在分布式备份中可以采取两种方式进行备份,一种是采用手动编写backup.yml文件进行备份,另外一种是吧备份过程交给备份工具自动执行。如果需要个性化进行备份,建议采用手动编写备份文件方式进行备份。
以下是针对两种备份方式的实践:
集群状态
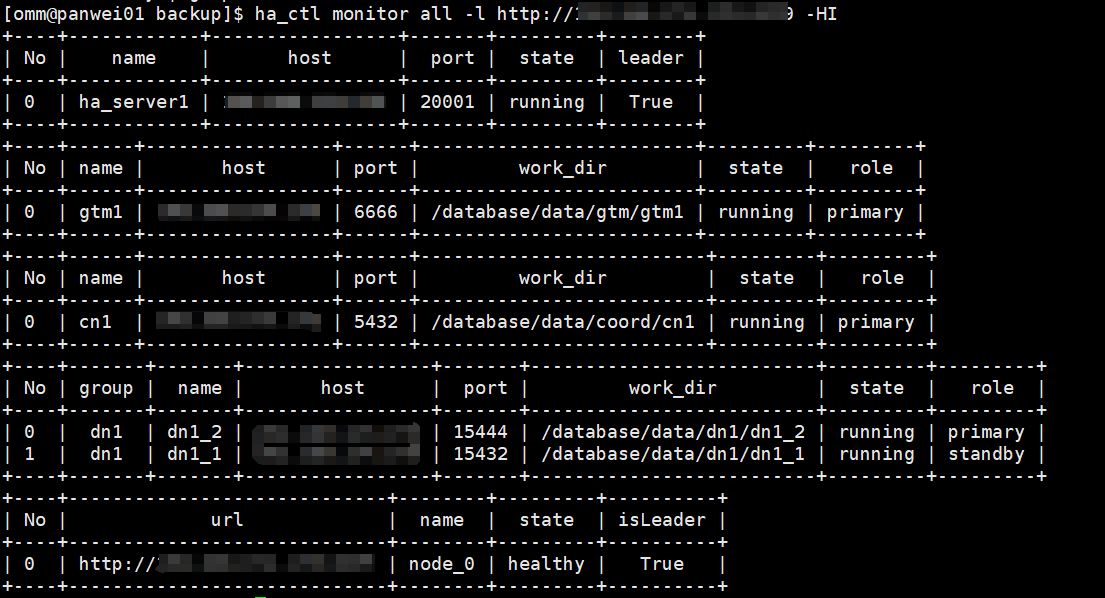
备份方案一
通过手动调整分布式节点archiv_command参数,并编写backup.yml文件进行编写
ha_ctl set gtm gtm1 -p archive_command="'scp %p 10.xx.xx.199:/backup/gtm_wal/%f'" -c panwei -l http://10.xx.xx.199:2379
ha_ctl set datanode dn1_1 -p archive_command="'scp %p 10.xx.xx.199:/backup/dn1_wal/%f'" -c panwei -l http://10.xx.xx.199:2379
ha_ctl set datanode dn1_2 -p archive_command="'scp %p 10.xx.xx.199:/backup/dn1_wal/%f'" -c panwei -l http://10.xx.xx.199:2379
## CN节点可以不做归档设置,并且不需要进行备份
## 同时建议同一分片的不同副本,如:dn1_1、dn1_2、dn1_3等副本设置归档路径为同一主机同一路径下,即使数据库发生主备切换,仍然方便收集归档日志文件。
vi /software/backup.yml
gtm:
backup_host: 10.xx.xx.199
backup_dir: /software/gtm
tbs_dir: /software/gtm_tbs
datanode:
- dn1:
backup_host: 10.xx.xx.199
backup_dir: /software/dn1
tbs_dir: /software/dn1_tbs通过备份命令
