卷积神经网络(Convolutional Neural Networks)
一、卷积神经网络的历史发展
Neocognitron(1980)
由 Kunihiko Fukushima 提出,Neocognitron 是最早模拟人类视觉皮层结构的人工神经网络架构。它具备层级结构与局部连接机制,可以实现位置不变性的图像识别,是现代 CNN 的雏形。
LeNet-5(1998)
Yann LeCun 等人提出了 LeNet-5,这是第一个完整定义了现代 CNN 架构的网络,包含以下核心结构:
- 卷积层(Convolutional Layer):提取局部图像特征
- 池化层(Pooling Layer):进行空间压缩
- 全连接层(Fully Connected Layer):执行最终分类任务
LeNet 使用反向传播算法进行训练,成功地应用于手写数字识别(如 MNIST)。但由于模型规模较小,难以应对更复杂的数据,如自然图像和视频。
手写数字识别中的传统方法对比
在 MNIST 数据集上,主流方法的错误率如下:
| 方法类型 | 错误率范围 |
|---|---|
| 线性分类器 | 8% ~ 12% |
| K 近邻(KNN) | 1.x% ~ 5% |
| 支持向量机(SVM) | 0.6% ~ 1.4% |
| 多层神经网络 | 1% ~ 5% |
这些结果表明,尽管传统方法在小规模图像上有竞争力,但在泛化能力和深层次语义理解方面存在局限。
AlexNet(2012)
AlexNet 是深度学习在图像领域广泛流行的转折点。由 Krizhevsky、Sutskever 和 Hinton 提出,首次在 ImageNet 2012 大规模视觉识别竞赛中获得显著胜利:
- Top-5 错误率为 15.3%,领先第二名超过 10.8%
- 使用了更深的网络结构:5 个卷积层 + 3 个全连接层
- 使用 GPU 进行加速训练,大大缩短训练时间
- 引入 ReLU 非线性激活函数,缓解梯度消失问题
- 使用 Dropout 正则化,有效防止过拟合
AlexNet 的成功充分展示了深层 CNN 模型在大数据 + 高计算资源条件下的强大表达能力。
在这里插入图片描述
二、CNN 的现实应用
随着计算能力和数据规模的增长,CNN 在多个视觉任务中得到了广泛应用:
- 图像分类(Image Classification)
- 图像分割(Image Segmentation)
- 姿态估计(Pose Estimation)
- 图像风格迁移(Style Transfer)
- 目标检测(Object Detection)
- 图像描述生成(Image Captioning)
近年来的代表性研究工作包括:
- Krizhevsky et al., 2012
- Shaoli et al., 2017
- Jianfeng et al., 2017
- Xinyuan et al., 2018
三、CNN 的基本组件
卷积神经网络主要由以下三类结构组成:
- 卷积层(Convolutional Layer):负责从输入图像中提取局部空间特征。
- 池化层(Pooling Layer):用于特征下采样,减少计算量并增强模型的平移不变性。
- 全连接层(Fully-Connected Layer):将高维特征映射为最终输出类别或值。
这些组件层层堆叠,共同构成完整的深度神经网络结构。
四、典型 CNN 网络结构展示
一个通用的 CNN 网络结构通常如下所示:
- 输入图像(通常为 RGB 或灰度图)
- 多个卷积层叠加
- 若干个池化层穿插其中
- 经过展平(Flatten)后连接若干全连接层
- 输出为分类概率或其他任务输出
这种结构可以不断提取从低级边缘特征到高级语义特征的信息。
可参考项目示例:
五、PyTorch 中的卷积层定义
在 PyTorch 中,卷积层由 nn.Conv2d 实现,常用参数如下:
in_channels:输入通道数(例如灰度图为 1,RGB 图为 3)out_channels:输出特征图数量(即卷积核数量)kernel_size:卷积核大小,如(3, 3)表示 3x3 核stride:步长,控制卷积核的滑动幅度padding:是否在边缘补零以控制输出尺寸bias:是否包含偏置项
示例代码如下:
python
import torch.nn as nn
conv = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5, stride=1, padding=2)六、卷积层的基本操作流程
我们以灰度图像为例说明卷积过程:
输入图像为 6×6:
1 2 0 1 0 1
2 1 1 0 0 1
