一、引言
新手小白学习网络编程(尤其是Linux系统),肯定绕不过对 select/poll/epoll 概念的理解,与之密切相关的概念就是:I/O多路复用
这篇文章以一个小白的角度出发,循序渐进学习一下I/O多路复用。还是要回答三个问题:
- What:什么是I/O多路复用
- Why:为什么要用I/O多路复用
- How:如何实现I/O多路复用
1.1 IO多路复用的概念
可以拆解为三个概念:
-
什么是I/O?
I/O在网络编程中,可以简单理解为通过socket进行的网络数据的读写
-
什么是多路?
指的是多个I/O通道,也就是多个socket网络连接
-
什么是复用?
指的是使用一个线程或进程来处理多个socket上的读写事件
综上,I/O多路复用简单理解就是:一个线程处理多个客户端请求
既然有"一个线程处理多个客户端请求"的情况,自然而然会想到以下两种情况:
- 一个线程处理一个客户端
- 多个线程处理多个客户端
(多个线程处理一个客户端,这没意义)
搞懂以上这两种情况存在的问题,就能够理解为什么要用I/O多路复用了
1.2 一个线程处理一个客户端
以下是一段最基础的Server伪代码,这个Server只有一个主线程,先接收一个客户端连接,连接建立后再读取客户端请求消息,并给客户端返回响应消息
c++
// 服务端伪代码
int main()
{
// 创建socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 绑定地址和端口
sockaddr_in address;
// ...
bind(server_fd, (struct sockaddr*)&address, sizeof(address));
// 监听
listen(server_fd, 3);
// 等待客户端连接 ==> 阻塞
int client_socket = accept(server_fd, (struct sockaddr*)&client_addr, &client_addr_len);
// ...
while(true)
{
int bytes_read = read(client_socket, buffer, BUFFER_SIZE); // 读取客户端消息
// 省略break逻辑
write(client_socket, buffer, bytes_read);// 回复客户端消息
// 省略break逻辑
}
// 关闭连接
close(client_socket);
close(server_fd);
return 0;
}这个Server最明显的问题 就是:一个线程既要负责通过accept接收客户端连接,又要通过read/write负责客户端的消息读写,所以它只能处理一个客户端连接。
那么自然会想到改进的方法:主线程负责接收客户端连接,然后开启子线程进行客户端消息读写。也就是下面要介绍的多个线程处理多个客户端
1.3 多个线程处理多个客户端
以下是改进后利用多个线程处理多个客户端的Server端伪代码
c++
// 伪代码
int main()
{
// 创建socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 绑定地址和端口
sockaddr_in address;
// ...
bind(server_fd, (struct sockaddr*)&address, sizeof(address));
// 监听
listen(server_fd, 3);
while(true)
{
// 等待客户端连接 ==> 阻塞
int client_socket = accept(server_fd, (struct sockaddr*)&client_addr, &client_addr_len);
std::thread([client_socket](){
while(true)
{
int bytes_read = read(client_socket, buffer, BUFFER_SIZE); // 读取客户端消息
// 省略break逻辑
write(client_socket, buffer, bytes_read); // 回复客户端消息
// 省略break逻辑
}
close(client_socket);
}).detach(); // 立即分离线程
}
}主线程通过while循环一直accept接收客户端连接,每次有新的客户端连接到来,获取该连接的client_socket后创建一个子线程std::thread,在子线程中处理该客户端读写消息
看样子是实现了同时处理多个客户端请求,但是需要面对如下问题:
-
线程资源耗尽风险:每个客户端连接都会创建一个新线程,当并发连接数量过大时,系统资源(如内存、CPU 调度开销)会被大量占用,甚至导致服务器崩溃。例如,若每个线程占用 1MB 栈空间,1 万个并发连接将消耗约 10GB 内存
-
线程创建 / 销毁开销:频繁创建和销毁线程会带来显著的性能开销,包括内存分配、上下文切换等。对于短连接场景(如 HTTP 请求),这种开销可能远超实际业务处理所需资源
-
可扩展性瓶颈:线程数量受限于系统资源(如 Linux 默认单进程最大线程数约 3 万个),无法支持百万级并发连接(如高性能 Web 服务器需求)。这种模式本质是 "用资源换并发",而非"高效利用资源"
-
线程同步 、异常处理等其他问题...
