一、字符串接龙(Kamacoder 110)
1.思路:
在无权图中,用广搜求最短路最为合适,广搜只要搜到了终点,那么一定是最短的路径。因为广搜就是以起点中心向四周扩散的搜索。
python
from collections import deque
# 判断两个字符串是否只差一个字符
def is_one_letter_diff(s1, s2):
return sum(c1 != c2 for c1, c2 in zip(s1, s2)) == 1
# 广度优先搜索,寻找最短变换路径
def bfs(start, end, word_list):
if start == end:
return 0 # 起点就是终点,步数为 0
n = len(word_list)
visited = [False] * n # 记录哪些字符串已经访问过
queue = deque()
queue.append((start, 1)) # 初始节点和步数为 1(因为要从 start 开始变换)
while queue:
current_word, steps = queue.popleft() # 取出队头元素
# 如果当前字符串和目标只差一位,表示下一步就能变成目标
if is_one_letter_diff(current_word, end):
return steps + 1
# 遍历所有未访问过的中间词
for i in range(n):
if not visited[i] and is_one_letter_diff(current_word, word_list[i]):
visited[i] = True
queue.append((word_list[i], steps + 1)) # 入队下一步
return 0 # 无法转换到目标字符串
# 主程序入口
if __name__ == '__main__':
n = int(input()) # 输入字符串个数
start_word, end_word = input().split() # 输入起点和终点
word_list = [input().strip() for _ in range(n)] # 输入字符串列表
result = bfs(start_word, end_word, word_list)
print(result)
python
sum(c1 != c2 for c1, c2 in zip(s1, s2)) == 1这是一个生成器表达式,逐对比较两个字符串对应字符是否不同,返回布尔值序列,Python 中 True == 1,False == 0,所以 sum() 会统计有多少个字符不同:
python
s1 = "abc"
s2 = "adc"
zip(s1, s2) → [('a','a'), ('b','d'), ('c','c')]
返回布尔值序列:
['a' != 'a' → False,
'b' != 'd' → True,
'c' != 'c' → False]
Python 中 True == 1,False == 0,所以 sum() 会统计有多少个字符不同:
sum([False, True, False]) → 1当然也可以改写为更直观方式:
python
def is_one_letter_diff(s1, s2):
count = 0
for c1, c2 in zip(s1, s2):
if c1 != c2:
count += 1
return count == 12.带路径追踪写法
我们可以在原有 BFS 基础上,追加路径追踪功能,在队列中不仅记录当前字符串和步数,还记录当前路径的历史节点列表。
python
queue.append((当前字符串, 当前步数, [路径上的字符串们]))
python
from collections import deque
# 判断两个字符串是否只差一个字符
def is_one_letter_diff(s1, s2):
return sum(c1 != c2 for c1, c2 in zip(s1, s2)) == 1
# 广度优先搜索:寻找最短路径并打印变换路径
def bfs(start, end, word_list):
if start == end:
print(0)
print(start)
return
n = len(word_list)
visited = [False] * n # 记录哪些字符串已经访问过
queue = deque()
queue.append((start, 1, [start])) # 包含路径的队列节点
while queue:
current_word, steps, path = queue.popleft()
# 如果下一步就可以达到目标,直接输出路径
if is_one_letter_diff(current_word, end):
print(steps + 1)
print(" -> ".join(path + [end]))
return
for i in range(n):
if not visited[i] and is_one_letter_diff(current_word, word_list[i]):
visited[i] = True
queue.append((word_list[i], steps + 1, path + [word_list[i]]))
print(0) # 无法到达目标
# 主程序入口
if __name__ == '__main__':
n = int(input()) # 中间字符串数量
start_word, end_word = input().split() # 起点和终点
word_list = [input().strip() for _ in range(n)]
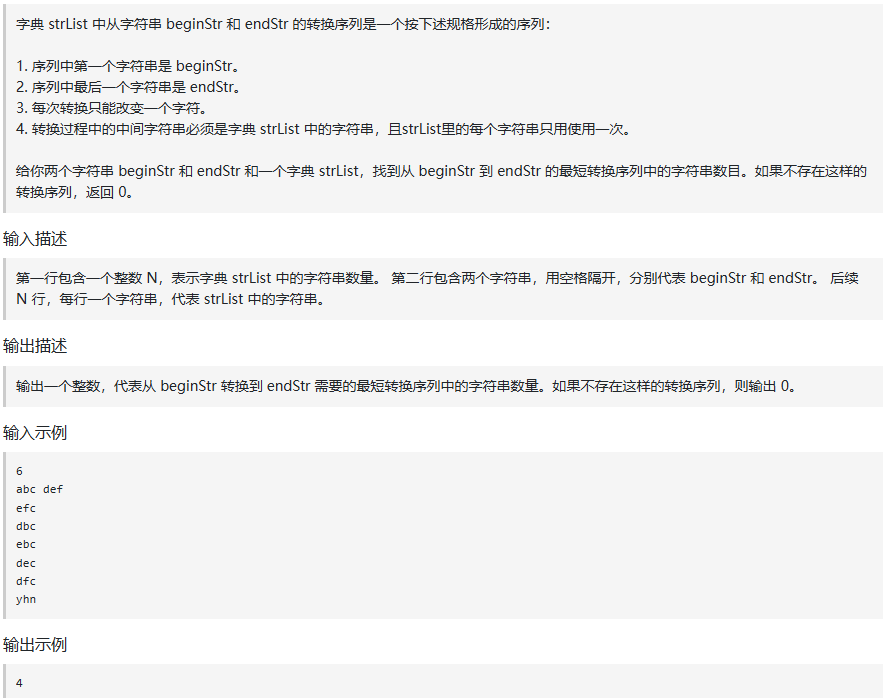
bfs(start_word, end_word, word_list)输出结果示例:
python
4
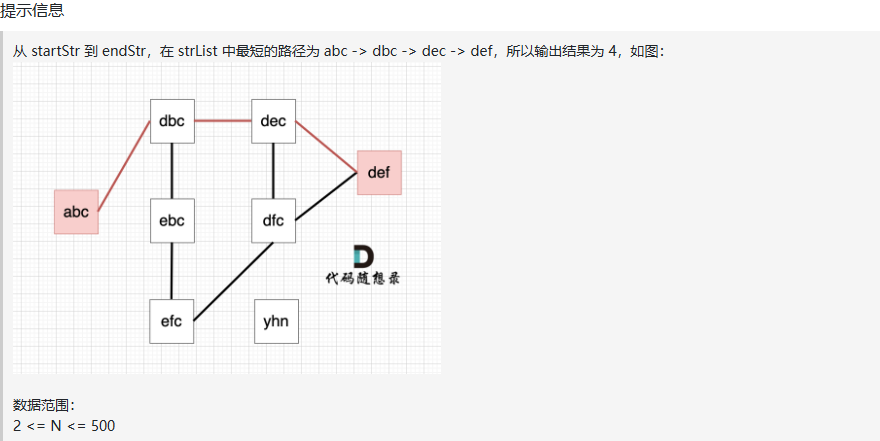
abc -> dbc -> dec -> def二、有向图的完全可达性(Kamacoder 105)
python
import collections
# 广度优先搜索:从起点 start 出发,遍历整个图,返回所有可达节点的集合
def bfs(start, graph):
visited = set() # 记录访问过的节点,防止重复访问
que = collections.deque([start]) # 使用 deque 实现高效队列,初始加入起点
while que:
node = que.popleft() # 取出队首节点
if node in visited:
continue
visited.add(node) # 记录当前节点为已访问
# 遍历当前节点的所有可达节点
for cur in graph[node]:
que.append(cur) # 将邻居节点加入队列等待访问
return visited
# 主函数:读取输入、建图、执行 BFS,并判断所有节点是否可达
def main():
n, k = map(int, input().split())
# 使用 defaultdict 初始化图的邻接表结构
graph = collections.defaultdict(list)
for _ in range(k):
src, dest = map(int, input().split())
graph[src].append(dest) # 构建有向图(从 src 指向 dest)
visited_nodes = bfs(1, graph) # 从节点 1 出发执行 BFS,获取所有可达节点
# 如果访问到的节点刚好是 1~N,说明所有节点都可以从 1 号访问到
if visited_nodes == set(range(1, n + 1)):
return 1
else:
return -1
if __name__ == "__main__":
print(main())三、寻找存在的路径(Kamacoder 107)
当我们需要判断两个元素是否在同一个集合里的时候,就要想到用并查集。
并查集主要有两个功能:
-
将两个元素添加到一个集合中。
-
判断两个元素在不在同一个集合
python
# 并查集(Union-Find)结构定义
class UnionFind:
def __init__(self, size):
# 初始化父节点数组,初始每个节点的父亲是自己
self.parent = list(range(size + 1))
def find(self, u):
# 查找 u 的根节点(带路径压缩优化)
if self.parent[u] != u:
# 递归查找根节点,并压缩路径(使中间所有节点直接指向根)
self.parent[u] = self.find(self.parent[u])
return self.parent[u]
def union(self, u, v):
# 合并 u 和 v 所在集合
root_u = self.find(u)
root_v = self.find(v)
if root_u != root_v:
# 将 v 的根节点挂到 u 的根节点上(实现合并)
self.parent[root_v] = root_u
def is_same(self, u, v):
# 判断 u 和 v 是否属于同一集合
return self.find(u) == self.find(v)
def main():
import sys
input = sys.stdin.read # 读取整个标准输入(适合大数据量的评测输入)
data = input().split() # 按空格/换行切分为字符串列表
index = 0
n = int(data[index]) # 读取节点个数 n
index += 1
m = int(data[index]) # 读取边数 m(union 操作数)
index += 1
uf = UnionFind(n) # 初始化并查集结构(节点从 1 到 n)
# 处理 m 次 union 操作,代表 m 条边
for _ in range(m):
s = int(data[index]) # 每条边的起点
index += 1
t = int(data[index]) # 每条边的终点
index += 1
uf.union(s, t) # 合并两个节点所在的集合
# 读取要判断的两个节点
source = int(data[index])
index += 1
destination = int(data[index])
# 判断两节点是否在同一集合
if uf.is_same(source, destination):
print(1) # 同一集合,输出 1
else:
print(0) # 不同集合,输出 0四、冗余连接(Kamacoder 108)
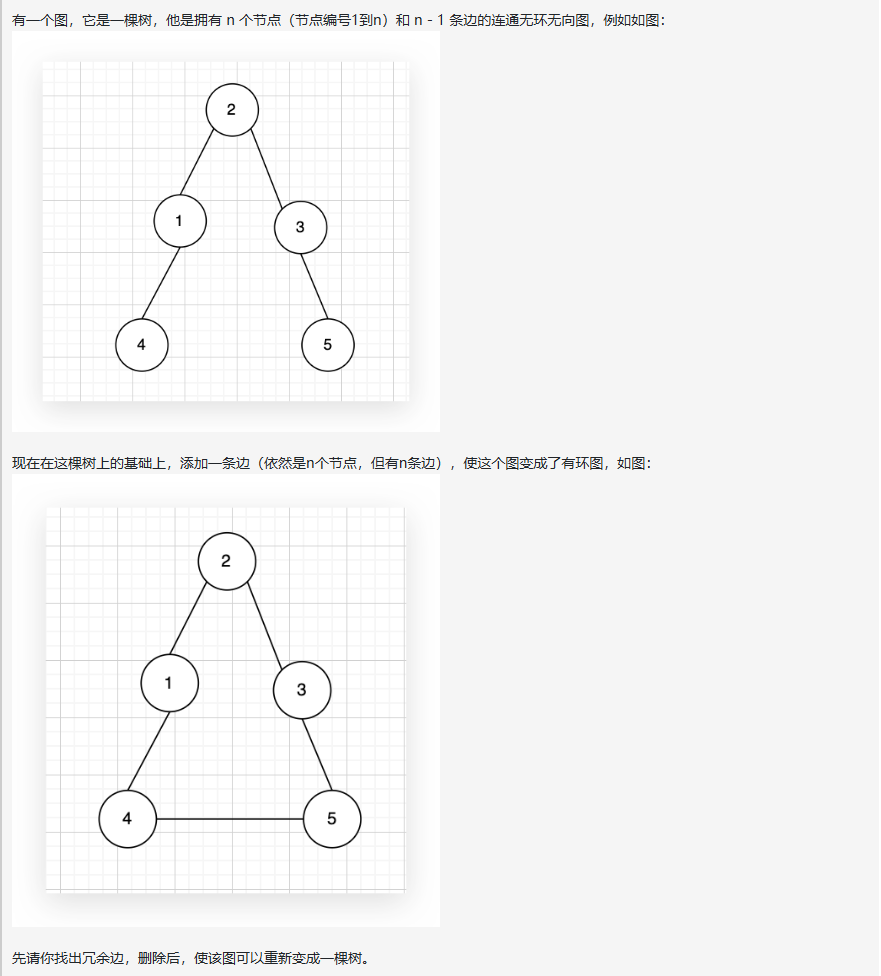
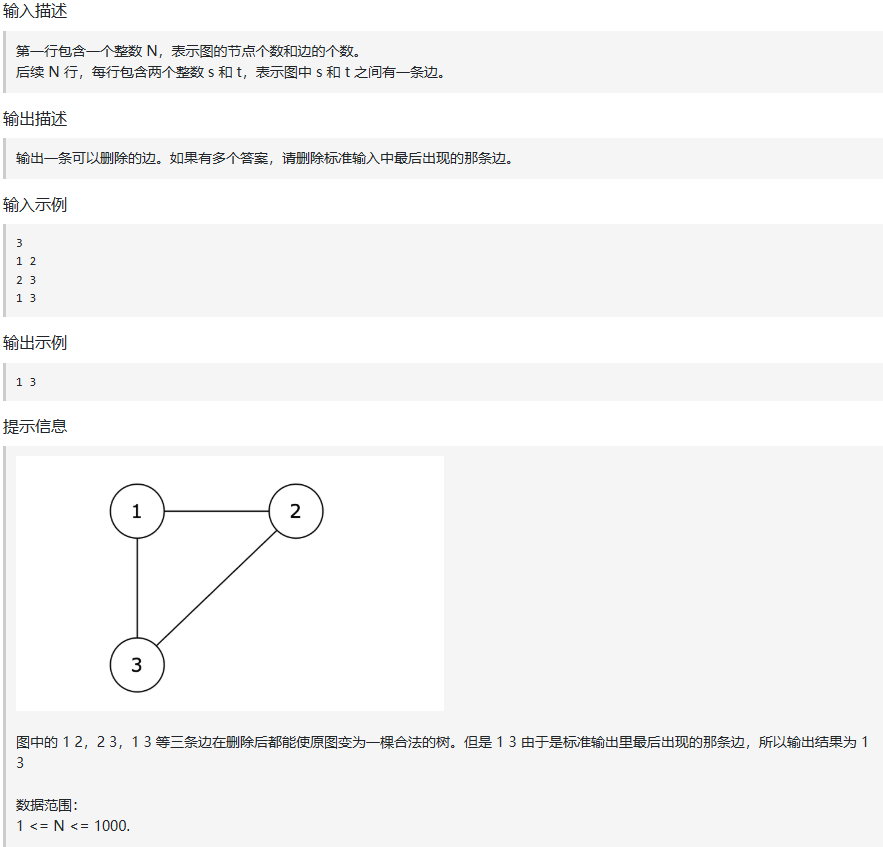
python
# 用于存储每个节点的父节点(并查集结构)
father = list()
# 查找某个节点的根节点(带路径压缩)
def find(u):
if u == father[u]:
return u
else:
# 路径压缩:让 u 直接指向根节点
father[u] = find(father[u])
return father[u]
# 判断两个节点是否属于同一个集合(即是否已经连通)
def is_same(u, v):
u = find(u)
v = find(v)
return u == v
# 将两个节点所属的集合合并
def join(u, v):
u = find(u)
v = find(v)
if u != v:
father[u] = v # 将 u 的根指向 v 的根(合并)
# 主程序入口
if __name__ == "__main__":
# 输入节点个数(注意:这题通常默认节点编号从 1 开始)
n = int(input())
# 初始化并查集数组(0 ~ n),每个节点的父亲先设为自己
for i in range(n + 1):
father.append(i)
result = None # 存放第一条构成环的边(即答案)
# 依次读入 n 条边
for i in range(n):
s, t = map(int, input().split()) # 边的两个端点
if is_same(s, t):
# 如果两个端点已经在一个集合中,说明成环
result = str(s) + ' ' + str(t)
else:
# 否则就合并两个集合
join(s, t)
# 输出成环的边
print(result)