一文速通 Python 并行计算:11 Python 多进程编程-进程之间的数据安全传输-基于队列和管道
摘要:
Python 多进程中,Queue 和 Pipe 提供进程间安全通信。Queue 依赖锁和缓冲区,保障数据原子性和有序性;Pipe 实现点对点单/双向数据流。二者内置序列化,简化交换流程,确保一致性与安全性高效。

关于我们更多介绍可以查看云文档: Freak 嵌入式工作室云文档,或者访问我们的 wiki:****https://github.com/leezisheng/Doc/wik
原文链接:
往期推荐:
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与"file-like object"
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
全网最适合入门的面向对象编程教程:56 Python字符串与序列化-正则表达式和re模块应用
全网最适合入门的面向对象编程教程:57 Python字符串与序列化-序列化与反序列化
全网最适合入门的面向对象编程教程:58 Python字符串与序列化-序列化Web对象的定义与实现
全网最适合入门的面向对象编程教程:59 Python并行与并发-并行与并发和线程与进程
一文速通Python并行计算:01 Python多线程编程-基本概念、切换流程、GIL锁机制和生产者与消费者模型
一文速通Python并行计算:02 Python多线程编程-threading模块、线程的创建和查询与守护线程
一文速通Python并行计算:03 Python多线程编程-多线程同步(上)---基于互斥锁、递归锁和信号量
一文速通Python并行计算:04 Python多线程编程-多线程同步(下)---基于条件变量、事件和屏障
一文速通Python并行计算:05 Python多线程编程-线程的定时运行
一文速通Python并行计算:06 Python多线程编程-基于队列进行通信
一文速通Python并行计算:07 Python多线程编程-线程池的使用和多线程的性能评估
一文速通Python并行计算:08 Python多进程编程-进程的创建命名、获取ID、守护进程的创建和终止进程
一文速通Python并行计算:09 Python多进程编程-进程之间的数据同步-基于互斥锁、递归锁、信号量、条件变量、事件和屏障
一文速通Python并行计算:10 Python多进程编程-进程之间的数据共享-基于共享内存和数据管理器
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
Avnet ZUBoard 1CG开发板---深度学习新选择
万字长文手把手教你实现MicroPython/Python发布第三方库
工科比赛"无脑"操作指南:知识学习硬件选购→代码调试→报告撰写的保姆级路线图
爆肝整理长文】大学生竞赛速通指南:选题 × 组队 × 路演 48 小时备赛搞定
女大学生摆摊亏损5000元踩点实录:成都哪里人最多、最容易赚到钱?我告诉你!
普通继电器 vs 磁保持继电器 vs MOS管:工作原理与电路设计全解析
告别TP4056!国产SY3501D单芯片搞定充放电+升压,仅需7个元件!附开源PCB文件
文档获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc
该文档是一份关于 并行计算 和 Python 并发编程 的学习指南,内容涵盖了并行计算的基本概念、Python 多线程编程、多进程编程以及协程编程的核心知识点:
正文
进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing 模块支持两种形式:队列(queue)和管道(pipe)。
1.使用队列进行通信
Queue([maxsize]) 返回一个进程共享的队列,是线程安全的,也是进程安全的。任何可序列化的对象(Python 通过 pickable 模块序列化对象)都可以通过它进行交换,(maxsize 是队列中允许最大项数,省略则无大小限制)。
