1、核心概念
1.1、流量控制
流量控制是为了 防止系统被过多的请求压垮,确保资源合理分配并保持服务的可用性,比如对请求数量的限制。
流量控制的 3 个主要优势:
- 防止过载:当瞬间涌入的请求量超出系统处理能力时,会导致资源枯竭,如 CPU和内存耗尽。流量控制通过限制系统能处理的请求数,确保不会发生过载。
- 避免雪崩效应:高负载下某个服务崩溃可能引发其他依赖服务的崩溃,形成连锁反应。流量控制可以有效预防这种连锁故障,避免系统雪崩。
- 优化用户体验:即便部分请求被拒绝或延迟处理,流量控制也能确保大部分用户的请求能够正常响应,避免全局响应时间过长的情况。
常见的实现流量控制方法有 2 种:
- 限流:通过固定窗口、令牌桶或漏桶等算法限制单位时间内的请求数量。
- 排队:当请求量超出处理能力时,部分请求进入等待队列,防止立即超载。
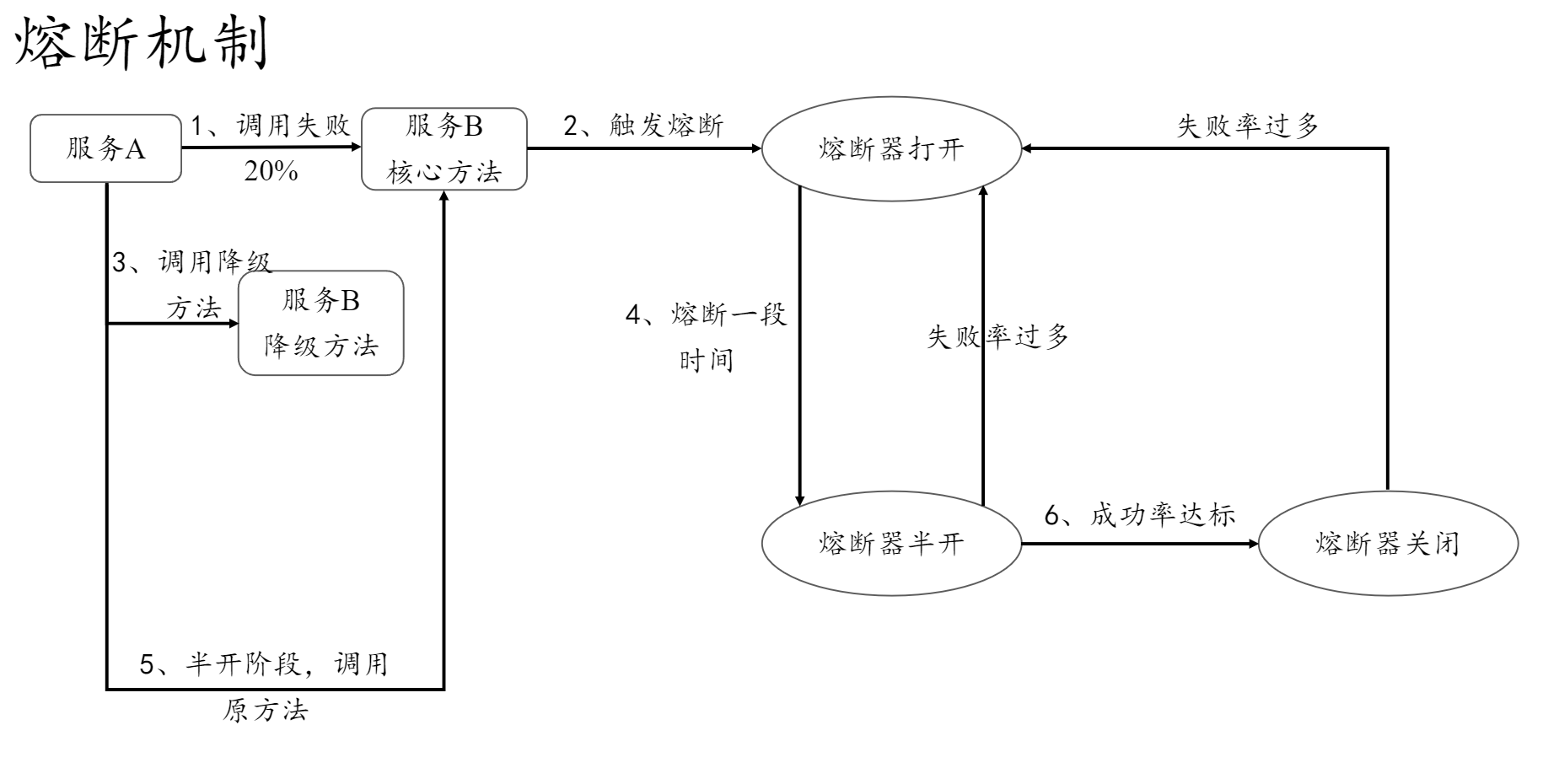
1.2、熔断机制
熔断机制的目的是 避免当下游服务发生异常时,整个系统继续耗费资源重复发起失败请求,从而防止连锁故障。
工作机制:
- 监控服务健康状态:系统会实时监控服务的调用情况,例如请求成功率、响应时间等,判断服务的健康状况。
- 进入熔断状态:当某个服务的错误率达到设定阈值(如响应时间过长或出错率过高)时,系统会激活熔断器,暂时停止对该服务的调用,避免消耗不必要的资源和让错误进一步扩散。
- 快速失败:在熔断状态下,系统不会再等待超时,而是直接返回失败响应,减少系统资源占用,并避免因长时间等待导致用户体验的恶化。(也可以降级处理)
- 熔断恢复机制:熔断并非永久状态。在一段时间后,熔断器会进入半开状态,允许少量请求测试服务的健康情况。如果恢复正常,熔断器将关闭,恢复正常服务调用;如果仍有问题,则继续保持熔断。
1.3、降级策略
