任务
1、基于iris_data.csv数据,建立决策树模型,评估模型表现;
2、可视化决策树结构;
3、修改min_samples_leaf参数,对比模型结果
代码工具:jupyter notebook
参考资料
博文:https://www.cnblogs.com/zwh0910/p/18708363
数据准备
数据集名称:iris_data.csv
点我转到百度网盘获取数据集 提取码: 8497
#加载数据
import pandas as pd
data = pd.read_csv('iris_data.csv')
data.head()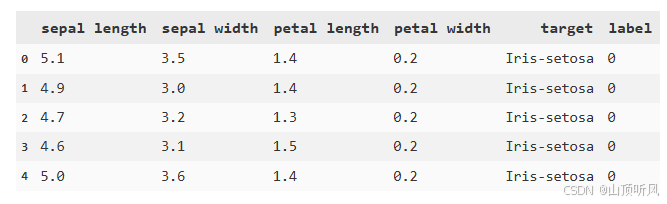
X= data.drop(['target','label'], axis = 1)
y = data.loc[:,'label']
print(X.shape, y.shape) #(150, 4) (150,)建立模型
#建立决策树模型
from sklearn import tree
dc_tree = tree.DecisionTreeClassifier(criterion = 'entropy', min_samples_leaf = 5)
#criterion='entropy'也就是采用ID3。min_samples_leaf:叶子节点最少样本数,少于最少样本数就没必要往下分了。
#决策树分裂出来的叶子最少要有5个样本,如果再往下分发现少于5个样本节点就没有必要往下分了
dc_tree.fit(X, y) #
#预测
y_predict = dc_tree.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)
print(accuracy)#0.9733333333333334决策树可视化
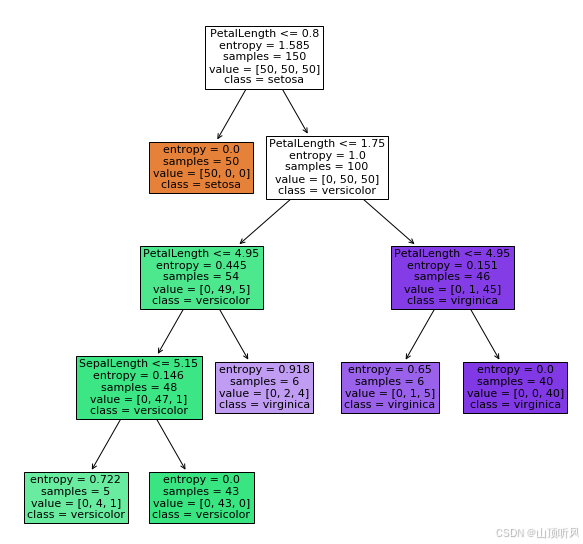
import matplotlib.pyplot as plt
fig1 = plt.figure(figsize=(10,10))
tree.plot_tree(dc_tree, filled=True, feature_names
= ['SepalLength', 'SepalWidth', 'PetalLength','PetalLength','PetalWidth']
, class_names=['setosa','versicolor','virginica'])
#填充底色, 分类名称
# filled=True表示根据不同的分类加上不同的背景颜色。feature_names是修改属性名称。class_names显示输出类别。
plt.show()