1、背景
最近我们在云服务器上部署的后端Java程序被操作系统给杀死了。那么我们有没有快捷的方法知道我们的服务是否存活,可实现的方法有很多,此处记录下如何通过shell脚本来进行服务的检测,并进行邮件的发送。
2、需求
- 通过shell脚本可以检测多个服务是否存活,若服务停止了,则发送一封邮件告知对应的人。
- 30分钟内,若服务还是处于未上线状态,则不进行邮件的发送。
- 若服务再次上线,则需要进行邮件的通知。
3、实现步骤
1、安装邮件发送客户端
1.安装mailx
shell
yum install mailx2. 配置mailx
此处以QQ邮箱配置为例
shell
vi /etc/mail.rc
set from=your_email@qq.com
set smtp="smtps://smtp.qq.com:465"
set smtp-auth-user=your_email@qq.com
set smtp-auth-password=your_auth_code
set smtp-auth=login
set smtp-ssl=yes
set nss-config-dir=/etc/pki/nssdb
set ssl-verify=ignore- set from:设置发件人邮箱地址。
- set smtp:设置 SMTP 服务器地址,QQ 邮箱为 smtp.qq.com。
- set smtp-auth-user 和 set smtp-auth-password:分别设置 SMTP 认证的用户名和密码。
注意,此处的密码应为 QQ 邮箱的授权码,而非登录密码。 - set smtp-auth=login:指定认证方式为 login。
- set nss-config-dir:指定 NSS 证书的存放目录,CentOS 7 默认为 /etc/pki/nssdb。
- set ssl-verify=ignore:忽略 SSL 证书验证,避免因证书问题导致邮件发送失败
3. 测试邮件的发送
shell
echo "邮件内容" | mailx -d -s "邮件主题" 1451578387@qq.com-d: 表示开启debug模式,邮件不会真正的发送出去。
-v: 表示显示详细信息
2.编写服务检测脚本
shell
#!/bin/bash
###############################################################################
# 服务状态监控告警脚本
# 功能:带详细邮件日志的服务监控,支持敏感信息过滤、日志审计和IP地址追踪
# 部署步骤:
# 1. 将脚本保存为 /usr/local/bin/service_monitor.sh
# 2. 创建配置文件 /etc/service_monitor.conf(可参考脚本内默认配置)
# 3. 设置执行权限:chmod +x /usr/local/bin/service_monitor.sh
# 4. 添加cron任务(例如每5分钟执行一次):
# */5 * * * * /usr/local/bin/service_monitor.sh >> /var/log/service_monitor_cron.log 2>&1
# 5. 安装邮件工具:apt-get install mailutils -y(Debian/Ubuntu)或 # 安装mailx软件包(包含mail命令)sudo yum install mailx -y(centos7)
# 6. 修改配置文件:vim /etc/service_monitor.conf,设置正确的邮箱、服务列表等
# 7. 首次运行前创建锁文件目录:mkdir -p /var/lock/service_monitor
# 依赖:bash 4.2+,systemctl/pgrep,mailutils,gzip
###############################################################################
#################################### 配置加载 ###################################
# 默认配置文件路径(使用绝对路径确保稳定性)
# 作用:指定全局配置文件位置,优先级高于脚本内默认值
# 示例:若存在/etc/service_monitor.conf,会读取其中的变量如EMAIL=ops@company.com
DEFAULT_CONFIG_FILE="/etc/service_monitor.conf"
# 加载配置文件(存在则覆盖默认配置)
# 原理:使用source命令执行配置文件,将其中定义的变量导入当前Shell环境
# 示例:配置文件中定义SERVICES=("nginx" "mysql")会覆盖脚本默认的服务列表
[ -f "$DEFAULT_CONFIG_FILE" ] && source "$DEFAULT_CONFIG_FILE"