1 0 0 2 1 0
2 0 0 0 2 1
0 1 1 2 0 2
1 0 1 0 1 1卷积核为 3×3:
1 0 -1
-1 0 0
0 0 1第一步,提取输入图像左上角 3×3 区域,与卷积核逐元素相乘后求和:
输入局部区域:
1 2 0
2 1 1
1 0 0
乘积计算:
1×1 + 2×0 + 0×(-1)
+ 2×(-1) + 1×0 + 1×0
+ 1×0 + 0×0 + 0×1
= 1 - 2 = -1这个 -1 就是输出特征图中对应位置的值。这个卷积窗口会按步长向右、向下滑动,覆盖整张图像,形成输出特征图。
七、步长(Stride)
步长决定了卷积核每次滑动时跳过的像素数:
- Stride = 1:卷积核每次移动 1 个像素,输出尺寸较大。
- Stride = 3:每次跳 3 个像素,输出尺寸较小,运算更快但信息更稀疏。
步长的选择会影响特征图的大小、感受野扩展速度及模型计算量。
八、填充(Padding)
当我们希望输出特征图与输入图像尺寸一致,或保留边缘信息时,可使用"零填充"。
示意图像的周围用 0 填充:
0 0 0 0 0 0 0 0
0 1 2 0 1 0 1 0
0 2 1 1 0 0 1 0
...这种处理方式保证了卷积核可以覆盖到图像边界,从而保留边缘特征。
九、输出尺寸的计算公式
设:
- N:输入图像尺寸
- K:卷积核大小
- S:步长
- P:填充
输出尺寸为:
O u t p u t S i z e = ( N + 2 P − K ) S + 1 Output Size = \frac{(N + 2P - K)}{S} + 1 OutputSize=S(N+2P−K)+1
这个公式适用于每一维度(宽度或高度)分别计算。
例如:
- 输入大小:6
- 卷积核大小:3
- 步长:1
- Padding:1
则输出大小为:
Output Size = floor((6 + 2×1 - 3)/1) + 1 = floor(6) + 1 = 6十、卷积核与多个滤波器
实际中,我们通常不只使用一个卷积核,而是使用多个不同的滤波器(filters)来提取不同的图像特征:
- 每个卷积核会输出一个特征图(Feature Map)
- 多个特征图堆叠后组成输出张量
例如:
- 输入:6×6×1(灰度图)
- 使用 3 个卷积核(3×3),步长为 1,无填充
- 输出为:4×4×3
不同的卷积核可以学习不同的结构模式,比如:
- Filter 1:提取边缘
- Filter 2:检测角点
- Filter 3:增强纹理
这些卷积核参数都是通过反向传播自动学习得到的。
十一、带通道的卷积操作(适用于 RGB 图像)
在之前的示例中,我们只考虑了灰度图(单通道输入)。但现实中大多数图像为 RGB 彩色图,具有 3 个通道。此时的卷积操作需要处理输入深度。
设输入张量尺寸为:
输入图像:W × H × D
卷积核:K × K × D
输出特征图:W' × H'其中:
- W, H 是图像的宽和高
- D 是输入通道数(RGB 图像 D=3)
- K 是卷积核大小
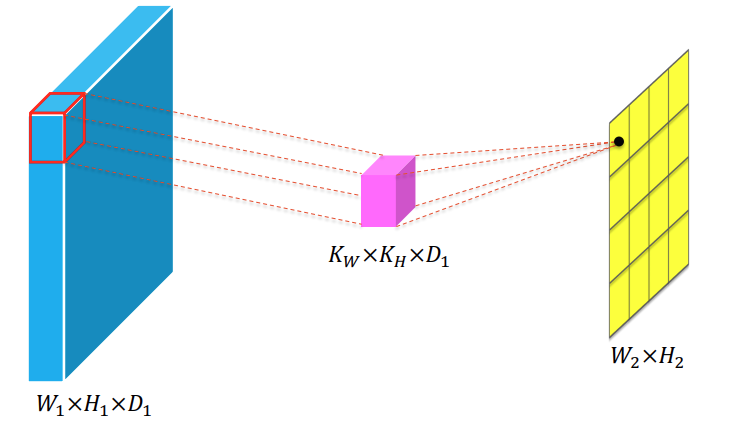
每个卷积核的深度必须与输入通道一致,卷积核将在每个通道分别滑动、乘积,再将所有通道的结果加总,得到一个输出值。
如果使用多个卷积核,则每个卷积核都执行同样操作,最终输出为多个通道的特征图。
示例:
- 输入图像为 32×32×3(RGB)
- 卷积核大小为 5×5×3
- 使用 16 个卷积核
- 输出特征图尺寸为 28×28×16(stride=1, padding=0)
十二、组合参数影响输出尺寸
我们可以通过组合 stride 和 padding 来控制输出特征图的空间大小。
设:
- 输入尺寸:W × H × D
- 卷积核大小:K × K
- 步长:S
- 填充:P
输出尺寸计算为:
W_out = floor((W + 2P - K) / S) + 1
H_out = floor((H + 2P - K) / S) + 1输出通道数由卷积核数量决定。
十三、卷积展开为稀疏矩阵乘法
卷积操作本质上是局部加权求和,可以将其转换为稀疏矩阵与向量的乘法形式。这样可以更直观地理解其线性结构与反向传播机制。
设输入张量展开为向量 x \mathbf{x} x,输出为向量 y \mathbf{y} y,卷积过程可表达为:
y = C × x其中 C 是一个稀疏矩阵(每一行对应一个卷积窗口展开),其非零元素就是卷积核的权重。如下是一个 3×3 卷积核在输入大小为 4×4 时对应的稀疏矩阵结构(仅示意):
C = [
w1 w2 w3 0 w4 w5 w6 0 ...
