一.索引的作用:
能够提高查找的效率。
二.索引的使用场景:
在查询时这个数据非常的庞大且它的修改和插入的次数少且索引会额外的占用磁盘空间。若这个表中要经常的修改和插入则最好不要使用索引。
三.索引的生成
3.1在这个数据类型的约束条件为主键,unique,外建时则系统会自动的生成。
show index from 表名;
3.2除此之外的约束条件或者没有约束条件的话我们若要索引的话则需自己创建
create index 索引名 on 表名(字段名);
drop index 索引名 on 表名;
四.最常用的索引类型(B+树)
什么是B+树?
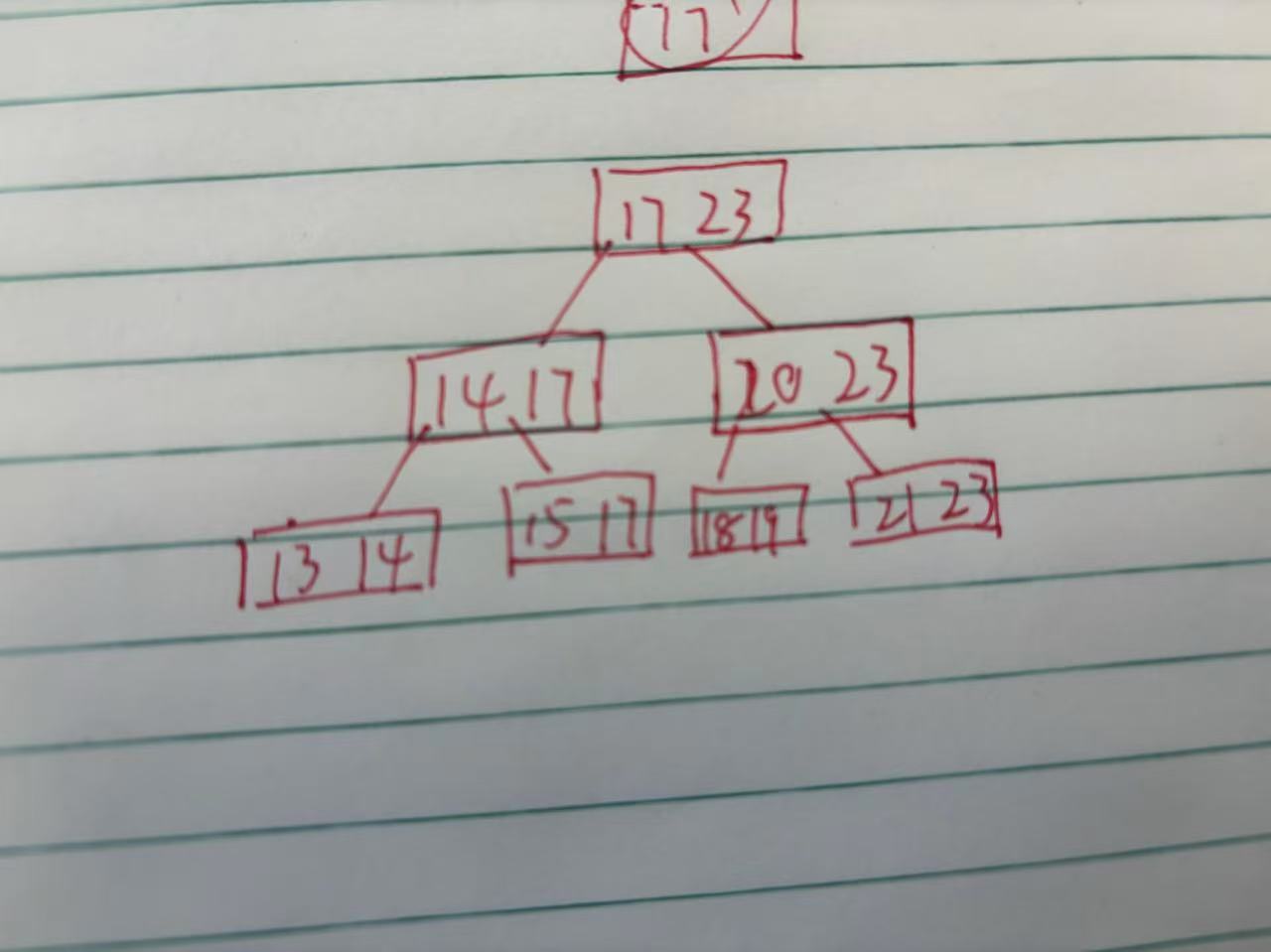
它的优点是:
1.一个结点上的n个key能有n个区间
2.每个结点上的n个key则为这个树的最大值
3.父亲节点上的每个key都会以最大值再下一个节点上(也可能会重复)
4.它会利用链表的结构将叶子结点串起来从而快速的去查询
而不用B树的原因在于它的查找不稳定时而快时而慢
原因在于它的结构会使数据散落在树的任何地方因此你每当想去查询的时候就会非常的耗时间或者非常的快而B+树不同它都是在叶子结点且还都是用链表装起来所以查找的速度就很快很迅速。
五.事务
5.1什么是事务?(原子性)
就是将一系列SQL语句装在一起然后一起去执行。
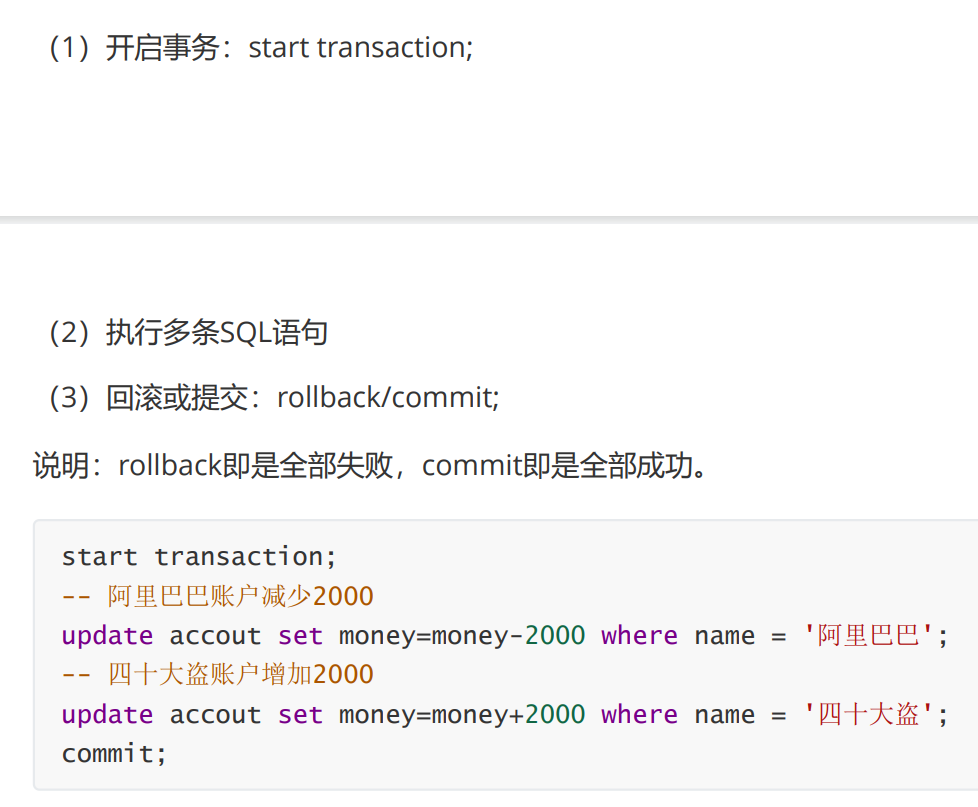
像这样子若在减少的时候出现错误那么就会开启回滚让它的数据恢复过来(它就没有减两百元)让人感觉它是没有执行的其实它早已执行完毕
当开启事务时它是还没有将这些SQL语句装在一起没有体现它的第一大特点原子性当它执行后则体现了它的原子性。
那么事务还有三大特性。
5.2 一致性
事务执行之前,和之后,数据都不能太离谱(很多时候是要靠数据库的约束以及一系列的检查机制来完成的)。
5.3持久性
事务做出的修改,都是在硬盘上持久保存的,重启服务器,数据仍然是存在,事务执行的修改仍然是有效的
5.4隔离性
数据库并发执行多个事务的时候,涉及到的问题
1.读未提交(Read Uncommitted)
