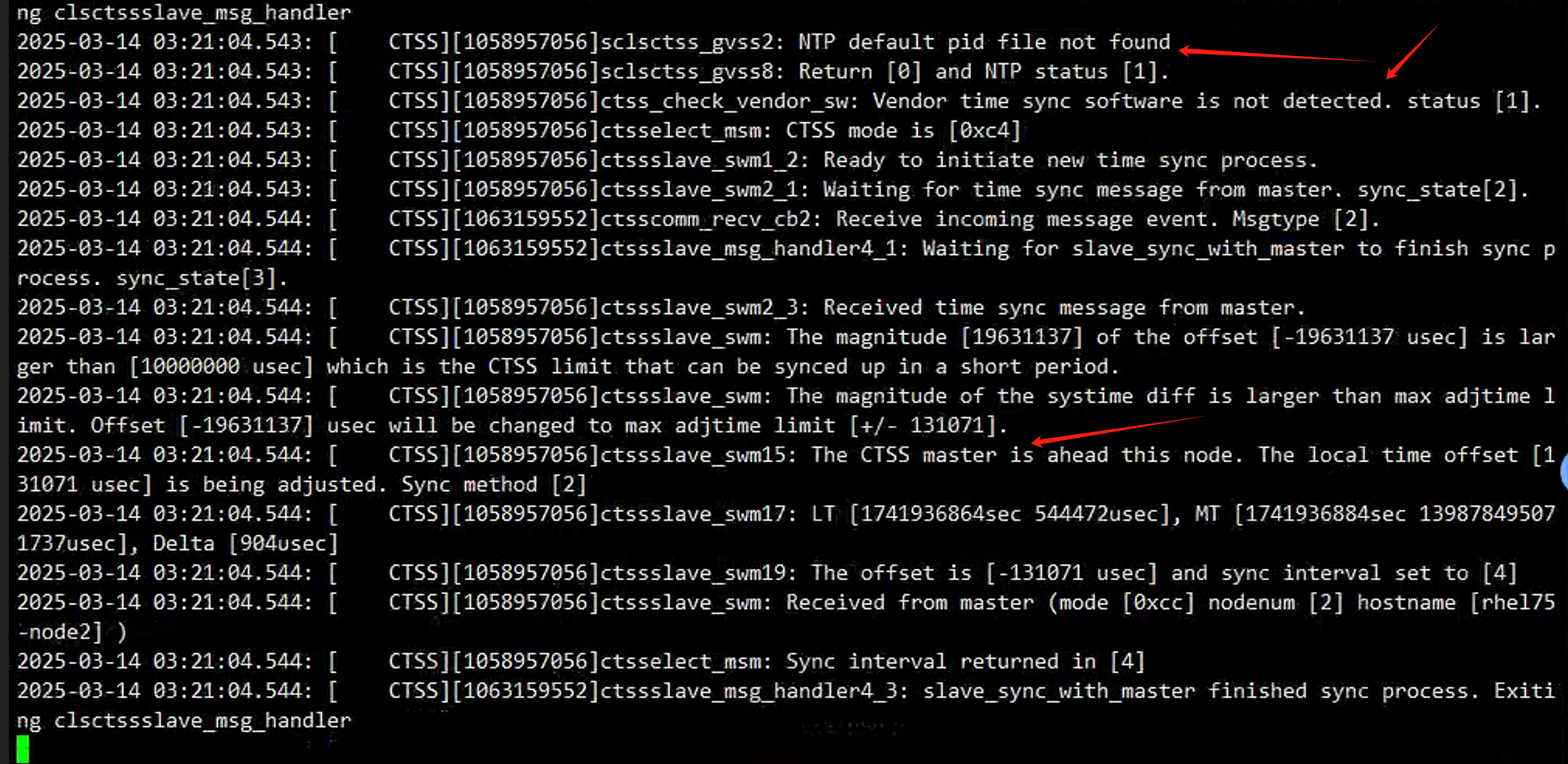
接下来只需要等待时间一节点上时间和二节点追平就可以了。
本次测试结论:
1、可以实现单节点时间修改,在这个过程中另外一节点节点可以正常提供业务,但是关掉的节点时间要修改为与正在运行的节点的时间附近,不能差距太大,如果想要两个节点时间延迟在us级别,可以使用ntp或者ctss
2、当有快于现实时间的节点,需要先把当前节点的服务停止(禁止业务数据写入),等待现实时间追上先前停机时间(时间快的节点),再启动相关服务,提供对外读写服务。
遗留问题:
那么两个节点上的时间到底要差多久才会脑裂?或者在节点有时间差异的基础上满足什么样的特殊条件才能触发集群脑裂呢?