0 w1 w2 w3 0 w4 w5 w6 ...
...
]这种方式有助于理解:
- 卷积其实是一种稀疏线性变换
- 多个卷积核对应多个矩阵叠加输出
- 权重共享通过重复使用相同卷积核权值实现
十四、卷积层中的反向传播机制(Back-propagation in CNN)
卷积层支持端到端训练,关键在于反向传播算法的实现。
设:
- 第 l l l 层的输出为 X l X^l Xl
- 第 l − 1 l-1 l−1 层的输入为 X l − 1 X^{l-1} Xl−1
- 卷积权重(即卷积核)为 W l − 1 W^{l-1} Wl−1,其矩阵展开为 C l − 1 C^{l-1} Cl−1(稀疏线性操作)
整体卷积操作可表示为:
X l = C l − 1 ⋅ X l − 1 X^l = C^{l-1} \cdot X^{l-1} Xl=Cl−1⋅Xl−1
反向传播核心目标
反向传播需要计算两部分梯度:
- 卷积核参数 W W W 的梯度: ∂ Loss ∂ w m , n \frac{\partial \text{Loss}}{\partial w_{m,n}} ∂wm,n∂Loss
- 上一层输入 X l − 1 X^{l-1} Xl−1 的梯度: ∂ Loss ∂ x i l − 1 \frac{\partial \text{Loss}}{\partial x_{i}^{l-1}} ∂xil−1∂Loss
1. 对卷积核的梯度
卷积核中每个参数 w m , n w_{m,n} wm,n 的梯度计算为:
∂ Loss ∂ w m , n = ∑ h , k ∂ Loss ∂ x h , k l ⋅ ∂ x h , k l ∂ w m , n \frac{\partial \text{Loss}}{\partial w_{m,n}} = \sum_{h,k} \frac{\partial \text{Loss}}{\partial x^l_{h,k}} \cdot \frac{\partial x^l_{h,k}}{\partial w_{m,n}} ∂wm,n∂Loss=h,k∑∂xh,kl∂Loss⋅∂wm,n∂xh,kl
其中,输出 x h , k l x^l_{h,k} xh,kl 对卷积核参数 w m , n w_{m,n} wm,n 的偏导为:
∂ x h , k l ∂ w m , n = x h + m − 1 , k + n − 1 l − 1 \frac{\partial x^l_{h,k}}{\partial w_{m,n}} = x^{l-1}_{h + m - 1,\, k + n - 1} ∂wm,n∂xh,kl=xh+m−1,k+n−1l−1
也就是说,对某个卷积核权重 w m , n w_{m,n} wm,n,它对损失函数的影响由所有使用它的输出像素贡献相加。
2. 对输入张量的梯度
反向传播还需将误差向前传播,即计算:
∂ Loss ∂ x h , k l = ∑ j ∂ Loss ∂ x j l + 1 ⋅ ∂ x j l + 1 ∂ x h , k l \frac{\partial \text{Loss}}{\partial x^l_{h,k}} = \sum_j \frac{\partial \text{Loss}}{\partial x^{l+1}_j} \cdot \frac{\partial x^{l+1}j}{\partial x^l{h,k}} ∂xh,kl∂Loss=j∑∂xjl+1∂Loss⋅∂xh,kl∂xjl+1
由矩阵表示法 X l = C X l − 1 X^l = C X^{l-1} Xl=CXl−1 可知,其反向传播为:
∂ Loss ∂ X l − 1 = C ⊤ ⋅ ∂ Loss ∂ X l \frac{\partial \text{Loss}}{\partial X^{l-1}} = C^\top \cdot \frac{\partial \text{Loss}}{\partial X^l} ∂Xl−1∂Loss=C⊤⋅∂Xl∂Loss
