编号:F005
文章结尾有CSDN官方提供的学长的联系方式!!
欢迎关注B站
视频
推荐算法+可视化Vue+Flask求职招聘推荐大数据可视化平台招聘python爬虫 图像识别(12W条数据)mysql 一体化系统源码+前后端分离
✅ usercf + itemcf 双协同过滤推荐算法推荐职位
✅ vue+flask 前后端分离架构,echarts可视化分析
✅ 爬虫获取数据
✅ 帅气界面,一辈子的事。
1 系统功能
- 爬取智联招聘10多个城市的12万条就业数据后,进行转化和清洗,存储到mysql数据库
- 利用Flask开发接口,对接Vue前端,实现对求职招聘数据的可视化分析(Echarts 多种图形和词云、薪酬分析)
- 百度AI身份证识别 OCR识别
- 注册与登录
2 系统亮点 ⭐
- 实现的分析图:数据大屏、职位分布中国地图、薪酬散点图、词云、多种折线图、饼图、环图等 (Vue集成 Apache Echarts); 实现jieba分词+词云。
- 推荐算法: 两种协同过滤推荐算法使用。 【User Based & Item Based】
- 实名认证功能:通过使用百度AI-ORC识别身份证实现 【python实现】
- 前端界面为专业美工设计,响应式,自动适配移动端,前后端分离一体化系统(爬虫→MySQL→Flask→Vue);
- 卡片式登录页面 + 大数据Style动画;
