一、背景与起源
- 上下文建模的局限:在 BERT 之前,诸如 Word2Vec、GloVe 等词向量方法只能给出静态的词表示;而基于单向或浅层双向 LSTM/Transformer 的语言模型(如 OpenAI GPT)只能捕捉文本从左到右(或右到左)的上下文信息。
- 论文贡献:2018 年 Google 的 Devlin 等人提出 BERT,通过真正的"深度双向"Transformer 编码器,在大规模语料上同时从左右两个方向学习上下文,显著提升了各类 NLP 任务的基线性能。
二、核心架构
-
Transformer Encoder
- BERT 完全由多层 Transformer Encoder 组成,每层包括多头自注意力(Multi-Head Self-Attention)和前馈网络(Feed-Forward Network),并配以层归一化与残差连接。
- 常见版本有
- BERT-Base:12 层 Encoder、768 维隐藏层、12 个注意力头,约 1.1 亿参数;
- BERT-Large:24 层 Encoder、1024 维隐藏层、16 个注意力头,约 3.4 亿参数。
-
Embedding 层
- Token Embeddings:子词(WordPiece)级别的初始向量;
- Segment Embeddings:用于区分句子 A/B,在下游需要句间关系时有效;
- Position Embeddings:表示序列中各 token 的位置;
- 三者逐元素相加后,送入第一层 Encoder。
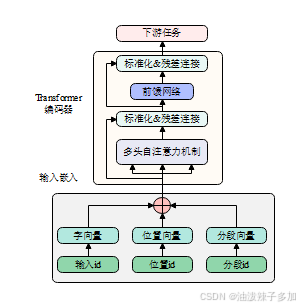
三、输入表示
给定输入文本对 (Sentence A, Sentence B),BERT 构造如下序列:
[CLS] tokens_A [SEP] tokens_B [SEP]- CLS:分类标记,其最终层输出向量用于下游分类任务;
- SEP:分隔符标记,标识句子边界;
- Segment ID:句子 A 中所有 token 的 segment embedding 为 0,句子 B 中为 1;
- Attention Mask:指示哪些位置是真实 token(1)或填充(0)。
四、预训练任务
BERT 的成功很大程度上来自于两个预训练目标的设计
- Masked Language Model (MLM)
- 思路 :随机遮蔽输入中 15% 的 token (
[MASK]),让模型预测这些被遮蔽位置原本的词。 - 细节 :
- 遮蔽策略:80% 用
[MASK]替换,10% 保留原词,10% 随机替换为词表中其他词; - 这样既避免模型过度依赖
[MASK],又能学习对真实 token 的预测能力。
- 遮蔽策略:80% 用
- 思路 :随机遮蔽输入中 15% 的 token (
- Next Sentence Prediction (NSP)
- 思路:给定句子对,50% 概率为原序列中相邻的两句话("IsNext"),50% 概率随机抽取另一段文字("NotNext");模型判别它们是否具有上下文连续关系。
- 作用:为下游的问答、自然语言推理等任务提供句间关系判断能力。
五、模型微调(Fine-Tuning)
-
通用流程
- 在预训练的 BERT 模型上,追加一个或多个任务相关的输出层(如分类头、回归头、序列标注头等);
- 以较小的学习率(如 2e-5--5e-5)在下游任务标注数据上继续训练整个网络;
- 最终得到一个在该任务上性能优异的专用模型。
-
示例任务
- 文本分类 :取
[CLS]对应的隐藏向量接一个全连接 + Softmax; - 命名实体识别:对每个 token 的输出向量接一个分类层,识别实体标签;
- 问答阅读理解:为每个位置预测开始/结束概率,找到答案所在 span。
- 文本分类 :取
六、BERT 的优势与局限
优势
- 深度双向上下文:相比单向或浅层双向模型,在理解句子含义时更全面;
- 统一框架:一个预训练模型可微调到几十种不同任务,极大简化了模型部署;
- 强大基线:在 GLUE、SQuAD、MNLI 等多项公开基准上创纪录。
局限
- 计算与内存开销大:特别是 BERT-Large,在推理时对 GPU/TPU 资源要求高;
- 预训练目标简单:如 NSP 的效果有限,后续研究多选择取消或替换
- 固定长度限制:标准 BERT 的最大输入长度为 512,难以直接处理超长文本。
七、应用与生态
-
下游生态
自 BERT 发布以来,社区围绕预训练与微调构建了丰富工具与框架,例如 Hugging Face Transformers、TensorFlow Hub 等,用户可以方便地加载各类 BERT 模型及其变种。
-
行业应用
包括智能客服中的意图识别与槽位填充、搜索引擎中的语义匹配、法律/医药领域的文档分类与信息抽取等。