其主要方法包括:
| 方法 | 作用 |
|---|---|
| Put() | 用以插入数据到队列中,put 方法还有两个可选参数:blocked 和 timeout。① 如果 blocked 为 True(默认值),并且 timeout 为正值,该方法会阻塞 timeout 指定的时间,直到该队列有剩余的空间。如果超时,会抛出 Queue.Full 异常。② 如果 blocked 为 False,但该 Queue 已满,会立即抛出 Queue.Full 异常。 |
| get() | 可以从队列读取并且删除一个元素。同样,get 方法有两个可选参数:blocked 和 timeout。① 如果 blocked 为 True(默认值),并且 timeout 为正值,那么在等待时间内没有取到任何元素,会抛出 Queue.Empty 异常。② 如果 blocked 为 False,有两种情况存在,如果 Queue 有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出 Queue.Empty 异常. |
| get_nowait() | 同 q.get(False) |
| put_nowait() | 同 q.put(False) |
| empty() | 调用此方法时 q 为空则返回 True,该结果不可靠,比如在返回 True 的过程中,如果队列中又加入了项目。 |
| full() | 调用此方法时 q 已满则返回 True,该结果不可靠,比如在返回 True 的过程中,如果队列中的项目被取走。 |
| qsize() | 返回队列中目前项目的正确数量,结果也不可靠,理由同 q.empty()和 q.full()一样。 |
| cancel_join_thread() | 不会在进程退出时自动连接后台线程。可以防止 join_thread()方法阻塞 |
| close() | 关闭队列,防止队列中加入更多数据。调用此方法,后台线程将继续写入那些已经入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果 q 被垃圾收集,将调用此方法。关闭队列不会在队列使用者中产生任何类型的数据结束信号或异常。例如,如果某个使用者正在被阻塞在 get()操作上,关闭生产者中的队列不会导致 get()方法返回错误。 |
| join_thread() | 连接队列的后台线程。此方法用于在调用 q.close()方法之后,等待所有队列项被消耗。默认情况下,此方法由不是 q 的原始创建者的所有进程调用。调用 q.cancel_join_thread 方法可以禁止这种行为 |
在下面的例子中, Producer 类生产 item 放到队列中,然后 Consumer 类从队列中移除它们。
python
import multiprocessing
import random
import time
class Producer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item)
print("Process Producer : item %d appended to queue %s" % (item, self.name))
time.sleep(1)
print("The size of queue is %s" % self.queue.qsize())
class Consumer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
while True:
if self.queue.empty():
print("the queue is empty")
break
else:
time.sleep(2)
item = self.queue.get()
print('Process Consumer : item %d popped from by %s \n' % (item, self.name))
time.sleep(1)