即误差通过卷积矩阵的转置进行传播。对于单个元素,可以展开写为:
∂ Loss ∂ x i l − 1 = ∑ j ∂ Loss ∂ x j l ⋅ C j , i \frac{\partial \text{Loss}}{\partial x_i^{l-1}} = \sum_j \frac{\partial \text{Loss}}{\partial x_j^l} \cdot C_{j,i} ∂xil−1∂Loss=j∑∂xjl∂Loss⋅Cj,i
即第 i i i 个输入位置的梯度由所有包含它的卷积窗口反向贡献加总。
注意:公式中的 x i l x^l_i xil 表示 X l X^l Xl 展平后的第 i i i 个元素,若原始二维索引为 ( h , k ) (h,k) (h,k),则有:
i = ( h − 1 ) ⋅ H + k i = (h - 1) \cdot H + k i=(h−1)⋅H+k
这个编号方式是矩阵向量化(flatten)后常用的顺序,用于矩阵乘法形式统一表示。
小结
- 卷积的反向传播包含两个方向:
- 向前传播误差(参数更新)
- 向后传播梯度(更新输入)
- 利用展开矩阵表示,可以用线性代数的方式统一表达卷积和反卷积的关系
- 实际框架(如 PyTorch)自动完成这些计算,但深入理解这些机制对调试和优化至关重要
十五、感受野(Receptive Field)
感受野是 CNN 中的重要概念,用于描述某一神经元在输入图像上所能"看到"的区域大小。即:
某个卷积层中神经元的输出值,最终是由输入图像中哪一块区域影响的?
感受野的特点:
- 与卷积核大小、步长、层数密切相关;
- 网络越深,感受野越大;
- 池化操作和步长 > 1 会加速感受野的扩大。
示例设置
假设使用以下参数配置:
- 卷积核大小 K = 3 × 3 K = 3 \times 3 K=3×3
- 步长 S = 2 S = 2 S=2
- 填充 P = 1 P = 1 P=1
此时,每多加一层卷积,感受野会变大,但由于存在步长,增长速度为指数级。
我们可递归计算感受野 r l r_l rl 第 l l l 层的大小:
r l = r l − 1 + ( k l − 1 ) ⋅ ∏ i = 1 l − 1 s i r_l = r_{l-1} + (k_l - 1) \cdot \prod_{i=1}^{l-1} s_i rl=rl−1+(kl−1)⋅i=1∏l−1si
其中:
- r l − 1 r_{l-1} rl−1:前一层感受野大小
- k l k_l kl:第 l l l 层的卷积核大小
- s i s_i si:第 i i i 层的步长
通过该公式,可以准确估算某一深层神经元最终能感知输入图像的多大区域。
可视化理解
图像左边:
- 普通 CNN 中层与输入的对应关系是"分散的",无法直接看出感受野。
图像右边:
- 使用固定尺寸的特征图(如保持输入大小不变),则可清晰标注出每个特征点在原图上的感受区域。
- 每个中间层神经元对应的感受野中心点可以准确定位。
这种可视化策略广泛用于模型解释与感知分析。
十六、膨胀卷积(Dilated Convolution)
膨胀卷积(也叫 Atrous Convolution)是一种修改版的卷积操作,其核心思想是在卷积核内部引入空洞,扩大感受野的同时不增加参数量。
膨胀的定义
膨胀卷积的参数 Dilation Rate(膨胀率)记作 d d d:
- 若 d = 1 d=1 d=1,则为标准卷积
- 若 d = 2 d=2 d=2,表示卷积核元素之间跳过一个像素
卷积公式(1D 情况)
设输入序列为 x i xi xi,卷积核为 w k wk wk,膨胀率为 d d d,则:
y i = ∑ k = 1 K w k ⋅ x i + d ⋅ k yi = \sum_{k=1}^{K} wk \cdot xi + d \\cdot k yi=k=1∑Kwk⋅xi+d⋅k
特点总结
- 感受野增长更快(指数级增长);
- 参数量保持不变(卷积核元素没变);
- 适用于语义分割、音频建模等需要全局信息的任务;
- 可替代池化层,避免空间分辨率下降。
举例:
使用 3 × 3 3 \times 3 3×3 卷积核时:
- 普通卷积感受野为 3 × 3 3 \times 3 3×3
- 膨胀率 d = 2 d=2 d=2 时,感受野变为 5 × 5 5 \times 5 5×5
- d = 4 d=4 d=4 时,感受野为 7 × 7 7 \times 7 7×7
通过调节 d d d,模型可以在保持特征图尺寸不变的前提下获取更大的上下文信息。
膨胀卷积广泛应用于:
- DeepLab 系列模型(图像语义分割)
- WaveNet(语音生成)
- Temporal convolution(序列建模)
(参考:Yu et al., 2015)
十七、池化操作(Pooling)
池化层是一种下采样机制,通常用于:
- 降低特征图的空间维度
- 减少计算量
- 提高特征的平移不变性(translation invariance)
池化操作在卷积层之后应用,不引入可训练参数。
常见池化类型包括:
- 最大池化(Max Pooling)
- 平均池化(Average Pooling)
- L2 范数池化(L2-Norm Pooling)
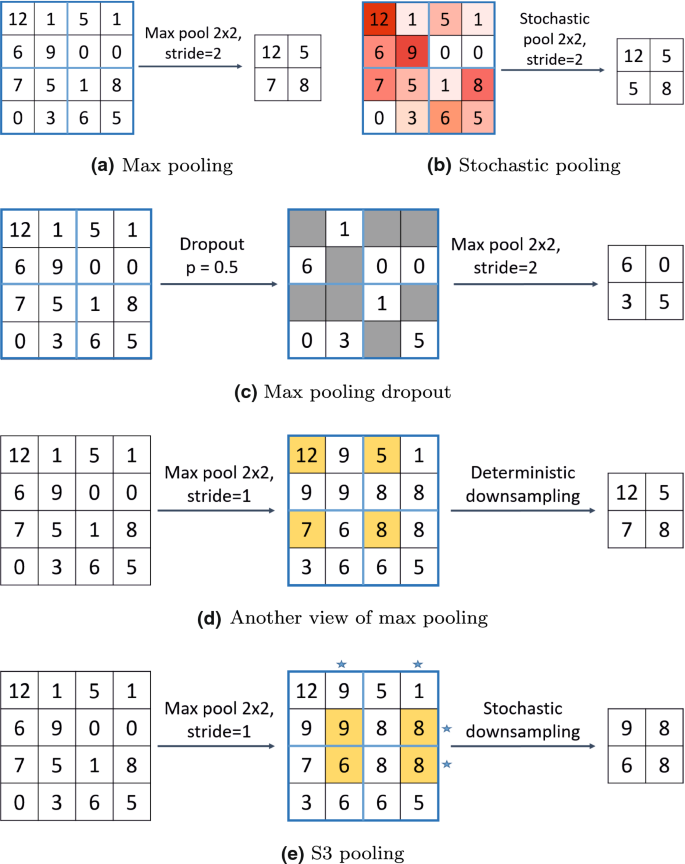
十八、最大池化(Max Pooling)
最大池化选取滑动窗口中的最大值作为输出:
- 滤波器大小: ( 2 , 2 ) (2,2) (2,2)
- 步长: ( 2 , 2 ) (2,2) (2,2)
示例
输入特征图:
-1 2 0 0
0 1 3 -2
0 0 -1 4
3 -1 -2 -2应用 ( 2 × 2 ) (2×2) (2×2) 的最大池化窗口后输出为:
2 3
3 4每个输出位置是对应窗口中的最大值。
最大池化具有选择性保留最强激活的作用,常用于分类模型中提取局部最强信号。
十九、平均池化(Average Pooling)
平均池化计算窗口中所有像素的平均值:
- 滤波器大小: ( 2 , 2 ) (2,2) (2,2)
- 步长: ( 2 , 2 ) (2,2) (2,2)
示例
输入特征图:
-1 4 1 2
0 1 3 -2
1 5 -2 6
3 -1 -2 -2最大池化结果:
4 3
5 6平均池化结果:
1 1
2 0相比最大池化,平均池化更加平滑,适合用于特征压缩、图像重建等任务。
二十、L2 范数池化(L2 Norm Pooling)
L2 池化是一种加权平均的方式,使用高斯核或其他权重模板对局部区域进行加权汇总:
定义
设池化窗口为 2 × 2 2 \times 2 2×2,对应像素为 x i , j x_{i,j} xi,j,权重为 w i , j w_{i,j} wi,j,输出为:
y = ∑ i , j w i , j ⋅ x i , j 2 y = \sqrt{\sum_{i,j} w_{i,j} \cdot x_{i,j}^2} y=i,j∑wi,j⋅xi,j2
这种方式对图像中的小幅变化更为敏感,可用于精细建模。
二十一、其他池化变种
除了标准的 Max 和 Average 池化,还有多种增强池化策略,常用于应对特定场景问题。
1. L p L^p Lp 池化
定义如下:
y = ( ∑ i w i ⋅ x i p ) 1 / p y = \left( \sum_i w_i \cdot x_i^p \right)^{1/p} y=(i∑wi⋅xip)1/p
通过选择不同的 p p p 值调节池化策略的平滑程度。当 p = 1 p=1 p=1 为平均池化, p → ∞ p \rightarrow \infty p→∞ 时趋近于最大池化。