################################# 默认配置参数 #################################
# 使用${VAR:-default}语法设置默认值,确保变量未定义时使用安全默认值
# 邮件配置
# @param EMAIL 主告警邮箱地址,支持多个邮箱用空格分隔(如"admin@a.com admin@b.com")
declare -g EMAIL="${EMAIL:-admin@example.com}" # 主告警邮箱
# @param MAIL_RETRIES 邮件发送失败时的重试次数,避免因网络波动导致告警丢失
declare -gi MAIL_RETRIES=${MAIL_RETRIES:-3} # 发送重试次数
# @param MAIL_DELAY 重试间隔时间(秒),防止频繁重试占用资源
declare -gi MAIL_DELAY=${MAIL_DELAY:-5} # 重试间隔秒数
# 服务配置
# @param SERVICES 监控的服务列表,systemd服务直接写服务名,非systemd服务写进程名
declare -ga SERVICES=(${SERVICES[@]:-"user_info_service" "shop_info_service"}) # 监控服务列表
# 路径配置
# @param RECORD_FILE 服务状态记录文件,存储宕机时间戳(格式:服务名,首次宕机时间,最后通知时间)
declare -g RECORD_FILE="${RECORD_FILE:-/var/lib/service_monitor/status_record}" # 状态记录
# @param LOG_FILE 主日志文件,记录所有监控活动和系统事件
declare -g LOG_FILE="${LOG_FILE:-/var/log/service_monitor.log}" # 主日志路径
# @param LOCK_FILE 锁文件路径,防止脚本并发执行导致数据混乱
declare -g LOCK_FILE="${LOCK_FILE:-/var/lock/service_monitor/monitor.lock}" # 锁文件路径
# @param ENABLE_SYSTEMD_CHECK 是否使用systemd检测模式(true/false)
# true:使用systemctl检测服务状态(适用于systemd管理的服务)
# false:使用pgrep检测进程存在(适用于普通进程)
declare -g ENABLE_SYSTEMD_CHECK=${ENABLE_SYSTEMD_CHECK:-false} # 检测模式
# 日志配置
# @param MAX_LOG_SIZE 单个日志文件最大大小(字节),超过后自动轮转
declare -gi MAX_LOG_SIZE=${MAX_LOG_SIZE:-10485760} # 日志轮转大小(10MB)
# @param LOG_BACKUPS 保留的历史日志版本数,避免日志占用过多磁盘空间
declare -gi LOG_BACKUPS=${LOG_BACKUPS:-5} # 历史日志版本数
# @param MAIL_DETAIL_RETENTION 邮件详情日志保留天数,到期自动清理
declare -gi MAIL_DETAIL_RETENTION=${MAIL_DETAIL_RETENTION:-30} # 邮件日志保留天数
# 检测配置
# @param ALERT_INTERVAL 同一服务连续告警的最小间隔(秒),避免告警风暴
declare -gi ALERT_INTERVAL=${ALERT_INTERVAL:-1800} # 告警间隔(30分钟)
# @param MAIL_LOG_FILTERS 敏感词过滤列表,使用正则表达式匹配(支持部分匹配)
declare -ga MAIL_LOG_FILTERS=(${MAIL_LOG_FILTERS[@]:-"password" "token" "api_key"}) # 敏感词过滤
################################## 初始化检查 ##################################
# 创建锁文件目录
mkdir -p /var/lock/service_monitor
# 创建必要目录结构(带错误处理)
# 作用:确保状态记录和日志文件的父目录存在,避免因目录缺失导致写入失败
# 示例:若RECORD_FILE=/var/lib/service_monitor/status_record,则创建/var/lib/service_monitor
mkdir -p "$(dirname "$RECORD_FILE")" "$(dirname "$LOG_FILE")" || {
echo "错误:目录创建失败,错误码:$?" >&2 # >&2表示输出到标准错误
exit 1 # 非零退出码表示脚本执行失败
