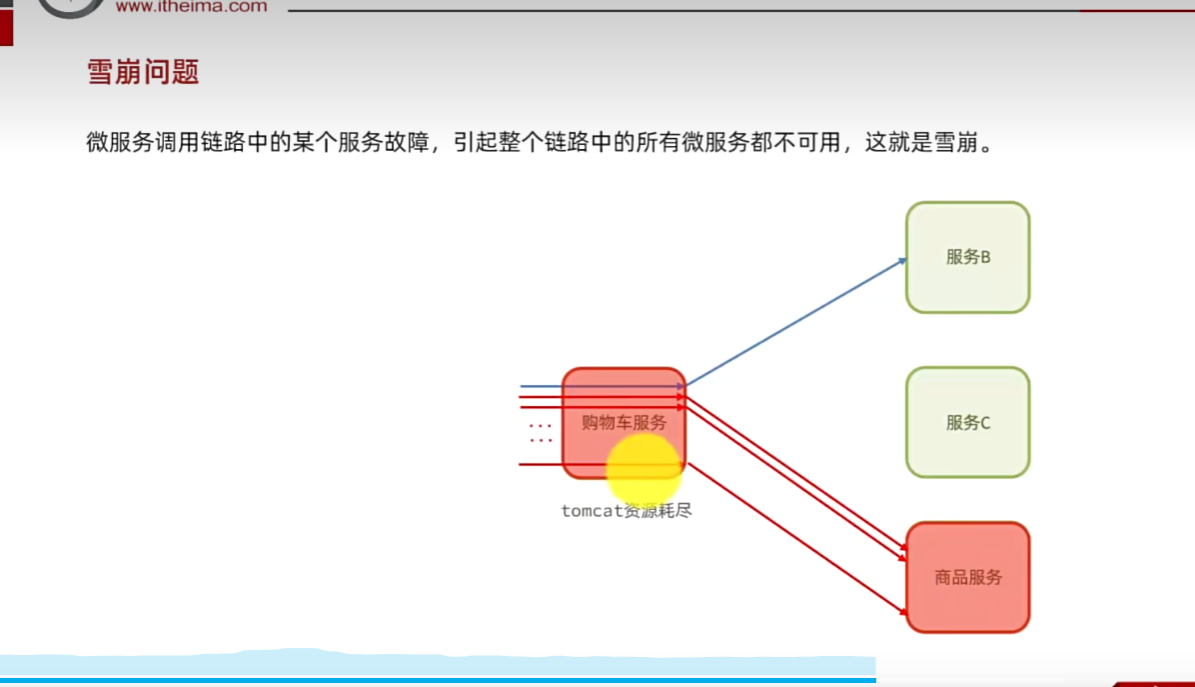
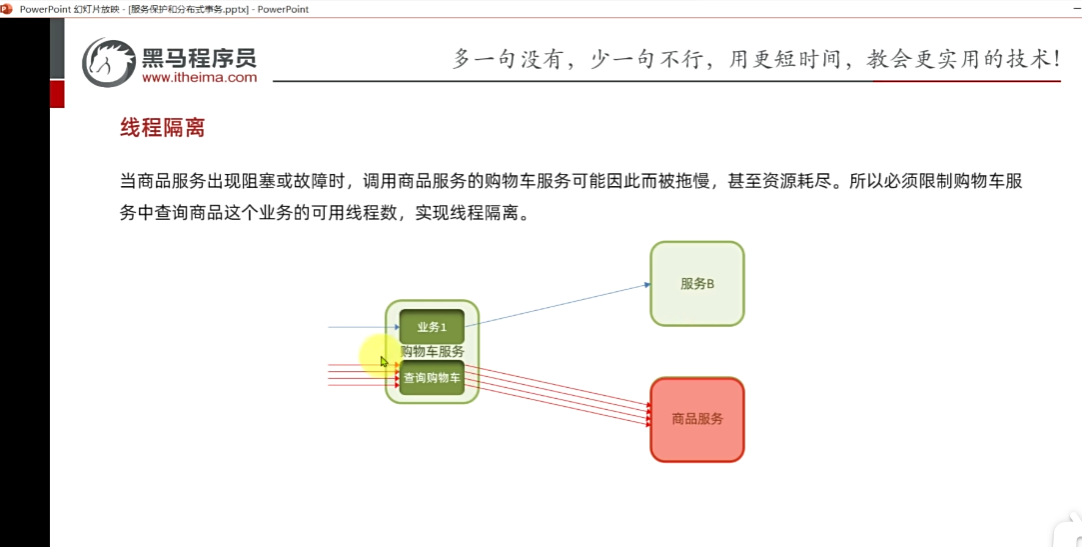
雪崩问题:
小问题引发大问题,小服务出现故障,处理不当,可能导致整个微服务宕机。
假如商品服务出故障,购物车调用该服务,则可能出现处理时间过长,如果一秒几十个请求,那么处理时间过长,那么卡的人越来越多,那么就会导致资源耗尽。原本服务B可以使用,此时此刻也宕机了,然后其他服务去调用服务B那么也会出现该情况,然后出现连锁反应。因为资源耗尽导致宕机等可能
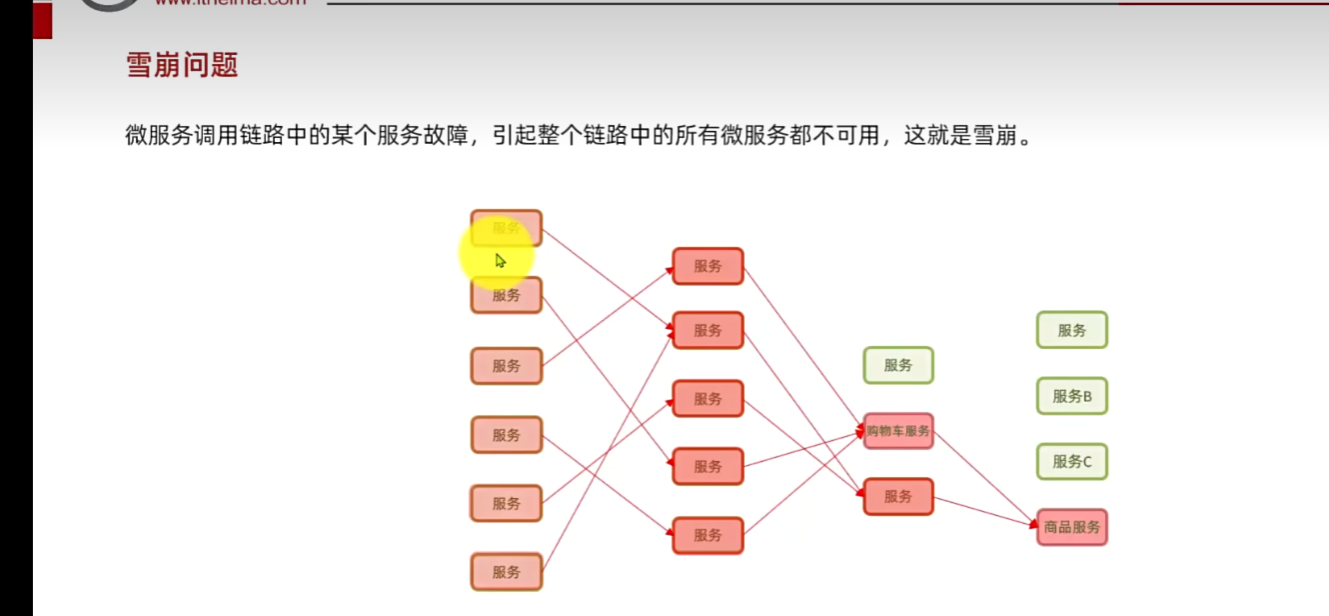
最后导致:出现级联反应,小问题不解决,越滚越大,原本就一个小问题,某一微服务提供者出现故障,负责调用它的人等待时间多长,就是滚雪球,没有进行异常处理。


解决方案:
一、不管请求多少,服务承受的都是固定的,从狂暴的到柔和的,限制到每秒中只有几个,避免崩掉

但是也无法保证百分百没有问题(避免卡死,等待导致雪崩)引入线程隔离。
我们去限定每个业务线程的数量,那么当有请求,就必须去线程池去取 然后去调用服务B,
业务二:那么即使四个线程去取的时候全故障了,那么也不会耗尽服务A的资源,关进黑屋里面,起到故障隔离,服务B影响不到
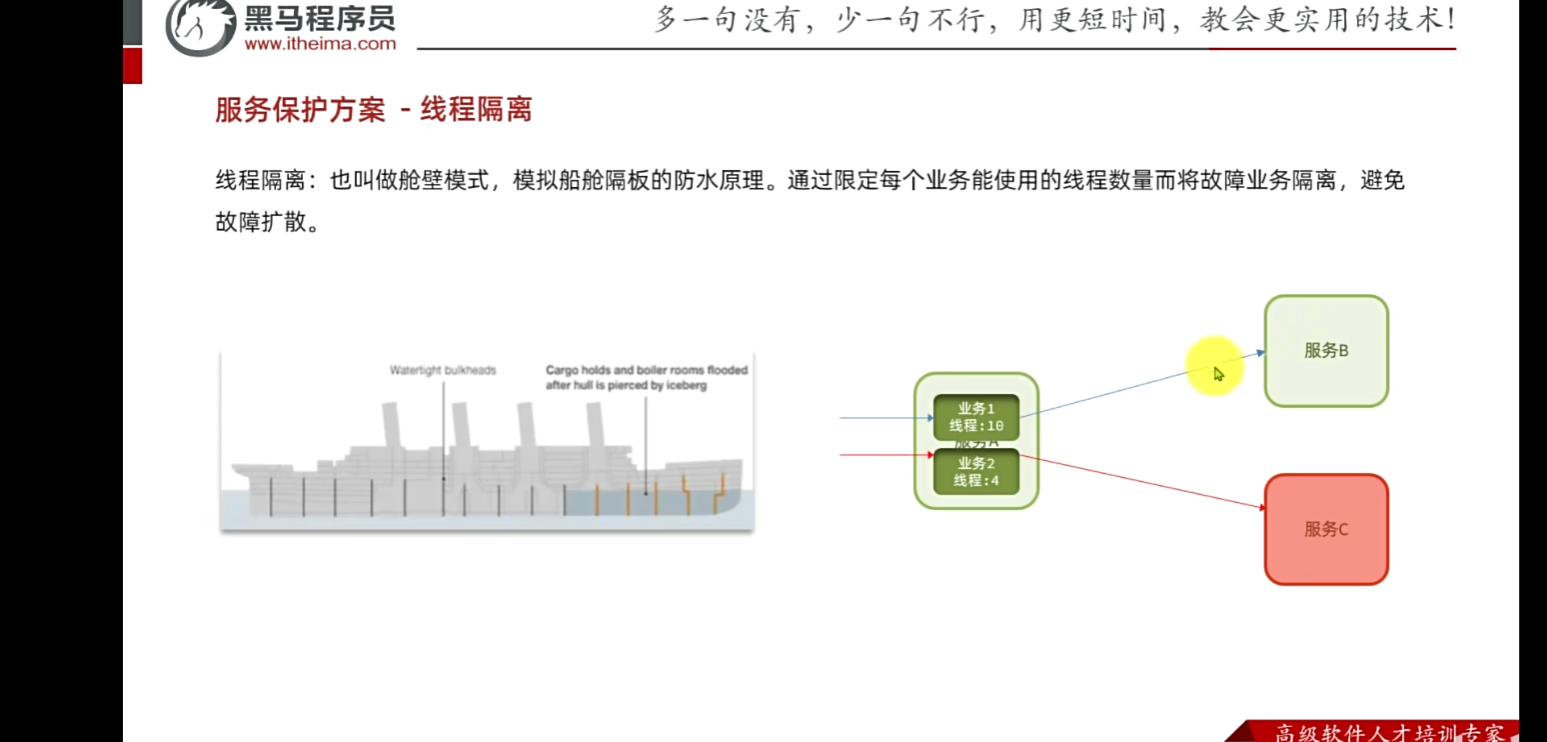
那么也不能百分百解决问题:假如一直来请求,那么虽然说已经隔离了四个,那么也一直不断有新的请求资源,虽然不会导致服务A宕机,但是也会消耗CPU资源等。
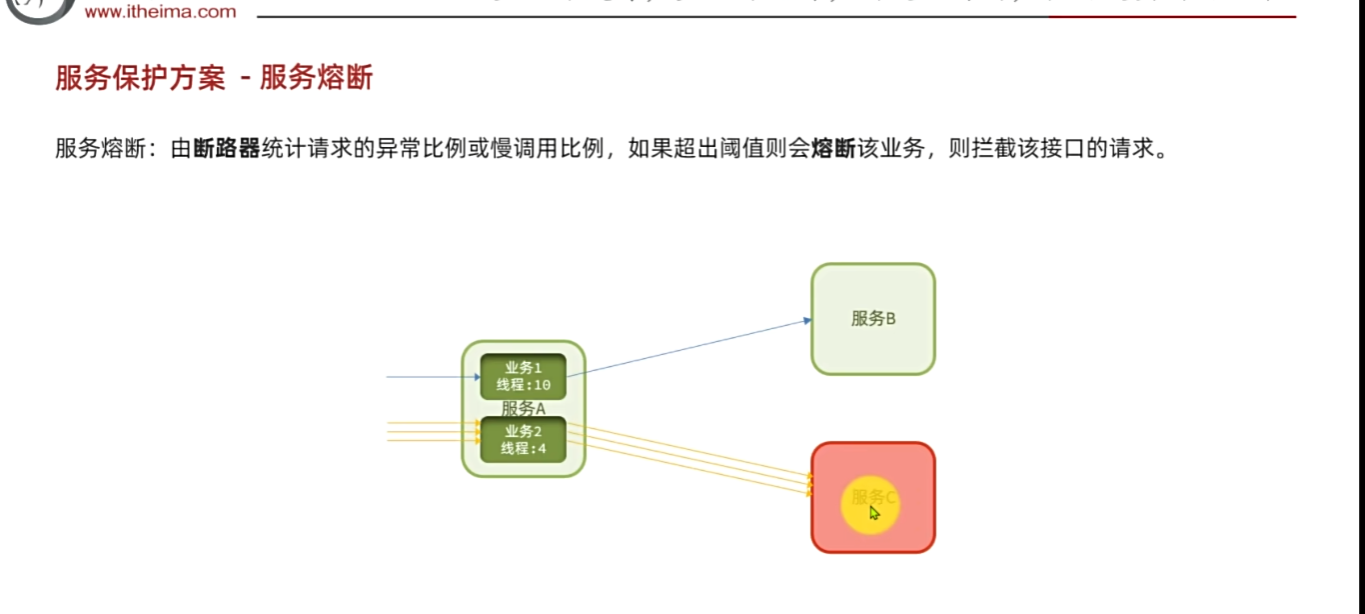
所以应该拒绝它访问,这个叫服务垄断,拦截请求,就像是电路的保险开关。"断路器" ,自动断开,防止进一步请求
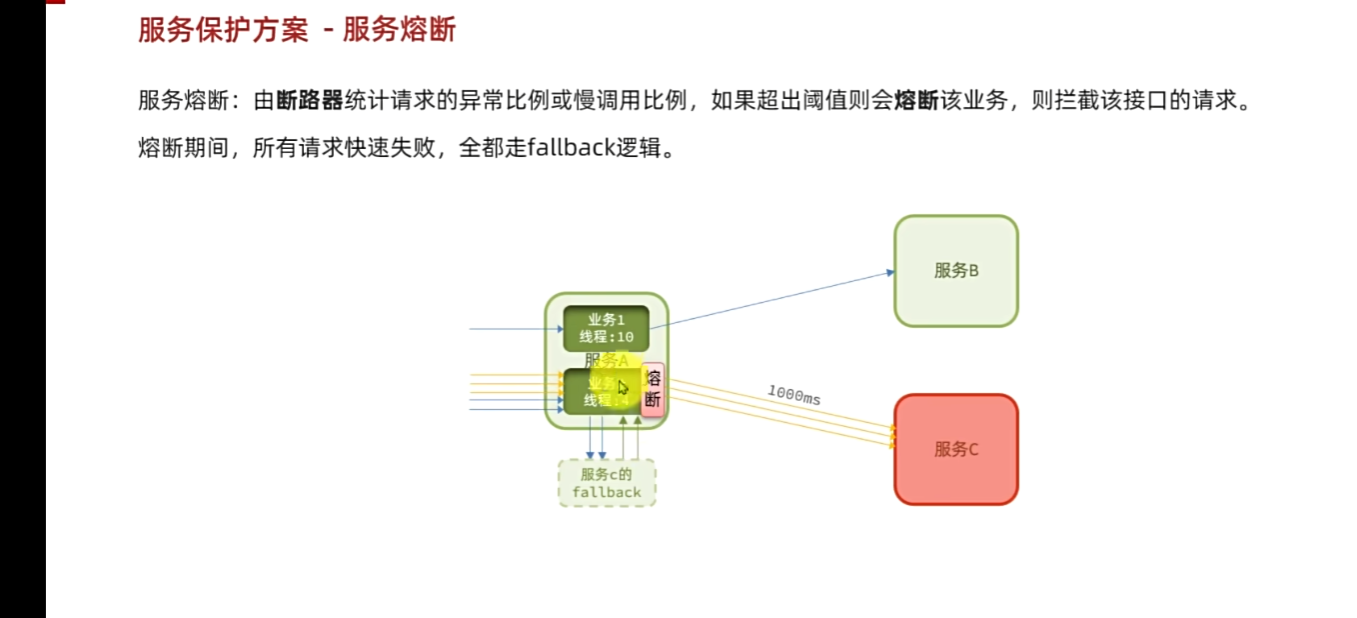
例如:假如访问时间过长,那么发现请求的异常比例 比如五次四次挂的或者慢调用太高,那么直接熔断该业务
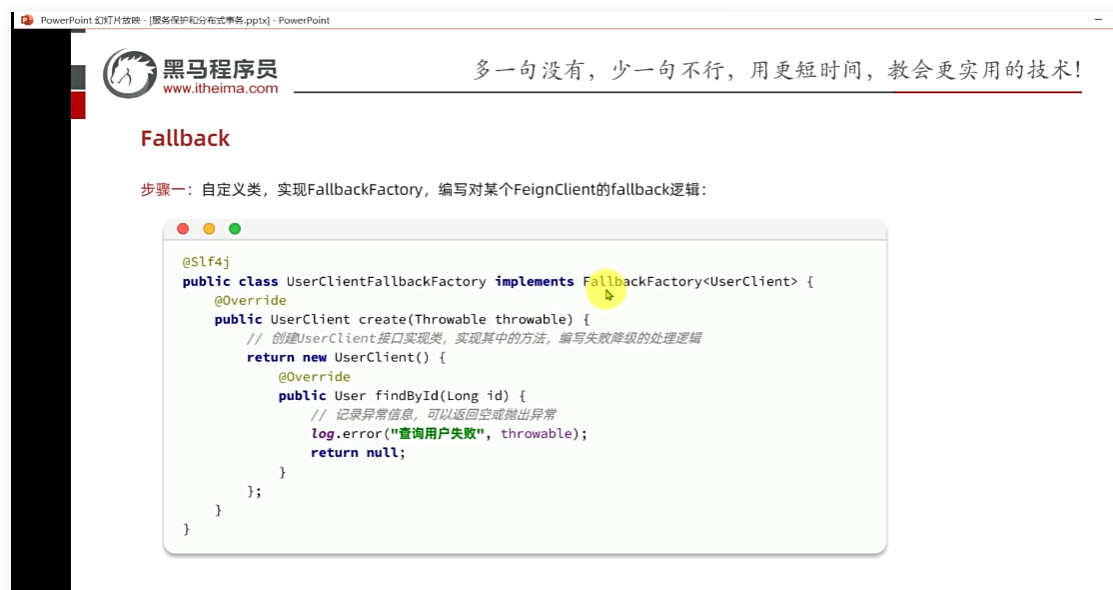
