文章目录
-
- 迭代高级特征跨尺度融合
- 高效的低层次特征跨尺度融合
- [KDA:Key-aware Deformable Attention](#KDA:Key-aware Deformable Attention)
论文翻译: CVPR 2023 | Lite DETR:计算量减少60%!高效交错多尺度编码器-CSDN博客
DINO团队的
(Lightweight Transformer for Object Detection)它是对DETR(Transformers for Object Detection)模型的一种轻量级改进,在保持模型性能的同时,成功将Encoder的计算开销减少了50%
改进的是Encoder,提出交错的多尺度Encoder,

对低层级的特征图的token来说,将会耗费太多的计算量,模型的性能提升也比较少,但是也不能去掉这些低层级的特征,因为很多检测需要低层级的特征提供信息。如上图所示,去掉低层级的特征图,Encoder的计算量会得到大幅度的降低,相应小目标的检测精度也会下降,大目标的检测精度没有太大影响。
下图是各个特征图的token数量占总token的比例

如下图所示, S1 ∼ S3 作为高级特征 ,(a) 是 3.4 节中讨论的建议的高级特征更新,(b) 是 3.5 节中讨论的低级特征跨尺度融合。在每个高效编码器块中,多尺度特征将经过 A 次高级特征更新,然后在每个块的末尾进行低级特征更新。高效编码器块将执行 B 次。
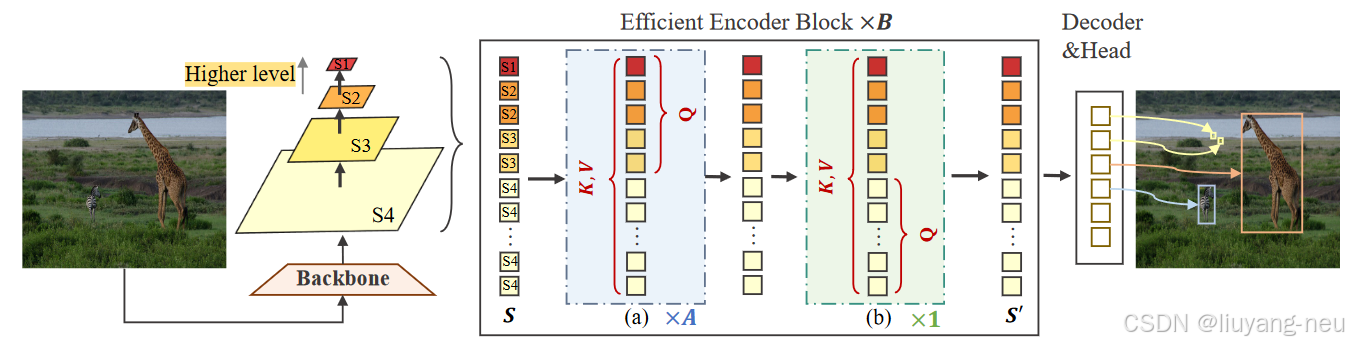
迭代高级特征跨尺度融合
在不同的设置中,FH 可以包含前三个或两个刻度,为清楚起见,我们默认将 FH 设为 S1、S2、S3,将 FL 设为 S4。FH 被视为主要特征,更新频率较高,而 FL 更新频率较低。
在该模块中,高层特征 FH 将作为查询(Q),从所有尺度中提取特征,包括低层和高层特征标记。这一操作增强了高层语义和高分辨率细节对 FH 的表示。例如,如表 2 所示,在前两个尺度或前三个尺度中使用多尺度特征查询将分别大幅减少 94.1% 和 75.3% 的查询次数。我们还使用了将在第 3.6 节中讨论的关键字感知注意力模块 KDA 来执行注意力和更新标记。
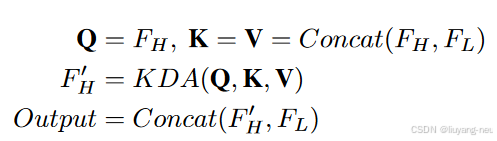
高效的低层次特征跨尺度融合
低级特征包含过多的标记,这是导致计算效率低下的关键因素。因此,高效编码器会在一系列高级特征融合之后,以较低的频率更新这些低级特征。具体来说,我们利用初始低层次特征作为查询,与更新的高层次标记以及原始低层次特征进行交互,以更新它们的表示。与高层特征更新类似,我们也使用了与 KDA 注意层的交互。
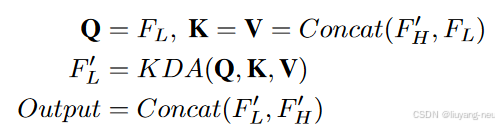
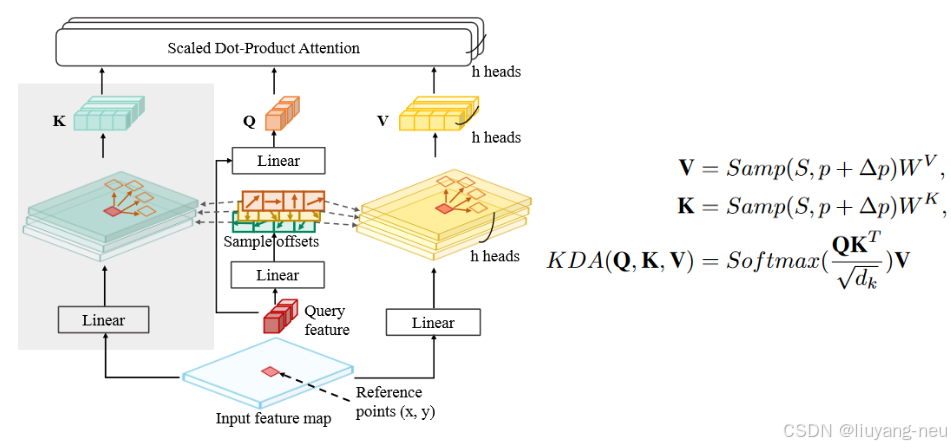
KDA:Key-aware Deformable Attention