一、分类算法是什么?
简单说 :教会计算机根据已有经验做选择题。
生活例子:
-
判断水果是苹果还是橙子(根据颜色、形状、重量)
-
预测邮件是正常还是垃圾邮件
-
诊断患者是否患有某种疾病
二、5大经典分类算法(附比喻)
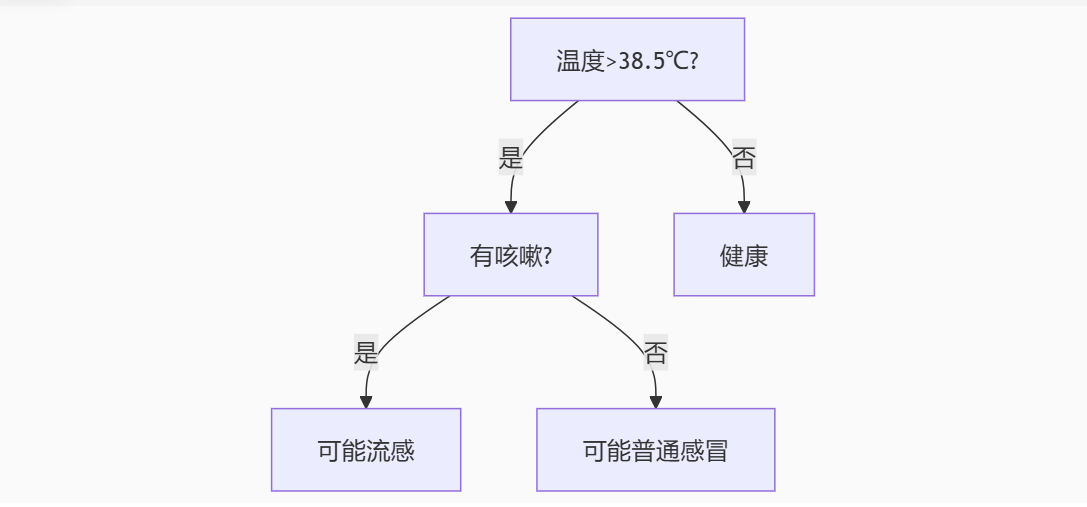
1. 决策树 ------ 最像人类的决策方式
工作原理 :像玩「20个问题」猜谜游戏,通过一系列问题逐步缩小范围
可视化例子:
Python代码:
python
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=3)
tree.fit(X_train, y_train)
# 可视化决策树
from sklearn.tree import plot_tree
plot_tree(tree, feature_names=feature_names)特点 :
✅ 可解释性强(能画出决策路径)
⚠️ 容易过拟合(需要设置max_depth等参数)
2. K近邻(KNN) ------ 近朱者赤
核心思想 :看最近的K个邻居属于哪类
生活比喻:搬新家时,参考周围5户人家的装修风格决定自家风格
距离计算(以2个特征为例):
距离=(年龄差)2+(收入差)2距离=(年龄差)2+(收入差)2
代码实现:
python
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)特点 :
✅ 无需训练过程(惰性学习)
⚠️ 计算成本高(需存储所有数据)
3. 逻辑回归 ------ 概率预测专家
虽然叫回归,实际是分类算法
核心 :用S型函数将线性结果转换为概率
Sigmoid函数:
P=11+e−(wx+b)P=1+e−(wx+b)1
代码实现:
python
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)特点 :
✅ 输出可解释(直接得到概率)
⚠️ 只能处理线性可分数据
4. 支持向量机(SVM) ------ 边界最大化专家
核心思想 :找到最宽的"隔离带"分开两类数据
生活比喻:在两群打架的小朋友之间画最宽的安全线
核技巧:通过变换处理非线性数据
python
from sklearn.svm import SVC
svm = SVC(kernel='rbf', C=1.0) # 高斯核
svm.fit(X_train, y_train)特点 :
✅ 小样本效果优秀
⚠️ 对缺失数据敏感
5. 随机森林 ------ 集体智慧的胜利
工作原理 :多个决策树投票决定结果
比喻:医生会诊,综合多位专家意见
代码实现:
python
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100)
forest.fit(X_train, y_train)特点 :
✅ 抗过拟合能力强
⚠️ 可解释性降低
三、算法选择指南(新手友好版)
| 你的数据特点 | 推荐算法 | 原因 |
|---|---|---|
| 需要解释为什么这样分类 | 决策树 | 可可视化决策路径 |
| 数据有明显空间分布规律 | KNN | 近邻即相似 |
| 样本量小(<1万) | SVM | 高维表现好 |
| 需要概率输出 | 逻辑回归 | 直接输出概率 |
| 追求最高准确率 | 随机森林 | 集成方法效果稳定 |
四、模型评估四件套
-
混淆矩阵:看清所有预测对错
pythonfrom sklearn.metrics import confusion_matrix confusion_matrix(y_true, y_pred)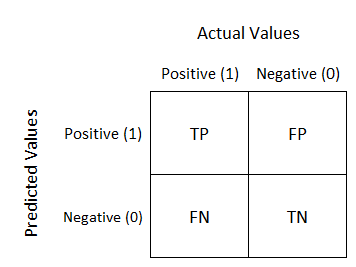
-
常用指标:
-
准确率(Accuracy):整体正确率
-
精确率(Precision):预测为正的准确率
-
召回率(Recall):实际为正的检出率
-
F1分数:精确率和召回率的调和平均
-
五、避坑指南
-
数据陷阱:
-
类别不平衡时不要只看准确率(比如99%正常邮件,1%垃圾邮件)
-
解决方法:用F1-score或AUC-ROC
-
-
特征陷阱:
-
KNN/SVM必须做特征缩放(如StandardScaler)
-
决策树不需要缩放
-
-
代码陷阱:
python# 错误!应该在训练集上fit后transform测试集 X_scaled = StandardScaler().fit_transform(X_all) # ❌ # 正确做法 scaler = StandardScaler().fit(X_train) X_test_scaled = scaler.transform(X_test) # ✅
六、实战建议
-
初学者项目:
-
鸢尾花分类(内置数据集)
-
Titanic生存预测(Kaggle入门赛)
-