3 架构功能图
-
架构图
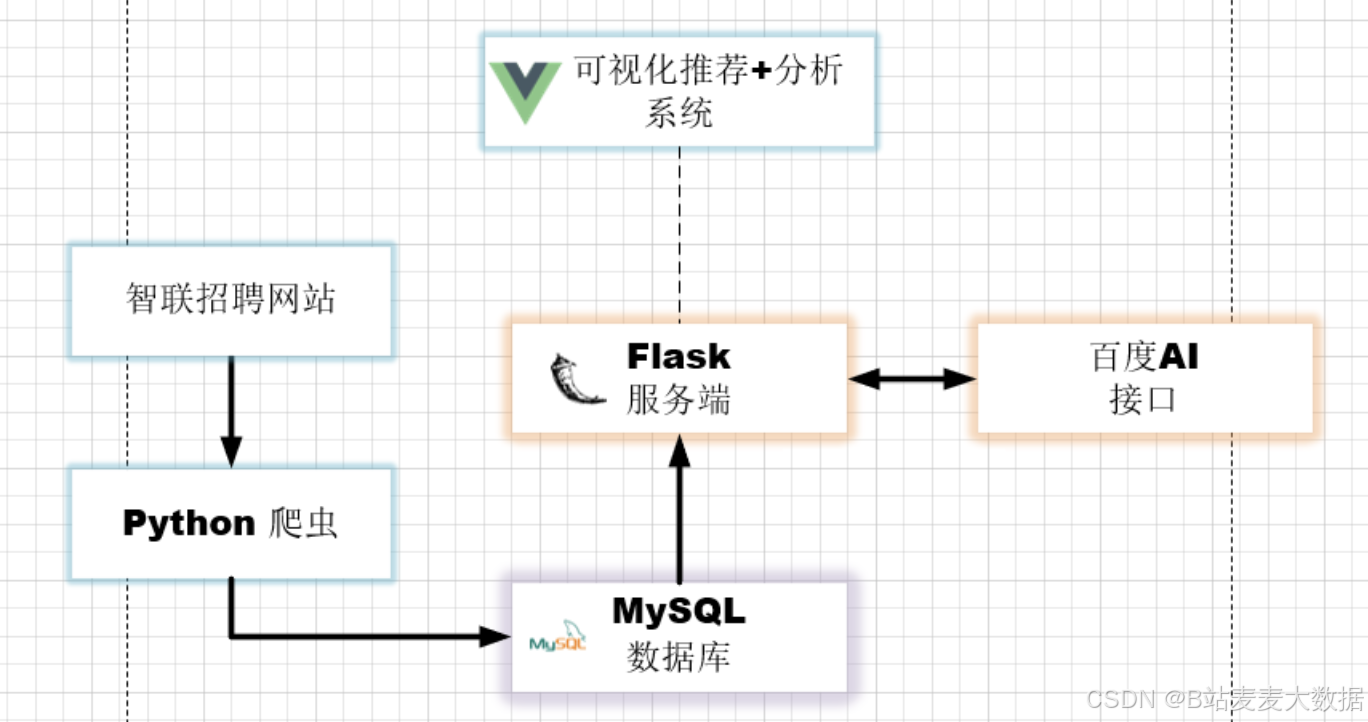
-
功能模块图
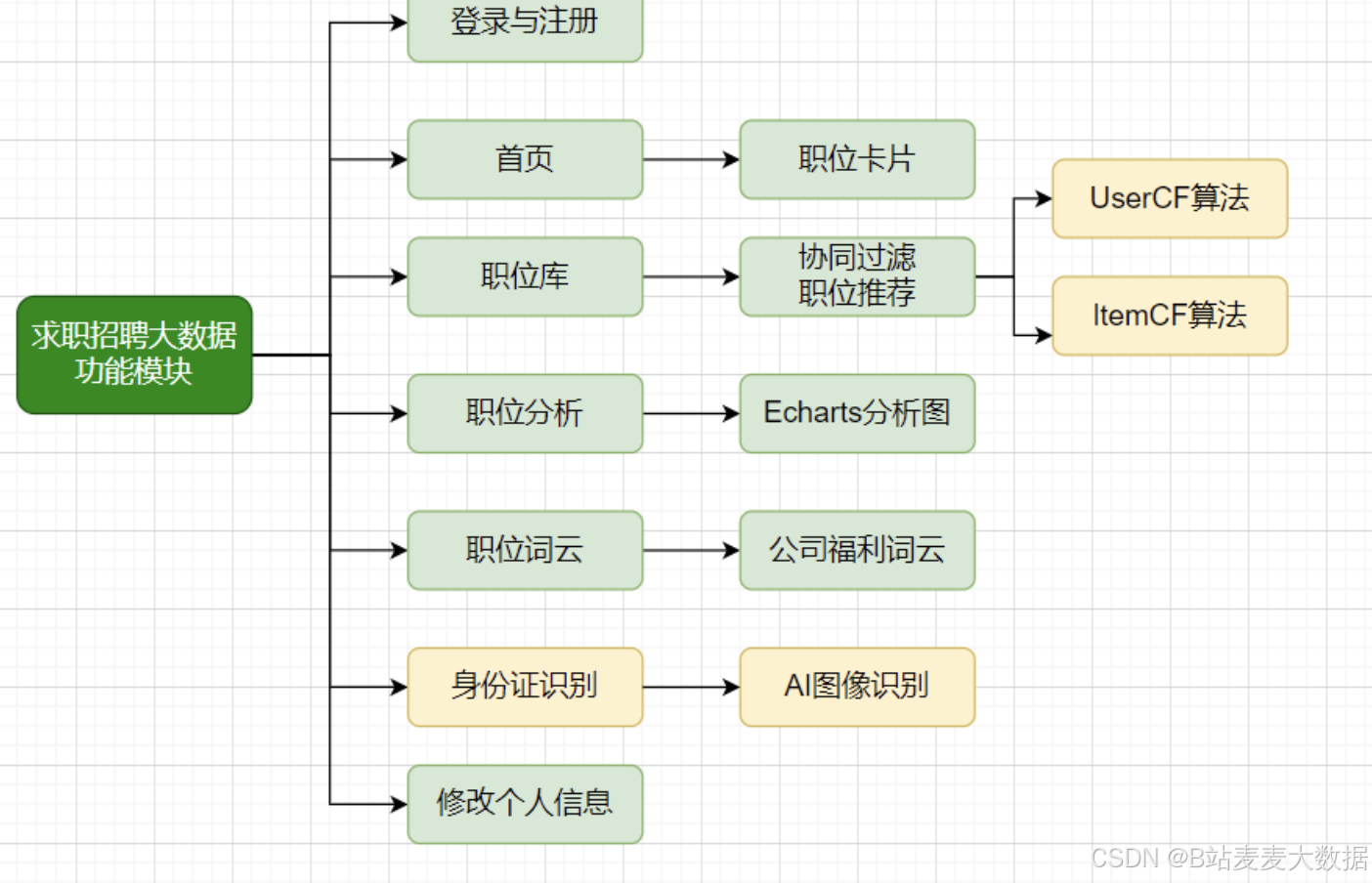
-
词云的逻辑
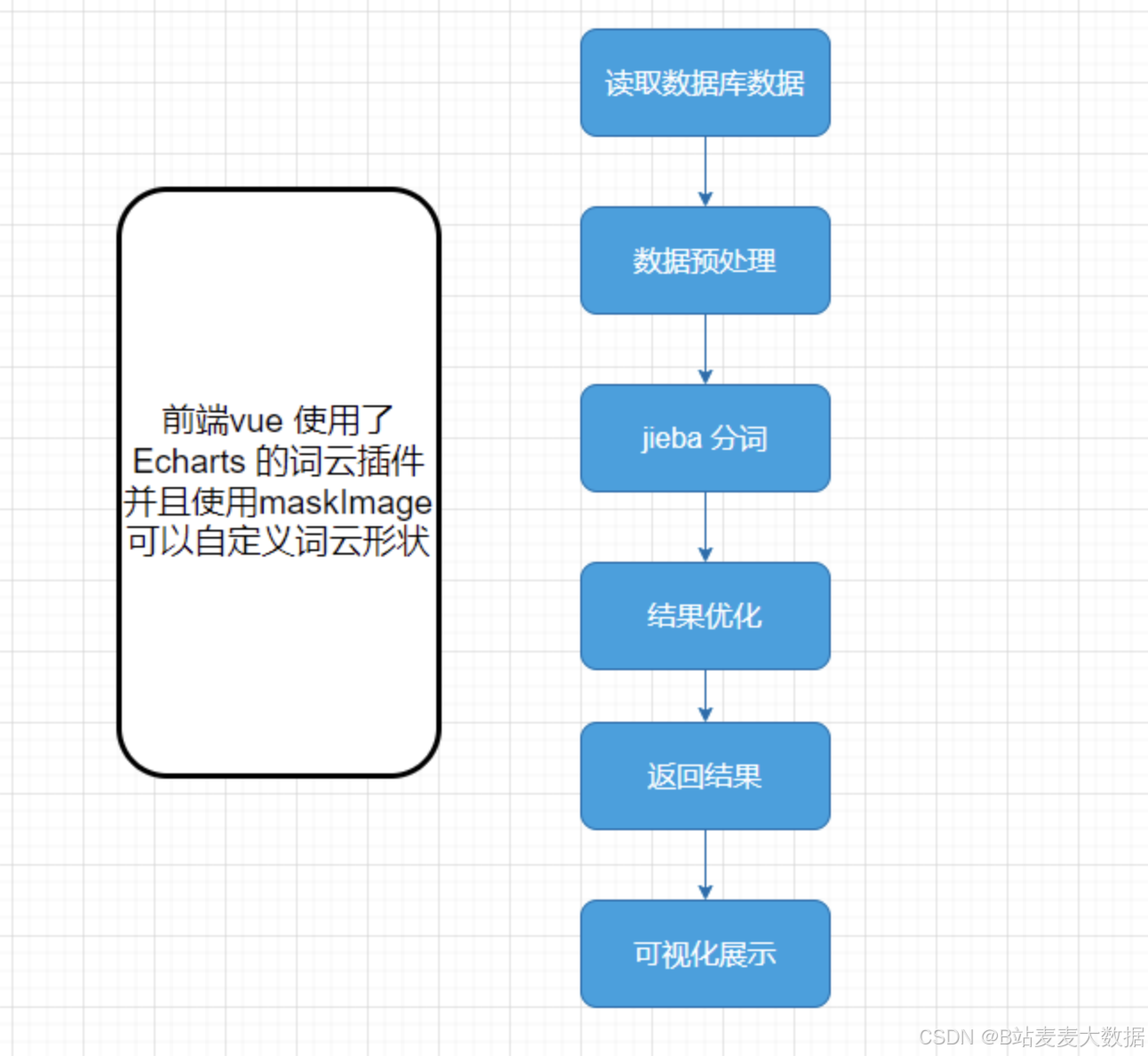
4 系统截图
-
登录&注册
-
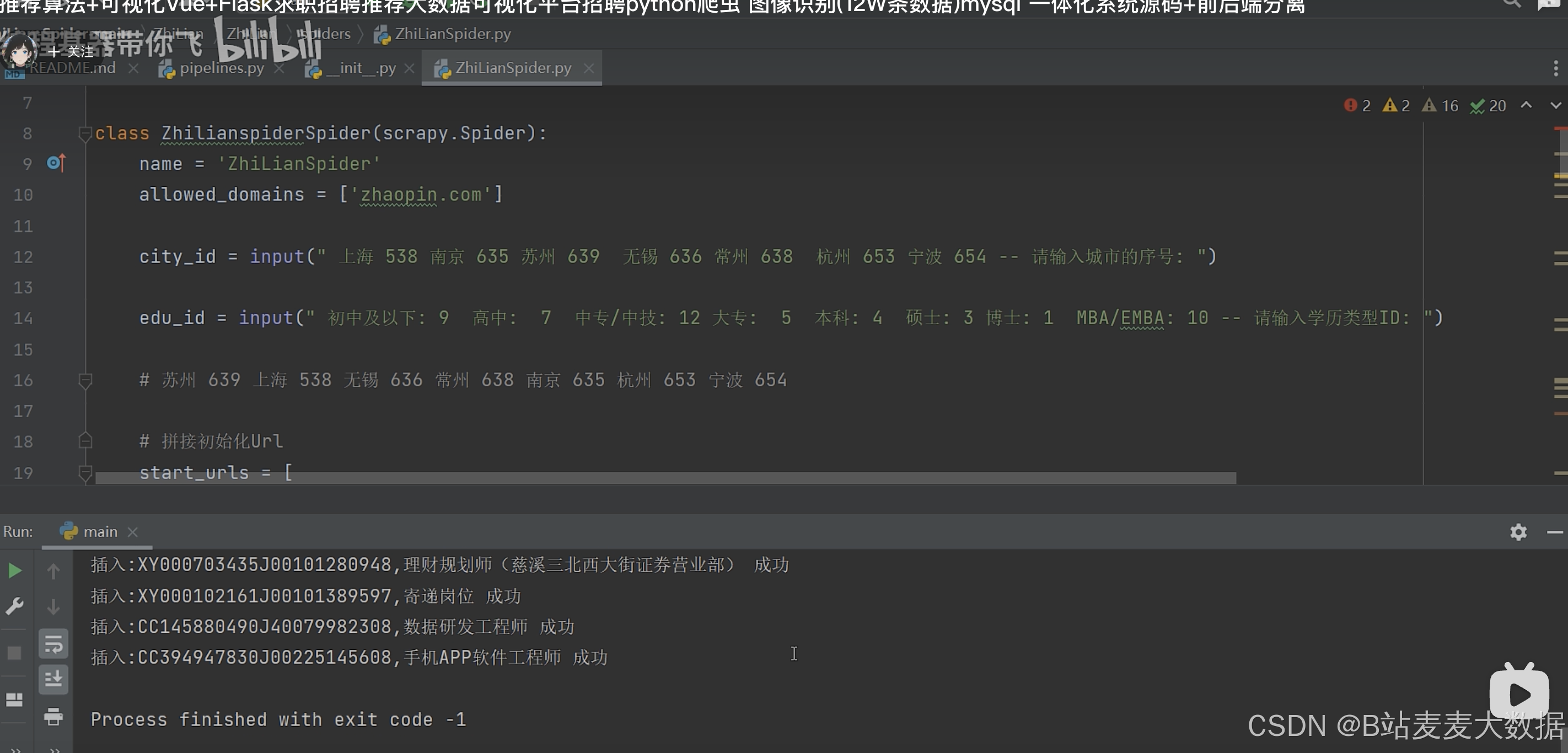
爬虫(数据的来源)
-
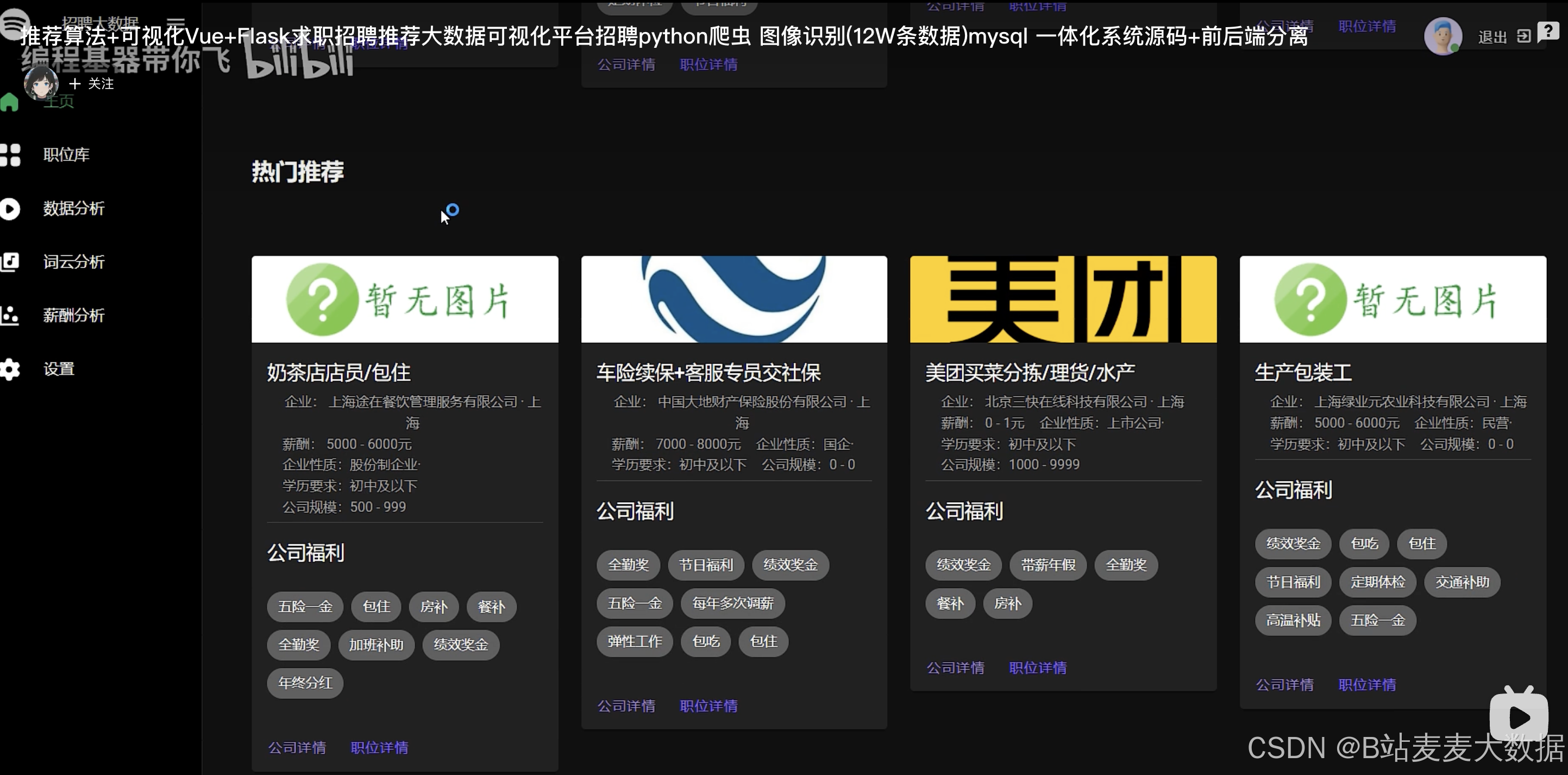
系统主页(带有usercf+itemcf双推荐算法推荐求职岗位,岗位展示图片、职位、薪酬等)