这时候有人会说,不用每个客户端连接都创建一个子线程,我在主线程中
accept新客户端连接,已连接的客户端消息交给一个线程池来处理行不行?
这样确实可以避免线程资源的问题,那么接下就讨论一下这种情况
c++
// 伪代码
int main()
{
// 创建socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
// 绑定地址和端口
sockaddr_in address;
// ...
bind(server_fd, (struct sockaddr*)&address, sizeof(address));
// 监听
listen(server_fd, 3);
// 保存已连接客户端
std::list<int> client_sockets;
// 工作线程(代表线程池)
std::thread worker([&]() {
while (true)
{
for (auto it = client_sockets.begin(); it != client_sockets.end(); )
{
int socket = *it;
int bytes_read = read(socket, buffer, BUFFER_SIZE);
if (bytes_read <= 0)
{
// 客户端断开连接或发生错误
close(socket);
it = client_sockets.erase(it);
}
else
{
// 处理读取到的数据
// ...
++it;
}
}
// 手动让线程休眠1s,不然cpu直接占满
std::this_thread::sleep_for(std::chrono::seconds(1));
}
});
// 主线程:接收新客户端连接
while (true) {
// 等待客户端连接 ==> 阻塞
int client_socket = accept(server_fd, (struct sockaddr*)&client_addr, &client_addr_len);
// 省略线程同步代码
// ...
client_sockets.push_back(client_socket);
}
// ...
close(server_fd);
return 0;
}这种情况下,主线程负责接收新的客户端连接,不负责处理业务逻辑,而是交由工作线程执行。工作线程轮询每个已连接的客户端,执行相应的读写操作和业务逻辑。但是这时会有一个很明显的问题------阻塞
由于read操作是阻塞的,需要一直等待客户端有数据来才能解除阻塞继续运行。假如前面的列表中依次有socket1、socket2、socket3,工作线程在对socket1执行read时遇到了较大的延迟,会导致后续socket2和socket3的处理也受到影响。即使是增加工作线程的数量,也无法根本解决该问题。
1.4 小结
根据上面的分析可以发现,仅靠我们自己基于用户态的编程行为,无法解决服务器高效处理大量客户端连接的问题。这时我们就迫切希望操作系统内核能够提供一种机制,帮助我们解决这个问题。
那么有这么一种的机制吗?有的兄弟,包有的,这就是我们非常耳熟却不一定能详的select/poll/epoll。
二、阻塞、非阻塞
2.1 预备知识
1️⃣ 预备知识1
先来了解一下用户空间、内核空间、用户态、内核态概念
| 概念 | 定义 |
|---|---|
| 内核空间 | 操作系统内核占用的内存区域(受硬件保护) |
| 用户空间 | 应用程序占用的内存区域(普通程序无法直接访问内核空间) |
| 内核态 | CPU 执行内核代码时的状态(对应内核空间的运行环境) |
| 用户态 | CPU 执行应用程序代码时的状态(对应用户空间的运行环境) |
- 内核态运行在内核空间 ,用户态运行在用户空间;
- 程序从用户态进入内核态时,必须通过系统调用、中断、异常等受控方式,不能直接跳转。
2️⃣ 预备知识2
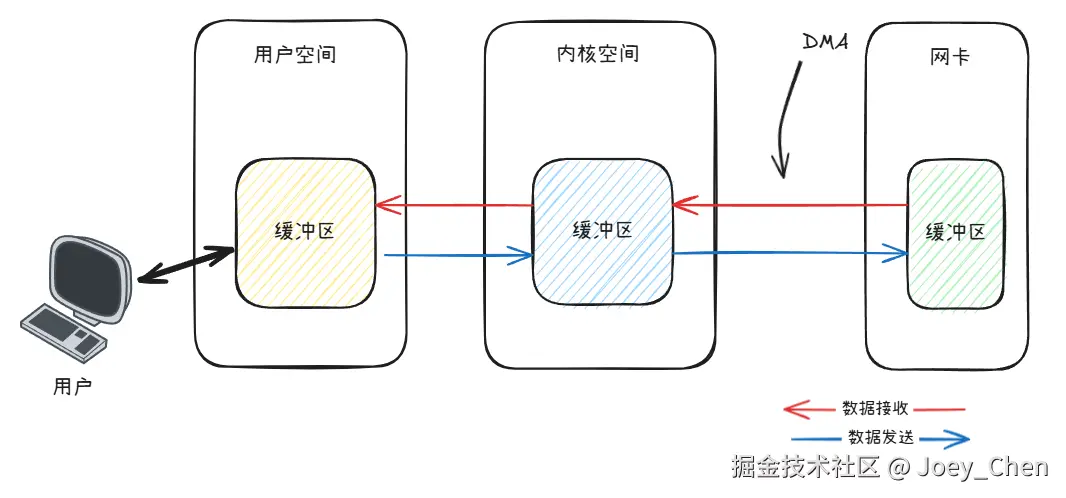
数据从网卡到内存的过程是什么样的?
