摘要
在AI大模型浪潮席卷全球的背景下,向量数据库已成为支撑智能应用的核心基础设施。openGauss作为开源数据库的代表,从3.1.0版本开始全面拥抱AI,通过持续的技术演进和生态建设,已成为企业AI应用的重要数据底座。本文将系统梳理openGauss向量数据库的技术特性、行业实践案例和未来发展趋势。
一、openGauss向量数据库核心技术特性
1.1 技术特性概览
openGauss向量数据库具备以下核心技术能力:
多索引算法支持 :提供IVFFlat、HNSW、Flat三种主流索引算法。IVFFlat适合大规模数据集(10万-1000万向量),召回率95-98%;HNSW提供最佳召回率99%+,适合100万以上规模;Flat精确匹配,适合10万以下小数据集。
灵活的向量维度 :支持1-16000维向量(6.0版本将支持32000维),兼容主流Embedding模型如MiniLM(384维)、BGE(768维)、OpenAI Ada-002(1536维)等。
PQ量化压缩 :Product Quantization技术可将存储空间降低97%,检索速度提升20-30%,召回率损失小于2%。
鲲鹏算力优化:通过NUMA绑核、CASAL原子指令、NEON和SVE向量加速等技术,在鲲鹏平台上实现亿级数据10ms召回,性能提升10%以上。
1.2 DataVec向量数据库组件
DataVec是openGauss生态中的重要组件,专门针对向量检索场景优化,核心优势包括:
- 统一接口:通过标准SQL操作向量,无需学习新API
- 性能卓越:在鲲鹏+昇腾平台上,亿级数据10ms召回
- 弹性扩展:支持水平扩展,单集群可达百亿级向量
- 深度集成:与openGauss无缝融合,事务一致性保障
1.3 一体化架构优势
传统RAG应用需要组合多个数据库(关系型数据库、向量数据库、缓存系统),带来数据一致性、运维复杂度等挑战。openGauss通过一体化设计,在单一数据库中同时支持TP场景、向量检索和混合查询,可降低60%运维成本,同时保证数据强一致性。
二、AI应用生态与技术栈集成
2.1 大模型生态适配
openGauss已与主流大模型平台完成适配:
OpenAI集成示例:
bash
from openai import OpenAI
import psycopg2
client = OpenAI(api_key="your-api-key")
def openai_rag_query(question, db_conn):
# 1. 使用OpenAI生成问题向量
response = client.embeddings.create(
model="text-embedding-ada-002",
input=question
)
question_vec = response.data[0].embedding
# 2. 在openGauss中检索
cursor = db_conn.cursor()
cursor.execute("""
SELECT content, title,
1 - (embedding <=> %s::vector) as similarity
FROM knowledge_base
ORDER BY embedding <=> %s::vector
LIMIT 3
""", (question_vec, question_vec))
