论文分享之Prompt优化
本文介绍几篇最近关于prompt优化的研究。
prompt格式对LLM的影响
Does Prompt Formatting Have Any Impact on LLM Performance
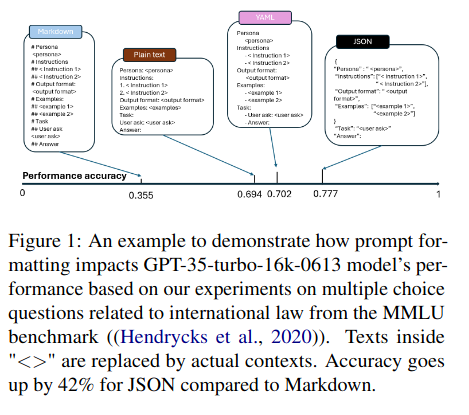
本文研究了提示(prompt)格式对大型语言模型(LLM)性能的影响,重点关注不同结构化模板(如纯文本、Markdown、JSON、YAML)在多种任务中的表现差异。通过实验发现:
- 提示格式显著影响模型性能:例如,GPT-3.5-turbo在代码翻译任务中因格式不同性能差异高达40%;在FIND数据集上,切换格式甚至导致性能提升200%。
- 模型规模与鲁棒性相关:较大的模型(如GPT-4)对格式变化的敏感度更低,性能波动较小(如GPT-4的波动范围比GPT-3.5低约50%)。
- 格式偏好因模型而异:例如,GPT-3.5偏好JSON格式,而GPT-4更适应Markdown;同一模型系列内(如GPT-3.5子版本)的格式兼容性较高,但跨系列模型(如GPT-3.5与GPT-4)的兼容性极低。
- 当前评估方法的局限性:固定模板的评估可能低估模型真实能力,需引入多样化的提示格式设计。
创新点:
- 首次系统性研究全局提示格式的影响:与先前仅关注局部修改(如标点、大小写)不同,本文全面对比了结构化模板(JSON/YAML/Markdown等)对多任务性能的影响。
- 跨模型与跨任务的综合分析:覆盖GPT-3.5至GPT-4系列模型,涵盖自然语言推理(MMLU)、代码生成(HumanEval)、代码翻译(CODEXGLUE)等六类任务,揭示了模型规模与任务类型对格式敏感度的交互作用。
- 提出量化评估指标:如敏感性(基于统计显著性检验)、一致性(输出稳定性)和可转移性(模板跨模型兼容性),为后续研究提供方法论参考。
- 揭示模型迭代的鲁棒性提升:首次验证GPT-4相较于GPT-3.5在格式鲁棒性上的显著进步,为模型设计优化提供了实证依据。
集成prompt的内容格式优化
Beyond Prompt Content: Enhancing LLM Performance via Content-Format Integrated Prompt Optimization
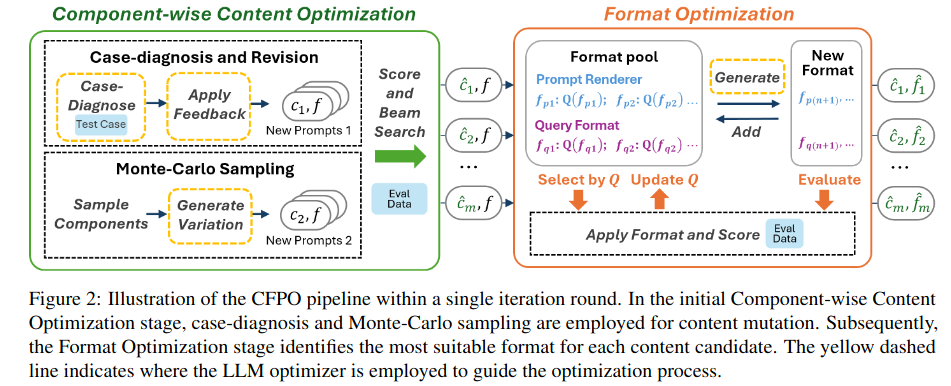
本文介绍了一种CFPO方法,可以同时优化自然语言模型的提示内容和格式。在过去几年中,LLM已经在各种任务上显示出了显著的能力,但它们的实际效果往往取决于提示设计的质量。虽然最近的研究主要关注于优化提示的内容,但是提示格式的作用也非常重要,但却很少被系统的研究。CFPO通过迭代细化过程,利用自然语言变异探索内容变化,并采用动态格式探索策略,系统性的评估多种格式选项。实验表明,CFPO比仅优化内容的方法具有可衡量的性能提升。这强调了整合内容和格式优化的重要性,并提供了一个适用于任何模型的方法来提高LLM的表现。
