文章目录
- 缓存全景图
- Pre
- 问题描述
- 解决思路
-
- 一、管道(Pipelining)替代多线程
- [二、使用 Hash Tag 保证数据同槽](#二、使用 Hash Tag 保证数据同槽)
- [三、用 Hash 结构一次性批量取值](#三、用 Hash 结构一次性批量取值)
- [四、把数据直接存进 ZSET(或用 RedisJSON)](#四、把数据直接存进 ZSET(或用 RedisJSON))
- 小结

缓存全景图
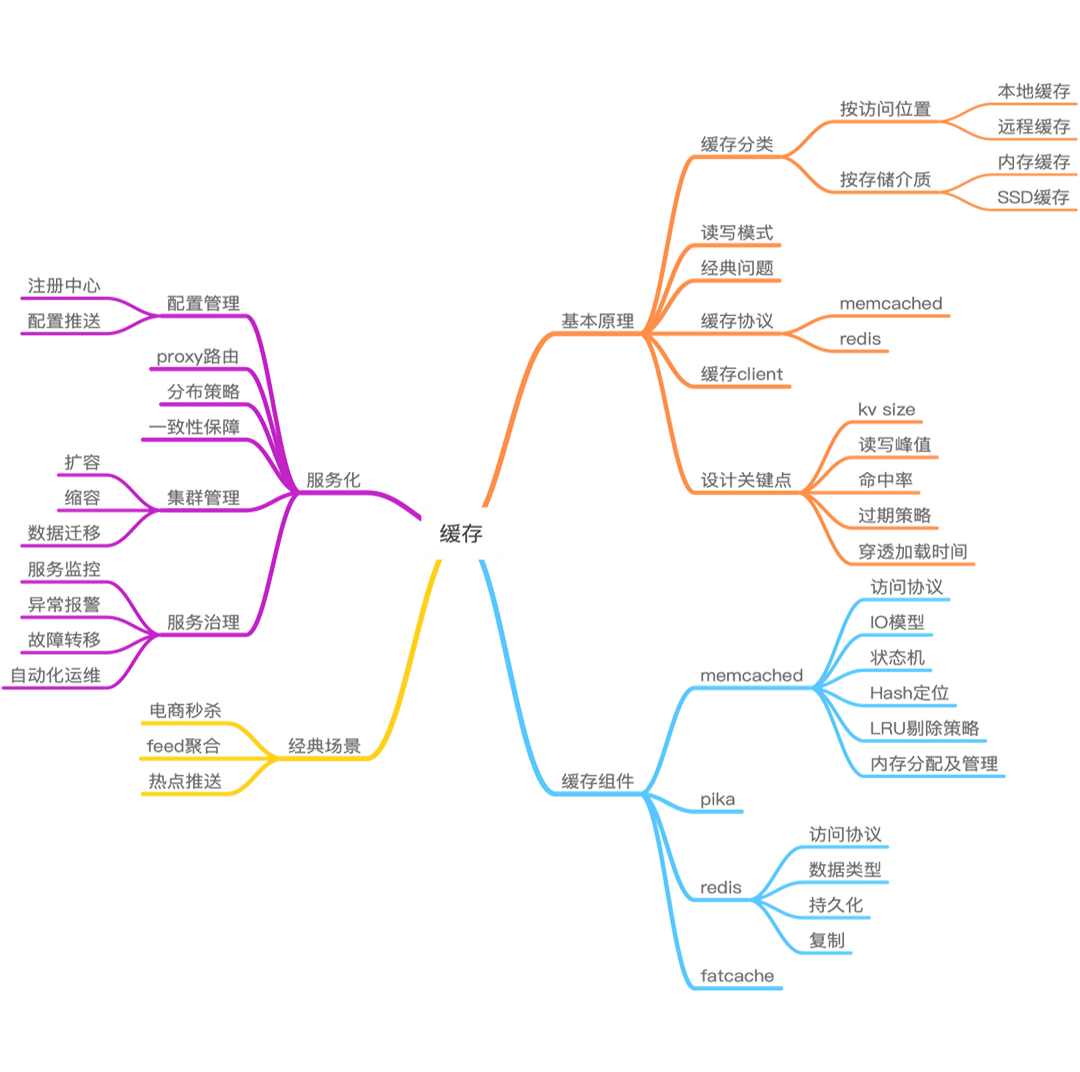
Pre
分布式缓存:缓存设计中的 7 大经典问题_缓存失效、缓存穿透、缓存雪崩
分布式缓存:缓存设计中的 7 大经典问题_数据不一致与数据并发竞争
分布式缓存:缓存设计中的 7 大经典问题_Hot Key和Big Key
问题描述
使用 Redis Cluster 时,经常会碰到 ZSET、MGET 跨槽(cross‐slot)或多线程大量并发 GET 导致的延迟和 CPU 问题, 下面说一下解决思路
解决思路
一、管道(Pipelining)替代多线程
-
问题 :用 20 个线程并发
GET,线程切换和上下文开销很大,而且大量线程会竞争 Tomcat 线程池资源。 -
建议 :在单个线程里,对每个分片的若干 key 使用 Redis Pipeline。Pipeline 可以把多条命令打包,一次性发给同一个 Redis 节点,极大减少网络往返(RTT)和线程切换开销。
- 拿到分页用的 ID 列表后,根据 ID 分别算出它们在 Cluster 中各自的 slot。
- 按 slot 分组,把属于同一 slot 的 ID 列表用一次 pipeline 批量
GET。 - 不同 slot 的分组各自 pipeline,最终合并结果即可。
-
效果 :比单条
GET快,且不必启 20 个线程,CPU 和线程池压力都会大幅下降。
二、使用 Hash Tag 保证数据同槽
Redis Cluster 要求一次多键操作(如 MGET、Lua 脚本)只能作用于同一个 slot 才不会报错。
-
做法 :给你的 ZSET key 和各个 ID key 都加上相同的Hash Tag,例如:
ZSET key: "user:123:{timeline}" ID key: "user:123:{timeline}:item:456" "user:123:{timeline}:item:789"这样 Redis 会只对
{timeline}这部分计算哈希槽,保证所有相关 key 都在同一个槽里。 -
好处:
- 就可以直接用一条
MGET user:123:{timeline}:item:456 user:123:{timeline}:item:789 ...,或者一段 Lua 脚本EVAL,一次性拉取多条数据。 - 避免了跨槽错误,也不需要分组 pipeline,代码更简单、性能更优。
- 就可以直接用一条
三、用 Hash 结构一次性批量取值
如果每条"内容"可以看成一个小对象(多个字段),还可以:
-
把所有 ID 对应的内容都存到一个 Hash,Hash 名称同样带上 Hash Tag:
HSET user:123:{timeline}:items 456 "{...json...}" 789 "{...json...}" -
查询时,
HKEYS → 拿到所有 field(ID) HGETALL 或 HMGET → 一次性批量获取分页这 20 条 content
- 优点:单个 key、单条命令就能拿到所有需要的 20 条数据,Redis 端没有多次网络往返。
四、把数据直接存进 ZSET(或用 RedisJSON)
如果对象比较小,也可考虑:
- Option A :把内容序列化后直接当 ZSET 的 member 存储,Score 用时间戳或自增序号。
ZRANGE ... WITHSCORES一次性既拿 ID(member)又拿内容。 - Option B :使用 RedisJSON 模块,把每条对象存为 JSON,Key 同样加 Hash Tag,ZSET 只存 ID,然后用
JSON.MGET(同槽下可跨多个 JSON key 一次取)来批量拉取。
小结
- Pipeline:最简单,不改数据模型,按 slot 分组即可。
- Hash Tag:相同槽内可直接 MGET 或 Lua,一条命令搞定。
- Hash 结构:把多条对象聚到一个 key,HMGET 一次性取完。
- 直接存 ZSET 或 JSON 模块:简化访问路径,避免额外的 GET。
以上方案可以各取所长,或组合使用:比如既用 Hash Tag,又用 Pipeline;或直接把热点数据存在 ZSET member 里。