降级的目的是在某个服务的响应能力下降、或该服务不可用时,提供简化版的功能或返回默认值作为 兜底,保持系统的部分功能可用,确保用户体验的连续性,避免系统频繁报错。
降级可以是手动配置,也可以根据系统负载自动触发。系统可能由于多种原因(如高负载、外部依赖不可用等)触发降级,返回简化的响应或默认值。
降级机制的好处:
- 优雅地处理故障:在降级状态下,系统不会直接返回错误信息,而是提供一个替代方案。例如,某个数据查询服务不可用时,系统可以返回缓存数据,确保用户看到的是有效信息,而非错误页面。
- 降低服务压力:降级有助于减轻系统对非核心服务的依赖,确保核心功能的稳定运行。例如,当推荐系统或广告服务出现故障时,降级可以减少对这些服务的调用,保护系统的整体稳定性。
1.4、熔断和降级的区别
具体来说:
- 熔断是当服务健康状况恶化时,通过 切断调用 避免系统资源浪费或服务间故障扩散。
- 降级是在系统压力过大或某个服务不可用时,通过提供简化的替代方案 ,保持系统的可用性和用户体验。
2、实战
2.1、对单个接口整体限流
目的:控制对耗时较长的、经常访问的接口的请求频率,防止过多请求导致系过载
限流规则:
- 策略:整个接口每秒钟不超过 10 次请求
- 阻塞操作:提示"系统压力过大,请耐心等待"
熔断规则:
- 熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
- 熔断操作:直接返回本地数据(缓存或空数据)
2.2、对单个 IP 访问单个接口限流
限流规则:
- 策略:每个 IP 地址每分钟允许查看题目列表的次数不能超过 60 次。
- 阻塞操作:提示"访问过于频繁,请稍后再试"
熔断规则:
- 熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
- 熔断操作:直接返回本地数据(缓存或空数据)
3、Sentinel 介绍