2. 混合池化(Mixed Pooling)
为缓解最大池化容易过拟合的问题,可将最大值与平均值进行加权融合:
y = a ⋅ max ( x 1 , . . . , x n ) + ( 1 − a ) ⋅ mean ( x 1 , . . . , x n ) y = a \cdot \max(x_1, ..., x_n) + (1 - a) \cdot \text{mean}(x_1, ..., x_n) y=a⋅max(x1,...,xn)+(1−a)⋅mean(x1,...,xn)
其中 a ∈ 0 , 1 a \in 0,1 a∈0,1 是超参数,可设定或学习。
3. 随机池化(Stochastic Pooling)
不使用固定规则选择池化输出,而是基于激活概率随机选择:
y = x l where l ∼ P ( p 1 , . . . , p n ) , p i = e x i ∑ j e x j y = x_l \quad \text{where } l \sim P(p_1, ..., p_n), \quad p_i = \frac{e^{x_i}}{\sum_j e^{x_j}} y=xlwhere l∼P(p1,...,pn),pi=∑jexjexi
具有正则化作用,常用于大型 CNN 中防止过拟合。
4. 频域池化(Spectral Pooling)
将特征图转换到频域,截断高频部分再转换回来,从而实现尺寸压缩:
y = F − 1 ( F ( x ) : k , : k ) \mathbf{y} = \mathcal{F}^{-1}(\mathcal{F}(\mathbf{x}):k, :k) y=F−1(F(x):k,:k)
比空间域池化保留更多图像信息。
这些高级池化策略在视觉任务中逐步得到广泛应用,例如语义分割、目标检测和图像生成任务中。
二十二、为什么使用卷积神经网络(Why CNNs)
1. 全连接网络的局限性
在传统的全连接神经网络中,每个神经元与上一层的所有节点相连,导致:
- 参数爆炸:输入图像尺寸越大,连接权重越多。
- 空间结构丧失:图像的像素位置和邻接关系被打乱,模型难以感知局部图案。
- 长距离像素相关性弱:远距离像素间往往没必要直接连接。
例如,对于 1000 × 1000 1000 \times 1000 1000×1000 的图像,若使用全连接层处理,每个神经元都需要处理 10 6 10^6 106 个输入,这在计算和存储上都是巨大的负担。
二十三、局部连接机制(Locally Connected)
CNN 借鉴了生物视觉系统的结构,采用局部连接策略:
- 局部感受野(Local Receptive Field):每个神经元只关注输入图像中的一个小区域。
- 相当于对图像的每一小块执行局部特征提取。
优点:
- 稀疏连接(Sparse Connectivity):减少参数数量,提升计算效率;
- 位置敏感性:捕捉图像中的局部结构,如边缘、纹理等。
这种机制让神经元只关注邻域范围内的信息,形成层层抽象的特征。
二十四、局部连接的延伸问题
虽然局部连接可以捕捉小范围特征,但仍然存在问题:
- 每个滤波器只能捕捉固定位置的局部模式;
- 更高层特征依赖下层的组合能力,因此网络需要变"深";
- 最终学到的不是全图线性变换,而是非线性组合的区域特征表示。
Ranzato (CVPR 2013) 指出,深层堆叠卷积可以将局部特征组合成更复杂的、抽象的、高级语义特征。
二十五、权重共享(Weight Sharing)
CNN 的另一核心思想是权重共享:
一个卷积核在图像的所有位置上滑动使用,同一组权重参数共享。
优点:
- 参数大幅减少:显著减少模型规模;
- 平移不变性:卷积核可以捕捉图像中任意位置的特征;
- 泛化能力增强:同一结构适用于不同位置的特征检测。
示例