fallback:提前写好逻辑,后备处理方案,对于服务C的一个补充。
当有再次新的请求那么直接拒绝走fallback,少了等待卡死
不仅上面故障隔离,避免了服务A被拖死。还在这个熔断策略,避免无效资源浪费,提高了前端的响应速度
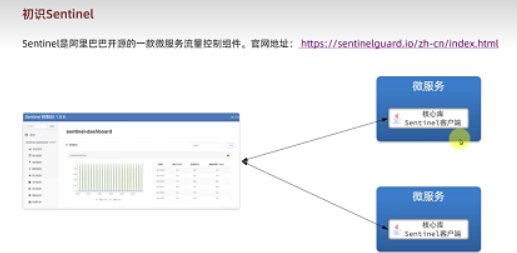
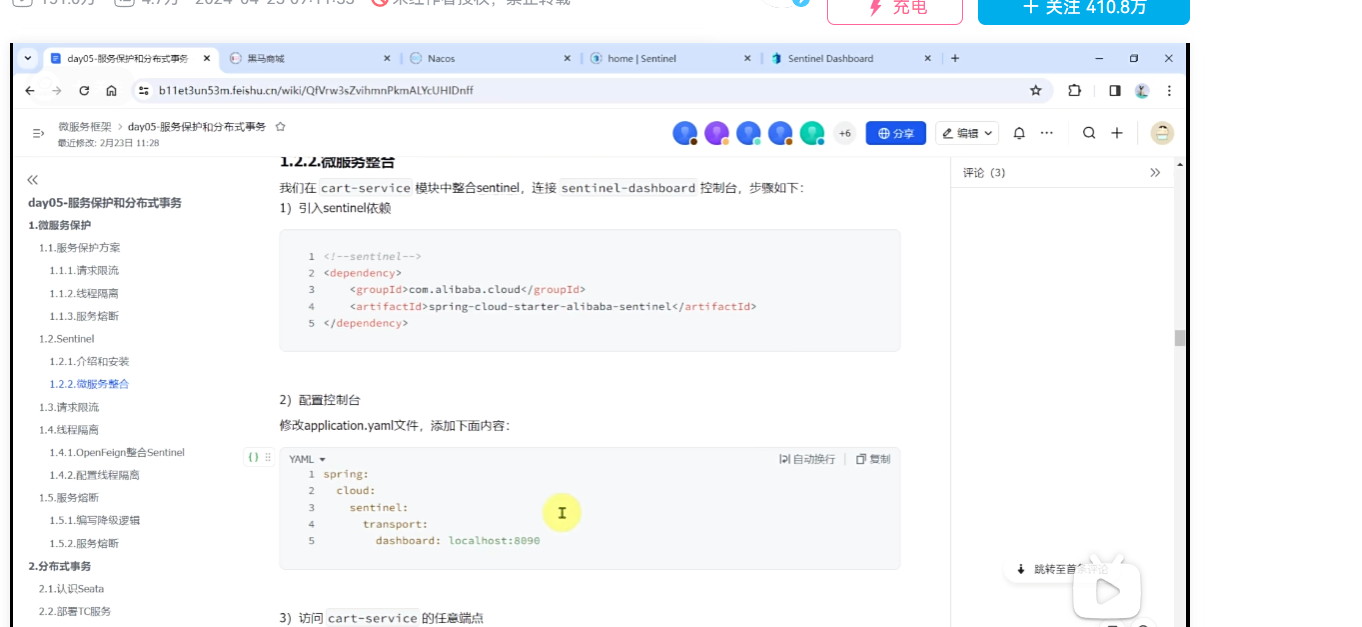
**sentinel配置:**导入相关依赖和配置,与控制台相连接,方便管理
java
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
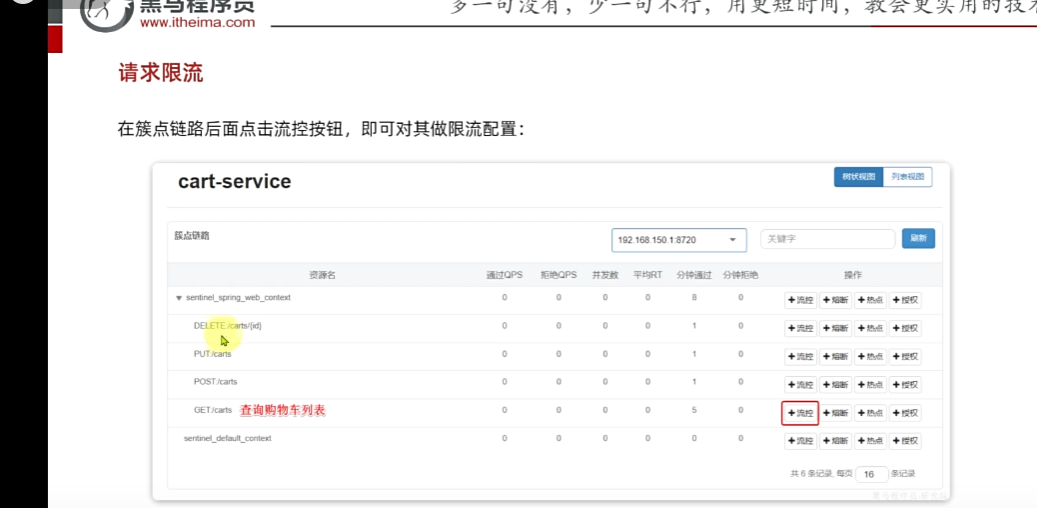
以上多调用几次该微服务就可以显示,例如调用购物车列表
**簇点链路:**意思就是那些Controller接口(监控http接口)
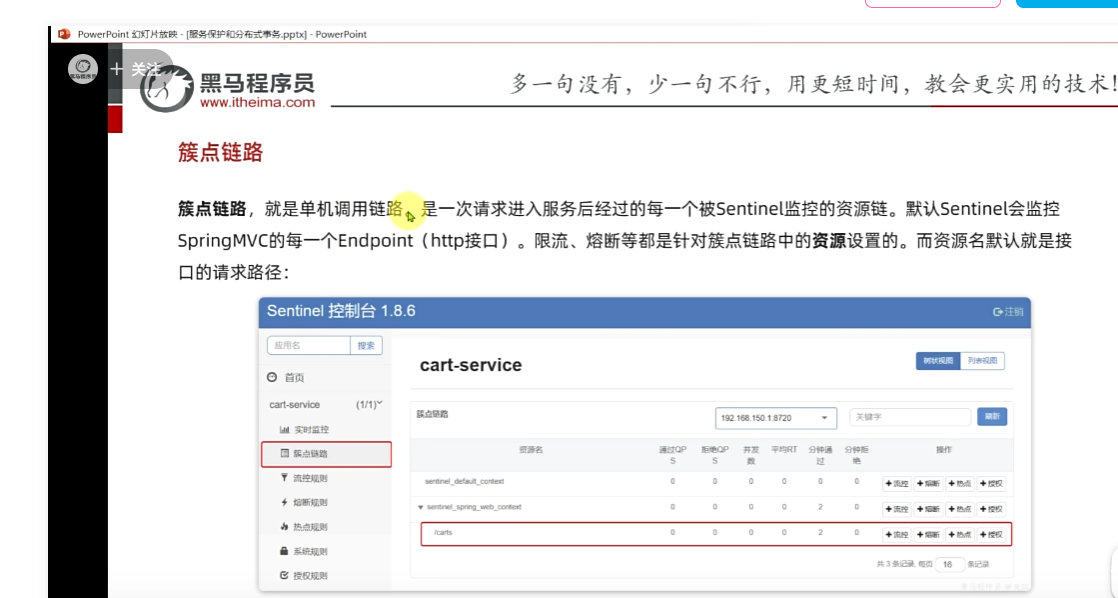
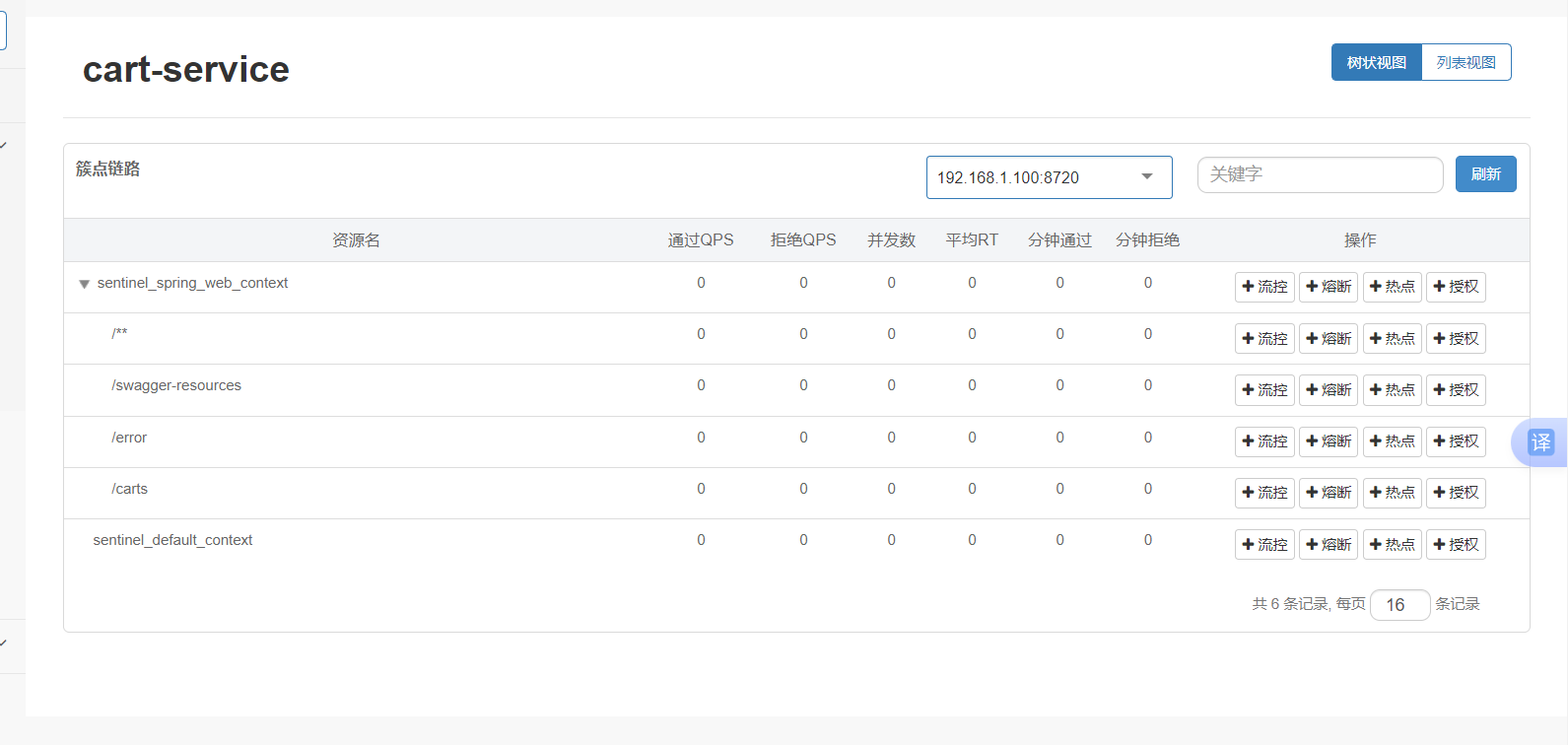
