
文章摘要
沙特阿卜杜拉国王科技大学和Meta AI研究团队提出Vgent框架,通过构建视频语义图谱和结构化推理机制,显著提升大型视频语言模型在长视频理解任务中的表现,在MLVU基准测试中获得3.0%-5.4%的性能提升。
原文PDF - https://t.zsxq.com/JSYYi
引言:长视频理解的技术挑战
随着多模态大语言模型(MLLMs)在视觉理解领域的快速发展,大型视频语言模型(LVLMs)在视频理解任务中展现出巨大潜力。然而,处理和推理长时间视频内容仍然是一个巨大挑战------一段30分钟的视频可能包含超过200K个token,远超大多数模型的上下文限制。
现有的解决方案主要依赖稀疏帧采样或token压缩技术,但这些方法不可避免地导致视觉信息丢失,削弱了细粒度时序理解和连贯推理能力。虽然检索增强生成(RAG)技术在处理大语言模型的长上下文方面表现出色,但将其应用于长视频面临着时序依赖关系断裂和无关信息干扰等挑战。
Vgent框架:创新的图谱化解决方案
核心创新点
沙特阿卜杜拉国王科技大学和Meta AI的研究团队提出了Vgent框架,这是一个全新的基于图的检索推理增强生成框架,专门用于增强LVLMs的长视频理解能力。
该框架的两大核心创新包括:
-
结构化图表示
:通过构建保持视频片段间语义关系的结构化图谱来表示视频,提高检索效果
-
中间推理步骤
:引入结构化验证机制来减少检索噪音,促进跨片段相关信息的显式聚合,产生更准确和上下文感知的回应
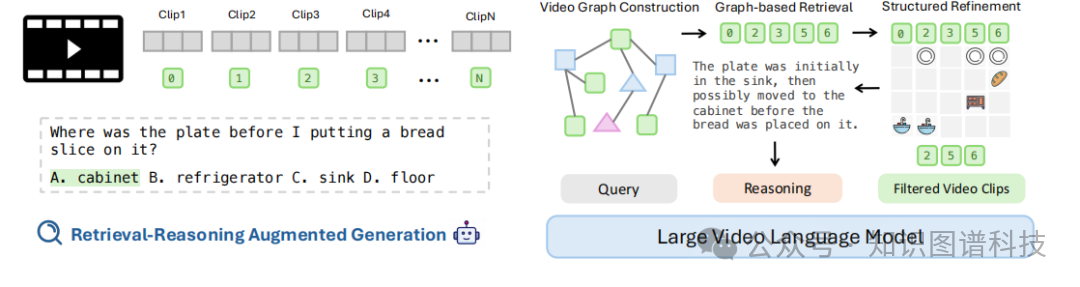
Figure 1框架总体概览图,展示基于图的检索推理增强生成框架
技术架构深度解析
Vgent框架采用四阶段流水线设计,如下图所示:

Figure 2:完整的技术流水线图
阶段一:离线视频图谱构建
首先,系统将长视频V分割成包含K帧(K=64)的短视频片段序列{V₁, V₂, ..., V⌈F/K⌉}。对于每个视频片段,利用LVLM从口语内容(字幕)Cᵢ和视频片段Vᵢ中提取关键语义实体:
code
{(e₁ᵢ, t₁ᵢ), (e₂ᵢ, t₂ᵢ), ...} ← LVLM(Cᵢ, Vᵢ)其中实体集合记为Eᵢ = {e₁ᵢ, e₂ᵢ, ...},对应描述集合记为Tᵢ = {t₁ᵢ, t₂ᵢ, ...}。
实体合并与节点连接是图构建的关键步骤。由于LVLM独立处理视频片段,系统需要识别并统一跨片段语义等价的实体。具体而言,对于新提取的实体-描述对(eⱼᵢ, tⱼᵢ),系统计算其与全局实体集合U中实体描述的相似度分数:
code
s* = max_{u∈U} sim(tⱼᵢ, tᵤ)
u* = argmax_{u∈U} sim(tⱼᵢ, tᵤ)如果相似度分数 > τ(τ=0.7),则实体eⱼᵢ被认为与现有实体语义等价并合并;否则作为独特实体加入U。
阶段二:基于图的检索
关键词提取:系统首先从查询Q中提取关键语义元素K,避免直接基于原始查询进行检索可能导致的上下文不足问题。
图基检索:对于每个关键词k∈K和每个实体u∈U,计算相似度分数sim(k, tᵤ)。如果sim(k, tᵤ) > θ(θ=0.5),则将与实体u相关的所有节点纳入目标检索节点集R:
code
R = ⋃_{u∈U,k∈K} {v∈V | u∈U(v), sim(k, tᵤ) > θ}获得检索节点集R后,系统基于查询关键词与每个节点的实体、文本描述和字幕的相似度对节点重新排序,最终选择Top-N(N=20)个具有最高平均相似度分数的节点。
阶段三:结构化推理
结构化查询细化:研究团队发现,在约40%的失败案例中,正确片段确实被成功检索到,但模型仍然生成错误回应。为解决这一问题,系统采用分而治之策略,通过结构化查询验证来细化检索结果。
具体而言,系统提示LVLM基于原始查询Q和提取的关键词K生成结构化子查询Q。这些子查询专注于验证相关实体的存在或量化其出现次数,期望答案为二元(是/否)或数值。
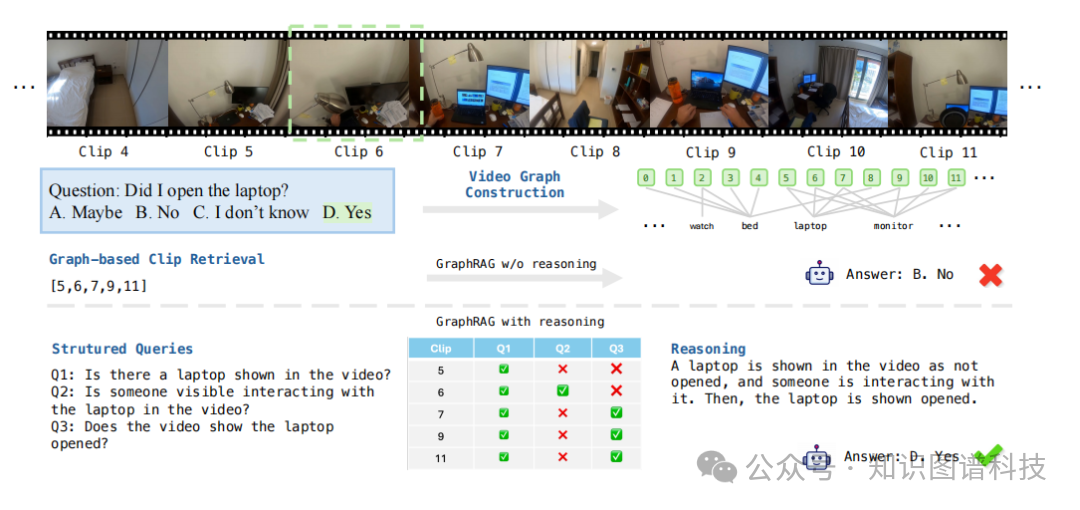
Figure 3:结构化子查询示例图
经过结构化验证后,细化的片段集R'可表示为:
code
R' = {vᵢ ∈ R | ∃qⱼ ∈ Q, f(vᵢ, qⱼ) > 0}其中f(vᵢ, qⱼ)表示检索片段vᵢ对子查询qⱼ的回应。系统在细化后最多保留r=5个片段。
信息聚合:系统让LVLM聚合和总结来自结构化查询的所有有用信息及其对应的每个视频片段结果,提供丰富的辅助上下文以增强最终推理。
阶段四:多模态增强生成
系统将中间推理结果和过滤的视频片段作为多模态上下文输入到LVLM中生成最终回应。这种丰富的输入允许模型同时利用结构化推理和相关视觉信息,生成更准确且上下文相关的最终答案。
实验评估与性能表现
实验设置
研究团队在七个不同规模(2B到7B)的LVLM上评估框架性能,包括InternVL2.5、Qwen2、Qwen2.5-VL、LongVU和LLaVA-Video等开源模型。
评估使用三个长视频理解基准:
-
Video-MME
:包含从11秒到1小时的不同长度视频子集
-
MLVU
:视频长度从3分钟到2小时,平均约12分钟
-
LongVideoBench (LVB)
:专注于需要分析长帧序列的推理任务
主要实验结果
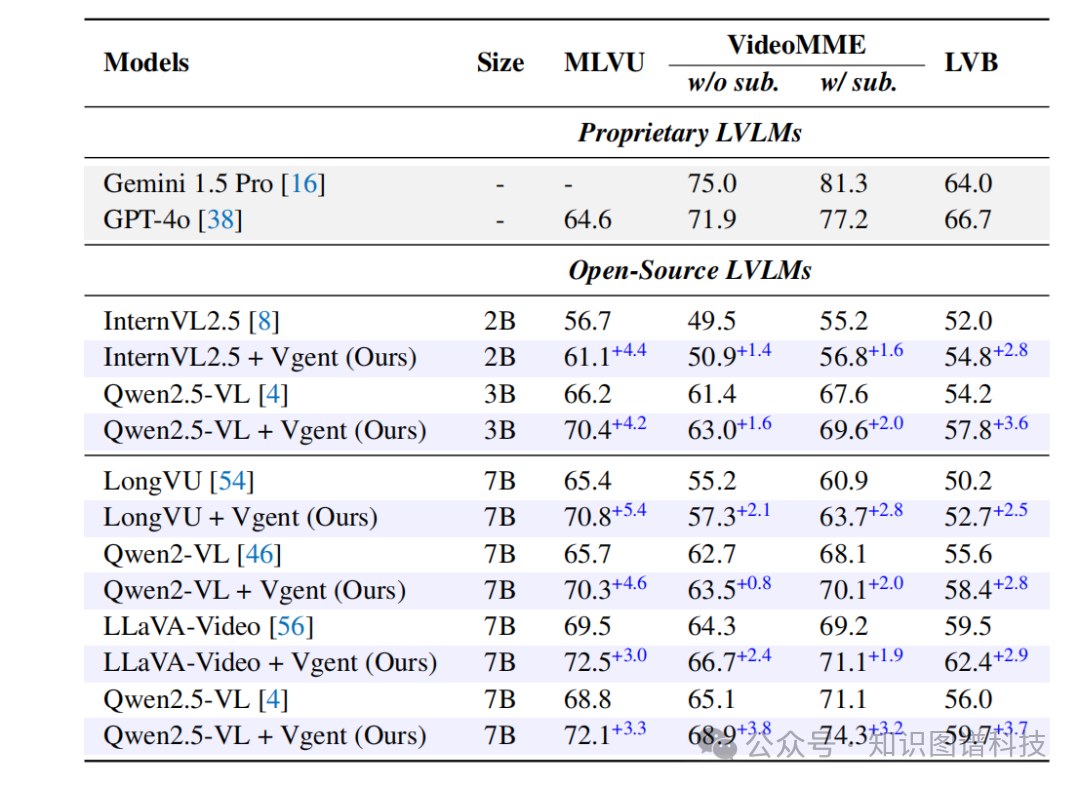
Table 1:与LVLM性能对比表
与LVLM对比:实验结果显示,Vgent框架在所有模型上都实现了显著改进:
-
在MLVU基准上,框架将LongVU性能提升5.4%,Qwen2.5VL (7B)提升3.3%
-
值得注意的是,应用于Qwen2.5VL (3B)时,Vgent达到70.4%的准确率,超越其更大的7B对应版本,并将基础模型性能提升4.2%
-
在VideoMME基准上,框架在所有视频长度上都优于基础模型,平均性能提升4.2%
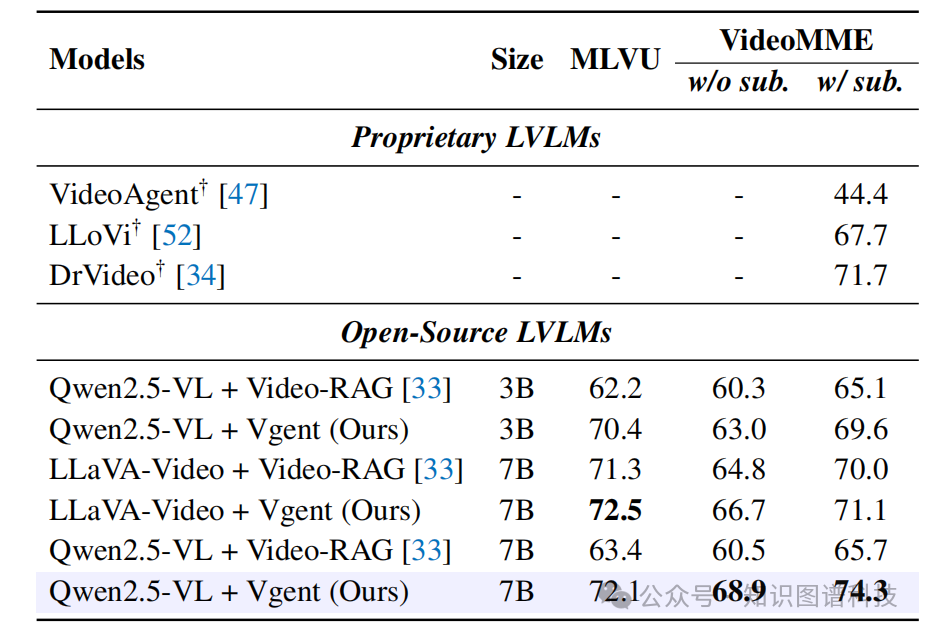
Table 2:RAG方法对比表
与最先进RAG方法对比:
-
框架在三个不同LVLM基础模型上都持续优于RAG基线Video-RAG
-
与严重依赖闭源API的专有RAG方法相比,Vgent提供了更灵活有效的长视频理解解决方案
-
总体而言,框架超越现有基于RAG的视频理解工作8.6%
消融实验分析
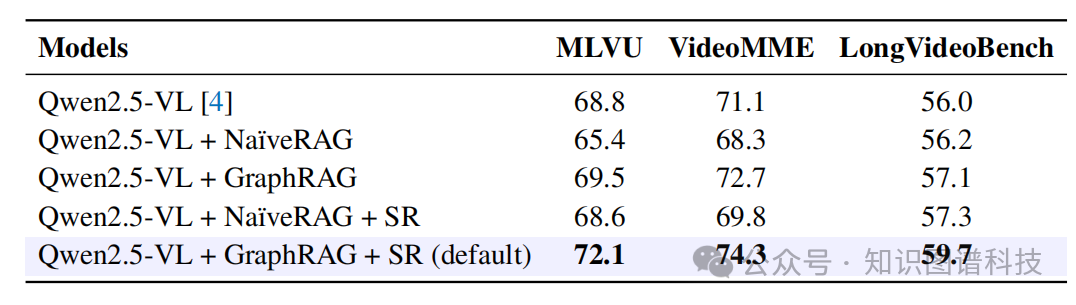
Table 3:消融实验结果表
NaïveRAG vs GraphRAG:集成GraphRAG相比NaïveRAG平均提升2.9%,在MLVU上特别显著提升4.1%。这是因为NaïveRAG难以处理需要跨多个片段时序推理的复杂查询,而GraphRAG通过图表示有效保持片段间语义关系。
结构化推理(SR)效果:通过结构化查询的中间推理细化检索节点,在MLVU上额外提升2.6%,VideoMME上提升1.6%,总体平均提升3.4%。
检索数量影响:
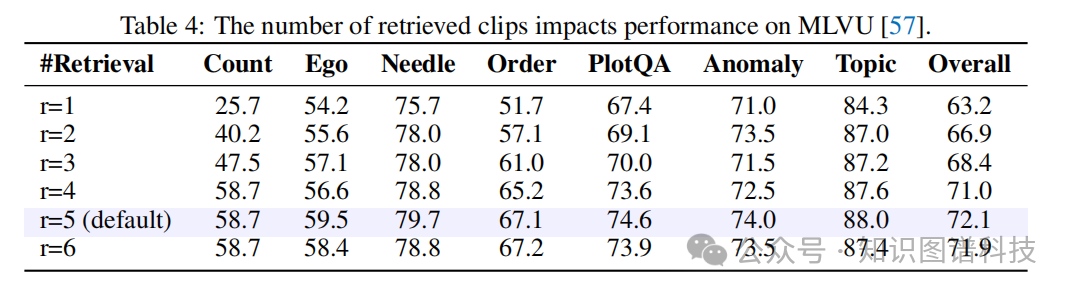
Table 4:检索片段数量影响分析表
研究发现增加检索片段数量持续改善性能,特别是对于需要多片段推理的任务,在r=5时达到最高性能。
推理时间分析
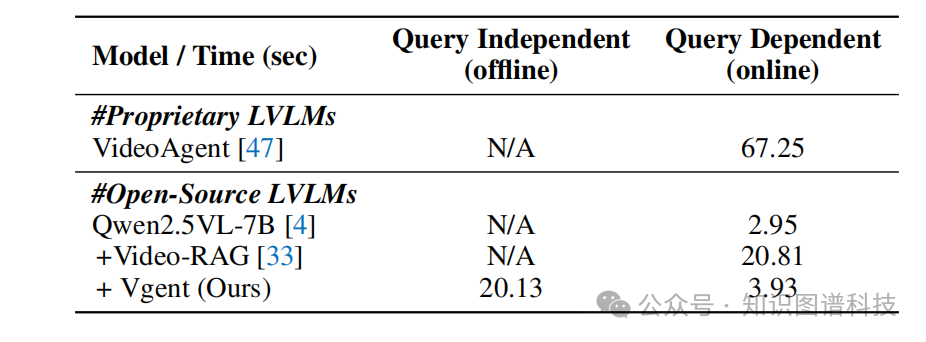
Table 5:推理时间分析表
框架在计算效率方面表现出色:
-
离线图构建需要20.13秒,但这是查询无关的一次性过程
-
在线检索、推理和生成过程每分钟视频仅需3.93秒
-
在多问题场景中(如VideoMME每个视频三个问题),相比Video-RAG实现1.73倍加速
定性分析案例
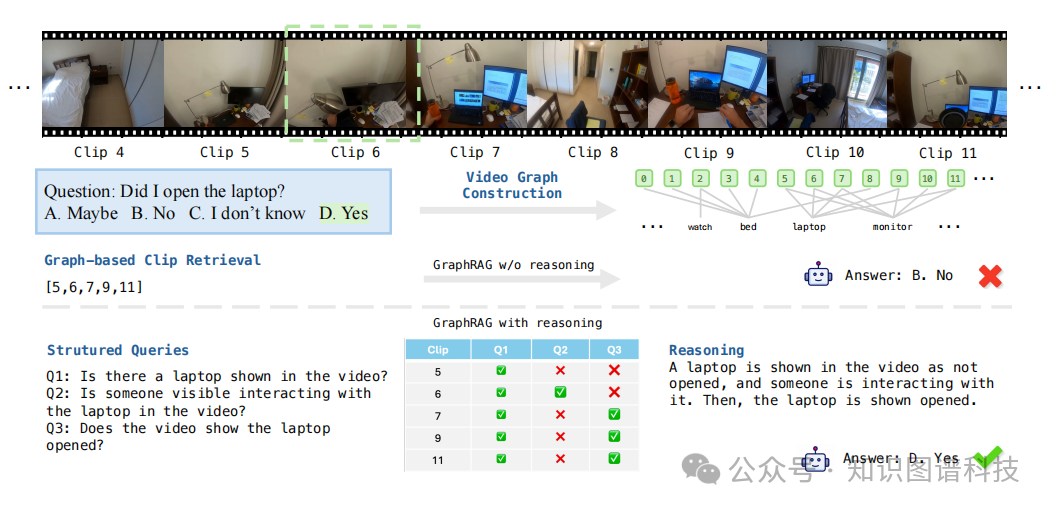
Figure 3:定性分析示例
图3展示了一个典型案例:虽然基于图的检索系统能够识别包含笔记本电脑的相关节点,但模型最初由于来自多个片段的难负样本干扰而错误回答。然而,通过中间推理步骤验证每个检索节点的结构化子查询,系统能够正确推断笔记本电脑被打开,克服了难负样本的干扰。
技术优势与创新价值
相比现有方法的优势
-
保持时序连贯性:不同于将长视频分割成独立文档的传统方法,Vgent通过图结构保持实体和时序依赖关系
-
自包含设计:相比依赖专有LLM如GPT-4的方法,Vgent专门针对开源LVLM设计,更具灵活性和成本效益
-
查询无关图构建:图构建离线执行且查询无关,一旦构建可重用于同一视频的多个问题,无需重新处理视频
-
结构化噪音减少:通过结构化推理步骤系统性过滤无关片段,有效减少信息过载问题
应用场景与商业价值
该技术在多个领域具有广阔应用前景:
-
网络内容分析
:处理长时间在线视频内容的自动化理解和标注
-
生活记录系统
:个人或企业长时间视频记录的智能检索和分析
-
流媒体服务
:提升视频推荐系统的内容理解精度
-
安防监控
:长时间监控视频的异常检测和事件分析
局限性与未来发展
虽然Vgent框架在长视频理解方面取得显著进展,但仍存在一些局限性:
-
图构建开销:虽然是离线过程,但对于大规模视频数据集,图构建仍需要相当的计算资源
-
实体识别准确性:框架性能部分依赖于LVLM的实体提取能力,在复杂场景中可能存在识别错误
-
跨模态对齐:视觉实体与文本描述的对齐仍有改进空间
未来研究方向可能包括:
-
优化图构建算法以提高效率
-
增强跨模态实体对齐技术
-
扩展到更多视频理解任务
结论与展望
Vgent框架通过创新的图谱化表示和结构化推理机制,为长视频理解领域带来了重要突破。其在保持时序关系、减少检索噪音、提升推理准确性等方面的技术创新,不仅在学术基准测试中获得显著性能提升,更为实际应用场景提供了可行的解决方案。
该工作为更准确和上下文感知的长视频检索推理系统铺平了道路,标志着多模态大语言模型在视频理解领域的重要进展。随着技术的不断完善,预计将在智能视频分析、内容理解等领域产生广泛的商业价值和社会影响。
标签
#GraphRAG #视频理解 #大模型 #多模态 #LLM #检索增强生成
注:本文基于沙特阿卜杜拉国王科技大学和Meta AI研究团队的最新研究成果编译整理,详细技术实现请参考原论文。
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。