网卡自身会有一个硬件缓冲区,用于临时存储待发送或刚接收的数据帧。现在的计算机都通过一种叫做DMA (直接内存访问)的机制,直接在网卡和内存之间传输数据,可以不需要CPU参与。这里要注意,数据是从网卡硬件缓冲区直接复制到内核空间的套接字缓冲区 ,还要继续复制到用户空间缓冲区,才是我们代码中真正操作的数据。
3️⃣ read系统调用的空间与状态变化
当应用程序调用read读取文件时,整个过程涉及用户态与内核态的切换,以及用户空间与内核空间的交互:
-
用户态(用户空间):
应用程序在用户空间准备好缓冲区(如
char buf[1024]),调用read(fd, buf, 1024)。此时 CPU 处于用户态,执行用户程序代码。 -
切换到内核态(内核空间):
read触发系统调用,CPU 从用户态切换到内核态,进入内核空间;- 内核检查文件描述符
fd的合法性,找到对应的文件 inode; - 内核通过 VFS(虚拟文件系统)调用底层设备驱动(如硬盘驱动),读取数据到内核缓冲区(内核空间)。
-
返回用户态(用户空间):
- 内核将数据从内核缓冲区复制到用户空间的
buf中; - 切换回用户态,
read返回读取的字节数,应用程序继续处理buf中的数据。
- 内核将数据从内核缓冲区复制到用户空间的
2.2 阻塞和非阻塞
了解用户态和内核态之后,接下来要理解一下什么是阻塞 和非阻塞 。之前的伪代码中,像accept和read都是阻塞的,那么阻塞到底是什么意思?
阻塞模式下的内核行为:
当用户进程调用read时,内核检查套接字缓冲区是否有数据:
-
若无数据:内核将进程从运行队列移到等待队列(进程进入阻塞态),释放 CPU;
-
若有数据(或 DMA 传输完成后):内核将数据从套接字缓冲区复制到用户空间缓冲区,唤醒进程(移回运行队列),read返回数据长度。
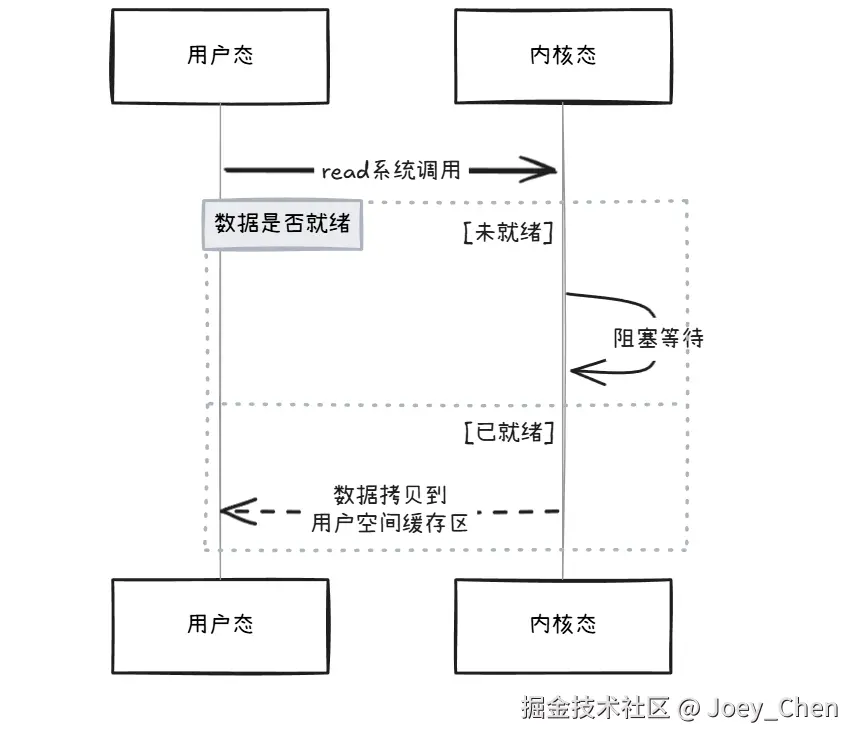
若内核缓冲区的数据没有就绪,进程就要一直等待,称之为阻塞。
如果有10个socket连接需要处理,很明显我们不希望一直卡在其中一个socket上,如果它的数据还没就续,是否有办法直接返回一个状态码后,继续切回用户态往后执行?