## 进行全量备份
ha_ctl backup all -p /software -c panwei -U test -W 'xxxxxx' -l http://10.xx.xx.199:2379
## 进行增量备份
ha_ctl backup all -a '-b PTRACK' -p /software -c panwei -U test -W 'xxxxxx' -l http://10.xx.xx.199:2379
## 查看备份集
ha_ctl backup show -p /software -l http://10.xx.xx.199:2379
## 校验备份集
ha_ctl backup validate -p /software -l http://10.xx.xx.199:2379
备份方案二
通过填写备份文件模板进行备份。
vi /software/backup_new.yml
backup_host: 192.168.174.170 #or local
backup_dir: /software备份命令
## 进行全量备份
ha_ctl backup all -p /software -c panwei -U test -W 'xxxxxx' -l http://10.xx.xx.199:2379
同时在通过填写备份文件模板自动备份时,我们可以发现,备份工具对我们数据库参数进行自动设置,对比备份前后的gtm以及dn节点的archive_command参数值,备份工具自动进行调整为备份路径,从而设置归档路径。
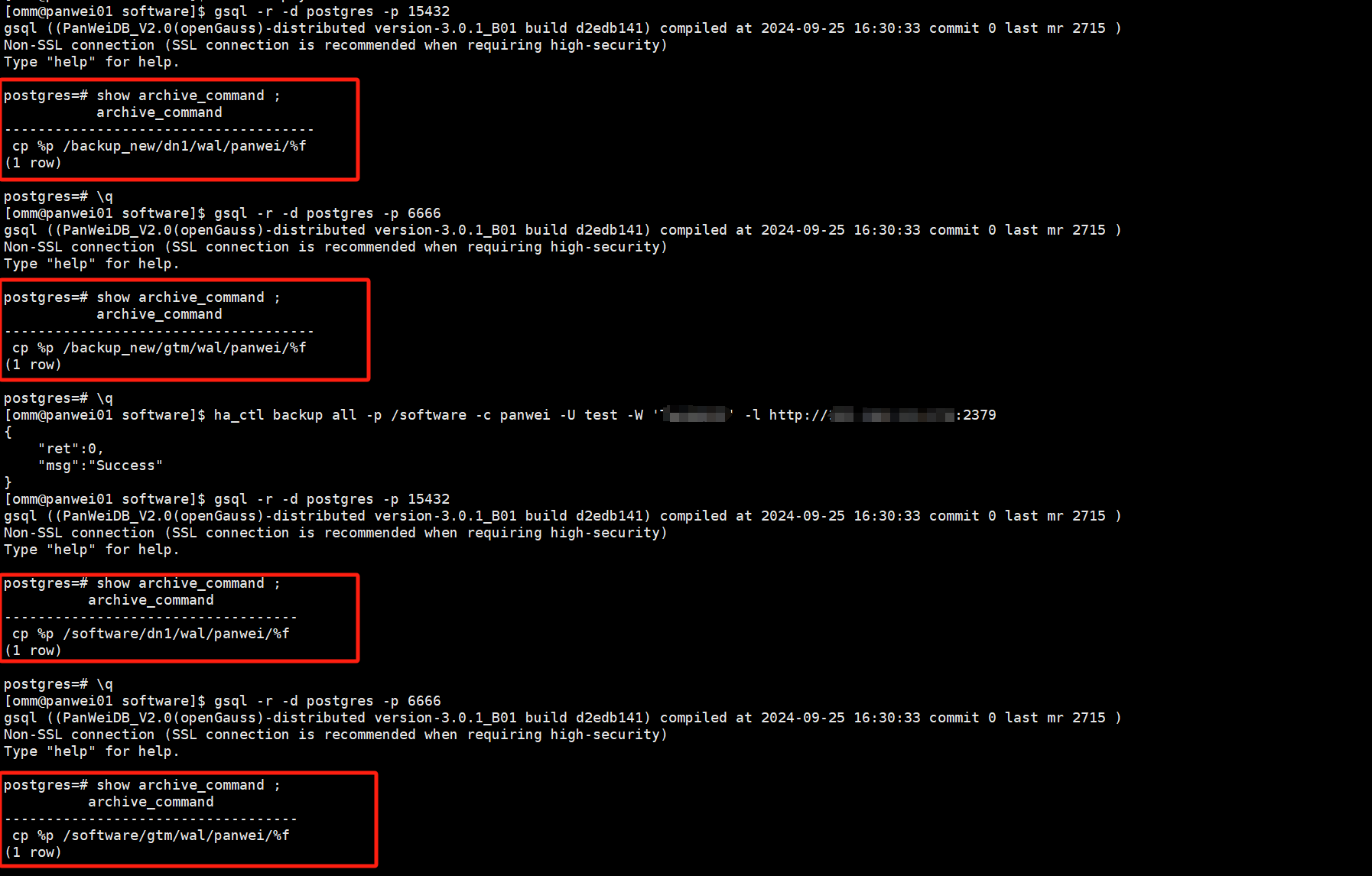
## 进行增量备份
ha_ctl backup all -a '-b PTRACK' -p /software -c panwei -U test -W 'xxxxxx' -l http://10.xx.xx.199:2379
## 查看备份集
ha_ctl backup show -p /software -l http://10.xx.xx.199:2379
## 校验备份集
ha_ctl backup validate -p /backup_new -l http://10.xx.xx.199:2379