这里把carts作为簇点名称,以这个为唯一标识,但是我们发现我们这个都是restful风格的,路径都是相同,但是请求方式不同
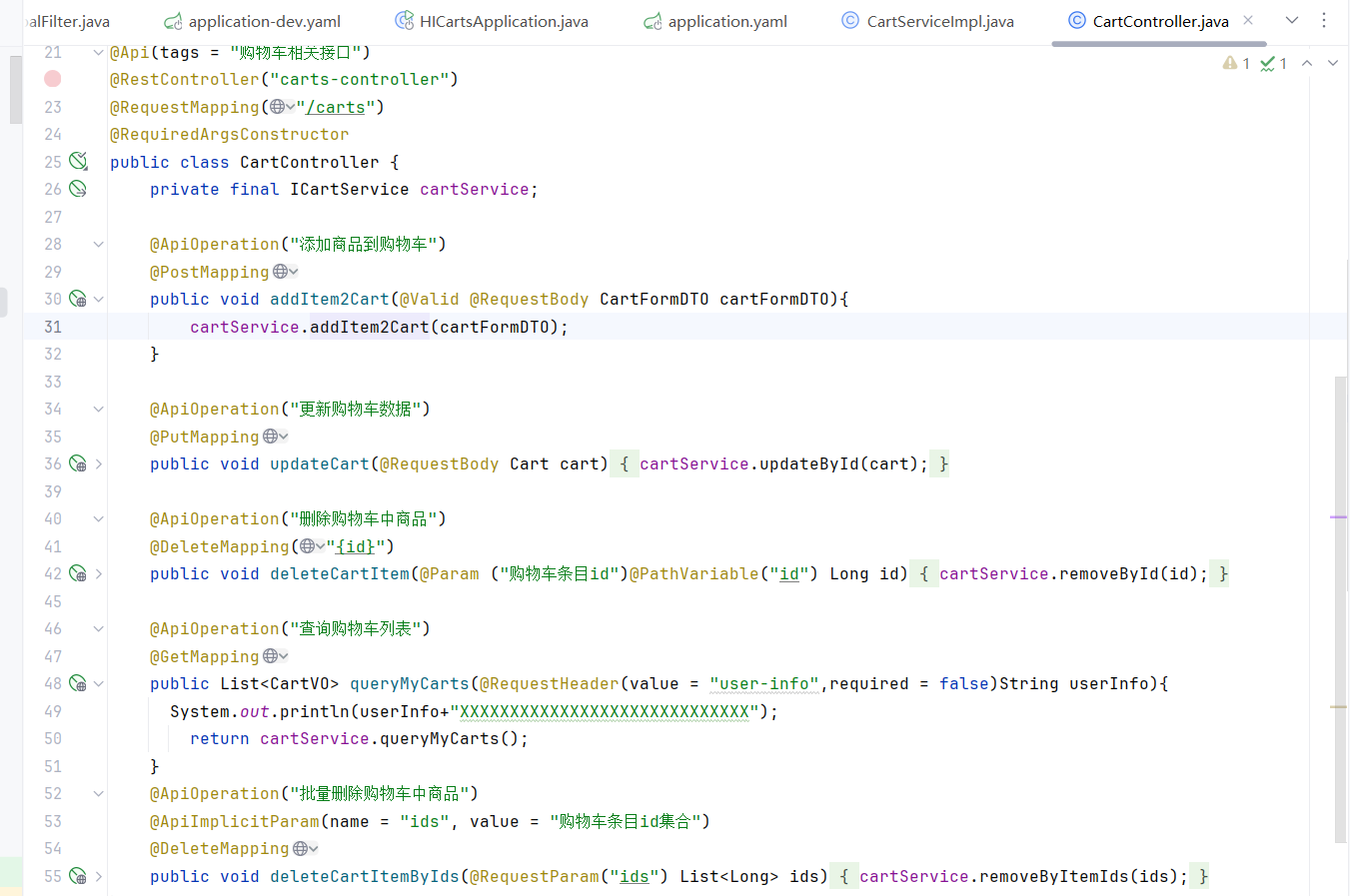
如何解决呢 加上这行
访问该微服务的各个接口,每个接口都分别地去做监控
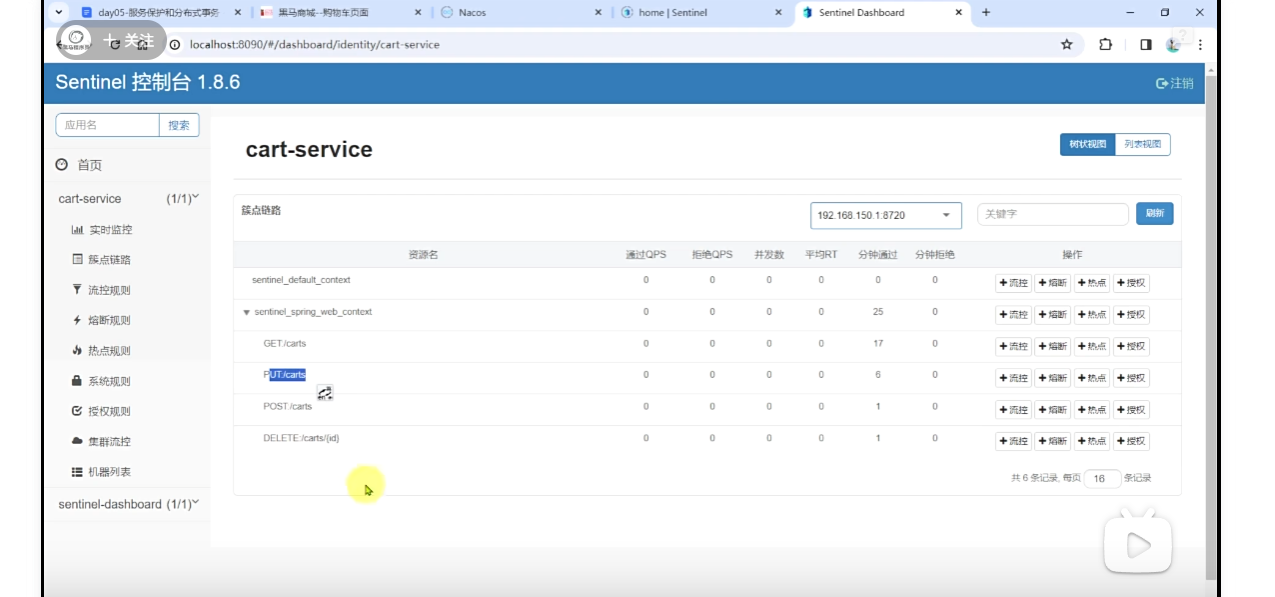
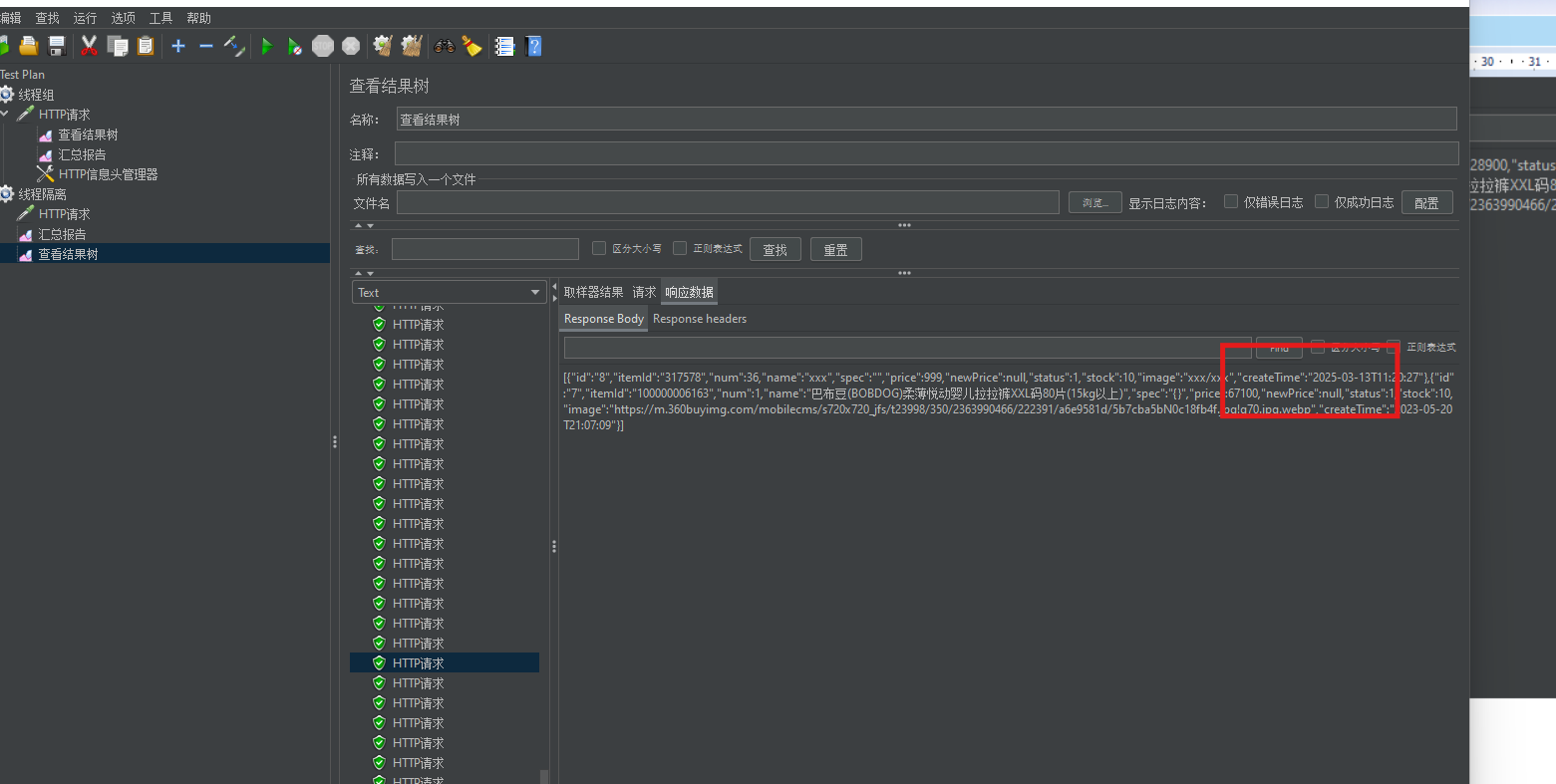
详细分析:过程使用Jmeter
请求限流:
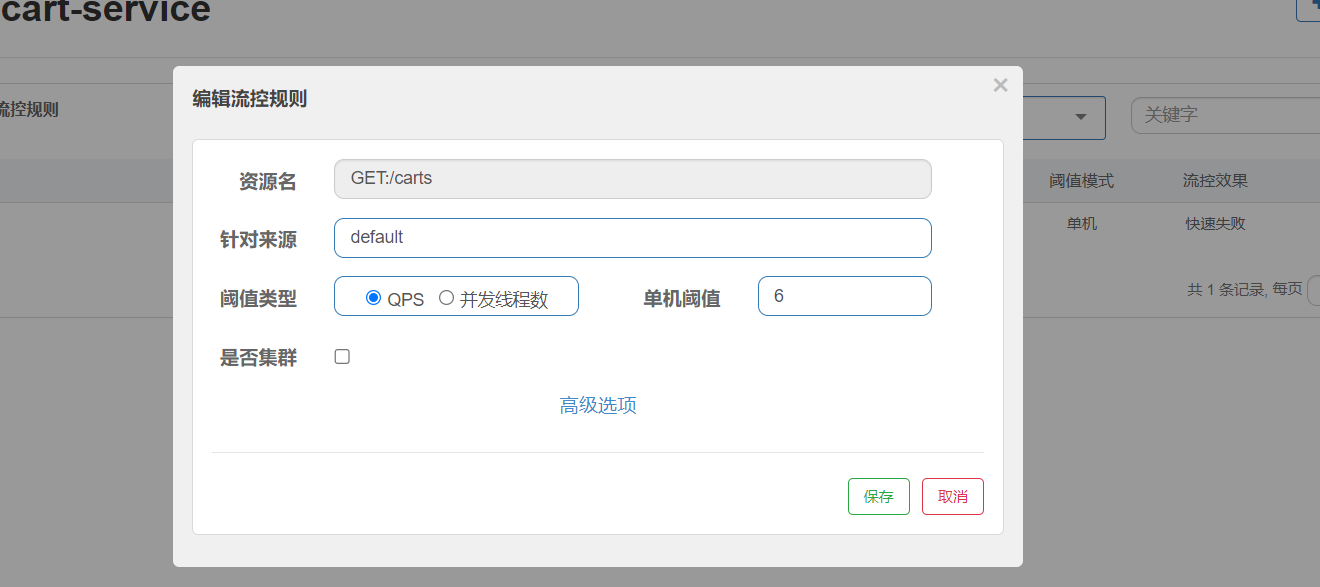
1.以购物车为例,**QPS:**每秒钟请求的数量,**单机阈值:**每秒钟多少个
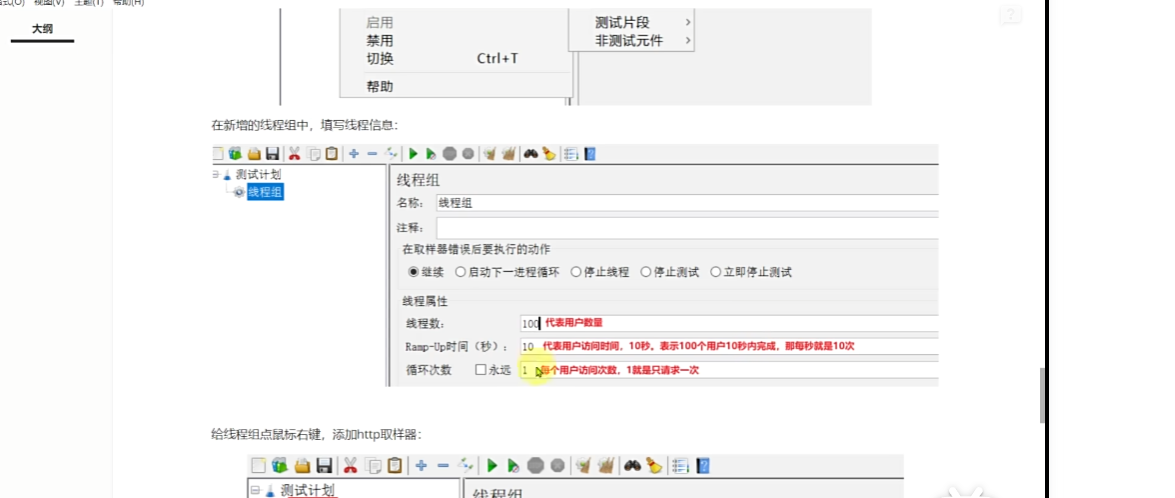
Jmeter: 在TestPlan->线程(用户)->然后线程组(模拟多个用户)
用户100个,发起请求总共耗时多久,多久把请求发完 100%10=10,就是每秒钟10个
