


MySQL(四)查询进阶
[1.group by](#1.group by)
一、查询规则
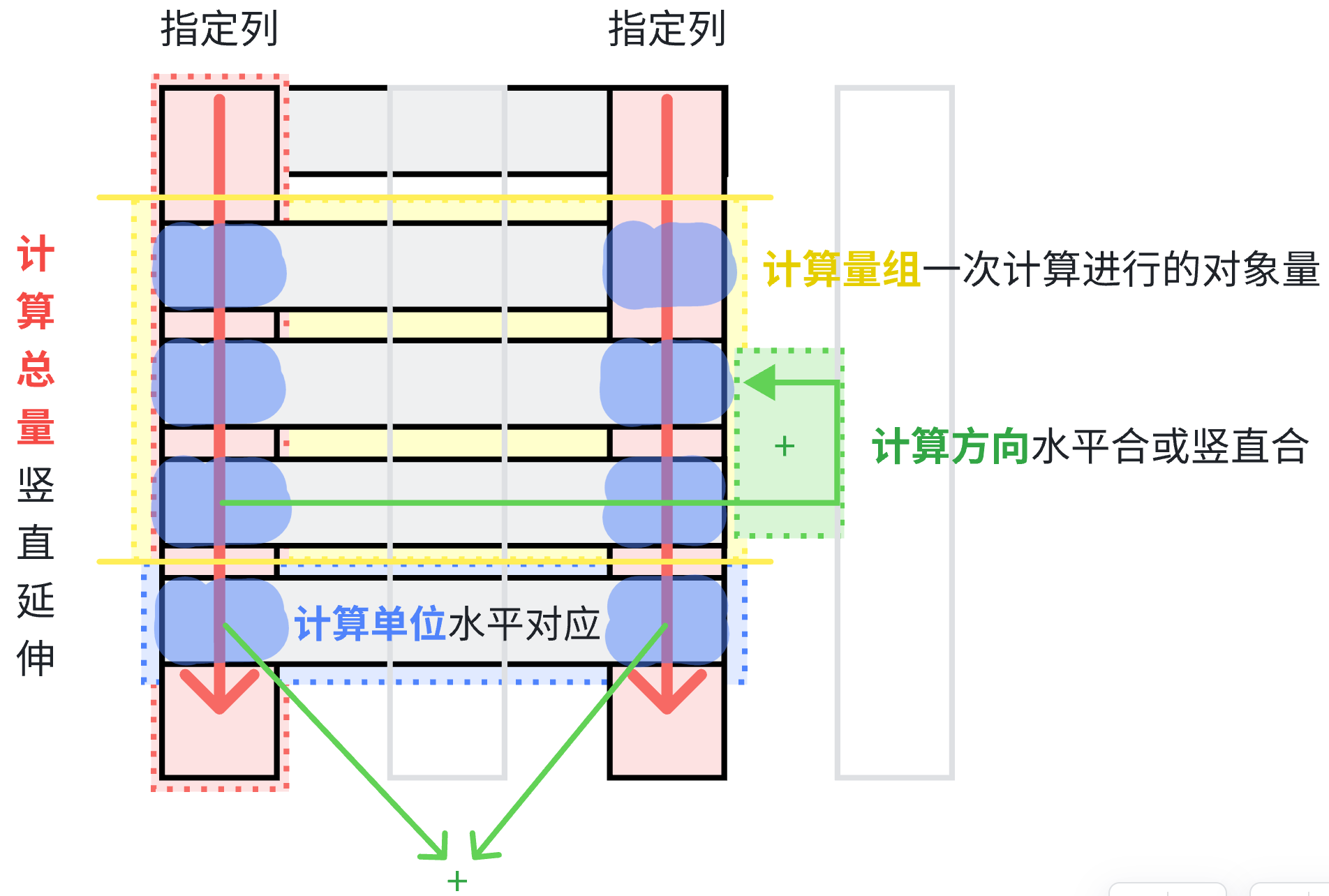
1.计算总量
计算总量 往指定列竖直延伸
2.计算单位
计算单位 是一条行水平对应
3.计算方向
计算方向 是水平合或竖直合,除了聚合函数 的计算方向为 计算单位竖直合,其它的计算方向 都为水平合
4.计算量组
计算量组 是一次计算进行的对象量,一个量组 对应一个计算结果 ,通过group by 以指定列字段合数据相同 进行分组
二、分组查询
select col,... from tb_name where 条件 group by col,... having 条件;
1.group by
group by分组 是按照 指定列字段 水平单位合数据相同的 上下水平划分成组
2.having
where条件 在分组之前 进行的条件筛选 ,写在group by的前面,having条件 在分组之后 对++合组结果++ 进行的条件筛选,写在group by的后面
三、聚合查询
sql里,函数的参数是列
- 聚合函数 都只能传入一个参数(一个列 或一个表达式列 或*),
- 聚合函数的计算方向 是特定的 计算单位竖直合
1.count
sql
select count([distinct] col) from tb_name;计算 每个计算量组里 计算单位的个数 ,除全列查询外 计算单位的数据为null的 不计入计算单位个数
2.sum
sql
select sum([distinct] col) from tb_name;计算 每个计算量组里 计算单位的数据和 ,会对计算单位里的数据 强转成double进行计算,遇到null 会跳过不参与运算