Sentinel是阿里巴巴开源的限流、熔断、降级组件,旨在为分布式系统提供可靠的保护机制。它设计用于解决高并发流量下的稳定性问题,并且支持与 Dubbo、Spring Cloud 等多种框架集成。
详细内容可查看 -> 官方文档
它的功能:
- 限流:支持基于 QPS、并发数量等条件的限流,支持滑动窗口、预热、漏桶等算法。
- 熔断降级:支持失败率、慢调用比例等指标触发熔断,并提供自动恢复机制。
- 热点参数限流:可以基于特定的参数进行限流,如限制特定用户 ID 的请求频率。
- 系统负载保护:可以根据系统的实际负载(如 CPU、内存)动态调整流量。
- 丰富的规则配置:通过配置中心或控制台动态调整限流和熔断规则。
优势:功能丰富、提供控制台、更新较频繁、社区活跃、文档清晰,能够快速入门上手。
3.1、使用方式
使用 Sentinel 来进行资源保护,主要分为几个步骤:
- 定义资源
- 定义规则
- 检验规则是否生效
3.2、架构设计
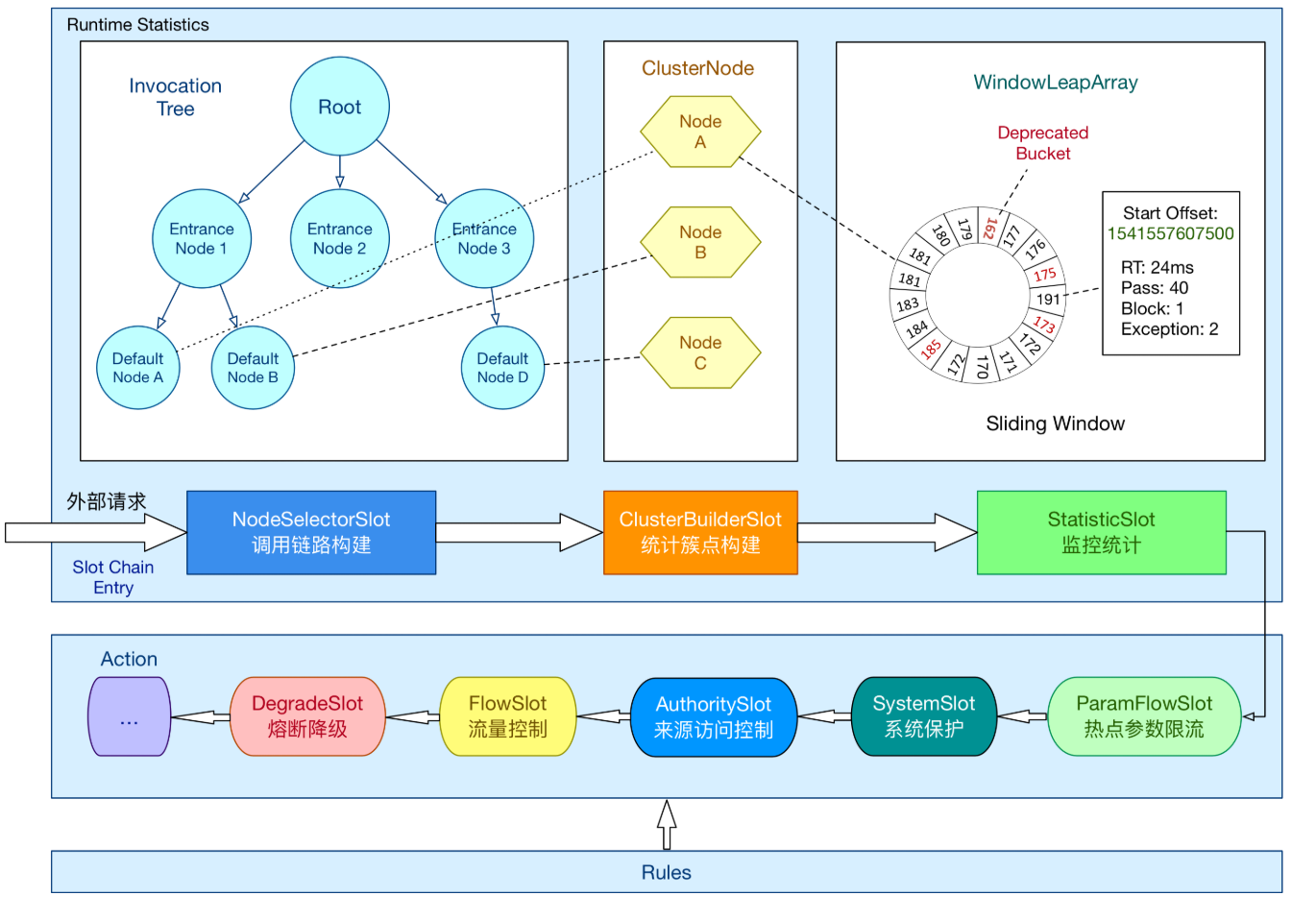
在 Sentinel 里面,所有的资源都对应一个资源名称以及一个 Entry。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 API 显式创建;每一个 Entry 创建的时候,同时也会创建一系列功能插槽(slot chain)。这些插槽有不同的职责,例如:
3.2.1、NodeSelectorSlot
NodeSelectorSlot 的本质作用:Sentinel 是通过一条一条资源"链路"来判断是否限流/降级的,而 它 就是用来维护这些资源链路的结构树。
具体干这几件事:
1、把资源"挂"到调用上下文树上
比如你访问 nodeA,它就会:
- 看你当前上下文是哪个入口(entrance1)
- 在 entrance1 节点下面查:有没有挂过 nodeA
- 没有就新建一个 DefaultNode(nodeA),挂上去!