每个用户发起一个请求
然后添加HTTP请求
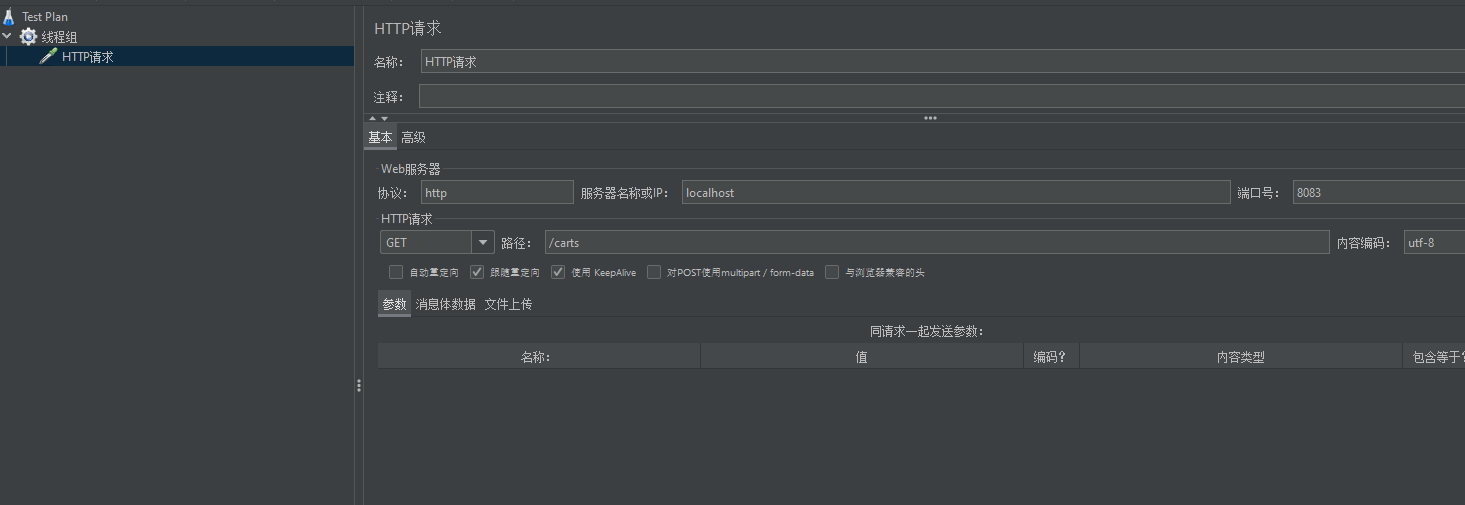
那么启动之后
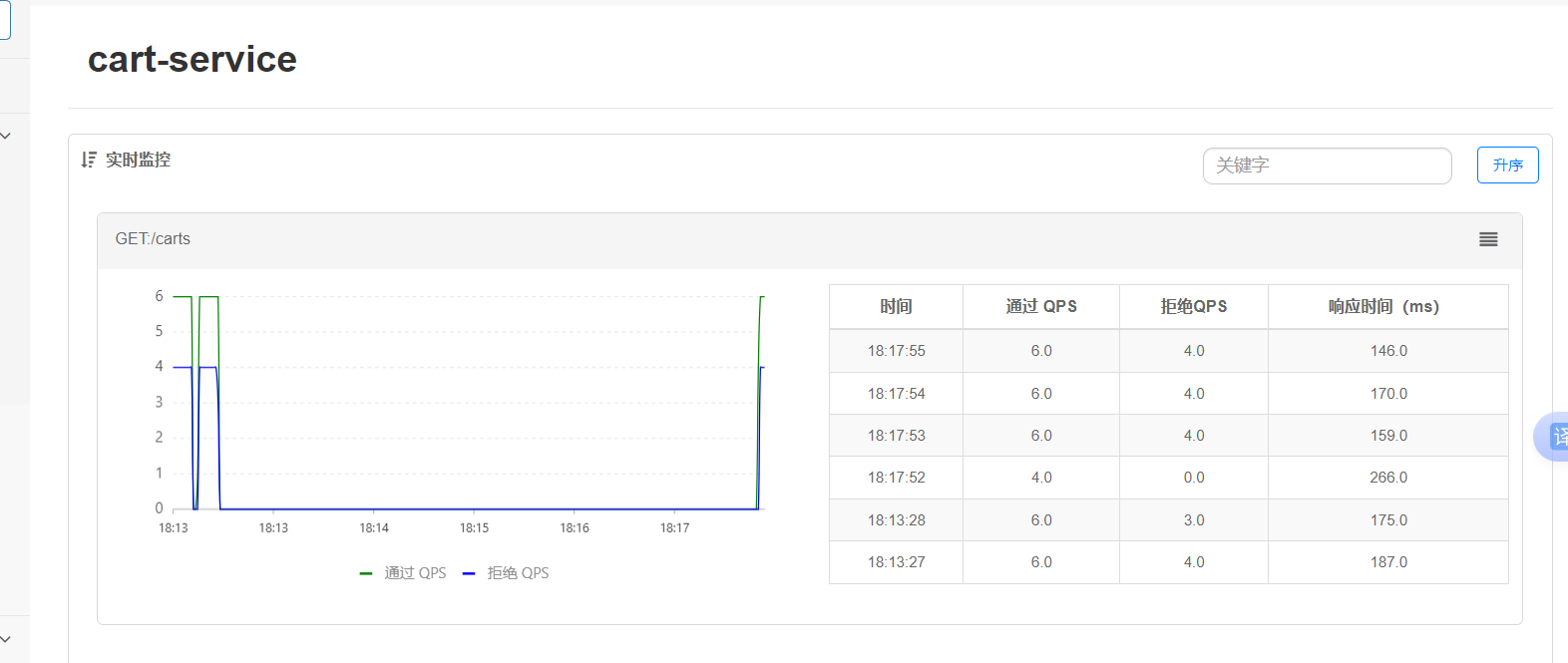
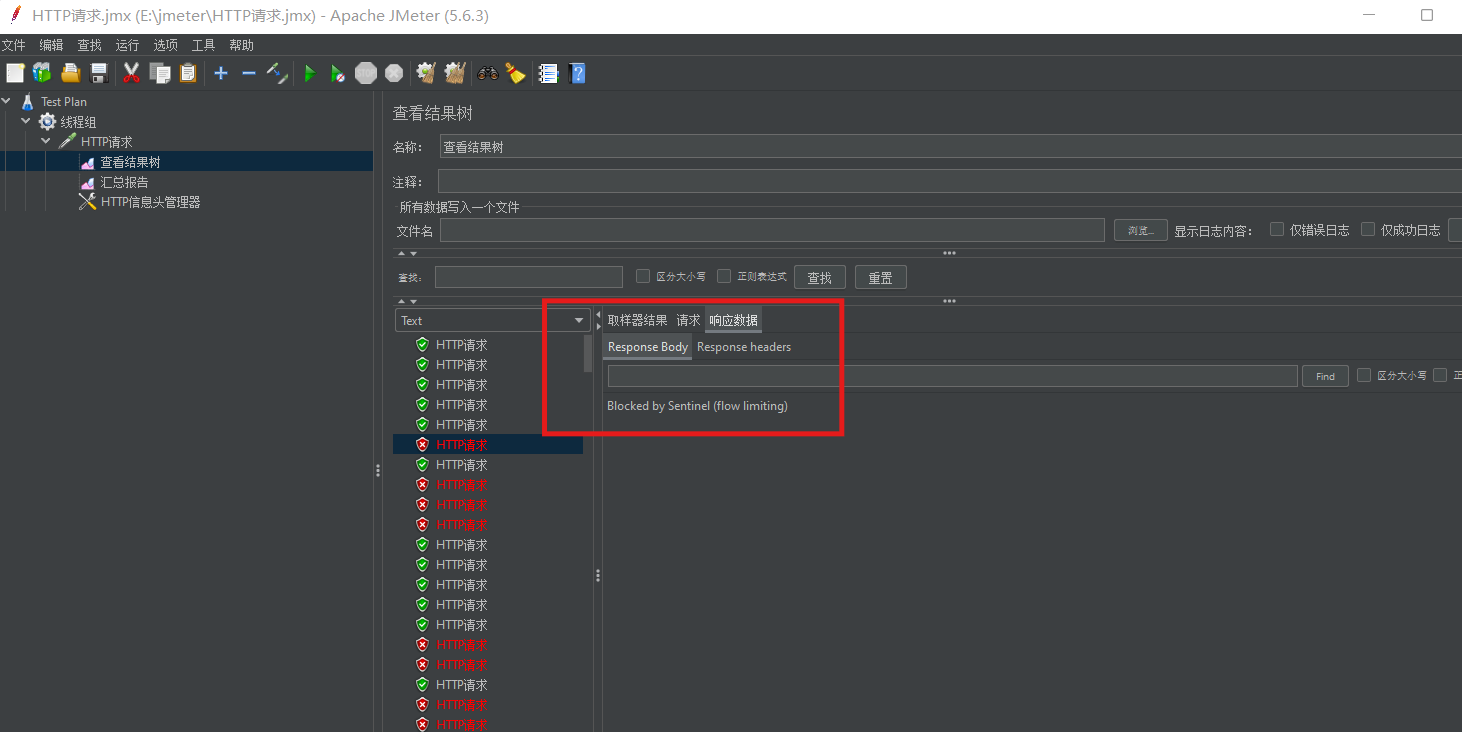
我们可以查看报告十个里面有4个就是说被拒绝了,并且异常为百分之40
报告如下:(如果访问的是429的状态码),比如秒杀,有可能你被限流了
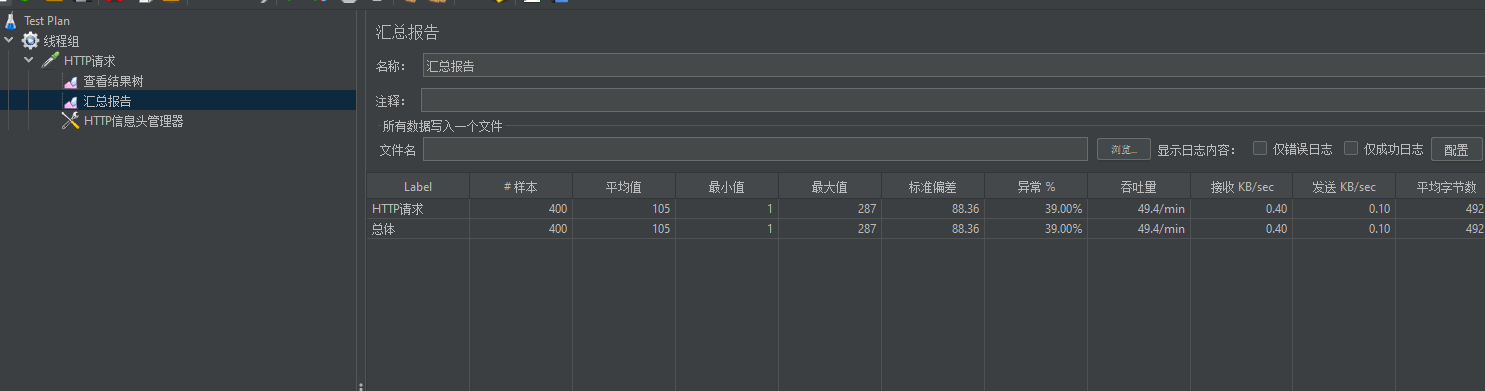
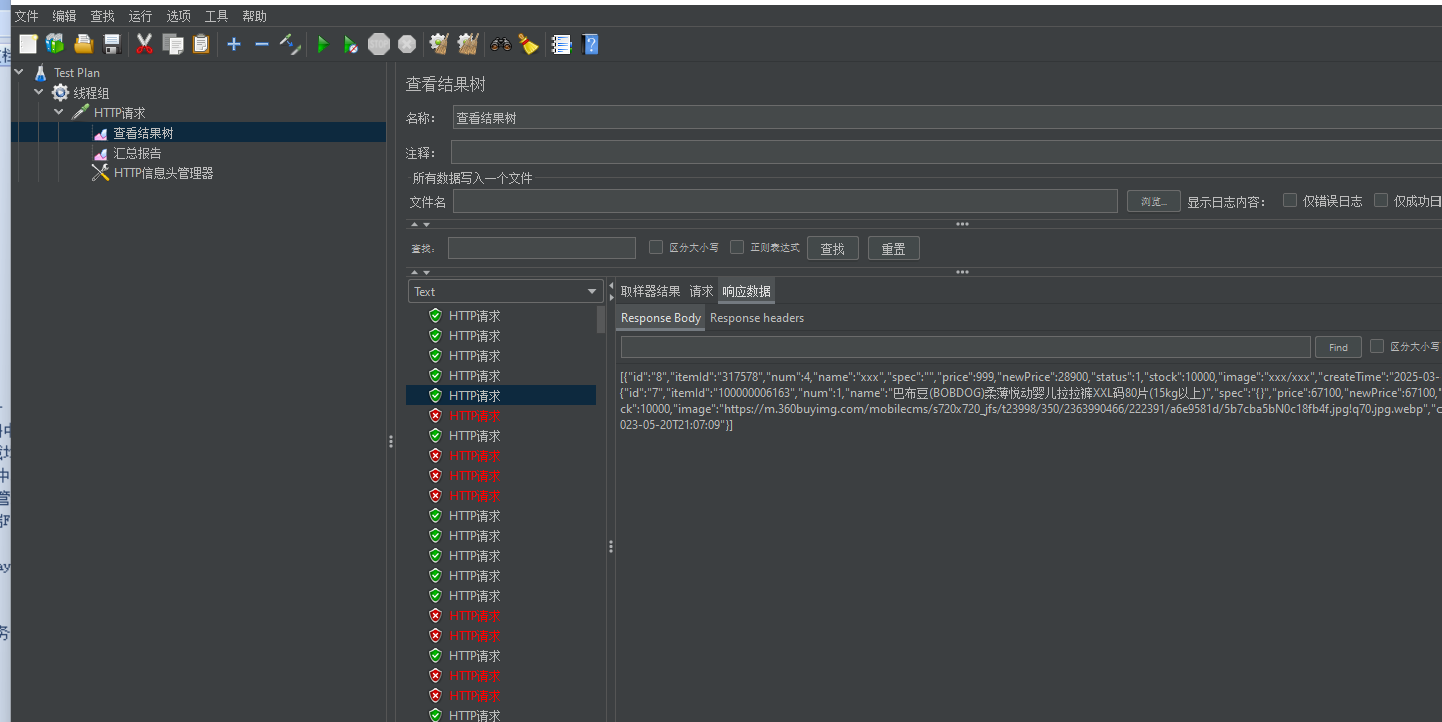
成功的案例:
线程隔离:
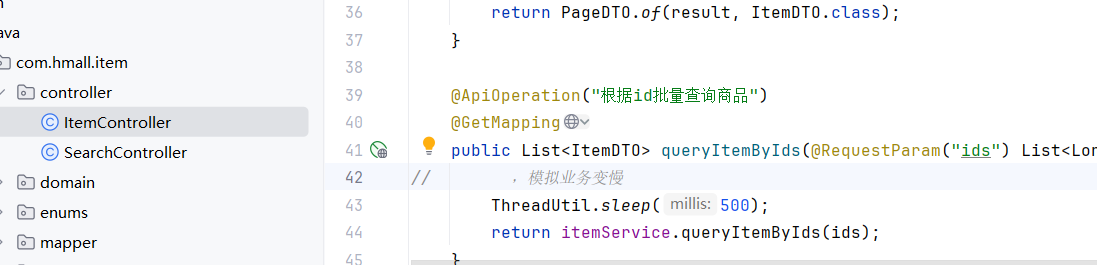
1.举例:查询购物车列表。模拟商品服务需要加载两秒到三秒然后才能返回给服务A,
把服务A的各个业务各自分配相应的线程数
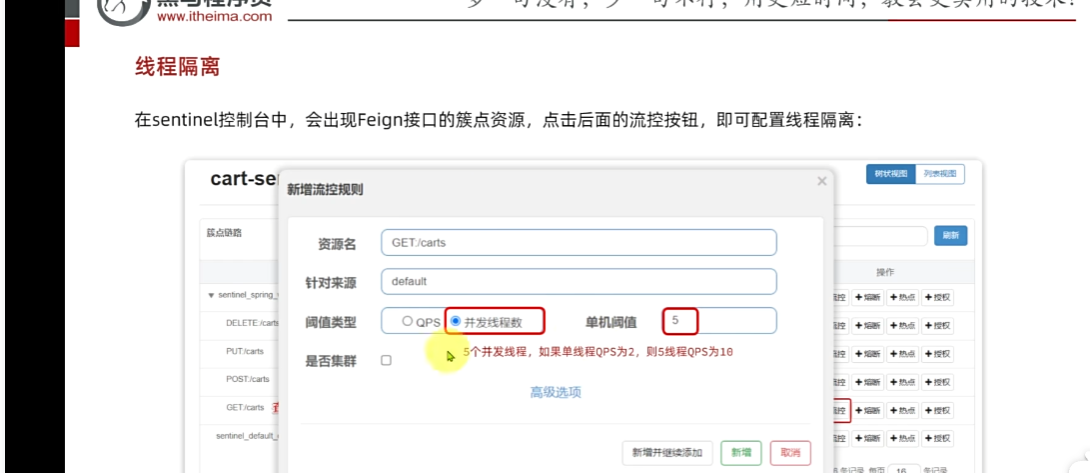