-
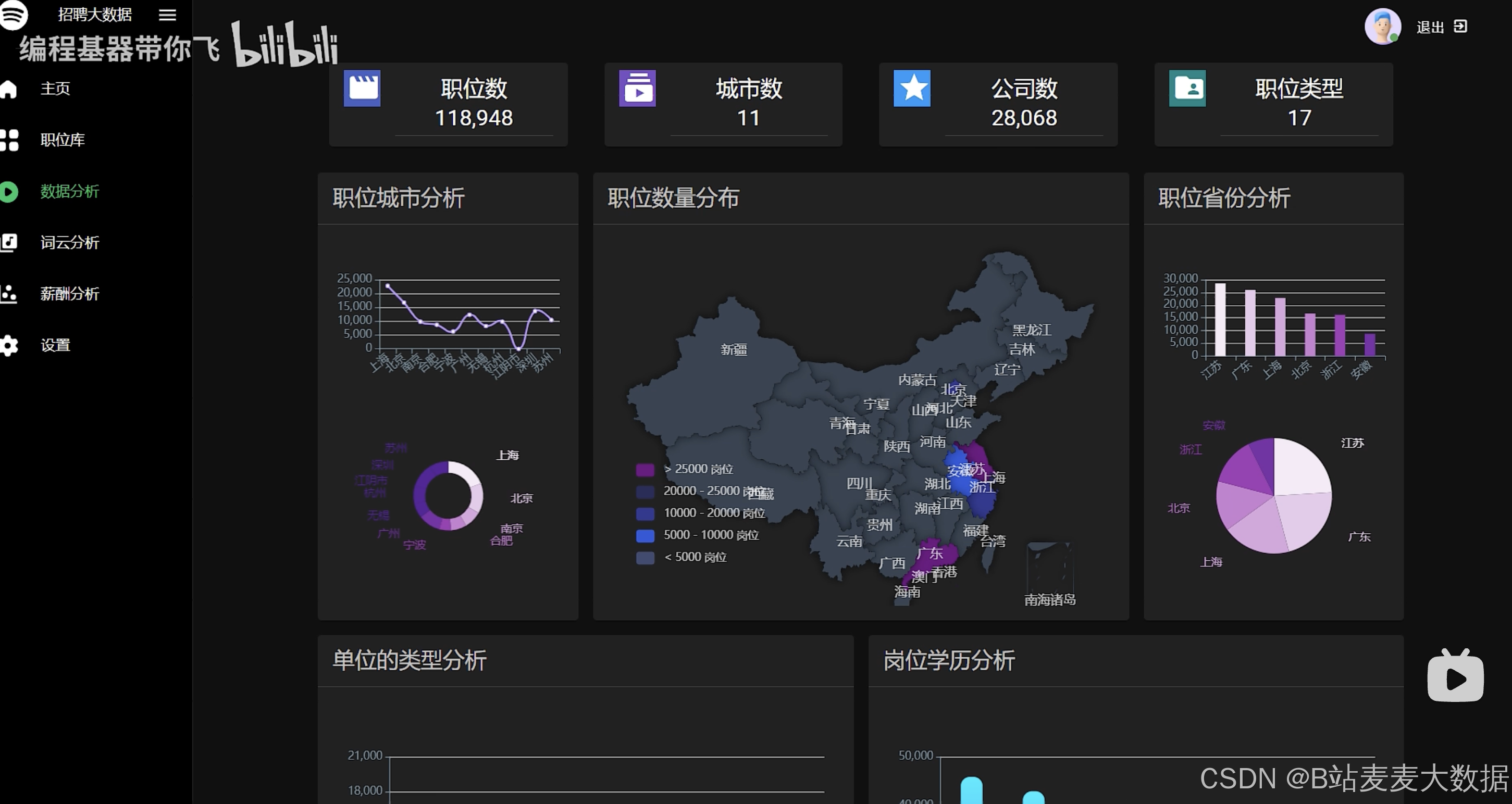
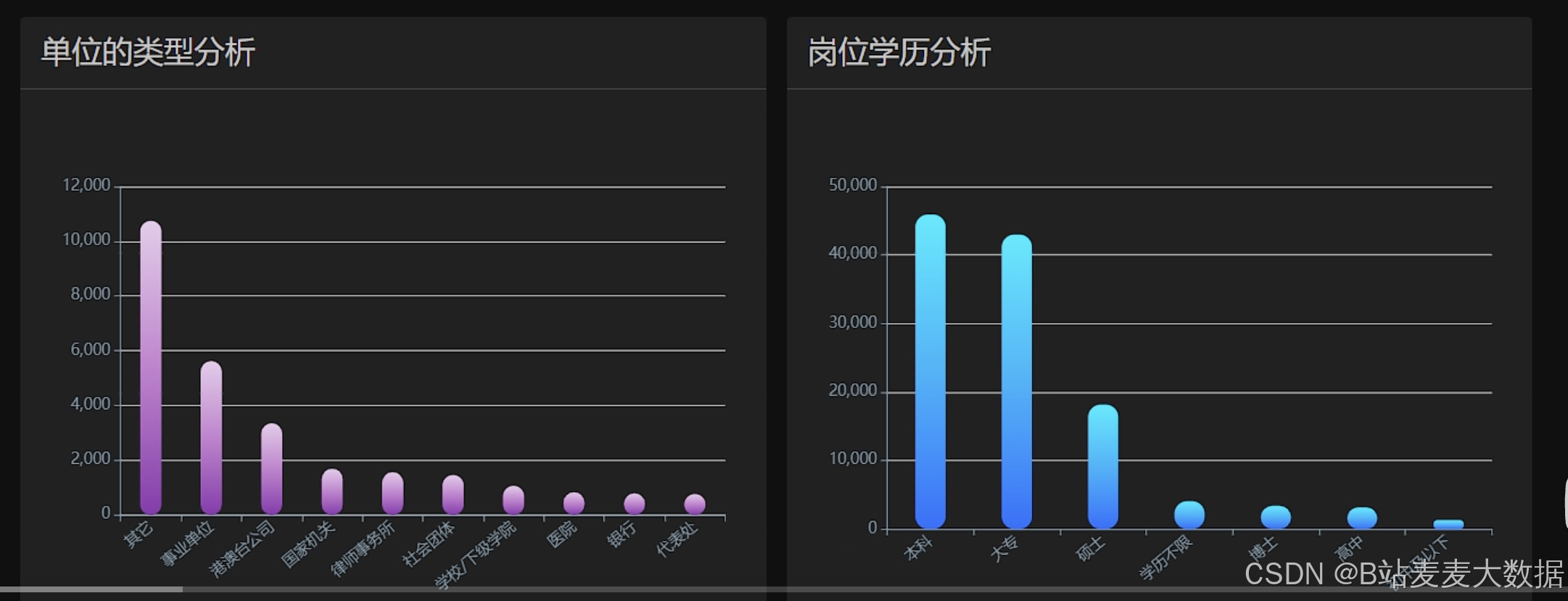
数据分析、数据大屏(带有滚动数据、职位分析、地图分析、单位类型分析等)
-
词云分析
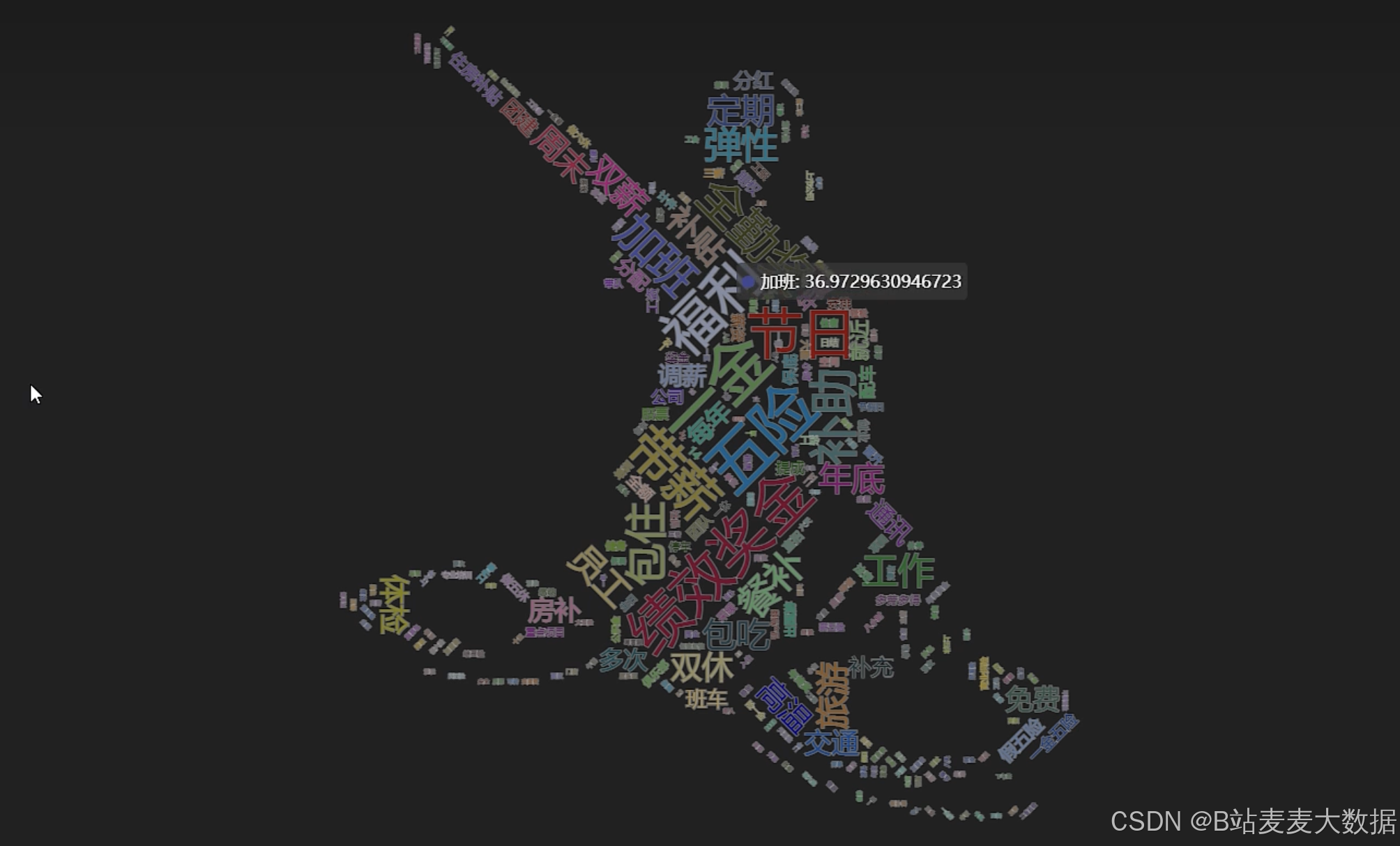
-
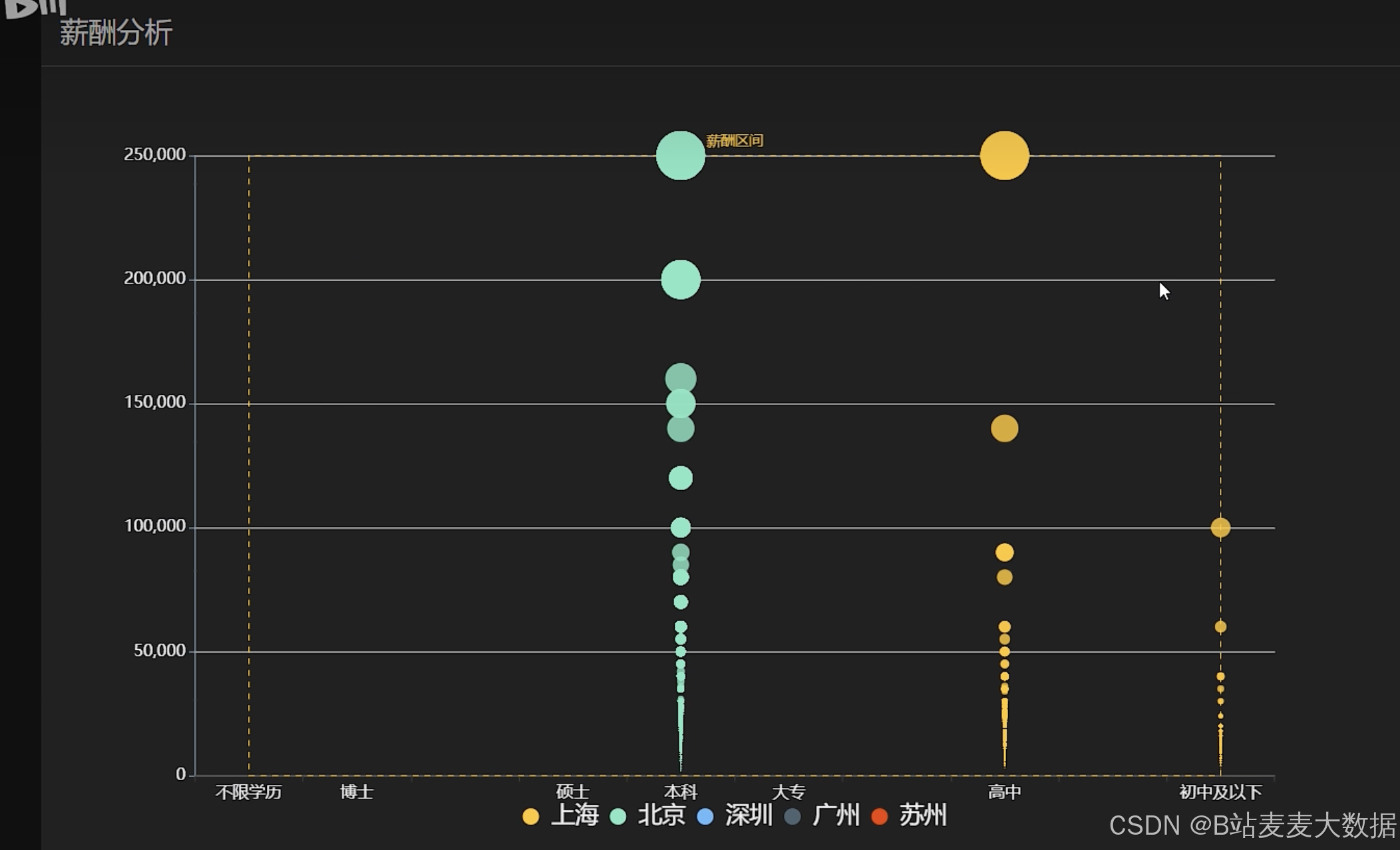
薪酬分析(散点图)
-
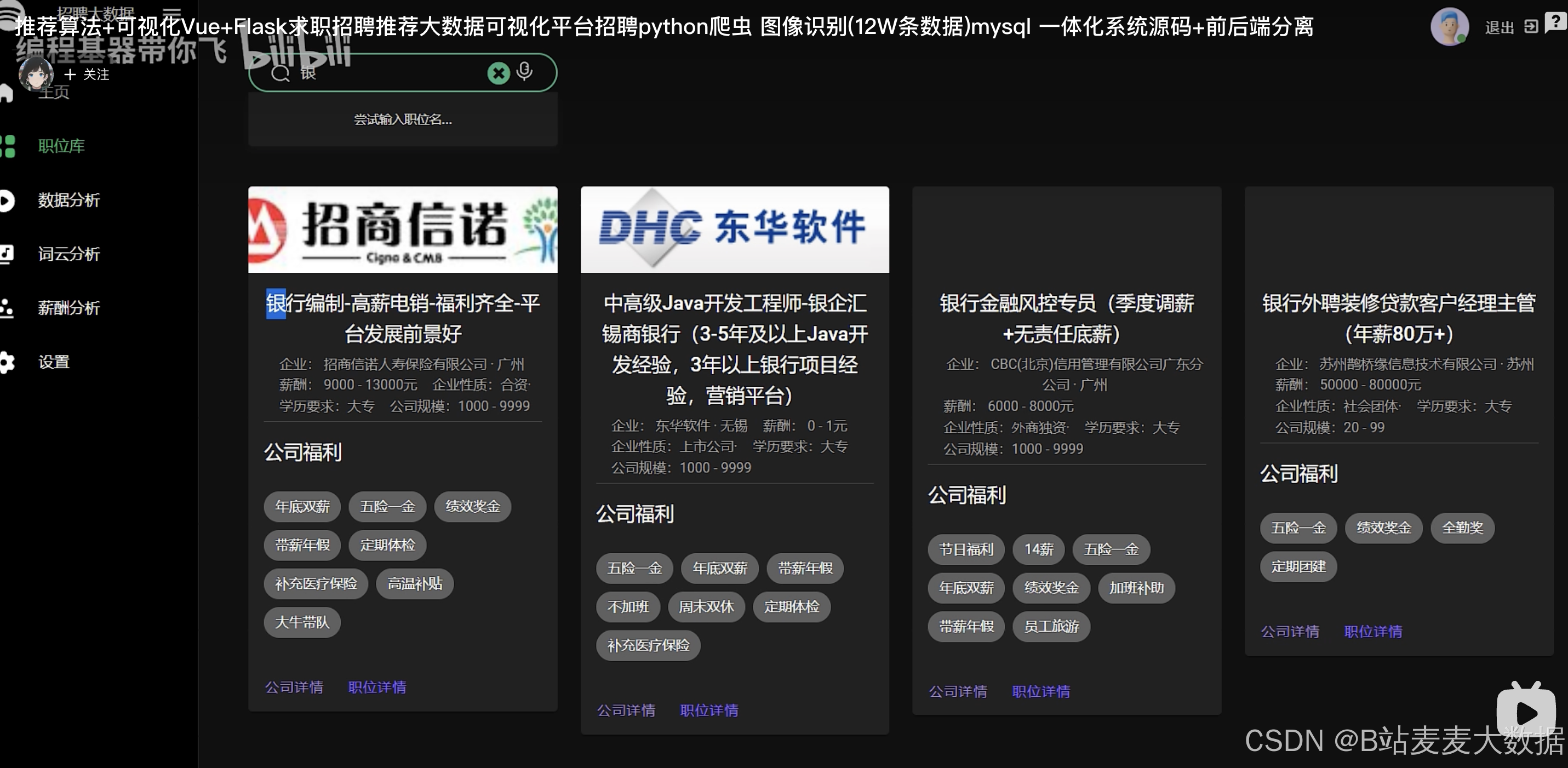
职位搜索
-
