Kafka Consumer工作流程图
1、启动与加入组
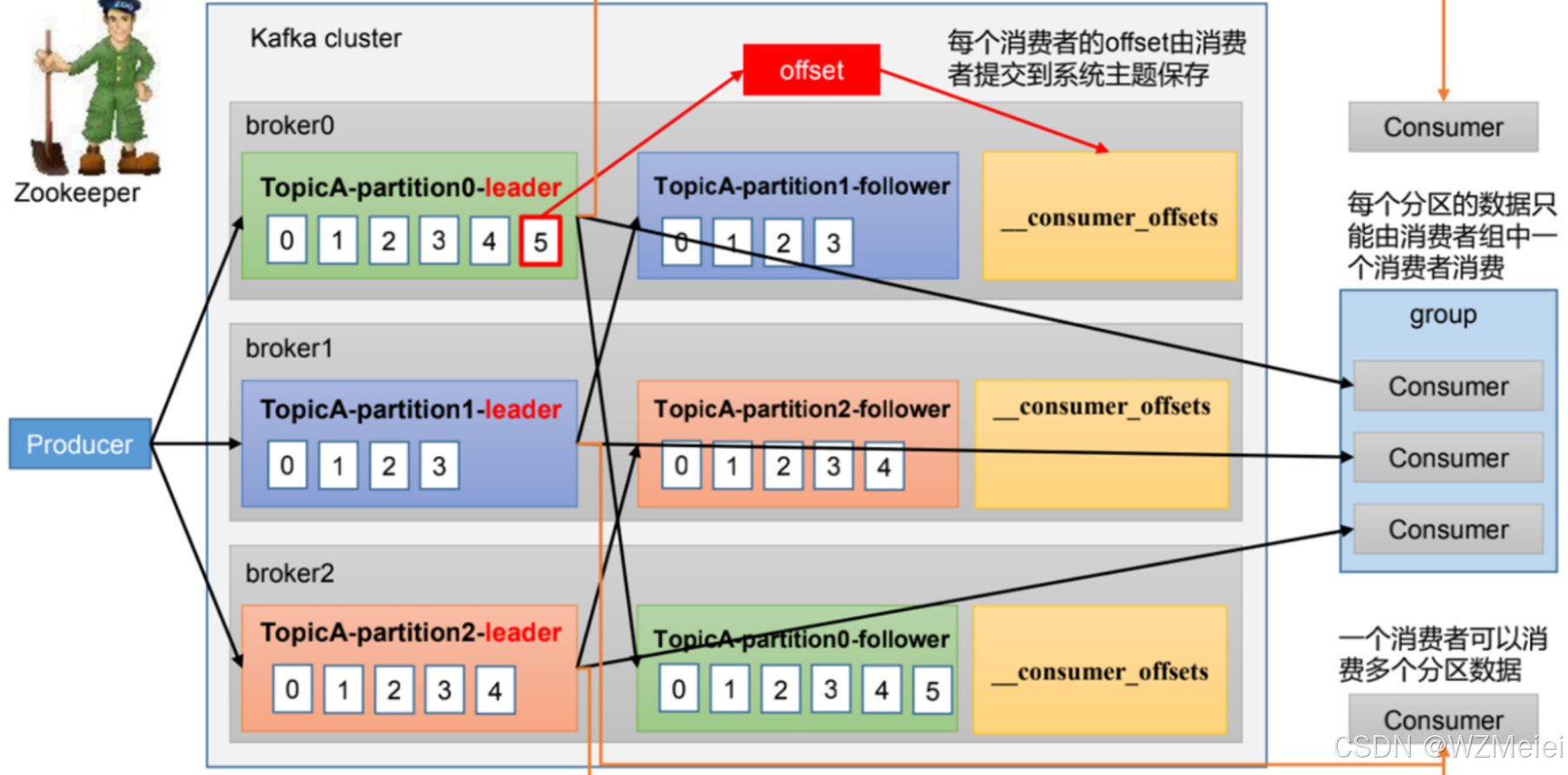
- 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。
2、组内分区分配(Rebalance)
- 消费者协调器会对消费者组内的消费者进行分区分配。一个消费者组订阅某个 Topic 时,该 Topic 的每个分区只能由组内一个消费者消费 ,但一个消费者可消费多个分区数据 。比如图中
TopicA的不同分区,会分配给组内不同消费者。当组内消费者数量变化,或 Topic 分区数量改变时,会触发 Rebalance,重新分配分区。
3、确定消费位置(获取 Offset)
- 消费者从系统主题
__consumer_offsets中获取自己上次提交的偏移量(Offset ),它标识着消费者在分区中上次消费到的位置。若首次消费或没有可查询的偏移量记录,可能从分区起始位置(最早消息 )或最新位置(最新消息 )开始消费,这取决于配置策略。
4、消息拉取
- 消费者根据分配到的分区,向对应分区的 Leader 副本所在 Broker 发起拉取请求(如向图中
broker0上的TopicA - partition0 - leader拉取 )。消费者可配置每次拉取消息的最大数量、最大字节数等参数。若 Broker 当前没有新消息,消费者可能收到空响应,也可设置等待策略,直到有新数据才返回 。
5、消息处理
- 反序列化 :拉取到的消息通常是序列化的字节数组,消费者利用配置的
key.deserializer和value.deserializer进行反序列化,将其转换为程序可处理的对象格式。 - 业务逻辑处理:对反序列化后的消息,依据具体业务需求进行处理,如写入数据库、进行计算分析等。处理过程中要兼顾可靠性和性能,防止消息积压。
6、偏移量提交
- 消费者处理完消息后,需将当前消费到的偏移量提交到
__consumer_offsets。可选择自动提交(配置enable.auto.commit=true,默认每 5 秒提交一次 ),优点是简单,但可能导致重复消费或消息丢失;也可手动提交,开发者在确保消息处理完成后提交,能更精准控制消费位置,保证消息准确消费 。