LightRAG:轻量级检索增强生成框架
概述
LightRAG 是由香港大学数据科学实验室开发的一个开源项目,它通过结合知识图谱和向量检索技术,优化了传统检索增强生成(Retrieval-Augmented Generation, RAG)系统在处理复杂知识关系和检索效率方面的不足。LightRAG 旨在提供一个简单、快速且高效的解决方案,特别适合资源受限的场景,如移动设备或边缘计算环境。
核心流程
LightRAG 的工作流程可以分为以下几个步骤:
-
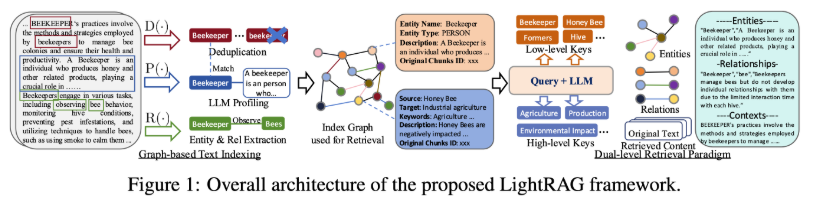
实体和关系提取
使用大型语言模型(LLM)分析文档,自动识别出文本中的实体及其关系,并将这些信息转化为键值对。
-
图基文本索引
提取的信息被组织成图结构,其中实体作为节点,关系作为边,形成高效查询的信息网络。
-
双层检索范式
用户查询时,系统首先进行局部关键词匹配,然后是全局关键词匹配,以全面覆盖信息。
-
答案生成与上下文整合
系统根据检索到的信息生成最终的答案,并确保其逻辑连贯、信息准确 。
架构图
与GraphRAG的区别
-
架构设计
GraphRAG 更加注重于构建复杂的知识图谱,适用于需要多跳推理的任务,而 LightRAG 则强调轻量化和高效性,适合实时性和资源受限的应用 。
-
性能与成本
GraphRAG 对硬件要求较高,响应速度相对较慢,但提供了强大的推理能力;相比之下,LightRAG 计算复杂度低,支持在低算力设备上运行,响应速度快 。
-
适用场景
GraphRAG 更适合用于医疗诊断、法律咨询等需要深度推理的领域;而 LightRAG 更适合实时问答系统、个人助理等需要快速响应的应用 。
适用场景
-
搜索引擎优化
增强搜索引擎的查询处理能力,提供更准确和相关的搜索结果 。
-
智能客服系统
在客户服务领域,理解客户的复杂查询,提供详尽、准确的回答,提高客户满意度 。
-
推荐系统
整合用户行为和产品信息,提供个性化的推荐,增强用户体验 。
示例代码
以下是一个简单的示例代码,展示了如何使用 LightRAG 进行初始化、插入文本以及执行查询。
python
import os
import asyncio
from lightRAG import LightRAG, QueryParam
WORKING_DIR = "./your_project_directory"
async def initialize_rag():
rag = LightRAG(
working_dir=WORKING_DIR,
embedding_func=openai_embedding, # 需要定义您的嵌入函数
llm_model_func=gpt_4o_mini_complete # 需要定义您的LLM模型函数
)
await rag.initialize_storages()
return rag
def main():
rag = asyncio.run(initialize_rag())
# 插入文本
rag.insert("Your text here.")
# 执行查询
query = "What are the top themes in this story?"
result = rag.query(query, param=QueryParam(mode="global"))
print(result)
if __name__ == "__main__":
main()