创新点:
- 首创内容与格式联合优化框架:首次系统性提出同时优化提示内容(语义)和格式(结构)的方法,突破传统仅优化内容的局限。
- 动态格式探索策略:提出基于 LLM 的格式生成器(LLM_f_gen)和 UCT 算法驱动的格式选择机制,实现自动化格式创新与高效搜索。
- 结构化提示模板设计:将提示分解为内容组件(任务说明、示例)和格式组件(渲染器、查询格式),支持细粒度优化,增强可解释性。
- 跨模型与任务的普适性验证:在 4 类开源模型(Mistral、LLaMA、Phi-3)和 6 类任务(分类、推理、代码生成等)中验证 CFPO 的有效性,证明其模型无关性。
- 量化评估指标创新:引入敏感性(Sensitivity)、一致性(Consistency)、可转移性(Transferability)等指标,为后续研究提供方法论参考。
对LLM语义解析的再思考
Rethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
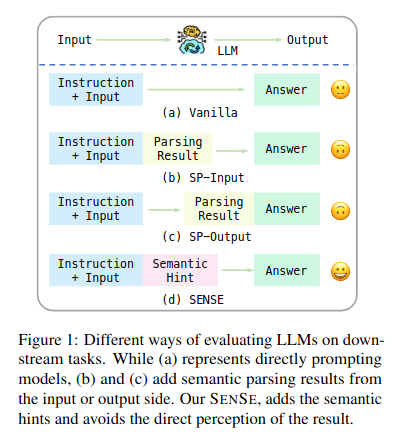
本文旨在探讨语义解析应用于LLM的效果,并提出了一个新的提示方法SENSE以提高LLM在各种任务中的性能。以往的研究表明,语义解析可以增强较小的模型在下游任务上的表现。然而,对于LLM来说,直接添加语义解析结果可能会降低其性能。为了解决这个问题,作者提出了SENSE这一新的提示方法,它将语义提示嵌入到提示中。实验结果表明,SENSE能够持续的提高LLM在各种任务中的性能,这突显来整合语义信息以改善LLM的能力的潜力。
From Prompt Merits to Optimization
Rethinking Prompt Optimizers: From Prompt Merits to Optimization
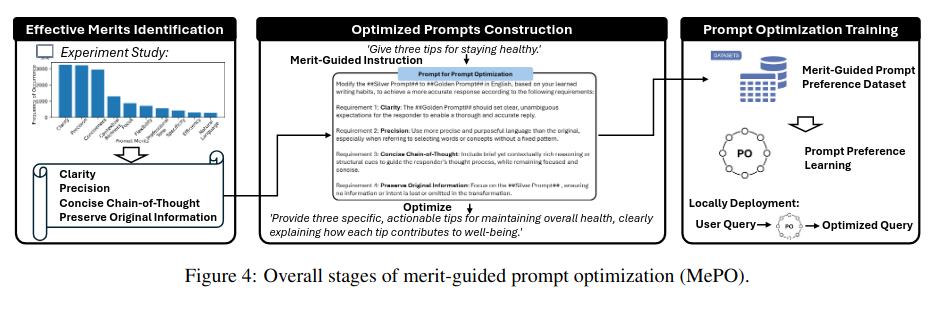
文章指出,现有提示优化方法通常依赖GPT-4等大型语言模型生成优化后的提示,但这些提示可能因冗长或指令复杂导致轻量级推理模型性能下降(即"向下兼容性不足")。为此,作者提出了一种基于明确、可解释设计的轻量级提示优化框架MePO(Merit-guided Prompt Optimizer)。该方法通过实证分析总结出四项核心提示质量指标(清晰性、精确性、简洁思维链、原始信息保留),并基于这些指标构建由轻量级模型生成的偏好数据集,训练本地可部署的优化模型。实验表明,MePO在多个任务和不同规模的推理模型上表现优于现有方法,且兼具向下兼容(适配轻量模型)和向上兼容(适配大型模型)能力,同时降低了成本与隐私风险。
文章的创新点是什么?
