一、下载
https://digi.bib.uni-mannheim.de/tesseract/
下载,尽量选择时间靠前的(识别更好些)。符合你的运行机(我的是windows64)
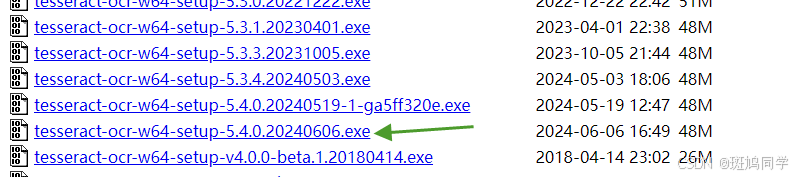
持续点击下一步安装,安装你认可的路径即可,没必要配置环境变量(后续在代码里指定即可)。
二、下载语言包
https://github.com/tesseract-ocr/tessdata/blob/main/chi_sim.traineddata
(这是中文的。有了它,后续的识别会更精准)
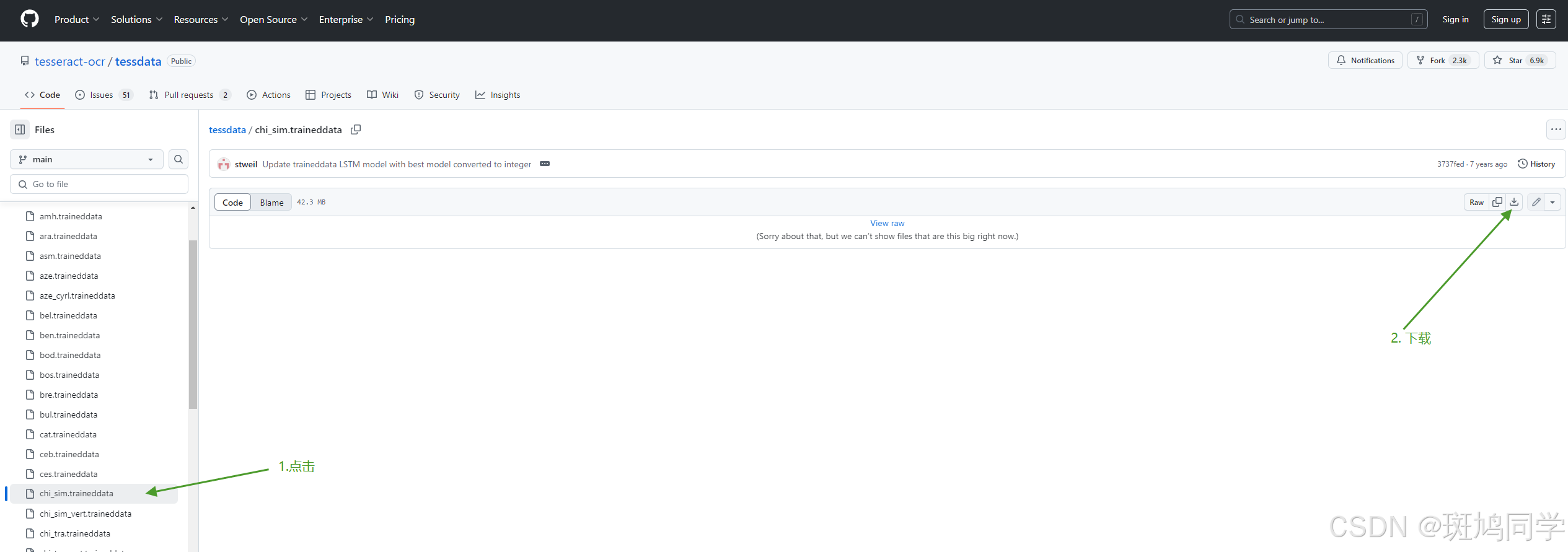
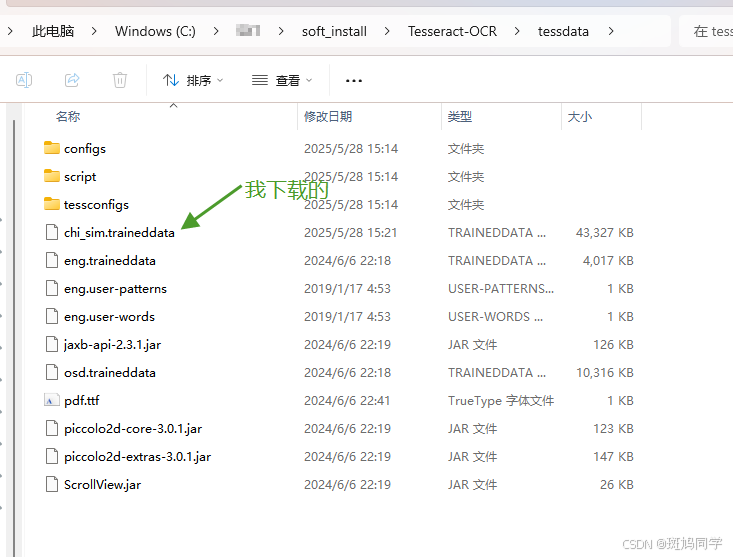
下载到的语言包放到安装目录的 Tesseract-OCR\tessdata 目录下
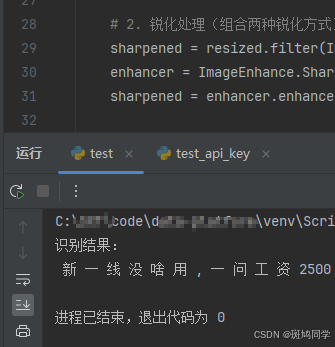
三、代码实现和图片优化
注意:图片的优化很重要,这会极大的提高识别。
【图片越大、像素越清晰,识别的准确度越高。
如果是小图片,需要额外做放大、锐化、对比度等处理。 本文章不做这方面的优化。
各位可以截大图和小图对比一下结果就知道了。】
下面以python实现为例:
程序:替换你的安装路径和图片地址,运行即可测试。
python
import pytesseract
from PIL import Image
# 设置Tesseract路径(根据实际安装路径修改)
pytesseract.pytesseract.tesseract_cmd = r'C:\soft_install\Tesseract-OCR\tesseract.exe'
def ocr_scan(image_path):
"""
对指定图片文件进行OCR识别
:param image_path: 图片文件路径(支持PNG/JPG等格式)
"""
try:
# 加载图片文件
image = Image.open(image_path)
# 识别文字(中英文混合)
text = pytesseract.image_to_string(image, lang='chi_sim+eng')
print("识别结果:\n", text.strip())
except FileNotFoundError:
print(f"错误:文件 '{image_path}' 不存在")
except Exception as e:
print(f"发生错误:{str(e)}")
if __name__ == "__main__":
# 直接指定图片路径(示例路径)
image_path = "processed_latest.png" # 修改为你的图片路径
ocr_scan(image_path)图片实例如下:

(图1 未经过放大和二值化阈值等处理。 会存在识别失真)
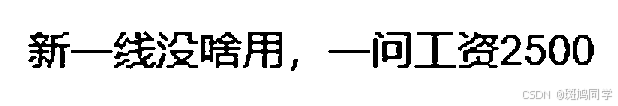
(图2 经过放大和二值化阈值处理。 上面的程序可以正确识别 )