- 图像大小: 1000 × 1000 1000 \times 1000 1000×1000
- 卷积核大小: 10 × 10 10 \times 10 10×10
- 卷积核参数数量: 10 × 10 = 100 10 \times 10 = 100 10×10=100
相比全连接的 10 6 10^6 106 参数,卷积显得极为紧凑高效。
二十六、多滤波器机制(Multiple Filters)
CNN 中每一层卷积通常不只使用一个卷积核,而是使用多个并行卷积核(filters):
- 每个卷积核学习不同的特征(例如边缘、角点、颜色块等);
- 每个卷积核输出一个特征图,多个特征图堆叠形成张量;
- 下一层继续基于这些特征图提取更深的抽象特征。
示例
- 图像大小: 1000 × 1000 1000 \times 1000 1000×1000
- 使用 100 个滤波器,每个大小为 10 × 10 10 \times 10 10×10
- 参数总量: 100 × 10 × 10 = 10 , 000 100 \times 10 \times 10 = 10,000 100×10×10=10,000
相比全连接层的 10 8 10^8 108 级别参数,仍然大大降低。
二十七、可视化示例(直观理解多核)
不同卷积核可学习图像中的不同模式,以下是直观示例:
- 边缘检测:提取水平或垂直边缘
- 模糊滤波:平滑图像
- 图像增强:突出纹理细节
- 方向敏感性:检测垂直、对角线等方向的纹理结构

通过组合多个卷积核输出的特征图,CNN 构建出层层递进的图像理解路径。
这些机制共同成就了 CNN 在图像识别、视频分析、语音建模等任务中的强大表现力。
二十八、CNN 特征可视化(Feature Visualization)
卷积神经网络虽然结构清晰,但其内部处理过程仍较难直接理解。特征可视化技术的提出,旨在揭示:
深层 CNN 每一层到底"看到了什么"?
网络为什么能正确分类、定位图像内容?
1. CNN 的逐层处理机制
CNN 通过层层堆叠的卷积和非线性操作(如 ReLU、MaxPooling)形成逐层抽象的表示结构:
- 低层(前几层) :
- 提取边缘、颜色、纹理等底层特征;
- 中层 :
- 提取形状、结构、局部对象部件;
- 高层 :
- 学到语义级别的模式(如猫的脸、车轮等);
- 最后一层(输出) :
- 映射为分类得分(如 ImageNet 1000 个类的 softmax 向量)
2. 可视化方式一:激活图观察
直接将中间层卷积后的特征图(activation map)可视化:
- 方法:在输入图像通过网络后,截取某一层的特征图,将其转换为灰度图显示;
- 不同通道显示不同卷积核的响应强度;
- 可以观察网络"关注"的区域(如边缘、纹理、部件等);
3. 可视化方式二:反卷积(DeconvNet)
由 Zeiler 和 Fergus(2014)提出,通过反向传播中间层的激活值到输入空间,重构"神经元看到的输入"。
步骤如下:
- 固定某层的某个通道(filter);
- 将该通道的激活值保留,其余设为 0;
- 通过反卷积 + 反激活(如 ReLU)+ 上采样操作,逐层向输入图像方向反向传播;
- 重建出该通道关注的输入图案。
优点:
- 可解释性强;
- 可观察出每个 filter 对应的输入模式;
- 可用于诊断网络学习是否有效。
4. 可视化带来的洞察
通过可视化我们可以发现:
- 有些卷积核只对特定方向或纹理敏感;
- 某些深层 filter 对"物体类别"具有高度响应(例如只对狗脸激活);
- 在错误分类时可分析网络关注区域是否合理。
这些信息对于理解模型行为、调试网络结构、发现训练问题都非常有帮助。
参考论文:Zeiler & Fergus, "Visualizing and Understanding Convolutional Networks", ECCV 2014.