--------- 有的兄弟,包有的,这种方式就称为非阻塞
非阻塞模式下的内核行为:
当用户进程调用read时,内核检查套接字缓冲区:
-
若无数据 :内核不将进程加入等待队列,直接返回
-1,并设置errno=EAGAIN("重试"); -
若有数据:与阻塞模式相同,复制数据到用户空间,返回数据长度。
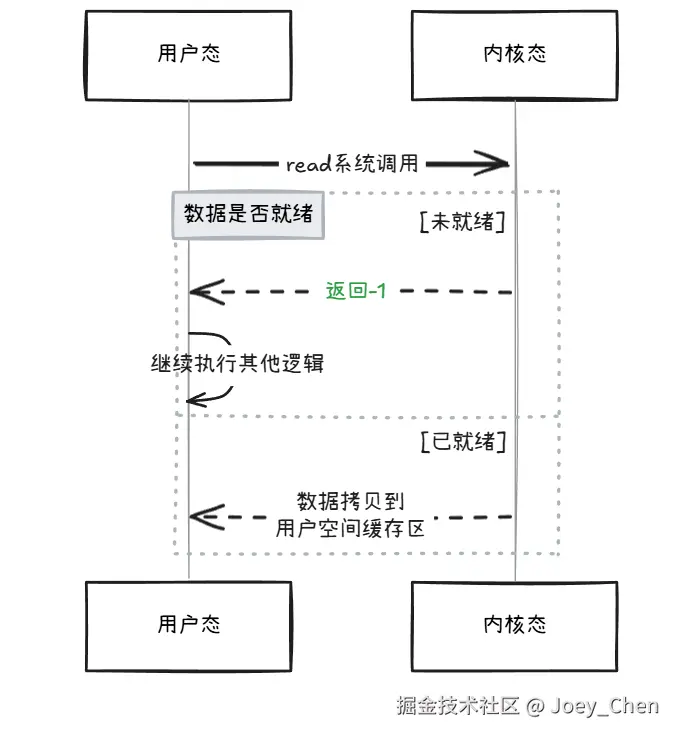
非阻塞的情况下,即使没有内核缓冲区中没有数据准备就绪,也不会导致进程阻塞,那么在【1.3节】中讨论的问题就迎刃而解,一个工作线程处理多个socket时,前面的socket没有数据并不会影响后面socekt的处理。
2.3 小结
通过这一章的介绍,我们可以知道要想实现I/O多路复用,也就是一个线程处理多个网络连接,就必须依赖操作系统内核为我们提供非阻塞的、高效的I/O方式,这就是我们非常耳熟却不一定能详的select/poll/epoll。
三、select/poll
3.1 函数原型和参数
c++
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);-
参数说明:
-
nfds:需要检查的最大文件描述符值加 1(例如,若监控的最大描述符是 5,则nfds为 6)。 -
readfds:指向可读文件描述符集合的指针,用于检查是否有数据可读。 -
writefds:指向可写文件描述符集合的指针,用于检查是否可写入数据。 -
exceptfds:指向异常文件描述符集合的指针,用于检查是否有异常发生。 -
timeout:超时时间,控制select的阻塞行为:NULL:永久阻塞,直到有文件描述符就绪。0:立即返回(非阻塞模式)。>0:阻塞指定时间(如struct timeval { tv_sec=5, tv_usec=0 }表示 5 秒)。
-
-
返回值:
>0:就绪的文件描述符总数。0:超时,无文件描述符就绪。-1:出错(需检查errno)。
3.2 原理
select 的核心原理是通过内核轮询机制监控多个文件描述符的状态,当任一描述符就绪(可读、可写或异常)时返回通知。其工作流程如下:
-
用户程序准备描述符集合 :
用户将需要监控的文件描述符添加到
fd_set集合中(通过FD_SET宏)。 -
系统调用进入内核态 :
select将描述符集合从用户空间复制到内核空间,并开始轮询监控。 -
内核轮询检查状态 :
内核遍历所有描述符,检查其状态(如接收缓冲区是否有数据、发送缓冲区是否有空间):
- 若有描述符就绪,立即返回。
- 若无就绪描述符且超时时间未到,进程进入睡眠状态,等待事件触发。