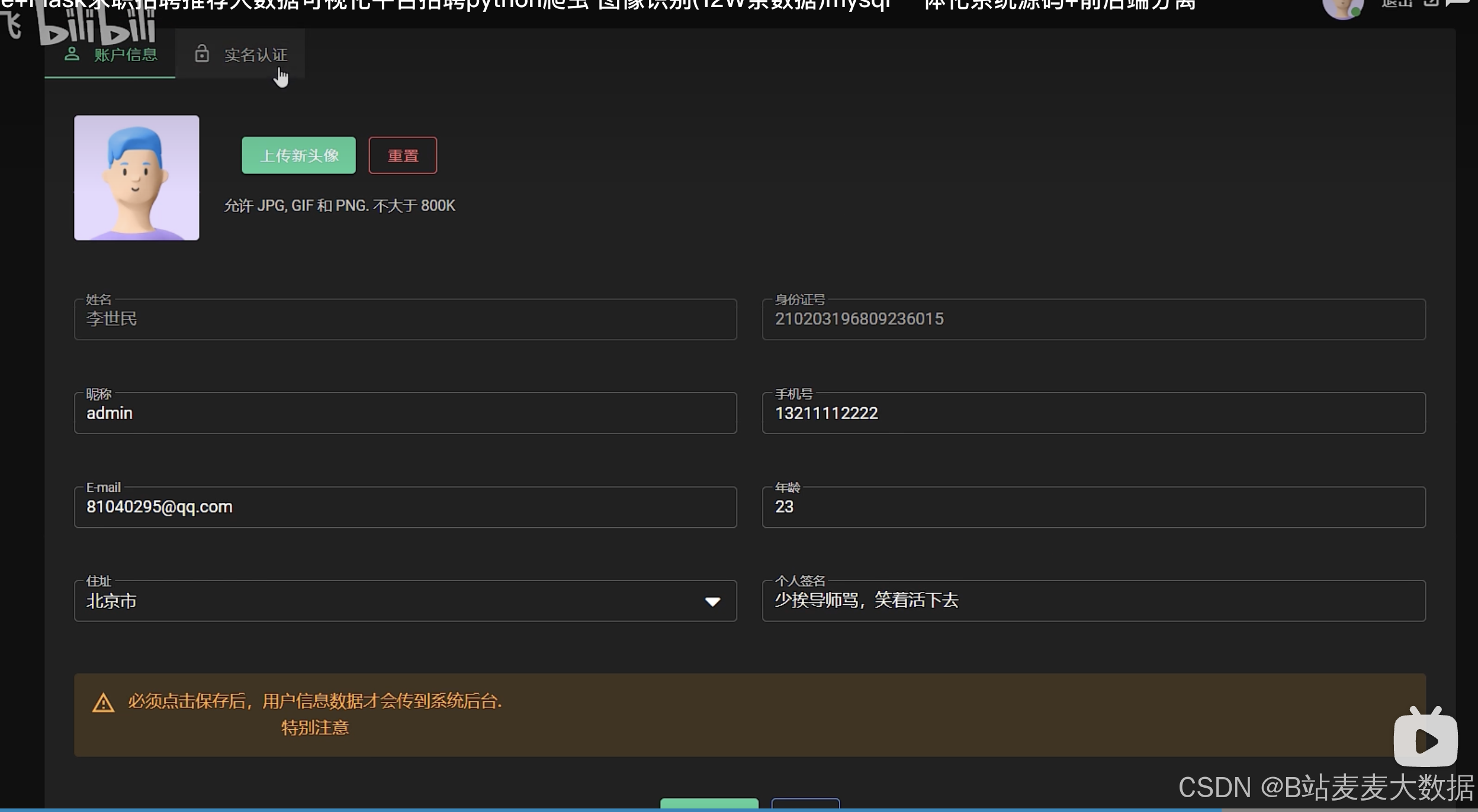
个人设置
5 开发环境和关键技术
- 服务端技术:Flask 、百度AI识别、SQLAlchemy、MarshMallow、Blueprint 等
- 前端技术:Vue 、Echarts 、Axios、Vuex等
- 爬虫技术: Scrapy 等
- 数据库:MySQL
- 开发语言: Python 3.8 Vue 2.x
- 集成开发环境: PyCharm-2021 WebStorm-2021 Windows-10 Node-12
python
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 假设我们已经将两个表加载到DataFrame
df_users = pd.read_csv('tb_user.csv')
df_jobs = pd.read_csv('tb_jobs.csv')
# 创建TF-IDF向量化器
tfidf_vectorizer = TfidfVectorizer()
# 合并用户和职位的描述字段进行向量化
df_jobs['combined_desc'] = df_jobs[['title', 'description', 'requirements']].fillna('').agg(' '.join, axis=1)
df_users['combined_desc'] = df_users[['job', 'major']].fillna('').agg(' '.join, axis=1)
tfidf_matrix_jobs = tfidf_vectorizer.fit_transform(df_jobs['combined_desc'])
tfidf_matrix_users = tfidf_vectorizer.transform(df_users['combined_desc'])
# 计算相似度矩阵(这里以用户id为索引,职位id为列)
similarity_matrix = cosine_similarity(tfidf_matrix_users, tfidf_matrix_jobs)
# 假设我们想要为某个特定用户推荐职位
user_id = 1
top_n = 5
# 获取推荐的职位ID列表
recommended_job_indices = similarity_matrix[user_id].argsort()[:-top_n-1:-1]
# 获取推荐职位详细信息
recommended_jobs = df_jobs.iloc[recommended_job_indices].reset_index()
print(recommended_jobs[['id', 'title', 'description']])