3.avg
sql
select avg([distinct] col) from tb_name;计算 每个计算量组里 计算单位的数据平均值
4.max
sql
select max([distinct] col) from tb_name;计算 每个计算量组里 计算单位的数据最大值
5.min
select min(distinct col) from tb_name;
计算 每个计算量组里 计算单位的数据最小值
四、联合查询
在表内 有信息完整的 关联字段互联的 多表 能通过关联字段拼接 把表信息 完整合并成大表 在一起
1.表的关联字段增添设计

1.1主对表单向对应
由于mysql不支持数组,设计增添表中的关联字段时,最好直接取一个 只有单向对应对象的表 为主对表,将主对表的记录全穷举完 为完整的一侧信息 ,再将关联字段 对着在主对表完整的侧面 进行共字段纽带的 对应信息填充
1.2主对表多向对应
如果两对象是++多对多++的关系 ,主对表必须得 多向对应对象时,每个记录同时对应的 关联字段多个数据 会成数组
1.2.1数组拆分
要将数组内容 并着重复id 向下拆分成 一对一的多个记录
1.2.2关联表存放
一般是++不会在主对表原表上 进行修改拆分 改变原表的记录行数据++ ,而是再设计一个 存放关联字段的中枢表 来存放这些拆分出的 所有一对一的关联记录 ,拼接时 两个表都往中枢表 关联字段地拼接 ,最后三个表拼接在一起 成完整信息的大表
2.笛卡尔积拼接
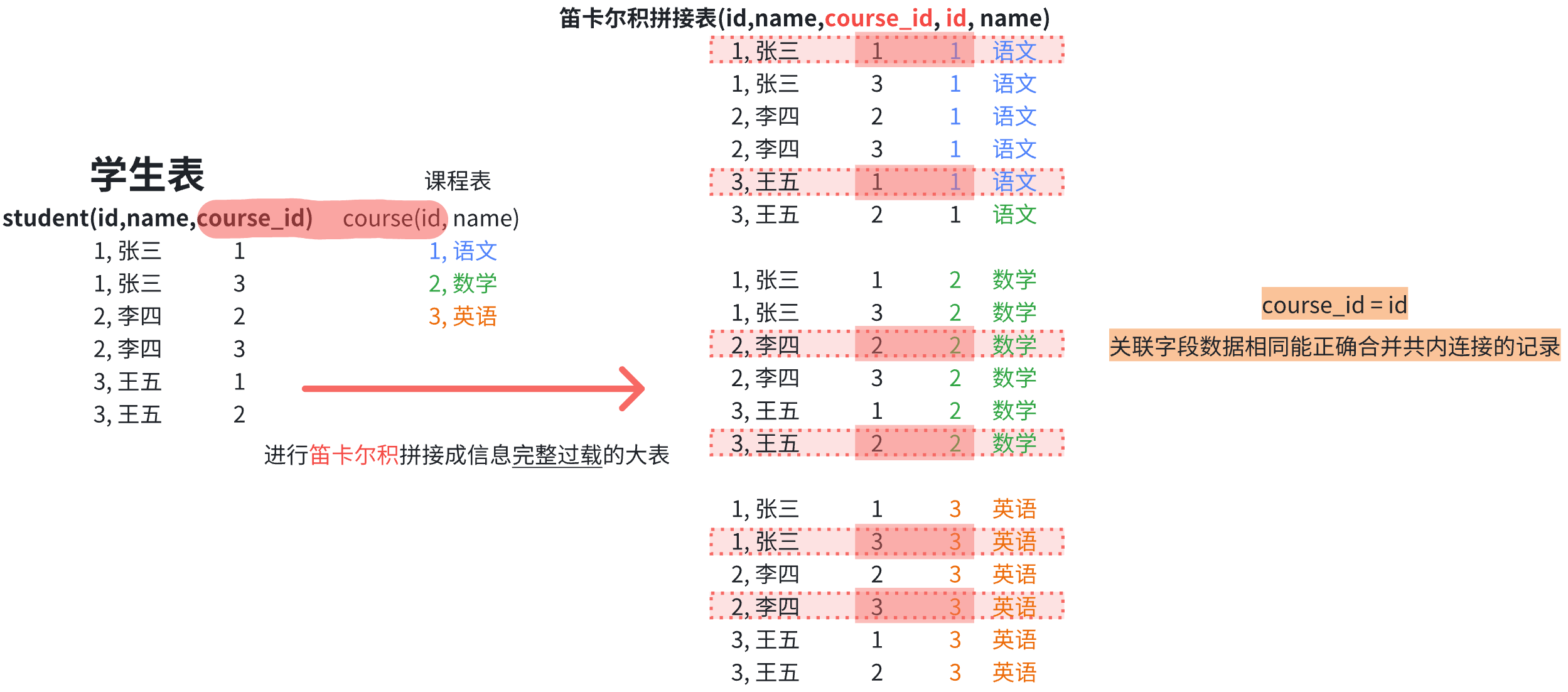
多个表中 已设计好有关联字段在内 能互相拼接的多表 去笛卡尔积拼接
2.1总拼情况
- 两个表的 列字段 属性 全部合并
