校招面试经常会问大家有没有过调优的经验,相信大家的回答基本都是往数据倾斜和小文件问题这两方面回答,对于数据倾斜相信大部分同学对热key打散或null值引发的倾斜已经非常熟悉,但这些内容面试官也是听腻了,希望大家在面试时候讲一些高大尚的案例,在描述的时候一定要有背景,有解决方案,最后结果,毕竟数据倾斜不会无故产生,一定是有业务背景的,这里给大家分享一种数据倾斜优化案例。

1.Uid和oaid之间的转化
在用增的拉新拉回业务中,经常会用到oaid来识别具体的设备是不是公司用户,所以我们需要将uid→oaid,需求目的:找到当日拉新的uid对应的oaid映射关系
代码如下:
-
1.从id mapping表中找出uid→oaid的映射关系;
-
2.根据最后一次活跃时间对uid→oaid映射关系去重;
-
3.将算法提供的uid人群圈选出对应的oaid。
原来的sql
select
t1.user_id,
oaid_md5
from
(
select
L.uid user_id,
md5(L.oaid) oaid_md5
from
(
select
distinct uid,
oaid
from
(
select
uid,
oaid,
row_number() over (
partition by oaid
order by
cast(last_active_timestamp as bigint) desc
) as rn
from
idmapping as G
where
G.p_date = '20250324'
and G.left_type = 'USER_ID'
and G.right_type = 'OAID'
) tt
where
tt.rn = 1
) as L
left join (
select
id
from
zuobishebei -- 作弊设备
where
p_date = '{{ds_nodash}}'
and supplier = 'cheat'
) as P on (md5(L.oaid) = P.id)
where
P.id is null
) t2
join (
SELECT
user_id
FROM
list_ground_truth
WHERE
p_date = '20250324'
) t1 on t1.user_id = t2.user_id粗略一看,符合正常计算流程和顺序,但这段sql出现了明显的数据倾斜。
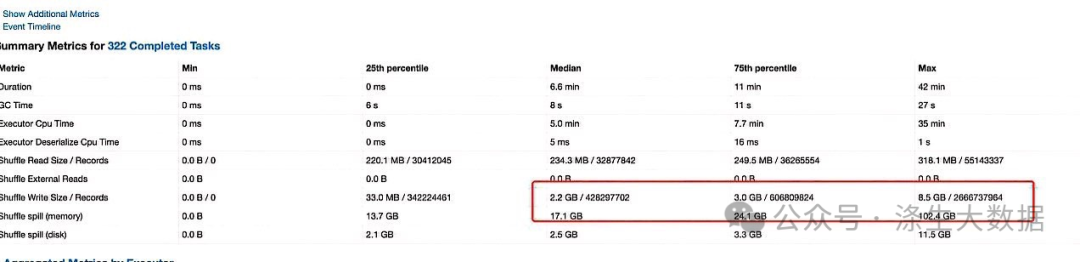
经过排查代码中有两块可能引起倾斜,一个是join,一个row number,先查询一下uid→oaid映射情况,发现部分的uid映射过10亿多的oaid,导致在去重的时候发生了数据倾斜。
解决方案
-
1.使用过滤条件和分组操作减少数据量;
-
2.通过调整连接顺序和提前应用过滤条件,减少了中间数据量;
-
3.如果倾斜仍然存在,考虑对倾斜字段进行分区或使用 broadcast join 来进一步优化。
优化后:
SELECT
user_id,
md5(paid) AS oaid
FROM
(
SELECT
user_id,
paid,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY
CAST(last_active_timestamp AS BIGINT) DESC
) AS rn
FROM
(
SELECT
t1.user_id,
t2.paid,
t2.last_active_timestamp
FROM
(
SELECT
user_id
FROM
list_ground_truth
WHERE
p_date = '20250324'
) t1
JOIN (
SELECT
uid,
oaid,
G.last_active_timestamp
FROM
idmappingG
WHERE
G.p_date = '20250324'
AND G.left_type = 'USER_ID'
AND G.right_type = ' OAID '
GROUP BY
G.left_value,
G.right_value,
G.last_active_timestamp
) t2 ON t1.user_id = t2.uid
) t3
) t1
WHERE
rn = 1原始脚本和优化后的脚本在逻辑上保持一致,但重点在于先jion较小的表(idmapping和 list_ground_truth),在进行row number,这样可以在join时先走map join同时减少row number执行的数据量。