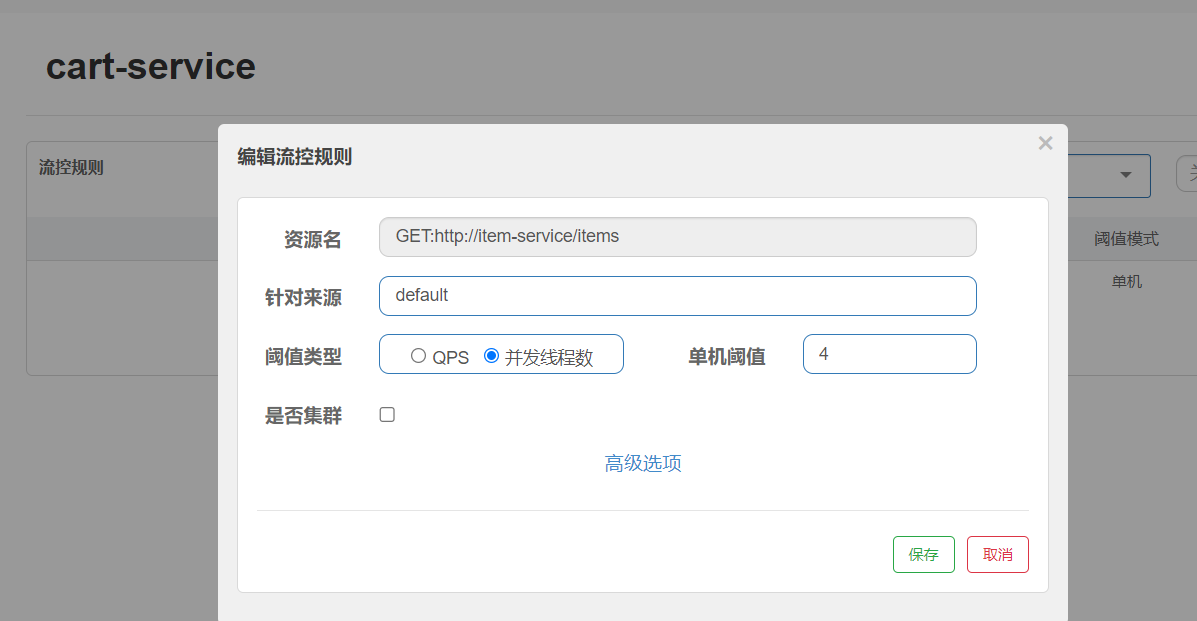
2.找到查询购物车的业务, 这个也是线程隔离也是流控的一部分,因为你要去隔离。
并发线程数: 线程可用资源数量。单机阈值,表示你可以用五个线程数;假设接口比较慢 返回一次需要500ms,那么一秒可以处理两次请求,一个线程每秒钟可以处理两个,五个就是每秒钟可以处理十个请求,也就是该接口允许每秒钟处理十个请求
我们现在就是模拟说并发比较高,把资源耗尽导致,添加购物车商品受影响
原本添加只需要22ms,查询:500ms
Jmeter模拟:
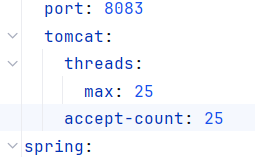
以上就是模拟了每秒钟最大的连接数,我们在tomcat已经设置好50
tomcat: max-connections: 50
刚刚只需要22ms,现在添加的接口资源被耗尽了。
以及极大可能导致查询失败。很慢很慢,查询连进都进不去,
商品服务变慢,导致了 购物车服务也被连累拖慢。如果并发进一步提高,那么可能挂了

如何解决?