- 提出模型无关的提示质量指标:通过实证分析提炼出清晰性、精确性、简洁思维链和原始信息保留四项核心指标,为提示优化提供可解释的设计依据。
- 轻量级本地化优化框架(MePO):利用轻量级模型(如Qwen2.5-7B)生成符合质量指标的提示,构建偏好数据集,并通过直接偏好优化(DPO)训练本地部署的优化器,摆脱对在线大型模型的依赖。
- 兼容性与通用性验证:实验证明MePO生成的提示不仅提升轻量模型的性能,还能适配大型模型,突破了传统方法因依赖高级LLM导致的兼容性限制。
- 低成本与隐私优势:通过轻量级模型生成数据并本地训练,避免了API调用成本,同时减少数据外流风险,适用于资源受限或隐私敏感场景。
微调和训练中的prompt样本创建
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
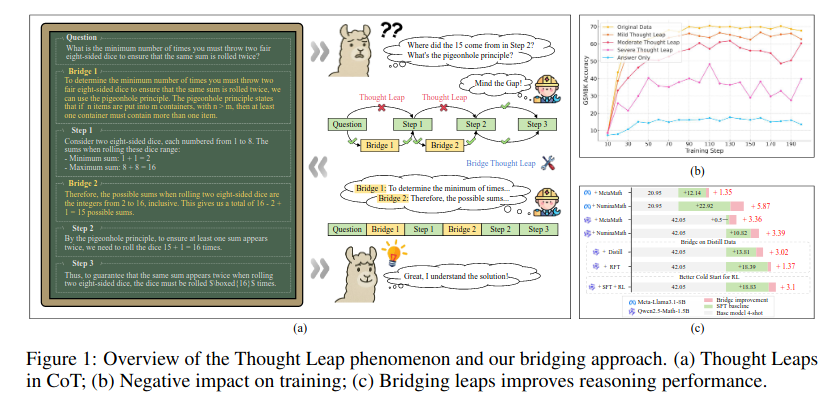
本篇论文主要探讨来大模型在数学推理任务中表现,并发现现有数据集存在"思维跳跃"问题,导致模型学习和泛化能力下降。为了解决这个问题,作者提出了"CoT Thought Leap Bridge Task",旨在自动检测并填补缺失的中间推理步骤,以恢复完整的思考链的连贯性。通过构建专门的训练数据集ScaleQM+,作者训练了一个名为CoT-Bridge的模块,可以有效地增强数据的精炼度,并提供更好的强化学习起点。实验结果表明,在数学推理基准测试中,使用桥梁数据集进行微调的模型比原始数据集上的模型表现更好,提高了高达5.87%的NuminaMath分数。此外,CoT-Bridge还展示了对域外逻辑推理任务的良好泛化能力,证实提高推理完整性能够带来广泛适用的好处。
Let LLMs Break Free from Overthinking via Self-Braking Tuning
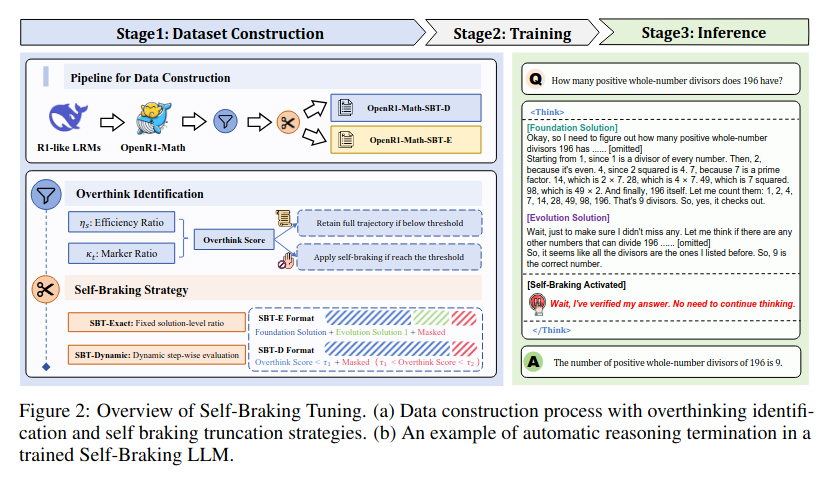
本文介绍了一种名为Self-Braking Tuning的新框架,旨在解决大型推理模型在推理过程中过度思考的问题。该方法通过让模型自我调节其推理过程,消除了对外部控制机制的依赖,并构建了一系列识别过思考的标准答案指标和检测冗余推理的系统化方法。实验结果表明,该方法能够在保持与未受约束模型相近的准确性的同时,将标记消耗降低高达60%。