- 两个表的 记录条 所有情况排列组合地 拼接成合并记录
合并后的大表的信息是完整的 但有过载着错误合拼的记录,包含有 关联字段数据不同地合拼的 错误拼接记录 与关联字段数据相同能并的 正确拼接的记录
2.2筛选拼接
用两表的 两关联字段数据相同****的 正确连接条件 搜索出完整的 正确拼接记录(内连接)
2.2.1内连接
select col,... from tb_name1,tb_name2 where recol1 = recol2;
select col,... from tb_name1 join tb_name2 on recol1 = recol2;
内连接即搜索 左右记录能相同合并共内的 ++正确++拼接的记录
2.2.2左外连接
select col,... from tb_name1 left join tb_name2 on recol1 = recol2;
把表1左外连接表2,左外连接会确保 内正确连接完后 左表记录没有连接上的记录****也全搜索出来 ,此时它对应连接的右表记录 则为空
2.2.3全外连接
全外连接会确保 内正确连接完 后 左右表记录没有连接上的记录****也都全搜索出来 ,此时它们各自对应连接的左右表记录 为空的
2.2.4自连接
select col,... from tb_name as name1, tb_name as name2 where name1.recol = name2.recol
将表 自己与自己进行笛卡尔积拼接,sql中的条件比较 都是对列与列之间进行的 ,如果需要 对行与行之间进行条件比较,就自己的字段 对自己笛卡尔积 复制一份 到列有 ,++行与行内容之间进行的比较 就转到列上有了 就可用条件进行 行与行内容的比较了++