}
# 设置文件安全权限
# chmod 600:仅文件所有者可读可写(状态记录文件包含敏感时间数据)
chmod 600 "$RECORD_FILE" 2>/dev/null # 状态文件私有读写,忽略无文件时的错误
# chmod 644:所有者可读可写,其他用户可读(日志文件需要运维团队查看)
chmod 644 "$LOG_FILE" 2>/dev/null # 日志全局可读,忽略无文件时的错误
# 初始化文件锁(使用文件描述符9)
# 作用:通过文件描述符9关联锁文件,实现脚本的单实例运行
# 原理:flock命令通过文件描述符操作锁,避免多个进程同时执行监控
exec 9>"$LOCK_FILE" || exit 1 # 关联锁文件到描述符9,失败则退出
# 非阻塞获取锁,防止并发执行
# flock -n:非阻塞模式,若锁已被占用则立即返回失败
# 示例:当前脚本正在运行时,新实例会输出提示并退出
flock -n 9 || {
echo "[$(date +%F%T)] 错误:检测到并发执行,当前实例退出" >&2
exit 0 # 零退出码表示正常退出(因已存在实例)
}
################################## 函数定义 ###################################
# ---------------------------
# 函数:增强型日志记录
# @param $1 日志级别(INFO/WARN/ERROR/SYSTEM等,默认INFO)
# @param $2 日志信息(必填,支持多行文本)
# @usage logger "ERROR" "磁盘空间不足,剩余空间<5%"
# 功能:生成带时间戳、日志级别、进程ID的标准日志条目,并处理日志轮转
# ---------------------------
logger() {
local level="${1:-INFO}" # 若未传级别,默认使用INFO
local message="$2" # 日志具体内容(支持变量和特殊字符)
local timestamp=$(date '+%Y-%m-%d %H:%M:%S') # 获取当前时间戳(YYYY-MM-DD HH:MM:SS)
# 生成标准日志格式:[时间戳] [级别] [PID:进程ID] 日志信息
# $$ 表示当前Shell进程的PID,例如:[2023-10-01 12:00:00] [ERROR] [PID:12345] 服务启动失败
local log_entry="[$timestamp] [${level^^}] [PID:$$] $message"
# 日志轮转检查:当日志文件大小超过阈值时,执行轮转
# wc -c < "$LOG_FILE":获取日志文件字节数,$(...)为命令替换
if [ -f "$LOG_FILE" ] && [ $(wc -c < "$LOG_FILE") -ge $MAX_LOG_SIZE ]; then
log_rotate # 调用日志轮转函数
fi
# 将日志条目追加到日志文件,>> 表示追加写入,不覆盖原有内容
echo "$log_entry" >> "$LOG_FILE"
}
# ---------------------------
# 函数:安全日志记录(处理多行内容)
# @param $1 日志级别(必须指定)
# @param $2 多行内容(支持管道输入或 heredoc)
# @usage log_multiline "DEBUG" "$(ls -alh /var/log)"
# 功能:将多行内容逐行记录到日志,避免多行内容被截断
# ---------------------------
log_multiline() {
local level="$1" # 日志级别(如DEBUG/INFO)
local content="$2" # 待记录的多行内容(例如命令输出)
# while循环逐行读取内容,IFS= 确保保留行首空格,read -r 禁止转义字符处理
while IFS= read -r line; do
logger "$level" "$line" # 调用logger函数记录每行内容
done <<< "$content" # <<< 表示将content变量作为输入传递给while循环
}
# ---------------------------
# 函数:日志轮转管理
# @param 无
# @usage log_rotate
# 功能:对日志文件进行压缩轮转,保留指定数量的历史版本
# ---------------------------
log_rotate() {
# 滚动历史版本:从最大保留版本开始重命名,避免覆盖
# 例如:当前保留5个版本,循环从5到1,将log.5.gz -> log.6.gz,log.1.gz -> log.2.gz
for ((i=LOG_BACKUPS; i>=1; i--)); do
