abstract
LLM 预测连续embedding,直接接DiT。和kaiming-Autoregressive Image Generation without Vector Quantization的文章思路一样。- LLM是casual attention,和diffusion 一起训练,相比于full attention会有性能的降低。因此采用【分而治之】的方法------长序列的连续tokens被分成多个patches;只有diffusion loss+stop loss;
离散token 更适用于文本任务,图片/视频/音频等高清生成更适合连续向量。过往的方法要么效果不好(casual attention),要么计算开销很大。
method
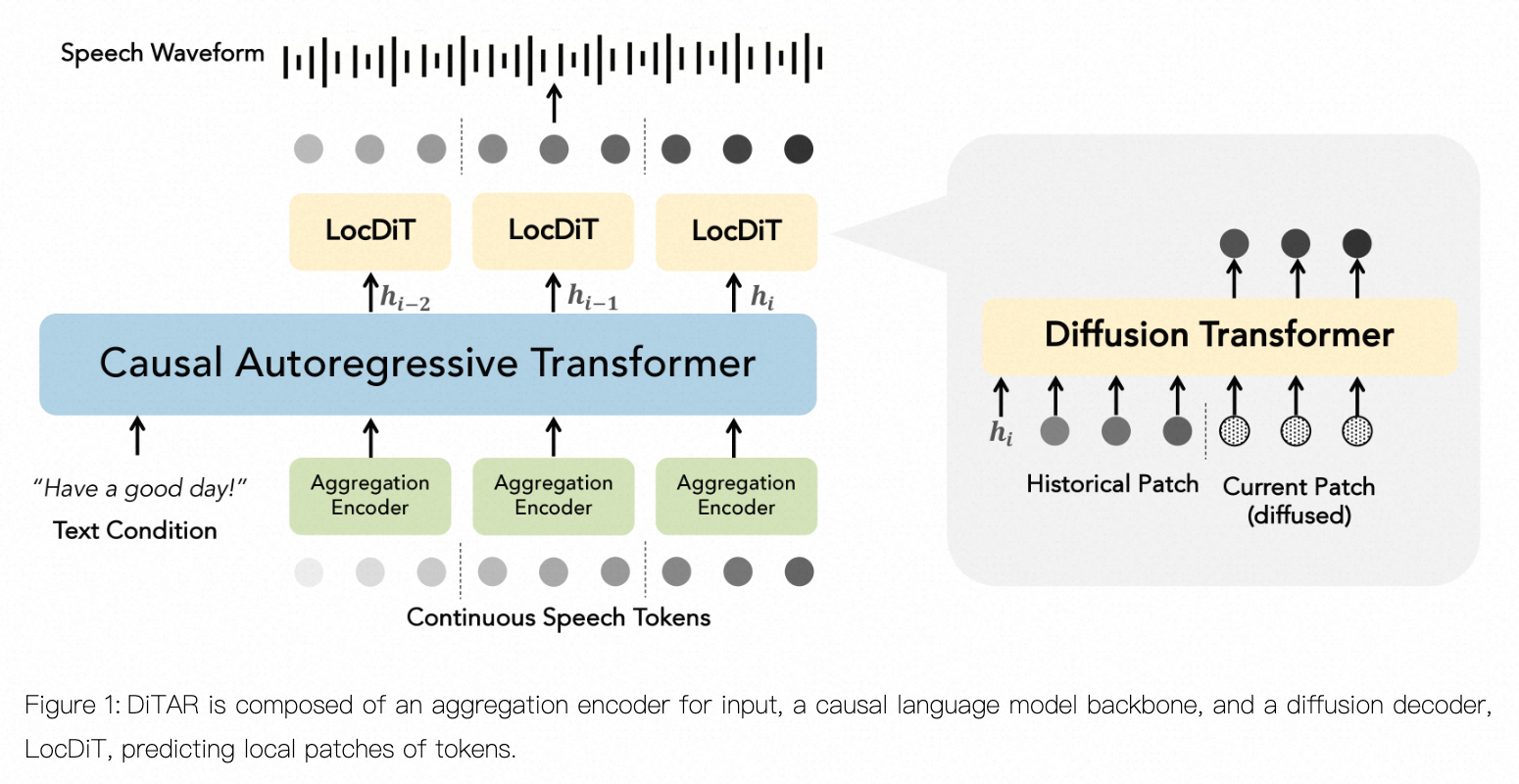
model
-
VAE 训练得到连续embedding;decoder 用bigVAGN 重建得到音频;24k 音频编码成40hz,dim=64
-
LocDiT 输入AR's output 生成下一个patch对应的speech,但是diffusion 在这些条件下很难预测下一个patch的信息;为了解决这一问题,如图1右,之前的patch 作为prefix,因此让任务和outpaiting & context-learning potential 更相关,也改善了生成性能。(4.4 详述)
-
也隐含了一个coarse-to-fine 的过程;
-
CFG 需要两次计算,如果对LLM 算两次,开销很大,本文提出一次LM 计算和两次diffusion 计算。
python