我们设置好线程隔离
 、
、
画红色部分为添加购物车访问时长,丝毫没有受到影响,而查询直接访问失败

fallback:
我们在测试的时候,把线程数打满的情况下,添加和修改的访问时长没有受到任何影响,查询这个接口,响应时长很慢很慢,甚至出现报错,前端得不到响应,资源被耗尽,这个时候我们应该如何去解决?
通过fallback去缓解
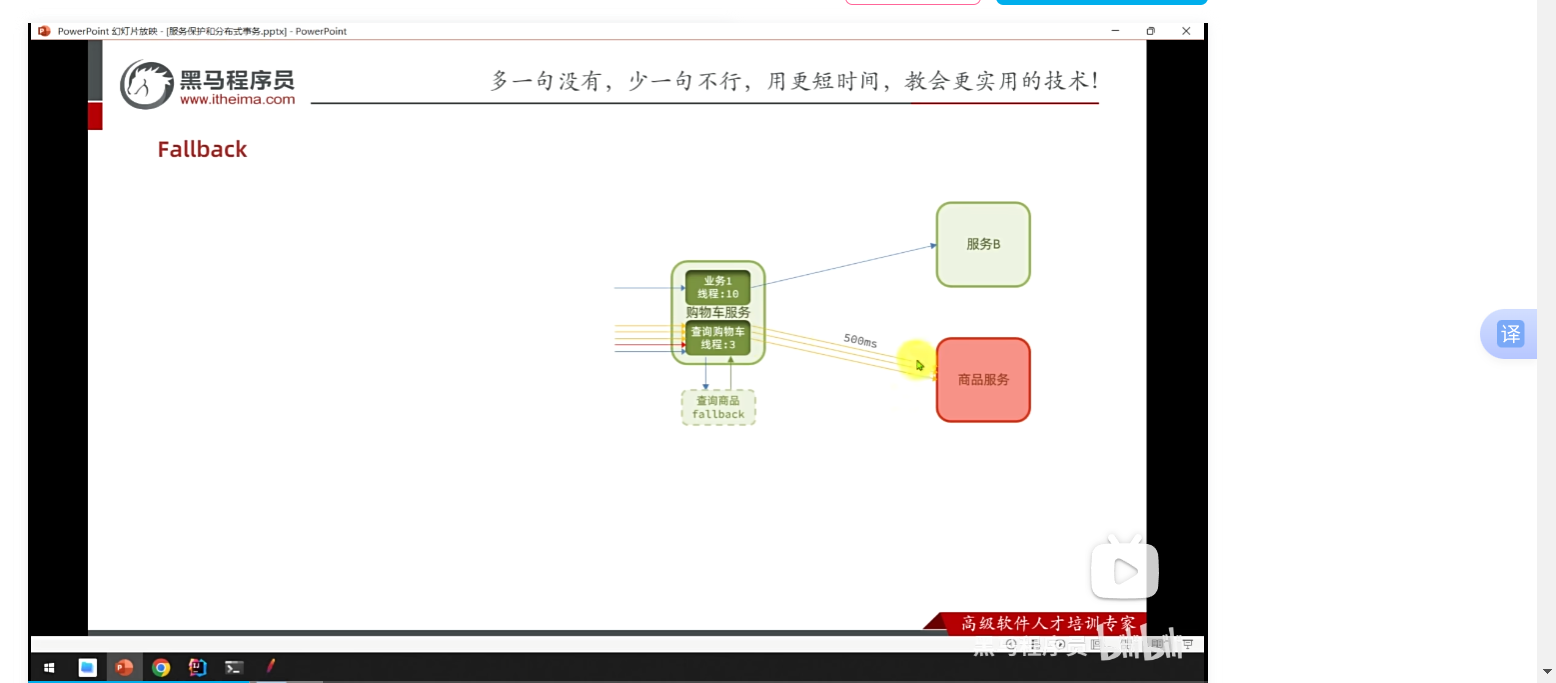
一瞬间来了很多请求,不会影响其他业务。但是,自身不可用,自身的资源被耗尽拒绝不再报错,而是给用户一个友好的提示。我们只对查询商品,我们对商品服务feign线程隔离,对购物车查询商品做fallback
所以
**第一:**让http远程调用也能被sentinel识别成为簇点。
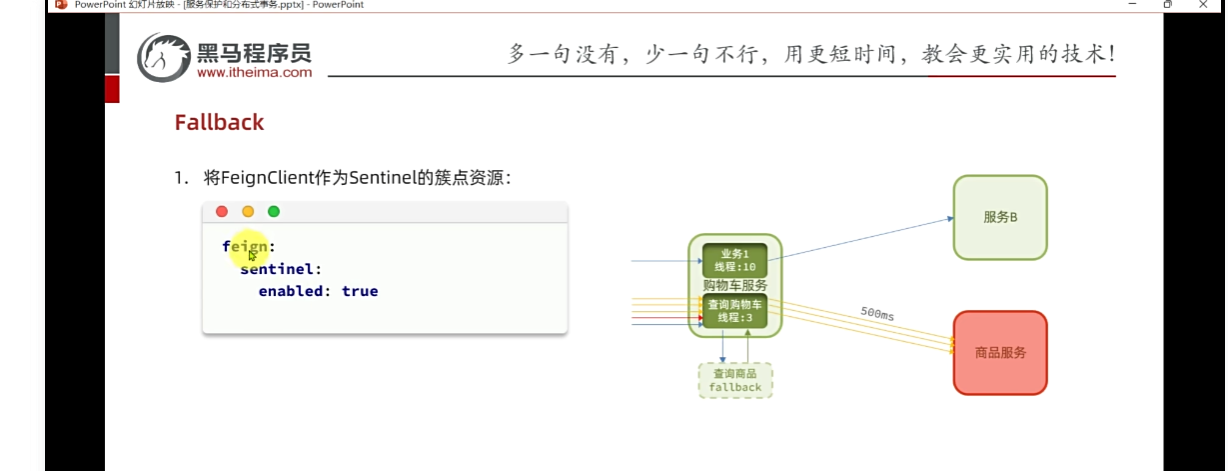
2.代表feign监控开启,开启流控,线程隔离,当线程打满的时候,拒绝新的请求,不想报错,添加fallback返回友好提示
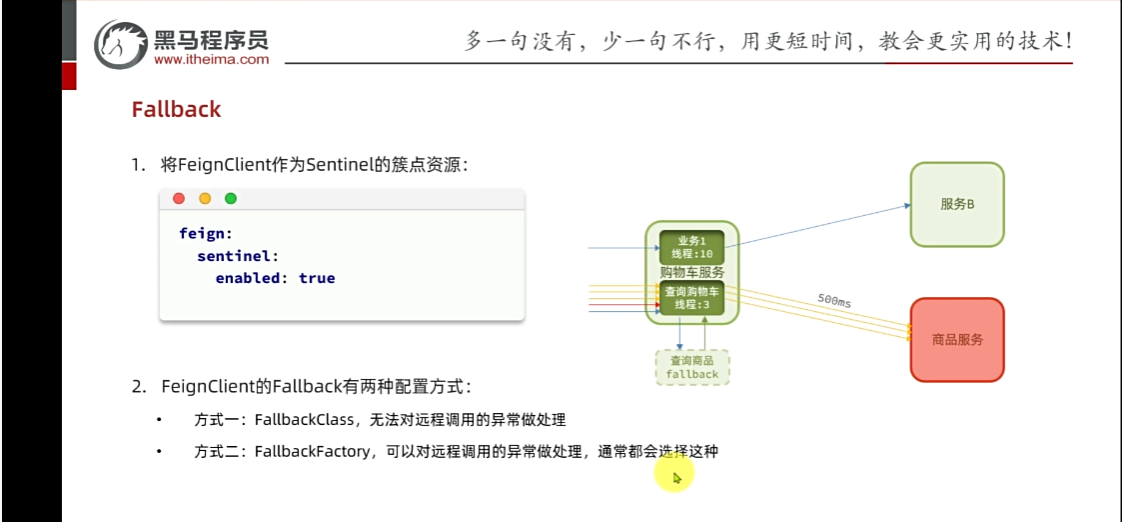
又多了一个链路,内部通过feign发起请求,开启feign监控后,那么就出现了
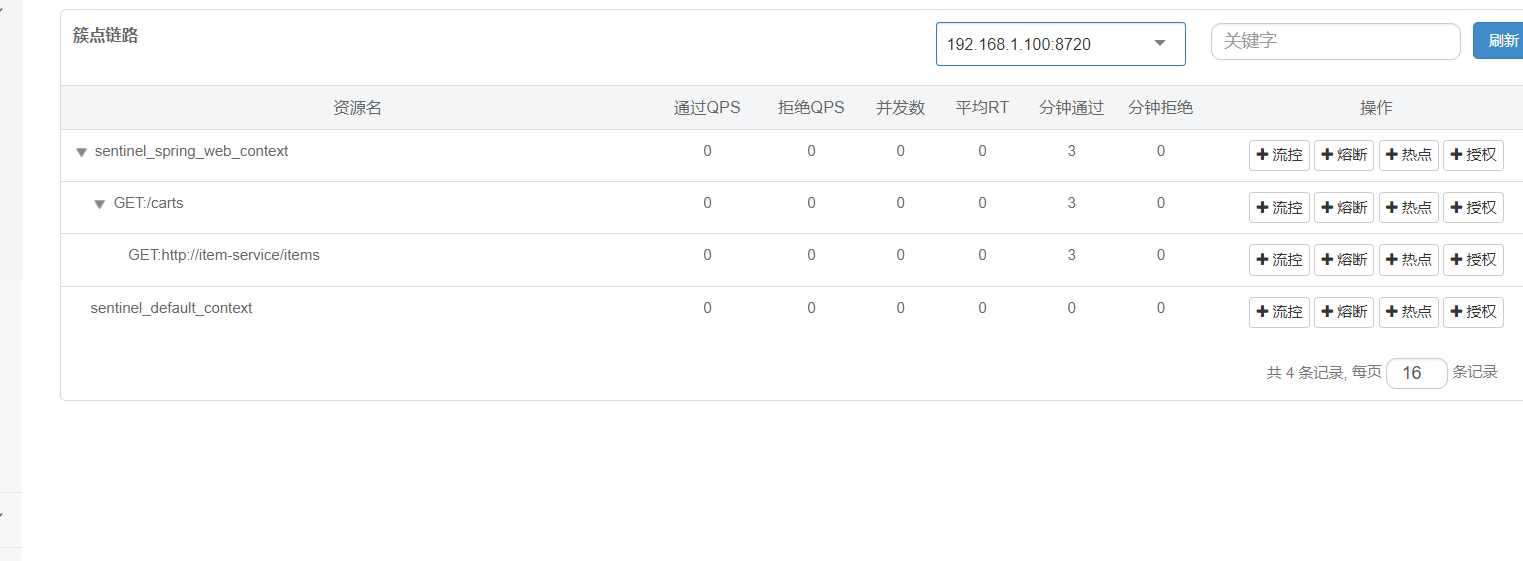
那么我现在不用对整个购物车中的查询商品进行线程隔离和流量控制,我仅仅对查这个feign的商品服务做线程隔离和流量控制,当我们的商品微服务出现故障的时候,我们只对商品微服务进行隔离,这样就没有问题,尽管你并发很高也不会把整个微服务资源耗尽
这里我配置的参数
不建议对整个查询购物车业务进行流量控制,一旦失败就都失败了,所以只针对feign
服务熔断:
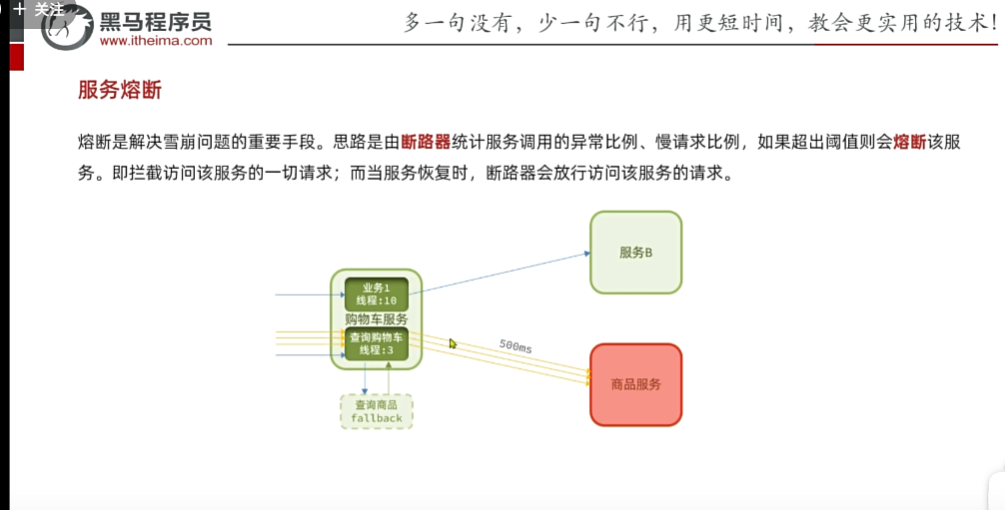