if __name__ == '__main__':
queue = multiprocessing.Queue()
process_producer = Producer(queue)
process_consumer = Consumer(queue)
process_producer.start()
process_consumer.start()
process_producer.join()
process_consumer.join()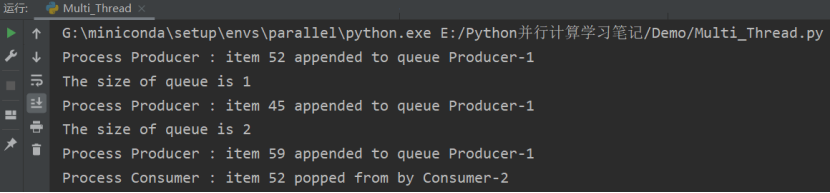
此代码的缺点是在慢生产快消费的情况下主进程会提前结束,其中一种解决方式是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以 break 出死循环。
但是又出现一个新问题,在有多个生产者和多个消费者时,有几个消费者就需要发送几次结束信号,十分麻烦。其实我们的思路无非是发送结束信号而已,有另外一种队列提供了这种机制。
队列还有一个 JoinableQueue 子类,它有以下两个额外的方法:
- **task_done()****: **消费者调用此方法表示之前入队的一个任务已经完成,比如
get()方法从队列取回item之后调用,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常。 - **join()****: **生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用
task_done()方法为止。
示例代码如下:
python
from multiprocessing import Process,JoinableQueue
import time,random,os
def consumer(q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res))
_# 向q.join()发送一次信号,证明一个数据已经被取走了_
q.task_done()
def producer(name,q):
for i in range(10):
time.sleep(random.randint(1,3))
res='%s%s' %(name,i)
q.put(res)
print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res))
q.join()
if __name__ == '__main__':
q=JoinableQueue()
_#生产者们:即厨师们_
p1=Process(target=producer,args=('包子',q))
p2=Process(target=producer,args=('骨头',q))
p3=Process(target=producer,args=('泔水',q))
_#消费者们:即吃货们_
c1=Process(target=consumer,args=(q,))
c2=Process(target=consumer,args=(q,))
c1.daemon=True
c2.daemon=True
_#开始_
p_l=[p1,p2,p3,c1,c2]
for p in p_l:
p.start()
p1.join()
p2.join()
p3.join()
print('主')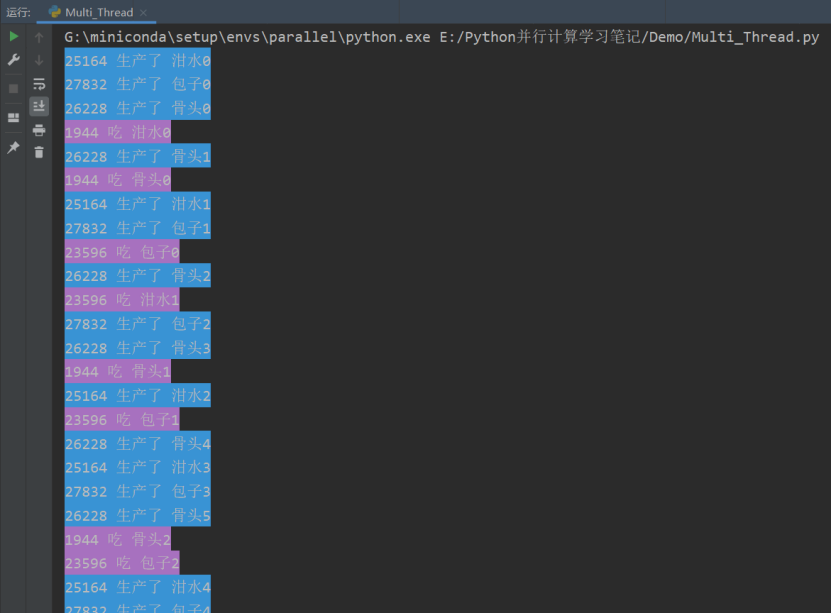
2.使用管道进行通信
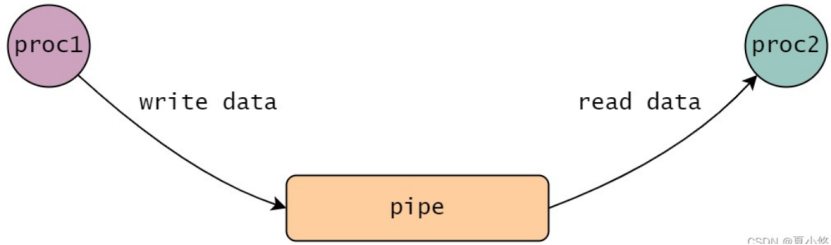
管道是一种最基本的进程间通信机制。把一个进程连接到另一个进程的一个数据流称为一个"管道",通常是用作把一个进程的输出通过管道连接到另一个进程的输入。管道本质上是内核的一块缓存,内核维护了一块缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区内存的操作。
管道通信的特点包括:
-