[ -f "${LOG_FILE}.${i}.gz" ] && mv -f "${LOG_FILE}.${i}.gz" "${LOG_FILE}.$((i+1)).gz"
# [ -f ... ]:检查文件是否存在;&&:前一命令成功则执行后一命令;mv -f:强制覆盖
done
# 压缩当前日志并清空:使用gzip压缩当前日志,保留原文件名为log.1.gz
# gzip -c:压缩并输出到标准输出,不修改原文件;true > "$LOG_FILE":清空原日志文件
gzip -c "$LOG_FILE" > "${LOG_FILE}.1.gz" 2>/dev/null && true > "$LOG_FILE"
logger "SYSTEM" "完成日志轮转,当前保留$LOG_BACKUPS个历史版本"
}
# ---------------------------
# 函数:服务状态检测
# @param $1 服务名称(systemd服务名或进程名)
# @return 0=正常,1=异常
# @usage check_service "nginx"
# 功能:根据配置检测服务状态(systemd模式或进程模式)
# ---------------------------
check_service() {
local service="$1" # 待检测的服务名称
local status=1 # 默认状态为异常(0表示正常,1表示异常)
# 检测模式选择:根据ENABLE_SYSTEMD_CHECK配置切换检测方式
if $ENABLE_SYSTEMD_CHECK; then
# systemctl is-active --quiet:检查服务是否处于active状态,静默模式
# 成功(服务运行)返回0,失败(服务停止)返回非零
systemctl is-active --quiet "$service"
else
# pgrep -x:精确匹配进程名,-x表示仅匹配完整进程名
# 示例:pgrep -x "nginx" 匹配进程名为"nginx"的进程,排除"nginx: master"等
pgrep -x "$service" >/dev/null # >/dev/null 丢弃输出,仅关注返回码
fi
status=$? # 获取最后一条命令的退出码(0=正常,非零=异常)
# 记录检测结果到日志
[ $status -eq 0 ] && logger "CHECK" "服务[$service]状态正常" || logger "CHECK" "服务[$service]状态异常"
return $status # 返回状态码给调用者
}
# ---------------------------
# 函数:邮件内容过滤
# @param $1 原始内容(邮件正文)
# @return 过滤后的内容(敏感词替换+长度限制)
# @usage filtered_content=$(filter_content "密码是secret,令牌是token123")
# 功能:替换敏感词为星号,并截断过长内容
# ---------------------------
filter_content() {
local content="$1" # 待过滤的原始内容
# 敏感词替换:遍历MAIL_LOG_FILTERS列表,使用sed正则替换
# 示例:将"password"替换为"******",支持正则表达式(如"token.*")
for keyword in "${MAIL_LOG_FILTERS[@]}"; do
content=$(echo "$content" | sed "s/$keyword/******/g")
done
# 长度限制:保留前5行且前200个字符,防止邮件内容过长
# head -n 5:保留前5行;head -c 200:保留前200个字符
echo "$content" | head -n 5 | head -c 200
}
# ---------------------------
# 函数:邮件发送(带审计日志)
# @param $1 服务名(告警关联的服务)
# @param $2 邮件主题(简洁描述告警类型)
# @param $3 邮件内容(详细告警信息)
# @usage send_alert "mysql" "服务宕机告警" "MySQL服务于2023-10-01 14:00停止运行"
# 功能:发送告警邮件,支持重试机制,并记录邮件审计日志
# ---------------------------
send_alert() {
local service="$1" # 服务名称(如"nginx")
local subject="$2" # 邮件主题(如"服务恢复通知")
local body="$3" # 邮件正文(支持多行文本)
local success=1 # 发送结果标记(0=成功,1=失败)
# 发送重试循环:根据MAIL_RETRIES配置进行多次尝试
for ((attempt=1; attempt<=MAIL_RETRIES; attempt++)); do
# echo -e:支持转义字符(如\n换行),mail -s 设置主题,发送到EMAIL
if echo -e "$body" | mail -s "【监控】$subject" "$EMAIL"; then
# 记录成功日志:显示服务名、尝试次数
logger "MAIL" "邮件发送成功[$service] - 第${attempt}次尝试"
# 记录邮件详情日志:包含服务名、收件人、主题和过滤后的内容摘要
local mail_log="[邮件详情]\n"
mail_log+="服务: $service\n"
mail_log+="收件人: $EMAIL\n"
mail_log+="主题: $subject\n"
mail_log+="内容摘要:\n$(filter_content "$body")"
log_multiline "MAIL_DETAIL" "$mail_log" # 调用多行日志记录函数
success=0 # 标记发送成功
break # 跳出循环,不再重试
fi
# 记录失败日志:显示服务名、尝试次数,并等待MAIL_DELAY秒
logger "WARN" "邮件发送失败[$service] - 第${attempt}次尝试,5秒后重试"
sleep $MAIL_DELAY # 等待指定间隔时间
done
return $success # 返回发送结果(0=成功,1=失败)
}
# ---------------------------
# 函数:宕机事件处理
# @param $1 服务名(发生宕机的服务)
# @param $2 当前时间戳(单位:秒,由date +%s生成)
# @usage handle_down "chat_service" "$(date +%s)"
# 功能:处理服务宕机事件,区分首次宕机和持续宕机
# ---------------------------
handle_down() {
local service="$1" # 服务名称
local timestamp="$2" # 当前时间戳(如1696234567)
local record # 存储状态记录文件中的对应行
# 从状态记录文件中查找该服务的记录(格式:服务名,首次宕机时间,最后通知时间)
record=$(grep "^$service," "$RECORD_FILE")
if [ -z "$record" ]; then
# 首次宕机处理:记录中不存在该服务,说明是首次检测到宕机
# 记录告警日志
logger "ALERT" "首次检测到服务[$service]宕机"
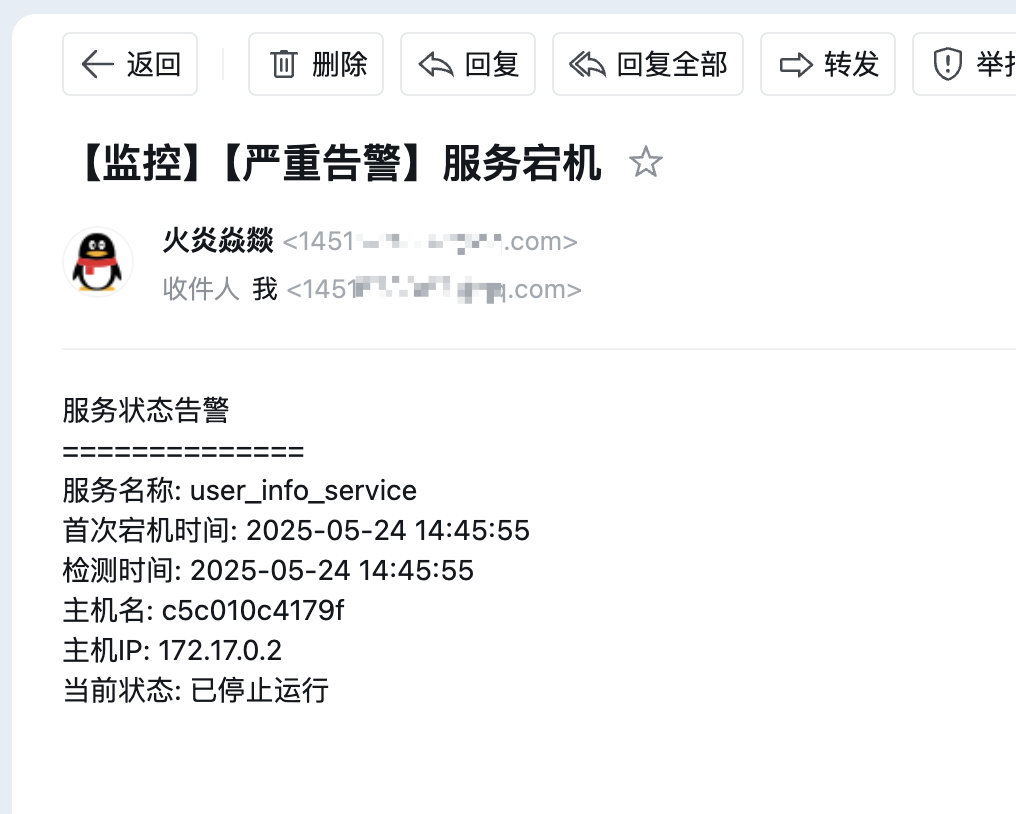
# 构建详细告警邮件(包含IP地址,使用hostname -I获取当前服务器IP)
local body="服务状态告警\n==============\n"
body+="服务名称: $service\n"
body+="首次宕机时间: $(date -d "@$timestamp" +'%F %T')\n"
body+="检测时间: $(date +'%F %T')\n"
body+="主机名: $(hostname)\n"
body+="主机IP: $(hostname -I | awk '{print $1}')\n" # 取第一个IP地址
body+="当前状态: 已停止运行\n\n"
# 发送告警邮件,成功后记录状态到文件
send_alert "$service" "【严重告警】服务宕机" "$body" && {
echo "$service,$timestamp,$timestamp" >> "$RECORD_FILE" # 记录格式:服务名,首次时间,最后通知时间
logger "RECORD" "新建宕机记录[$service] - 时间戳:$timestamp"
}
else
# 持续宕机处理:记录中存在该服务,说明宕机未恢复
# 解析记录中的时间戳
local first_down=$(cut -d, -f2 <<< "$record") # 首次宕机时间
local last_alert=$(cut -d, -f3 <<< "$record") # 最后通知时间
local interval=$((timestamp - last_alert)) # 距上次通知的间隔(秒)
if [ $interval -ge $ALERT_INTERVAL ]; then
# 超过告警间隔,发送持续宕机告警
local duration=$((timestamp - first_down)) # 总宕机时长(秒)
# 构建持续告警邮件(包含时长转换和IP地址)
local body="持续宕机告警\n==============\n"
body+="服务名称: $service\n"
body+="首次宕机时间: $(date -d "@$first_down" +'%F %T')\n"
body+="持续时间: $(date -ud @$duration +'%H小时%M分钟%S秒')\n"
body+="最新检测时间: $(date -d "@$timestamp" +'%F %T')\n"
body+="主机名: $(hostname)\n"
body+="主机IP: $(hostname -I | awk '{print $1}')\n"
body+="当前状态: 仍未恢复\n\n"
# 发送持续告警邮件,成功后更新记录时间
send_alert "$service" "【持续告警】服务未恢复" "$body" && {
sed -i "/^$service,/d" "$RECORD_FILE" # 删除旧记录
echo "$service,$first_down,$timestamp" >> "$RECORD_FILE" # 写入新记录(更新最后通知时间)
logger "RECORD" "更新[$service]告警时间 - 新时间戳:$timestamp"
}
else
# 未超过间隔,跳过通知
logger "NOTICE" "跳过[$service]告警 - 距上次通知仅$((interval/60))分钟"
fi
fi
}
# ---------------------------
# 函数:恢复事件处理
# @param $1 服务名(恢复正常的服务)
# @usage handle_recovery "robot_info"
# 功能:处理服务恢复事件,发送恢复通知并清除记录
# ---------------------------
handle_recovery() {
local service="$1" # 服务名称
local record # 存储状态记录文件中的对应行
# 查找该服务的宕机记录
record=$(grep "^$service," "$RECORD_FILE")
if [ -n "$record" ]; then
# 存在记录,说明是从宕机状态恢复
local first_down=$(cut -d, -f2 <<< "$record") # 首次宕机时间
local duration=$(( $(date +%s) - first_down )) # 总宕机时长(秒)
# 构建恢复通知邮件(包含完整时间统计和IP地址)
local body="服务恢复通知\n==============\n"
body+="服务名称: $service\n"
body+="首次宕机时间: $(date -d "@$first_down" +'%F %T')\n"
body+="宕机总时长: $(date -ud @$duration +'%H小时%M分钟%S秒')\n"
body+="恢复时间: $(date +'%F %T')\n"
body+="主机名: $(hostname)\n"
body+="主机IP: $(hostname -I | awk '{print $1}')\n"
body+="当前状态: 已恢复正常运行\n\n"
# 发送恢复通知邮件,成功后清除记录
send_alert "$service" "【通知】服务已恢复" "$body" && {
sed -i "/^$service,/d" "$RECORD_FILE" # 从记录文件中删除该服务条目
logger "RECOVERY" "清除[$service]宕机记录 - 服务已恢复"
}
fi
}
################################## 主程序 #####################################
# 监控周期开始,记录系统事件
logger "SYSTEM" "==== 监控周期开始($(date +'%F %T'))===="
# 遍历所有监控服务,逐个检查状态
for service in "${SERVICES[@]}"; do
logger "PROCESS" "开始检查服务: $service" # 记录处理开始
if check_service "$service"; then
# 服务正常,检查是否有恢复事件需要处理
handle_recovery "$service"
else
# 服务异常,处理宕机事件(传入当前时间戳)
handle_down "$service" "$(date +%s)"
fi
logger "PROCESS" "完成检查服务: $service" # 记录处理结束
done
# 监控周期结束,记录系统事件
logger "SYSTEM" "==== 监控周期结束($(date +'%F %T'))====\n"
# 释放文件锁,允许其他实例运行
flock -u 9 # -u 释放锁
exit 0 # 脚本正常退出对应的参数按照脚本进行修改
3. 配置定时任务每分钟执行一次脚本
shell
crontab -e
* * * * * /usr/local/bin/service_monitor.sh3. 确认是否收到邮件