-
事件触发与唤醒 :
当某个文件描述符发生事件(如数据到达、连接建立),内核唤醒进程,并修改描述符集合(仅保留就绪的描述符)。
-
返回用户态处理结果 :
select返回后,用户程序通过FD_ISSET宏检查哪些描述符就绪,并进行相应处理。
3.3 数据结构与关键宏
select 使用fd_set(文件描述符集合)来管理监控的描述符,通过以下宏操作:
c++
FD_ZERO(fd_set *set); // 清空集合
FD_SET(int fd, fd_set *set); // 将fd添加到集合
FD_CLR(int fd, fd_set *set); // 从集合中移除fd
FD_ISSET(int fd, fd_set *set); // 检查fd是否在集合中(就绪)示例:
c++
fd_set readfds;
int sockfd = 3; // 假设这是一个已连接的套接字
FD_ZERO(&readfds);
FD_SET(sockfd, &readfds);
// 监控sockfd是否可读,超时时间5秒
struct timeval timeout = {5, 0};
int ready = select(sockfd + 1, &readfds, NULL, NULL, &timeout);
if (ready > 0 && FD_ISSET(sockfd, &readfds)) {
// sockfd可读,可安全调用read()
}3.4 select的不足
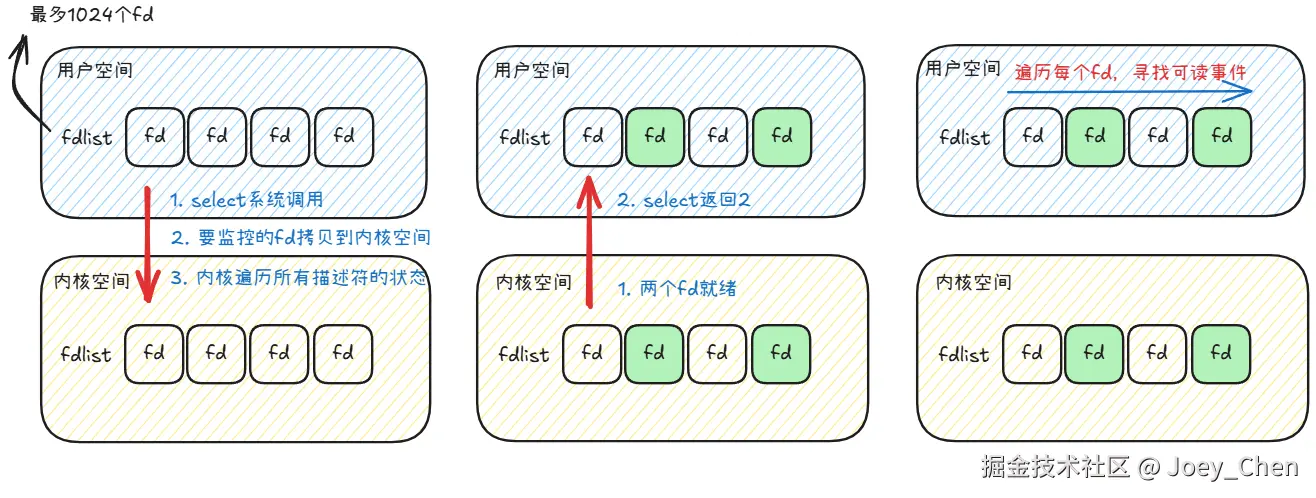
从上面这张图中可以看到select存在的问题:
-
能监听端口的数量有限,单个进程所能打开的最大连接数32位机默认1024个,64位默认2048。
-
每次调用select,都需要把被监控的fds集合从用户态空间拷贝到内核态空间,高并发场景下这样的拷贝会使得消耗的资源是很大的
-
被监控的fds集合中,只要有一个有数据可读,整个fds集合就会被遍历一次,这其中就包含了很多的无效遍历。例如,select一共监控了100个fd,但是其中只有1个fd数据就绪,但是select也不知道到底是哪一个,只能100个全遍历过去
3.5 poll与select的区别
poll和select本质上是一样的,只是描述fd集合的方式不同
-
select使用
fd_set结构,固定大小,一般为1024 -
poll使用
struct pollfd,使用动态数组,大小不受1024限制,但是受系统资源限制
其他的就不展开叙述了。
四、epoll
4.1 解决痛点
epoll 的设计目标是解决 select/poll 的两大痛点:
-
轮询遍历所有描述符(O (n) 时间复杂度)
-
每次调用需重复传递描述符集合(用户空间与内核空间频繁复制数据)
- 一次性拷贝 :
epoll通过epoll_ctl系统调用进行事件注册。当使用epoll_ctl并指定EPOLL_CTL_ADD时,会把要监听的文件描述符集合从用户态拷贝进内核态。之后,内核会维护这些描述符信息,在后续调用epoll_wait等待事件时,无需再次重复拷贝整个文件描述符集合,保证了每个文件描述符在整个过程中只会拷贝一次。 - 事件驱动与回调机制 :
epoll在内核中为每个注册的文件描述符指定一个回调函数。当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,该回调函数会把就绪的文件描述符加入一个就绪链表。epoll_wait的工作就是在这个就绪链表中查看有没有就绪的文件描述符,而不需要像select和poll那样每次都遍历所有的文件描述符集合,从而避免了频繁地进行系统调用和重复操作,减少了开销。
4.2 关键机制
-
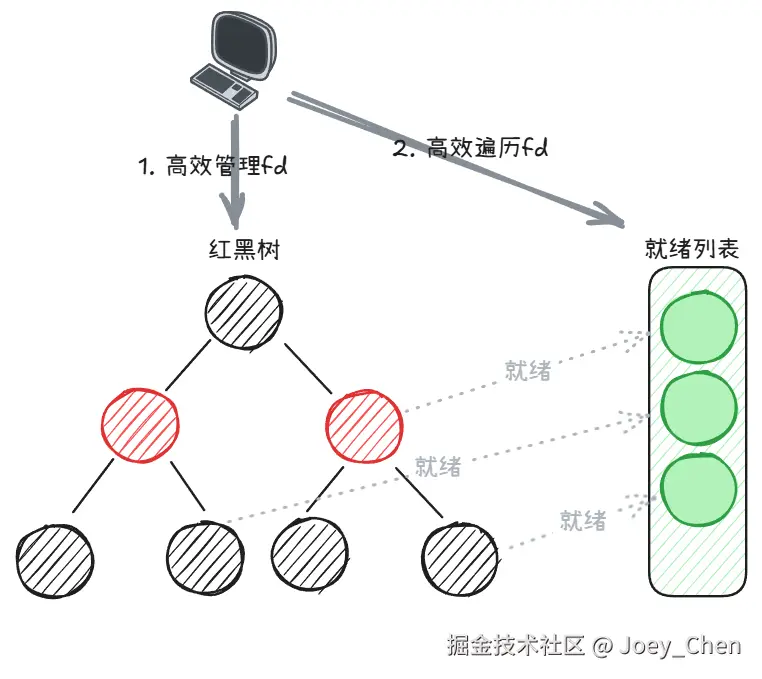
红黑树管理描述符:
内核维护一个红黑树(struct eventpoll),用于存储用户注册的文件描述符。插入、删除操作的时间复杂度为 O (log n)。
-
事件队列存储就绪事件:
当某个描述符就绪时,内核通过回调函数将其加入就绪队列(rdllist),用户只需遍历该队列即可获取所有就绪事件(O (1) 时间复杂度)。
-
回调机制替代轮询:
内核为每个描述符注册回调函数,当事件发生时触发回调,直接将描述符加入就绪队列,无需遍历所有描述符。
4.3 关键数据结构与系统调用
- 三个核心的系统调用
c++
// 创建epoll实例,返回文件描述符
int epoll_create(int size); // size参数已弃用,填>0的值即可
// 注册、修改或删除事件监听
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待事件发生,返回就绪描述符数量
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);- 关键数据结构
c++
struct epoll_event {
uint32_t events; // 事件类型(如EPOLLIN、EPOLLOUT)
epoll_data_t data; // 自定义数据(如fd或指针)
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;4.4 使用示例
- 创建 epoll 实例:
c++
int epfd = epoll_create(1024); // 创建epoll句柄
if (epfd == -1) {
perror("epoll_create");
exit(EXIT_FAILURE);
}- 注册监听事件:
c++
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET; // 边缘触发模式
ev.data.fd = listen_fd; // 监听套接字
// 注册事件
if (epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &ev) == -1) {
perror("epoll_ctl: listen_fd");
exit(EXIT_FAILURE);
}- 等待事件并处理:
c++
#define MAX_EVENTS 10
struct epoll_event events[MAX_EVENTS];
while (1) {
// 等待事件,超时时间-1表示永久阻塞
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
// 处理就绪事件
for (int i = 0; i < nfds; i++) {
if (events[i].data.fd == listen_fd) {
// 处理新连接
accept_new_connection(listen_fd);
} else if (events[i].events & EPOLLIN) {
// 处理读事件
handle_read(events[i].data.fd);
} else if (events[i].events & EPOLLOUT) {
// 处理写事件
handle_write(events[i].data.fd);
}
}
}4.5 水平触发和边缘触发
epoll 支持两种触发模式,通过 epoll_ctl 的 events 参数设置:
-
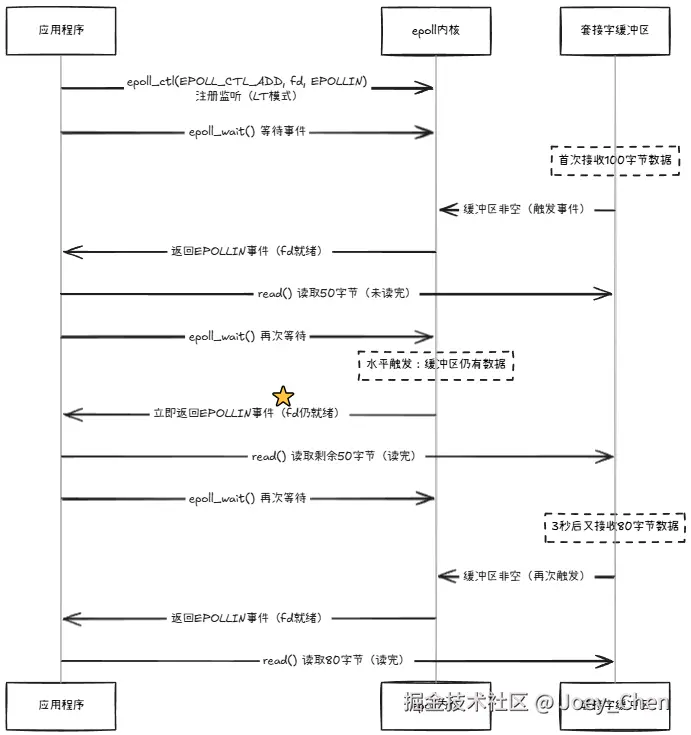
水平触发(Level Triggered,默认) :
只要描述符就绪条件持续满足(如缓冲区有数据可读),就会重复通知。
特点:可靠性高,但可能导致多次触发,需确保每次处理完所有数据。
-
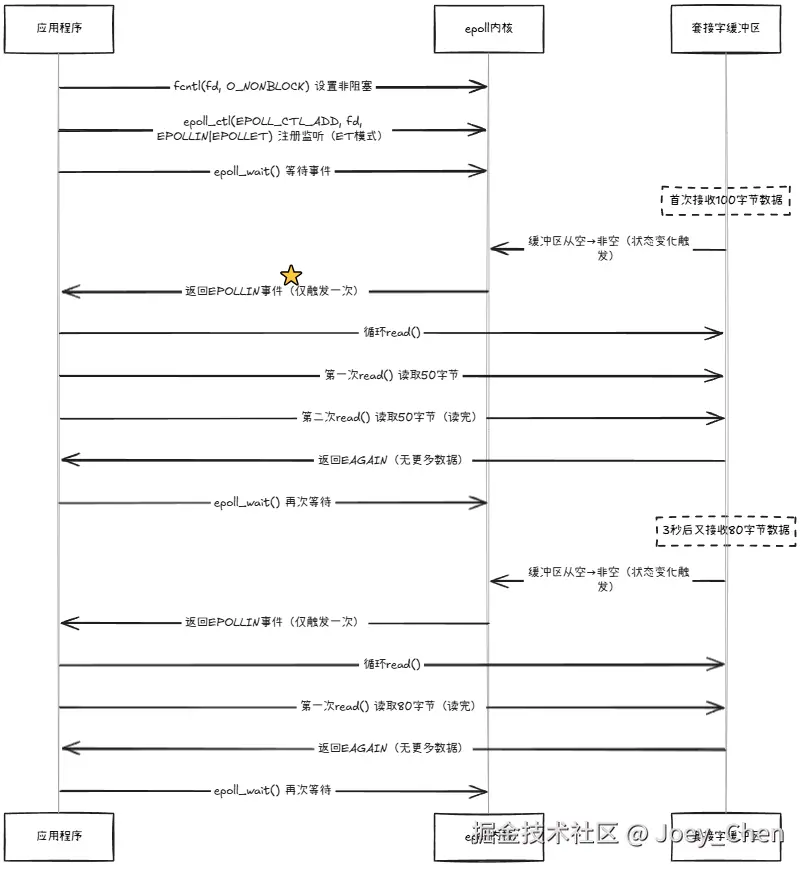
边缘触发(Edge Triggered) :
仅在描述符状态变化时(如从无数据变为有数据)触发一次。
特点:性能更高,但要求必须一次性处理完所有数据(否则不会再次通知),通常需配合非阻塞 I/O 使用。
差异分析
-
事件触发条件
-
水平触发 (LT):只要缓冲区有数据可读,就会持续触发 EPOLLIN 事件
-
边缘触发 (ET):仅在数据到达的那一刻触发一次 EPOLLIN 事件
-
-
读取方式
- 水平触发:可以分多次读取数据,一次 read 不完不会影响后续触发
c++// 水平触发:可以只读取部分数据 int n = read(fd, buffer, BUFFER_SIZE);- 边缘触发:必须循环读取直到返回 EAGAIN,否则剩余数据不会再通知
c++// 边缘触发:必须读完所有数据 while (true) { int n = read(fd, buffer, BUFFER_SIZE); if (n < 0 && (errno == EAGAIN || errno == EWOULDBLOCK)) { break; // 已读完所有数据 } // 处理数据... } -
水平触发更安全,适合初学者或简单应用
-
边缘触发性能更高,但编程复杂度也更高,需要严格遵循 "一次处理完所有数据" 的原则
-
实际应用中,ET 模式通常用于高性能服务器,如 Nginx、Redis 等
五、总结
现在我们再回头来看一下文章开头提出的三个问题:What、Why、How
-
What:什么是I/O多路复用
IO 多路复用是一种让单个进程(或线程)能同时监控多个文件描述符(如套接字、文件等),并在其中任一描述符就绪(可读写或发生异常)时得到通知的 I/O 模型。其核心是通过一次系统调用同时管理多个 I/O 操作,而非为每个 I/O 单独创建进程或线程。
-
Why:为什么要用I/O多路复用
IO 多路复用通过事件驱动机制可以解决传统I/O模型的痛点,核心优势体现在:
-
单进程 / 线程处理多 I/O: 一个进程可同时监控数百至数万个文件描述符,无需创建大量进程 / 线程。
-
减少阻塞时间: 进程仅在无任何 I/O 就绪时阻塞(如
select/epoll_wait),有就绪事件时立即处理,提升 CPU 利用率 -
降低资源消耗: 避免进程 / 线程的高频创建、销毁和切换,节省内存和 CPU 资源。
-
-
How:如何实现I/O多路复用
操作系统为我们提供了
select/poll/epoll之类的系统调用,可以很方便地实现I/O多路复用。
以上就是本文的全部内容,感谢阅读~