- 写时对读的影响 :事务 B 写数据(未提交)时,事务 A 能读取到未提交的数据。若事务 B 回滚,事务 A 读到的数据就是临时且无效的,这就是脏读。
- 读时对写的影响:事务 A 读数据时,事务 B 可对数据进行写操作(包括修改、删除等)。
- 示例:事务 B 将账户余额从 1000 改为 2000(未提交),事务 A 读取到余额 2000。随后事务 B 回滚,余额恢复为 1000,但事务 A 已读到错误的 2000。
并发程度最高,速度最快,隔离性最低,准确率最低,
2.读已提交(Read Committed)
- 写时对读的影响:事务 B 写数据时会加行锁,事务 A 的读操作需等待锁释放,因此不会读到未提交的数据,避免了脏读。
- 读时对写的影响 :事务 A 读数据时(基于 MVCC 读取历史版本),事务 B 可对数据进行写操作(当前读),但事务 A 再次读取时会基于最新提交版本,可能导致不可重复读。
- 示例:事务 A 第一次读余额为 1000,事务 B 将余额改为 2000 并提交,事务 A 再次读余额为 2000,两次读取结果不同。
3.可重复读(Repeatable Read)
- 写时对读的影响:事务 B 写数据时加行锁,事务 A 的读操作若基于 MVCC 读取历史版本,则不受影响;若为当前读(如 SELECT...FOR UPDATE),则需等待锁释放。
- 读时对写的影响:事务 A 读数据时(基于 MVCC),事务 B 可对数据进行写操作,但事务 A 后续读取仍基于事务开始时的快照,保证了可重复读。
- 示例:事务 A 第一次读余额为 1000,事务 B 将余额改为 2000 并提交,事务 A 再次读余额仍为 1000。
4.串行化(Serializable)
- 写时对读的影响:事务 B 写数据时加锁,事务 A 的读操作需等待锁释放。
- 读时对写的影响:事务 A 读数据时加共享锁,事务 B 的写操作需等待共享锁释放,实现了完全串行执行。
比如银行统计存款大于 50 万的客户数量。事务 A 开始统计,先查询出有 10 个客户符合条件 。此时事务 B 新插入一个存款 60 万的客户记录并提交 。事务 A 再次统计时,发现有 11 个客户符合条件了 。前后查询结果不同,事务 A 就像产生了 "幻觉" ,这就是幻读 。