# infer的时候,with_condition & wo_condition 推理两次
# train的时候,0.1的概率将LM的输出置为0,模拟wo_condition的状态,loss 函数正常计算
# pred = diffusion(zero, z) loss = mse(pre, target)
def cfg_guidance(z, hi, h∅, w):
# 无条件输出
uncond_output = diffusion_model(z, h∅)
# 有条件输出
cond_output = diffusion_model(z, hi)
# CFG 调整, w控制向文本/LM condition偏移的程度
final_output = (1 + w) * cond_output - w * uncond_output
return final_output
# 温度系数,温度 τ 调整噪声引入的时间点,影响生成结果的多样性
if τ == 1:
noise = normal_distribution() # 纯噪声
elif 0 < τ < 1:
noise = apply_diffusion(z0, τ) # 基于温度的噪声experiment
patch size
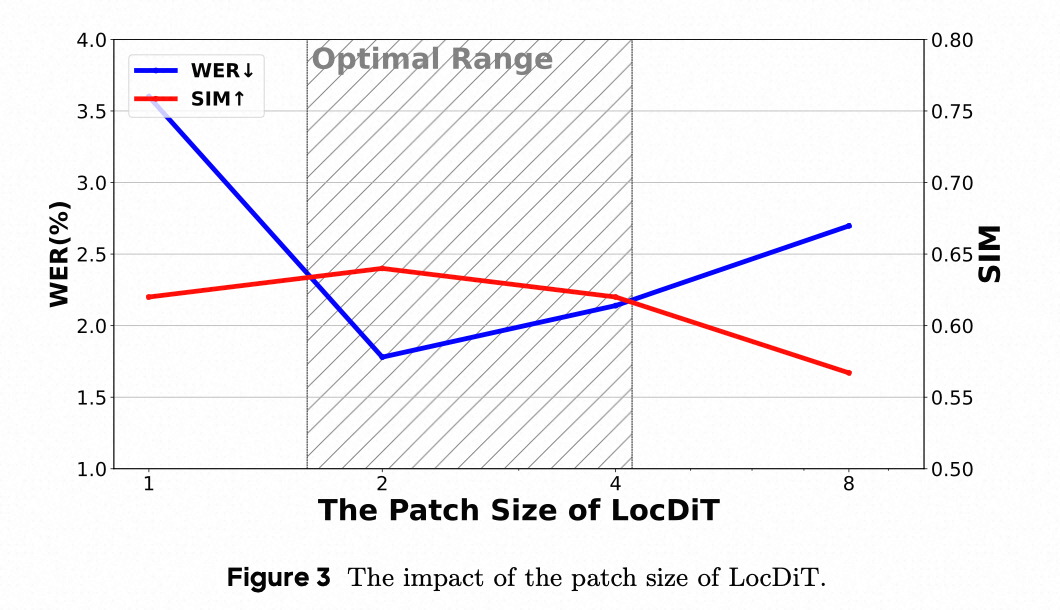
- 当补丁大小太大或太小时,性能会下降。过小的补丁会降低模型的双向注意力能力,迫使依赖因果注意力 AR 并降低性能。相反,过大的补丁会使 LocDiT 成为瓶颈,需要增加参数。
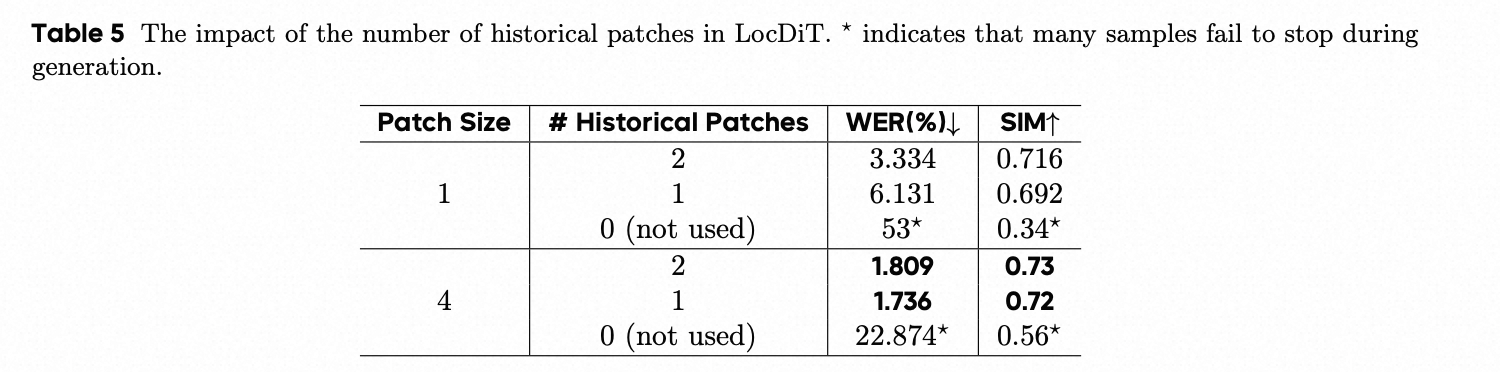
- The Number of Historical Patches of LocDiT
temperature
较高的温度会产生略高的 SIM 分数,而较低的温度会产生更好的 WER 分数。根本原因可能是,模拟看不见的说话者的声音需要模型具有更大的多样性,而发音稳健性需要模型具有更多的确定性和稳定性。