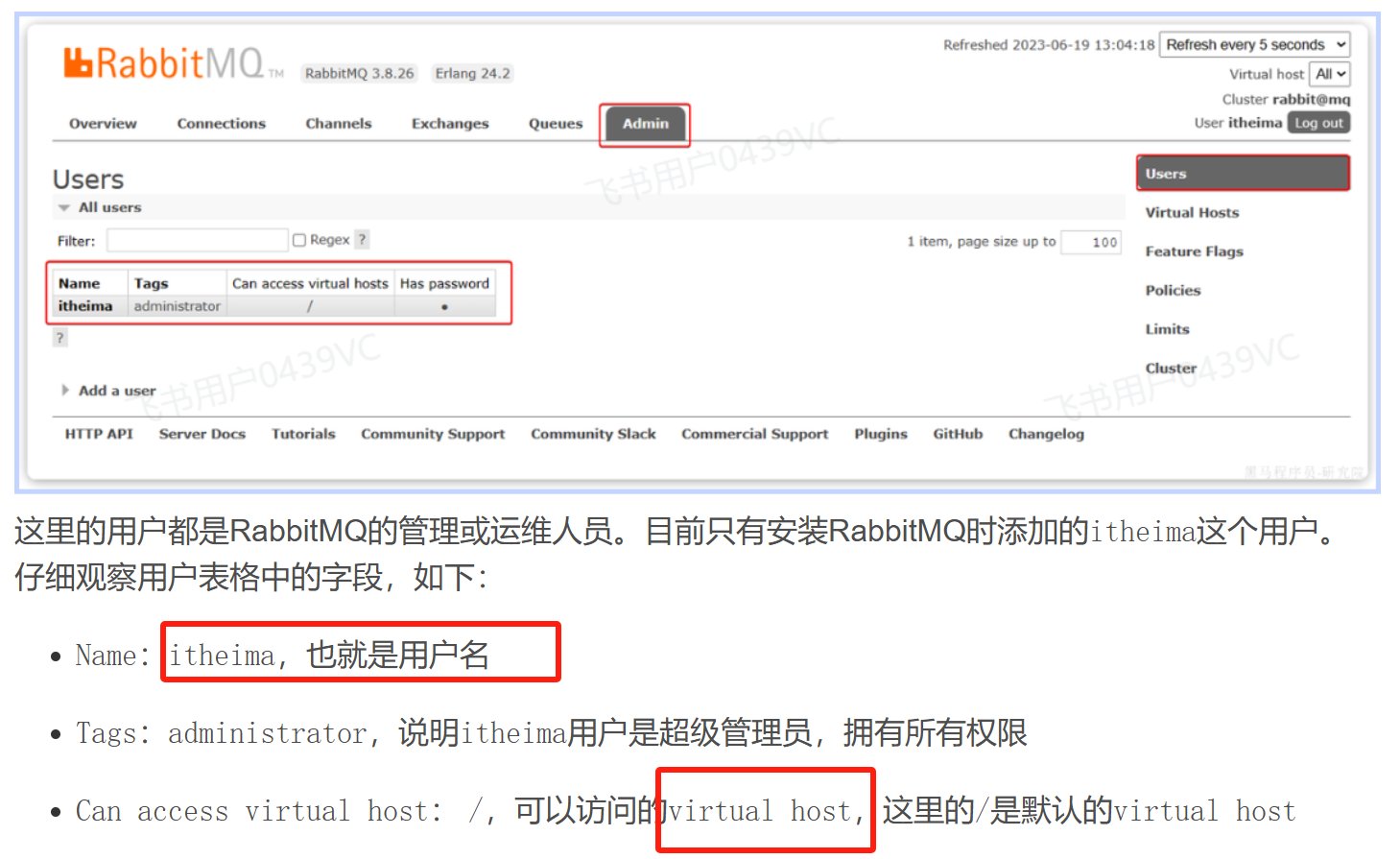
先参考文章:(必看)
1、Rabbit配置
配置都是大差不差:

没有显式指定
virtual-host,Spring Boot 默认会使用 RabbitMQ 的默认虚拟主机/。
多个用户共享一个虚拟主机是允许的,但建议谨慎使用,尤其在需要权限隔离或避免资源冲突的场景下,应采用多个 vhost 进行隔离。
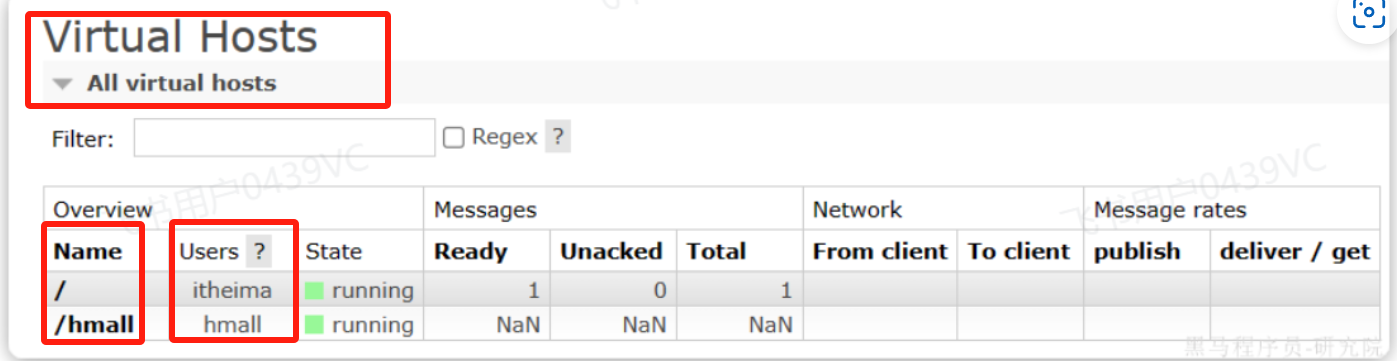
下面多了一个虚拟主机

参考下面的:

2、实战
因为有多种创建队列交互机方式,我下面只讲注解方式(实战时候使用下面方式就行)
使用注解时:消费者端创建交换机和队列( 所以关注生产者 和消费者 就行**)**
注意:下面只解释了一种交换机direct
2.1、生产者
rabbitTemplate.convertAndSend(exchangeName, "red", message);向 指定交换机 发送一条消息。
| 参数 | 含义 |
|---|---|
exchangeName |
要发送到的交换机的名称,例如 "hmall.direct" |
"red" |
路由键(Routing Key),用于和绑定队列的路由键进行匹配 |
message |
实际要发送的消息内容,可以是字符串、对象等(对象会被自动序列化) |
2.2、消费者
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"), // ① 定义队列 direct.queue1
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT), // ② 定义并绑定交换机 hmall.direct
key = {"red", "blue"} // ③ 绑定路由键 red 和 blue
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】"); // ④ 消费消息
}解释:
这是一个消费者,这段代码是使用 Spring AMQP(Spring 对 RabbitMQ 的支持)中的注解方式,声明并监听一个队列 ,并绑定到一个Direct 类型的交换机上。
| 部分 | 说明 |
|---|---|
@RabbitListener(...) |
表示这是一个监听 RabbitMQ 消息的方法。Spring 会自动创建监听器容器来消费消息。 |
@QueueBinding |
绑定队列和交换机之间的关系。内部包含队列、交换机、路由键信息。 |
@Queue(name = "direct.queue1") |
定义一个名为 direct.queue1 的队列。如果不存在则自动创建。 |
@Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT) |
定义一个名为 hmall.direct 的 Direct 类型交换机(点对点匹配的交换机)。 |
key = {"red", "blue"} |
表示队列 direct.queue1 会绑定两个 routing key:red 和 blue,即:hmall.direct 交换机上,凡是带有这两个 routing key 的消息,都会被路由到该队列。 |
方法参数 String msg |
表示消费者方法接收到的消息体内容。这里是字符串类型。 |
System.out.println(...) |
打印出收到的消息,方便调试或日志记录。 |
2.3、幂等性
我只讲实战可能会用到的
2.3.1、发送者的可靠性
2.3.1.1、生产者重试机制(×)
建议禁用重试机制
2.3.1.2、生产者确认机制(×)
开启生产者确认比较消耗MQ性能,一般不建议开启
2.3.2、MQ的可靠性
2.3.2.1、数据持久化(√)
交换机、队列、消息持久化
2.3.2.2、LazyQueue(√)
LazyQueue(惰性队列)

3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。
所以默认不用管
2.3.3、消费者的可靠性(*)
2.3.3.1、消费者确认机制(√)
auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:
如果是业务异常 ,会自动返回
nack;如果是消息处理或校验异常 ,自动返回
reject;消息处理失败后,会回到RabbitMQ,并重新投递到消费者。【不停发送】
2.3.3.2、失败重试机制(√)
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力
修改consumer服务的application.yml文件
前面两个结合用
2.3.3.3、失败处理策略(√)
对前面两个方式的补充:
因为之前重试次数消耗完后消息还是被丢弃了

比较优雅的一种处理方案是
RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
2.3.3.4、业务幂等性(√)
主要就是业务判断
执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理
2.3.3.5、兜底方案(√)
定时任务主动查询
思想很简单:既然MQ通知不一定发送到交易服务,那么交易服务就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致。
2.3.4、总结
主要是关于消费者的可靠性,确认机制 ,消费者无法消费信息后开始重试机制 ,重试一定次数后在进行失败处理策略 ,可以把失败信息全部放到一个队列中,后续由人工集中处理。兜底方案是进行主查