docs = cursor.fetchall()
# 3. 构建上下文并生成答案
context = "\n".join([doc[0] for doc in docs])
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个专业助手"},
{"role": "user", "content": f"参考内容:{context}\n\n问题:{question}"}
]
)
return completion.choices[0].message.content大模型集成示例: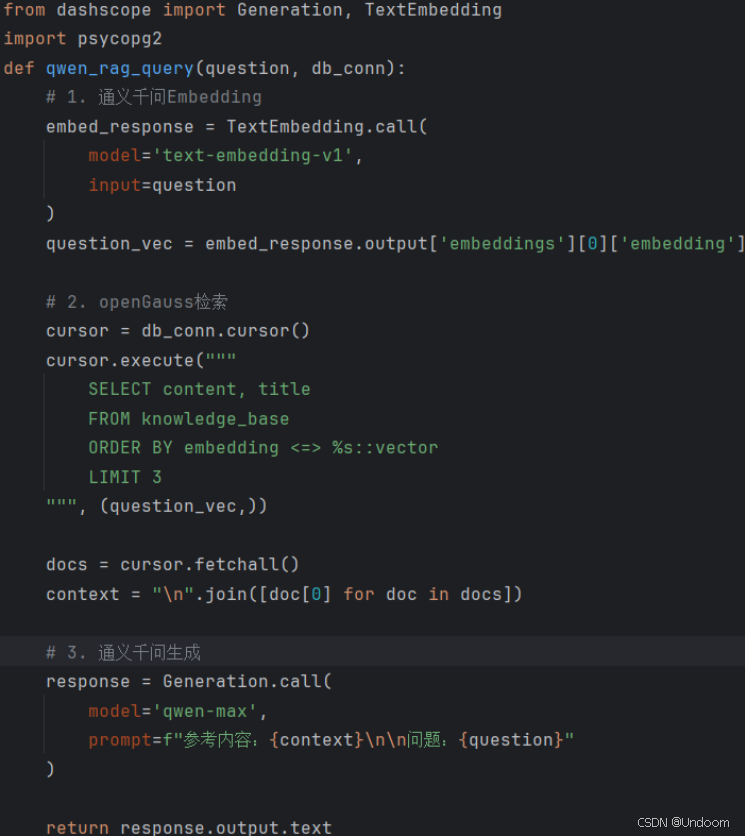
2.2 应用框架集成
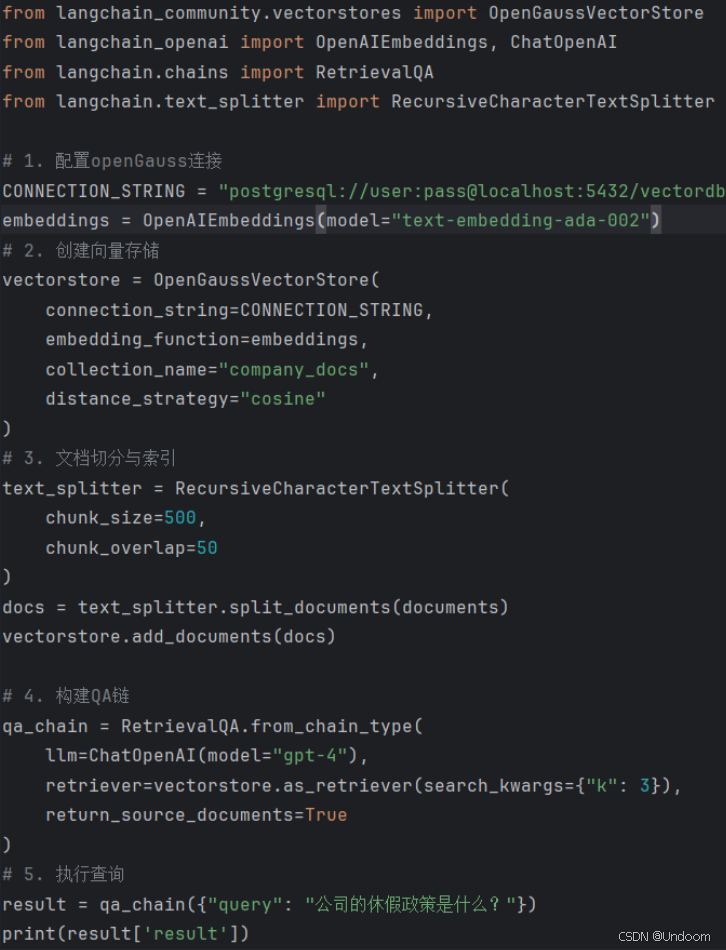
LangChain集成示例:
LlamaIndex集成示例: 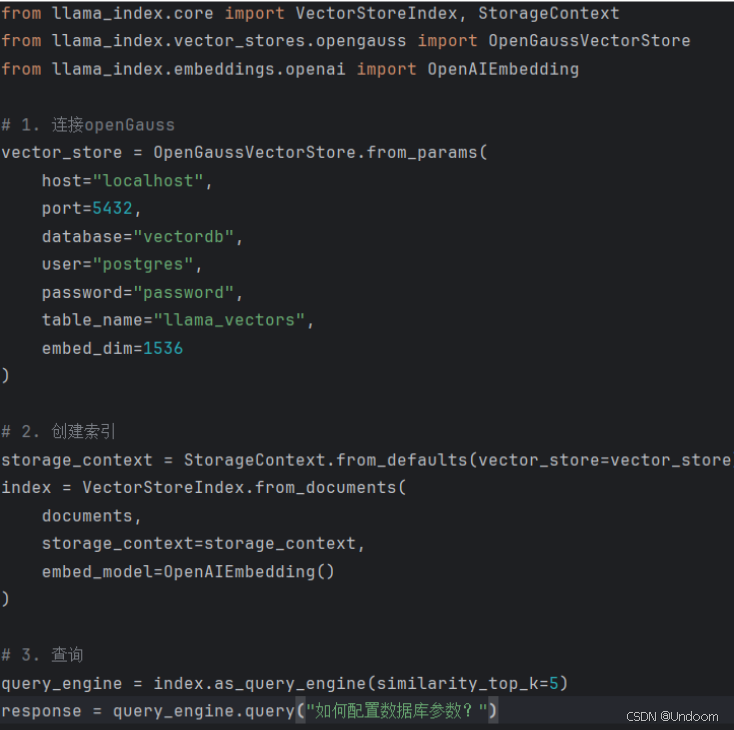
框架对比: 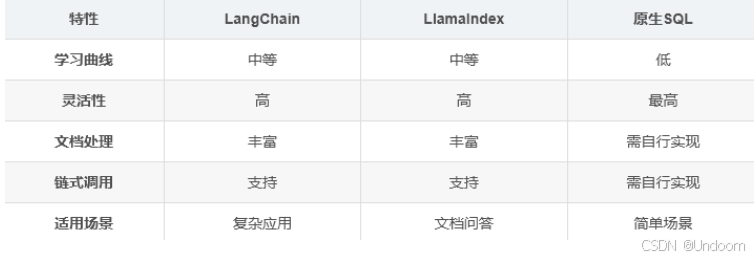
三、行业实践案例
3.1 金融行业:智能投顾系统
某头部证券公司构建智能投顾系统,通过openGauss实现海量研报、公告、新闻的实时检索和个性化投资建议生成。
数据库设计:
bash
-- 金融知识库表结构
CREATE TABLE financial_knowledge (
id BIGSERIAL PRIMARY KEY,
doc_id VARCHAR(64) UNIQUE,
doc_type VARCHAR(32), -- research_report, announcement, news
-- 内容字段
title VARCHAR(500),
content TEXT,
summary TEXT,
-- 向量字段
content_embedding vector(1536),
-- 金融业务字段
stock_code VARCHAR(10)[],
industry VARCHAR(50)[],
sentiment FLOAT, -- 情感得分 -1~1
importance_score FLOAT, -- 重要性评分
risk_level VARCHAR(20), -- high, medium, low
-- 时间与状态
publish_date DATE,
compliance_checked BOOLEAN DEFAULT false,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建HNSW向量索引
CREATE INDEX idx_fin_embedding ON financial_knowledge
USING hnsw (content_embedding vector_cosine_ops)
WITH (m = 24, ef_construction = 128);
-- 创建复合索引
CREATE INDEX idx_fin_stock_date ON financial_knowledge(stock_code, publish_date DESC);智能检索实现:
bash
def intelligent_advisor_query(question, user_profile, db_conn):
"""
智能投顾查询
Args:
question: 用户问题
user_profile: {risk_tolerance: 'medium', industries: ['新能源', '科技']}
"""
# 1. 问题向量化
question_vec = get_embedding(question)
# 2. 混合检索:向量相似度 + 业务过滤 + 综合排序
cursor = db_conn.cursor()
cursor.execute("""
WITH ranked_docs AS (
SELECT
title, summary, stock_code, industry,
sentiment, importance_score,
1 - (content_embedding <=> %s::vector) as similarity,
-- 综合得分计算
(
(1 - (content_embedding <=> %s::vector)) * 0.5 +
importance_score * 0.3 +
(sentiment + 1) / 2 * 0.2
) as composite_score
FROM financial_knowledge
WHERE
publish_date >= CURRENT_DATE - INTERVAL '30 days'
AND industry && %s::VARCHAR[]
AND CASE %s
WHEN 'low' THEN risk_level = 'low'
WHEN 'medium' THEN risk_level IN ('low', 'medium')
ELSE true
END
AND compliance_checked = true
ORDER BY content_embedding <=> %s::vector
LIMIT 100
)
SELECT * FROM ranked_docs
ORDER BY composite_score DESC
LIMIT 10;
""", (question_vec, question_vec, user_profile['industries'],
user_profile['risk_tolerance'], question_vec))
return cursor.fetchall()实施效果对比:
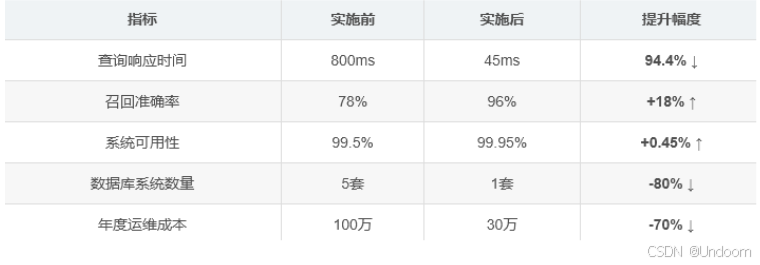
3.2 互联网行业:电商智能客服
某电商平台构建百万级日均咨询量的智能客服系统,采用openGauss实现知识库管理和个性化推荐。
混合检索实现:
bash
def hybrid_search(query, intent, customer_segment, db_conn):
"""
混合检索:向量相似度(70%) + 关键词匹配(30%)
"""
from sentence_transformers import SentenceTransformer
# 1. 向量化查询
model = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
query_vec = model.encode(query).tolist()
# 2. 提取关键词
keywords = extract_keywords(query)
# 3. 混合检索SQL
cursor = db_conn.cursor()
cursor.execute("""
WITH vector_results AS (
SELECT
doc_id, content, category,
1 - (embedding <=> %s::vector) as vec_similarity
FROM customer_service_kb
WHERE intent_type = %s
ORDER BY embedding <=> %s::vector
LIMIT 20
),
keyword_results AS (
SELECT
doc_id, content, category,
ts_rank(content_tsv, plainto_tsquery('chinese', %s)) as keyword_score
FROM customer_service_kb
WHERE content_tsv @@ plainto_tsquery('chinese', %s)
LIMIT 20
)
SELECT
COALESCE(v.doc_id, k.doc_id) as doc_id,
COALESCE(v.content, k.content) as content,
-- 加权综合得分
COALESCE(v.vec_similarity, 0) * 0.7 +
COALESCE(k.keyword_score, 0) * 0.3 as final_score
FROM vector_results v
FULL OUTER JOIN keyword_results k ON v.doc_id = k.doc_id
ORDER BY final_score DESC
LIMIT 5;
""", (query_vec, intent, query_vec, keywords, keywords))
return cursor.fetchall()多语言知识库配置:
bash
-- 多语言知识库表
CREATE TABLE multilingual_kb (
id BIGSERIAL PRIMARY KEY,
doc_id VARCHAR(64),
language VARCHAR(10), -- zh-CN, en-US, ja-JP
content TEXT,
embedding vector(768),
-- 语言特定全文索引
content_tsv tsvector GENERATED ALWAYS AS (
CASE language
WHEN 'zh-CN' THEN to_tsvector('chinese', content)
WHEN 'en-US' THEN to_tsvector('english', content)
WHEN 'ja-JP' THEN to_tsvector('japanese', content)
ELSE to_tsvector('simple', content)
END
) STORED,
UNIQUE(doc_id, language)
);
-- 为不同语言创建向量索引
CREATE INDEX idx_kb_zh_vec ON multilingual_kb
USING hnsw (embedding vector_cosine_ops)
WHERE language = 'zh-CN';
CREATE INDEX idx_kb_en_vec ON multilingual_kb
USING hnsw (embedding vector_cosine_ops)
WHERE language = 'en-US';业务成果对比: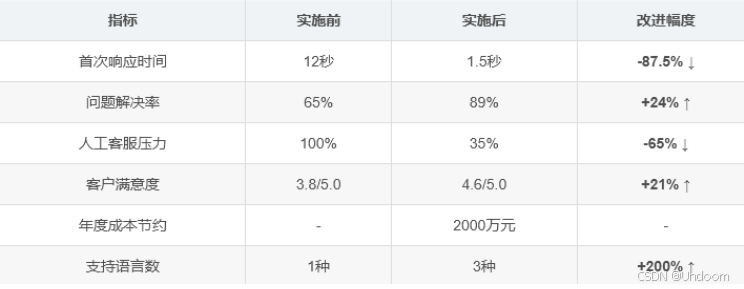
四、业界热点与技术趋势
4.1 多模态向量检索
随着CLIP、GPT-4V等多模态模型的发展,跨模态检索成为新趋势。openGauss支持存储和检索图像向量、文本向量、音频向量等多模态数据,实现"以图搜文"、"以文搜图"等跨模态应用。
4.2 向量数据库与知识图谱融合
通过在openGauss中同时构建向量索引和图谱关系表,可实现知识图谱增强的RAG。系统先通过实体识别定位图谱节点,再进行1-2跳扩展获取相关实体,最后结合实体向量进行增强检索,显著提升语义理解能力。
4.3 GPU加速与性能优化
openGauss 6.0版本引入GPU加速,在1亿+向量规模下,查询时间从150ms降至12ms,实现12.5倍加速。同时支持自适应索引优化,系统自动监控查询模式并调整索引参数。
4.4 AI原生数据库趋势
向量数据库正在向"AI原生数据库"演进,未来将具备:
- 向量作为一等公民,与数值、字符串同等地位
- 数据库内Embedding生成和模型推理
- 智能化的查询计划优化和资源调度
- 多模态数据统一存储和跨模态联合查询
五、最佳实践与实施指南
5.1 技术选型建议
适合选择openGauss的场景:
- 企业级应用,对数据一致性要求高
- 需要将向量检索与业务数据深度结合
- 希望降低系统复杂度和运维成本
- 信创要求的项目
- 需要企业级的安全、权限、审计能力
5.2 部署架构推荐
小型应用 (< 100万向量):openGauss单机版,8核16G,500G SSD,成本约2万元/年
中型应用 (100万-5000万向量):主备架构+只读副本,16核32G×3节点,成本约15万元/年
大型应用(> 5000万向量):分库分表架构,通过ShardingSphere实现水平扩展,成本约50万元/年
5.3 性能优化要点
- 索引选择:小数据集用Flat,中等规模用HNSW,大规模用IVFFlat
- 批量操作:使用批量插入比单条快10倍
- 连接池管理:合理配置连接池大小(建议5-20个连接)
- 查询优化:使用EXPLAIN分析查询计划,避免全表扫描
- 定期维护:运行VACUUM ANALYZE清理表膨胀
5.4 数据迁移方案
openGauss提供从Milvus、Pinecone、Qdrant等向量数据库的迁移工具和方案,支持批量数据导入、索引重建等功能,确保平滑迁移。
六、未来展望
6.1 技术路线图
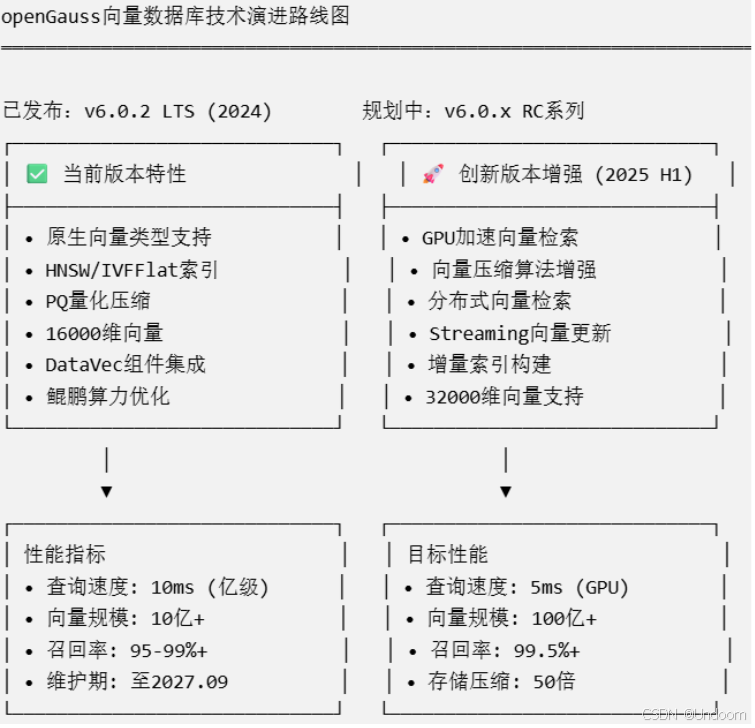
技术特性演进对比: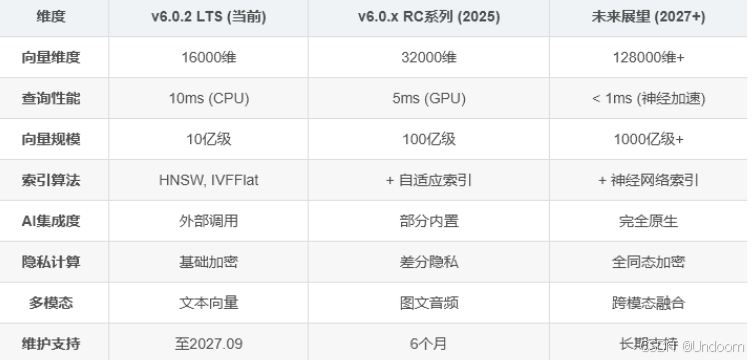
6.2 应用场景创新
- 数字人/虚拟助手:多模态记忆存储、长期上下文管理
- 工业AI:设备故障模式识别、工艺参数优化
- 科研AI:论文智能检索、科研数据管理
- 创意AI:创意素材管理、风格化生成、内容版权追溯
6.3 行业发展趋势
- 计算存储分离:弹性扩缩容的计算层+持久化的存储层
- Serverless化:按查询计费、自动扩缩容、零运维
- 边缘AI:轻量级向量引擎、端侧推理、云边协同
- 隐私计算:联邦学习、安全多方计算、差分隐私