但是我们尽管做了线程隔离,但是我们卡的不会太多线程数,但是每一次请求来了都要做远程调用,又很耗时,浪费,这还是超时,如果挂了没必要再发起请求,
如果异常比例比较高,直接熔断,拒绝发起请求,然后再走fallback这是优化后的最优解。
熔断也不能一直断开,如果恢复正常还要取消熔断。
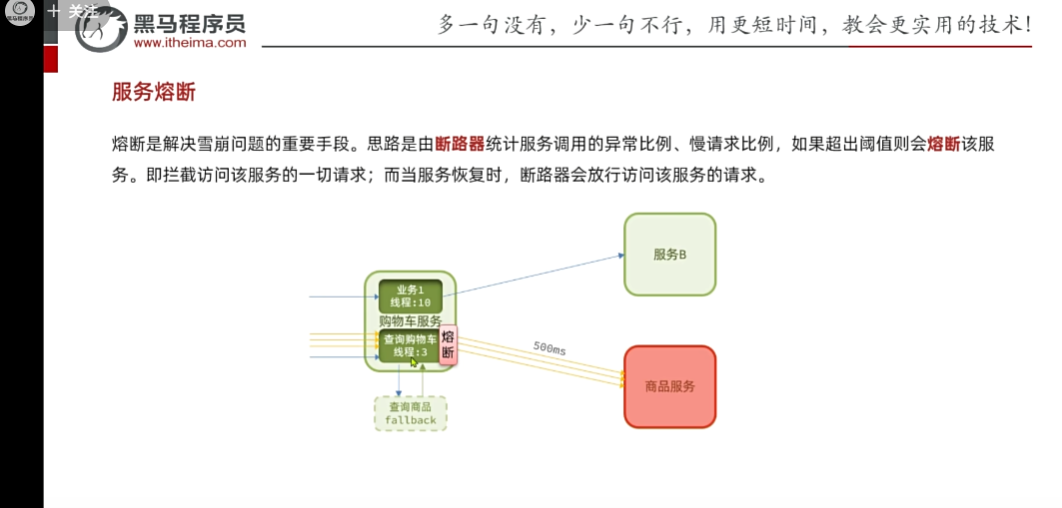
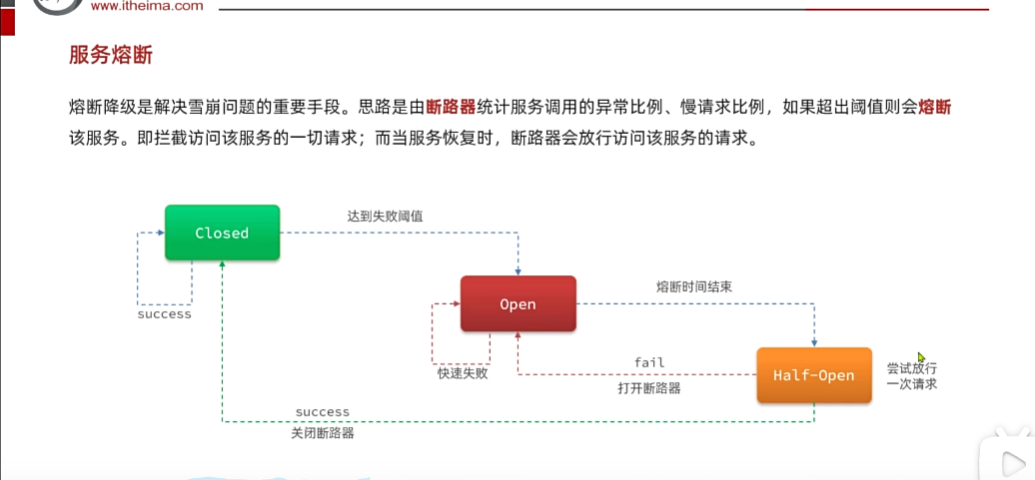
现在还有一个问题就是,什么时候熔断,什么时候断开?
断路器可以帮助我们
默认是绿色状态,表示可以正常访问,同时会去监控经过断路器的请求,如果发现比例过高达到阈值,直接open(持续时间可配置),熔断时间到期后,会去走到测试half,那么
检查一下服务有没有恢复,没有恢复就回到open,到期后,再次进行检查,如果成功了,就关闭
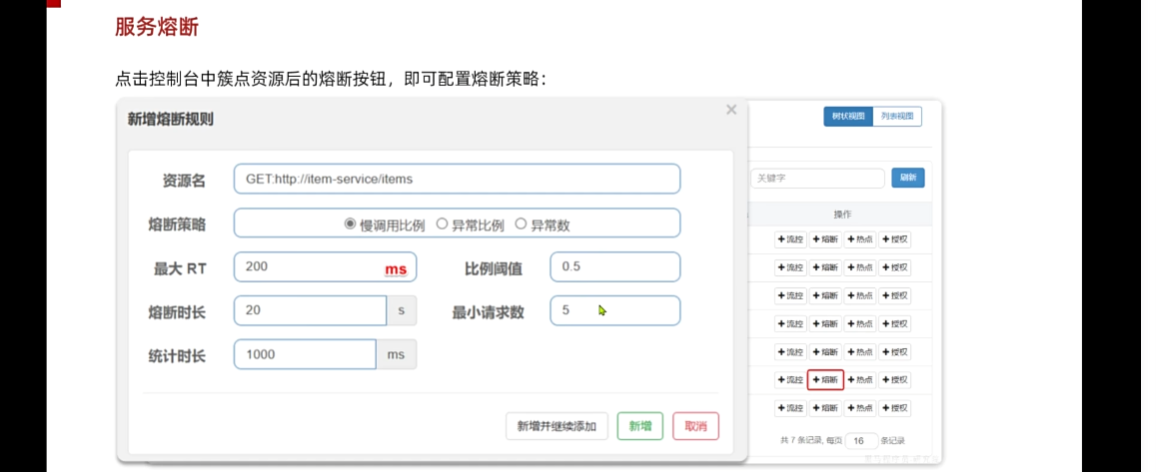
我们仅仅要做的就是在sentinel中做好配置 点击熔断查看规则
慢调用比例: 十次请求多少次请求很慢
RT: 最大响应时间 代表如果我发出这个请求超出200ms,那么就算是慢的,低于两百不统计
比例阈值: 那么就是慢多少达到阈值,超过百分之50,那么就达到阈值我就需要给你熔断,比如十次有五次
熔断时长: 就是触发熔断,open的临时状态,拒绝所有的请求,不发起远程调用,减少资源浪费
最小请求次数: 就是统计的次数,最少发起几次 然后查看是否达到0.5
统计时长:多少作为周期进行统计,1s只要请求数量为几次,失败多少次然后就触发
测试:
熔断后你会发现查询购物车速度变快很多,因为它不会再去远程调用,不会再去查商品
之前:

改进后:

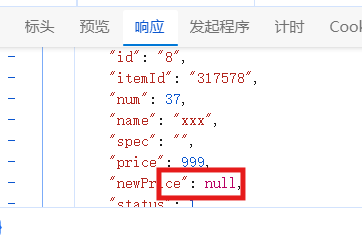
熔断结束了,我们发行一次检测都是七百多那么没事了,如果有超过继续熔断