2、同一个资源,但不同入口,树结构是独立的!
java
ContextUtil.enter("entrance1", "appA");
SphU.entry("nodeA"); // 第一次
ContextUtil.exit();
ContextUtil.enter("entrance2", "appA");
SphU.entry("nodeA"); // 第二次
ContextUtil.exit();这相当于你从 两个不同入口玩了同一个关卡,Sentinel 会建立两条路径记录:
java
machine-root
├── EntranceNode(entrance1)
│ └── DefaultNode(nodeA)
└── EntranceNode(entrance2)
└── DefaultNode(nodeA)为什么这么设计?
因为在真实业务中:
- 你可能有多个入口(比如首页、搜索页都能访问同一个资源)
- 你想控制每条链路的 QPS(比如"从搜索页过来的 QPS 限制更严格")
所以 Sentinel 就必须要分得清:
"你是从哪儿来的,然后才访问的这个资源"
3.2.2、ClusterBuilderSlot
ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
ClusterBuilderSlot 的作用
1、调用方级别限流!
- 比如限制 "微信小程序" 每秒最多访问 100 次,其他 origin 不受影响。
2、监控更细粒度!
- 哪个来源调用最多?
- 哪个来源的调用最慢、最容易出错?
比如:是不是 Web 前端的调用出异常多,是不是他们传参老有问题?
配合热点参数限流、来源限流做更精细的控制。
3.3.3、StatisticSlot
StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
- clusterNode:资源唯一标识的 ClusterNode 的 runtime 统计
- origin:根据来自不同调用者的统计信息
- defaultnode: 根据上下文条目名称和资源 ID 的 runtime 统计入口的统计
Sentinel 底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。
3.3.4、LeapArray底层原理
LeapArray 底层是一个固定长度的环形数组,每个元素是一个带有时间戳的窗口格子 WindowWrap。
它支持在高并发场景下以时间为索引安全读写,保证统计的是"最近一段时间"的窗口数据,用于 Sentinel 的实时监控与限流、降级判断。
结构总览:
java
public class LeapArray<T> {
protected final int sampleCount; // 窗口格子数,比如10
protected final int intervalInMs; // 窗口总时长,比如1000ms(1s)
private final WindowWrap<T>[] array; // 固定长度数组,环形复用
}每个窗口格子是这样一个类:
java
public class WindowWrap<T> {
private final long windowStart; // 窗口开始时间
private final long windowLength; // 每个格子的长度(interval / sampleCount)
private final T value; // 存放统计信息的对象,比如 MetricBucket
}它是怎么定位时间属于哪个窗口的?
比如:
总窗口时间是 1000ms,格子数是 10
每个格子负责 100ms
现在时间是 10:00:01.450(即 1450ms)
① 算出这个时间属于哪个格子:
java
int idx = (timestamp / windowLength) % sampleCount;
// 1450 / 100 = 14 -> 14 % 10 = 4,落在索引为4的格子② 再判断这个格子的起始时间是不是还有效:
java
//当前时间戳 ➜ 除以窗口长度 ➜ 计算出当前时间该落在哪个格子 ➜ 比较该格子的起始时间
//➜ 如果不同 ➜ 就滑窗、清理、重建!
window.windowStart == timestamp - (timestamp % windowLength)如果有效:直接返回当前格子
如果无效(已经过期了):用 CAS 创建一个新的 WindowWrap(复用原来的槽位)
3.3.4.1、它是怎么滑动更新的?
核心点:每次请求到来时,才会"懒更新"窗口格子
流程如下:
1、当前时间戳算出对应窗口索引(如上)
2、取出格子对象,检查是否是当前时间的窗口
- 是:直接用
- 否:CAS 替换为新窗口 + 清空旧统计值(滑动来了)
3、更新格子里的统计数据
它并不需要定时器或后台线程维护窗口,而是靠访问触发滑动,非常节省资源。
3.3.4.2、并发怎么处理?
多线程访问时可能并发写同一个窗口:
- 用的是 AtomicReferenceArray + Compare-And-Swap (CAS)
- 每个格子内部统计信息用 LongAdder 等并发友好结构
3.3.4.3、总结:
LeapArray 是一个时间轮+懒更新+CAS构建的滑动窗口数组,专为高并发下限流降级而生。
3.3.5、FlowSlot
这个 slot 主要根据预设的资源的统计信息,按照固定的次序,依次生效。如果一个资源对应两条或者多条流控规则,则会根据如下次序依次检验,直到全部通过或者有一个规则生效为止:
- 指定应用生效的规则,即针对调用方限流的;
- 调用方为 other 的规则;
- 调用方为 default 的规则。
3.3.6、DegradeSlot
这个 slot 主要针对资源的平均响应时间(RT)以及异常比率,来决定资源是否在接下来的时间被自动熔断掉。