管道在信息传输上是以流的方式传输,没有消息边界,所有管道一般用于 2 个进程之间通信;
-
管道的读写效率要高于队列;
-
管道是一种文件,可以调用
read、write和close等操作文件的接口来操作管道。另一方面管道又不是一种普通的文件,它属于一种独特的文件系统:pipefs。 -
进程间的
Pipe基于fork机制建立:- 当主进程创建
Pipe的时候,Pipe 的两个Connections连接的的都是主进程。 - 当主进程创建子进程后,
Connections也被拷贝了一份。此时有了 4 个Connections。 - 此后,关闭主进程的一个
Out Connection,关闭一个子进程的一个In Connection。那么就建立好了一个输入在主进程,输出在子进程的管道。
- 当主进程创建

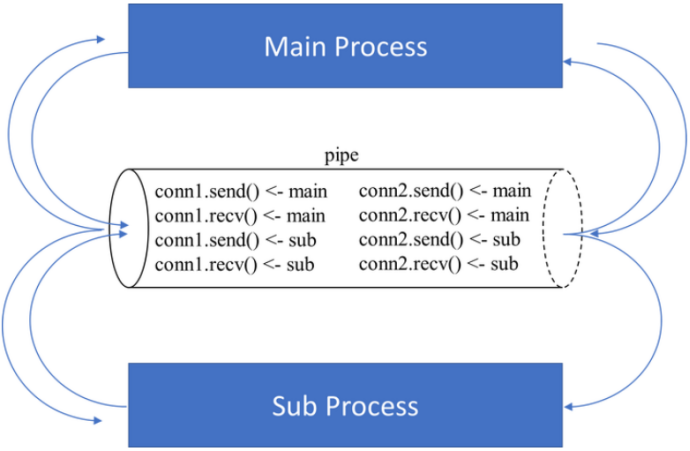
在如下示例程序中,我们在 main 进程中创建一个管道,main 进程对 conn1 和 conn2 都拥有 .send() 和 .recv() 方法的使用权。接下来我们在主进程中创建子进程,同时 conn1, conn2 作为参数传入子进程,此时,main 和 sub_process 对 conn1 和 conn2 都具有使用权限,即 main 和 sub_process 对 conn1 和 conn2 都拥有 .send() 和 .recv() 方法的使用权。
两个进程对两个端口的控制关系如下图所示:
python
from multiprocessing import Process, Pipe
import time
_# 创建两个管道端口对象_
_# Pipe拥有默认参数duplex=True,表示每个端口都为全双工模式,_
_# 即.send()和.recv()方法都可用_
conn1, conn2 = Pipe(duplex=True)
def worker(x, pipe):
conn1, conn2 = pipe
_# 验证sub_process能控制conn2的接收_
msg = conn2.recv()
time.sleep(1)
if msg == "conn1s":
print("conn2 receives msg in sub_p!")
_# 验证sub_process能控制conn2的发送_
conn2.send("conn2s")
_# 验证sub_process能控制conn1的接收_
msg = conn1.recv()
if msg == "conn2s":
print("conn1 receives msg in sub_p!")
_# 验证sub_process能控制conn1的发送_
conn1.send("conn1s")
if __name__ == '__main__':
conn1, conn2 = Pipe(True)
sub_process = Process(target=worker, args=(100, (conn1, conn2)))
sub_process.start()
_# 验证main能控制conn1的发送_
conn1.send("conn1s")
msg = conn1.recv()
time.sleep(1)
if msg == "conn2s":
_# 验证main能控制conn1的接收_
print("conn1 receives msg in main_p!")
_# 验证main能控制conn2的发送_
conn2.send("conn2s")
msg = conn2.recv()
time.sleep(2)
if msg == "conn1s":
_# 验证main能控制conn2的接收_
print("conn2 receives msg in main_p!")最后注意使用管道端口的**.close()**** 方法来切断当前进程对某一端口控制权限时,需要在所有可以控制conn 的进程中都调用conn.close()。**
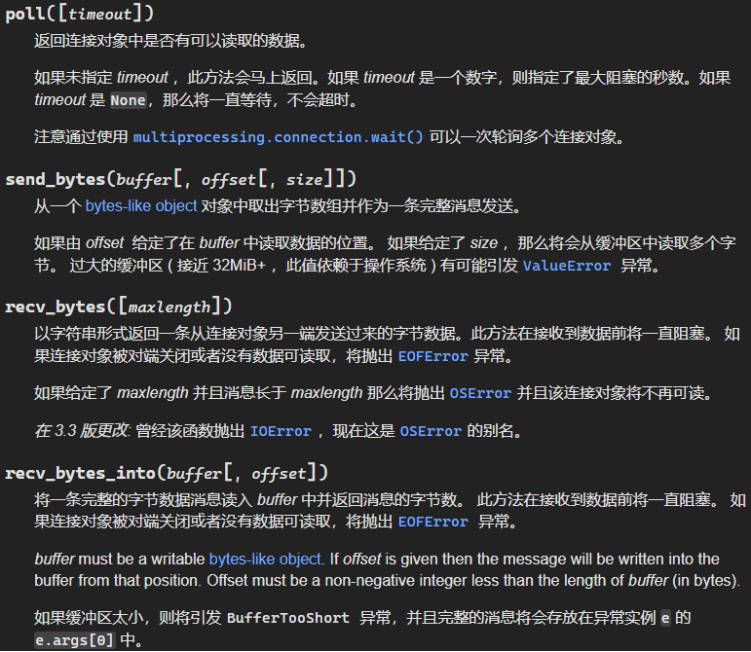
连接对象的其他使用方法包括: