 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- [Compaction Algorithms](#Compaction Algorithms)
- [Compact Execution Flow Based On Velox](#Compact Execution Flow Based On Velox)
- 结束语
引言
时序数据库与关系型数据库一个比较大的功能差异为Deduplicate,时序数据库默认携带,而关系型数据库依赖于索引和查询时主动去重。
以Influxdb举例子阐述Deduplicate功能:
INSERT temperature,device_id=sensor1 v1=25,v2=25 1620000000000000000
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
一般有两种Deduplicate粒度
第一种为Field-Level Updates,上述数据会被合并为:
INSERT temperature,device_id=sensor1 v1=26,v2=25 1620000000000000000
其选择策略为tag+time相同的情况下,相同field的选择lsn大的,field取最后一个非空的
第二种为Row-Level Deduplication,上述数据会被合并为:
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
单纯的基于lsn行选择。
Compaction Algorithms
首先定义 Amplification:
- Write Amplification: 指写入存储设备的数据量与写入数据库的数据量的比率。例如向数据库写入 10 MB 数据,而观察到的磁盘写入为 30 MB,则写入放大率为 3。基于SSD的存储只能写入有限次数,因此写入放大会缩短SSD的使用寿命。
- Read Amplification:指每个查询的磁盘读取次数。例如如果需要读取 5 页来响应查询,则读取放大为 5。写入放大和读取放大的单位不同。写入放大衡量实际写入的数据量比应用程序认为的写入量多,而读取放大则指计算执行查询所需的磁盘读取次数比认为的多。
- Space Amplification:指磁盘上实际存储的物理数据量相对于用户数据的逻辑大小的放大倍数
名词定义:
- T:层之间的大小比值
- L:LSM树的层数
- B:SST文件大小

时序数据库中为了提高查询的效率,数据需要基于时间分shard,这种情况下全局看基本可以认为都是TWCS(Time Window Compaction Strategy)策略,因为老旧shard在经历FullCompact后有且只有一个Sort Runs,在活跃shard中基于不同的考量会有不同的实现方式。
在influxdb1.x中使用了Tiered,多层内均无序,Compact是在每一层选择可压缩的文件,CompactScheduler调度执行。
在GrepTimeDB中使用N-Level,只有两层,内部允许N个Sort Runs,在读写放大之间做权衡
在influxdb3.0中使用了Tiered+Leveled,L0无序,剩下的层数有序,Rocksdb的默认Compact策略也是这样的。
但是值得一提的是时序数据库的Timestamp是去重的主键列,不能简单的依赖时间去重,因为两次写入的时间也可能是重复的,合并的关键在于真实时间上后来的需要覆盖前面的,从实现上来讲一致性引擎的LSN就很合适。
但是这为Compaction的算法实现带来了一点复杂度,如果不按照LSN顺序进行合并,会导致字段覆盖逻辑错误,破坏数据一致性。举以下例子:

错误的合并顺序:
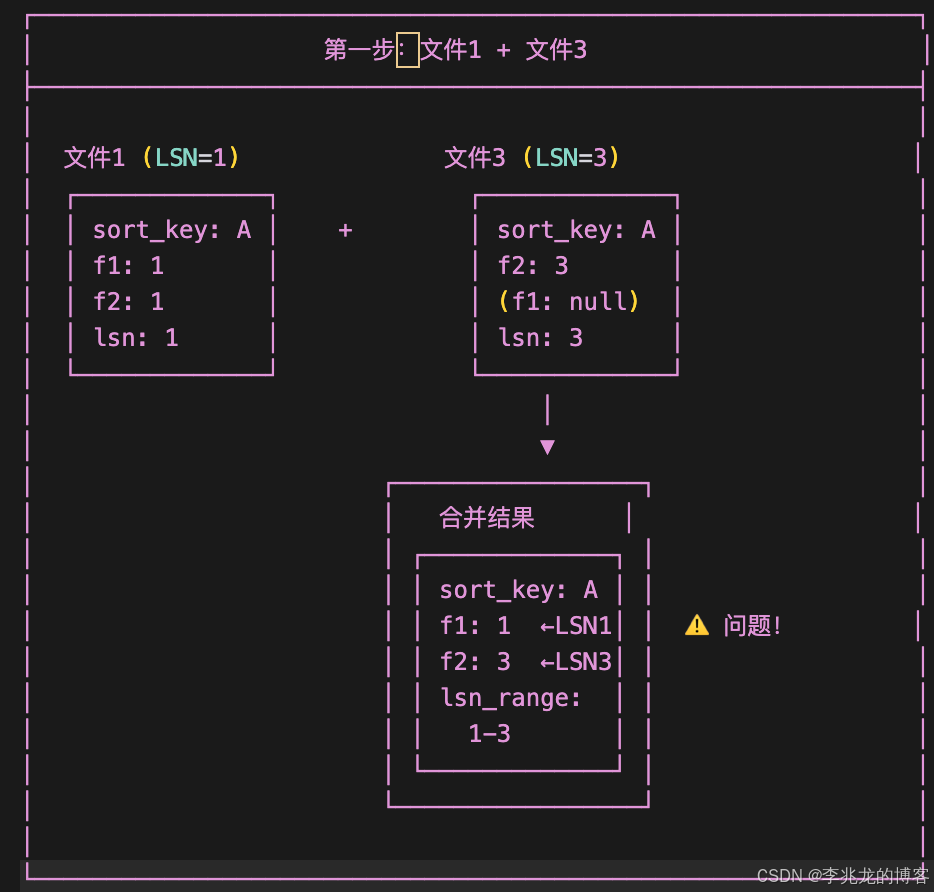
f1字段来自LSN=1的文件;f2字段来自LSN=3的文件。形成了LSN差值为1-3的混合记录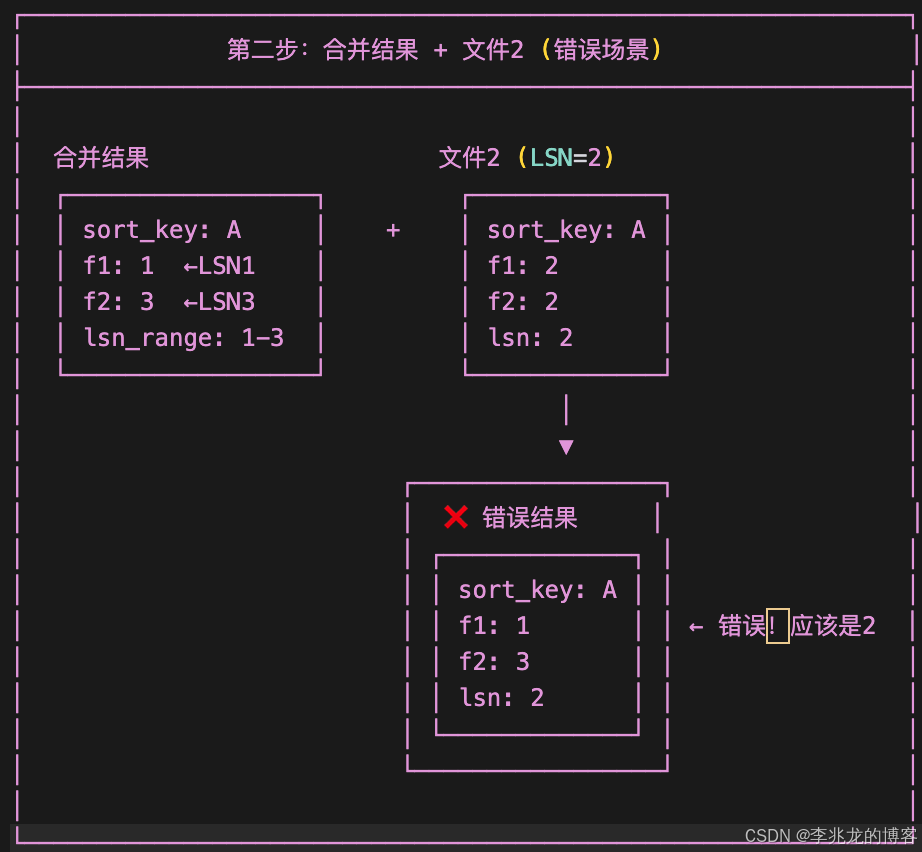
由于合并结果中f1和f2的LSN分别为1和3,都不等于文件2的LSN=2, 按照LSN覆盖规则,LSN=2无法覆盖LSN=3的f2字段, 但LSN=2应该覆盖LSN=1的f1字段,导致逻辑混乱。
正确的合并顺序如下: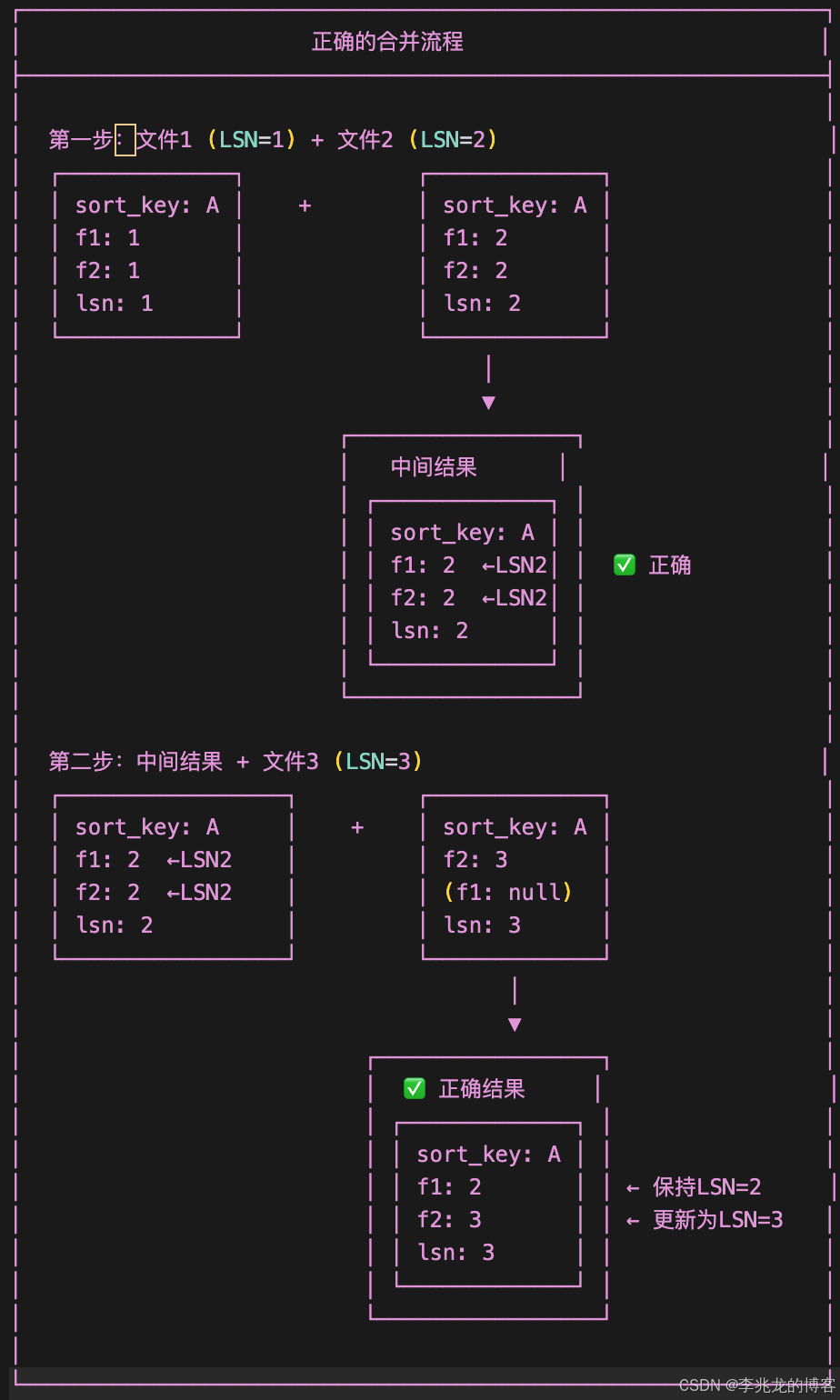
这要求我们再Compact的时候需要合并 LSN 临近的文件。
从实现的角度上讲,GrepTimedb和influxdb3.0的引擎是类似的,适用于时间线爆炸的场景,而influxdb1.x在时间线较少的场景下依然有较强的竞争力,Compaction的设计上也有区别。
时序数据库Compact最在意什么呢?不同的业务场景有不同的答案:TTL短的业务,写入量大,查询量大,存储量相对少,可以Tired+Level均衡读写;TTL长的业务,相对不是特别关心实时数据查询性能,TWCS冷shard可以理解为Level,所以活跃shard可以采用Tired这样的写入友好的策略;
回到实现的角度,自然Tiered是最简单的,因为Compaction的时候只需要维护LSN的区间有序就可以,compact的时候需要保证LSN连续的文件执行合并。influxdb1.x引入了一个Generations的概念,代表一次compact的输出,其文件名组成为000001-01.tsm,前面是Generations,后面是按文件大小切分的chunk,合并的时候只允许Generations连续的执行合并,这其实就是LSN相邻的文件合并,因为数据中没有存储LSN(TSI+SeriesFile+TSM,没有行的概念,无法支持行去重),只能在Compact上下功夫,这样的坏处自然就是事实数据查询性能差。
如果是Level策略,且只支持行级别去重,文件的行中存储一个LSN,这样Compact策略就比较自由,因为文件本身内部附带LSN信息,在合并的过程中建立WindowBuild内部可以基于LSN作去重,对于Compact的策略没有影响。
但是要是Level策略+支持Field级别去重,这就比较麻烦了,就像上面举的例子,事实上因为文件内部记录的是行级别的LSN,但是合并后可能存在不同LSN的数据被合并到一行,如果只记录一个LSN这会导致其中有些列的LSN被强行升级了,这会导致去重出现错误的数据覆盖。
这个时候有三种解决问题的思路:
第一种方法是简单的记录field级别LSN,在宽列场景下几乎不可用,因为存储空间占用太大
第二种方法是记录添加一个额外的列,记录出现Field覆盖时Field的LSN,这样可以大大减少冗余的LSN存储,毕竟列覆盖是极少数情况,但是需要给原始文件再加一列,因为Parquet等文件格式支持复杂类型,这样做也是可以的
第三种是Compact在选择文件时不仅仅考虑SortKey,而且需要考虑LSN的连续,具体的实现是在L0沉降L1时执行下述操作,是最优选择:
- L0为Tired,选择需要被合并的文件,要求LSN连续,计算其LSN区间,为区间1
- 选择L1中和L0文件SortKey重叠的文件,计算其LSN区间,为区间2
- 查找L1中区间1与区间2的空洞文件,计算其LSN区间,为区间3
- 三部分文件组成一个Compact任务,合并后更新Compact文件LSN区间,如果目标文件较大,可以拆分成多个,但是LSN区间是一样的
所以采用特殊的Compact策略可以实现低成本Field/Row Level 的Deduplicate。
Compact Execution Flow Based On Velox
这一节和文章题目没有关系,单纯的记录一下
基于执行引擎做Compact已经不是什么稀奇的事情了,毕竟一个好的执行引擎库基本上可以认为是AP的基础库了,而且Compact可以被抽象为算子的组合,在Velox中,我们可以把Compact抽象为TableScan+LocalMerge+Window+TableWrite的算子组合。
其实现的技术要点如下:
LocalMergeSource的管道分离流式读取
在Velox的LocalMerge操作中,PlanBuilder阶段传入的TableScan算子并不是直接转换为LocalMergeSource,而是通过管道分离和数据流重定向过程实现的。
管道 0 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource0
↓
管道 1 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource1
↓
管道 2 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource2
↓
管道 3 (Consumer Pipeline):
LocalMergeOperator ← LocalMergeSource0,1,2
数据生产阶段:每个TableScan管道中的数据流
TableScanOperator::getOutput()
↓
CallbackSink::addInput(RowVectorPtr input)
↓
consumer(input, future) // 这是LocalMergeSource的enqueue函数
↓
LocalMergeSource::enqueue(input, future)
↓
LocalMergeSourceQueue::enqueue(input) // 数据进入队列
数据消费阶段:LocalMerge管道中的数据流
LocalMerge::getOutput()
↓
TreeOfLosers::next() // 从多个source中选择最小值
↓
LocalMergeSource::next() // 从队列中取数据
↓
LocalMergeSourceQueue::next()
↓
返回排序后的RowVector
这样做有以下好处:
- 不同的并行性要求:生产者管道 (TableScan): 需要多线程并行处理,充分利用 I/O 带宽;消费者管道 (LocalMerge): 必须单线程执行,保证排序的正确性
- 数据流控制:生产者和消费者解耦,以支持背压控制(backpressure),生产者可以快速写入缓冲区,消费者按需读取
- 内存管理 :
- LocalMergeSource提供缓冲队列,支持流式处理,当缓冲区满时,生产者会被阻塞,防止内存溢出
- 可以基于缓冲队列实现精确的内存控制
- 容错性:管道间独立,单个管道失败不影响其他
- 生产者管道故障:不会直接影响消费者管道,可以独立重试
- 消费者管道故障:不会影响生产者的数据生成
- 部分失败处理:某个生产者失败时,其他生产者可以继续工作
基于LoserTree的归并排序
在Velox Window操作的LocalMerge场景中,需要处理多个已排序(基于提前指定的timestamp || measurement || tags作为排序key)的数据流并将其合并为一个全局有序的结果。
假设待排序列数为 N,待排元素总个数为 n,复杂度分析:
| LoserTree | 堆排序 | |
|---|---|---|
| 空间复杂度 | O(N) | O(N) |
| 单次调整时间复杂度 | O(n*logN) | O(2n*logN) |
| 整体排序完成时间复杂度 | O(logN) | O(2*logN) |
在调整LoserTree时,由于只需比较和更新对应叶子节点的路径上的节点,无需比较兄弟节点,因此在最坏情况下,单次调整败者树的时间复杂度为 O(logN)。
而堆排单次调整则需要比较兄弟节点,这里有常数级别的优化。
Window算子实现流式计算
认为每个窗口函数都通过一个 OVER 子句来运行,规定了 Window 函数的聚合方式。
窗口函数支持:
- 排名函数:ROW_NUMBER、RANK、DENSE_RANK
- 聚合函数:SUM、COUNT、AVG、MIN、MAX等作为窗口函数
- 分析函数:LAG、LEAD、FIRST_VALUE、LAST_VALUE等
RANGE框架边界类型:
- kUnboundedPreceding:之前的全部
- kPreceding:之前的N个
- kCurrentRow:当前行
- kFollowing:之后的N个
- kUnboundedFollowing:之后的全部
样例sql:
- sum(value) over (partition by partition_key order by order_key rows between unbounded preceding and current row) as running_sum
- avg(value) over (partition by partition_key order by order_key rows between 2 preceding and 2 following) as moving_avg
- row_number() over (partition by partition_key order by order_key) as rn
- c0, c1, c2, first_value(c0) OVER (PARTITION BY c1 ORDER BY c2 DESC NULLS FIRST {})
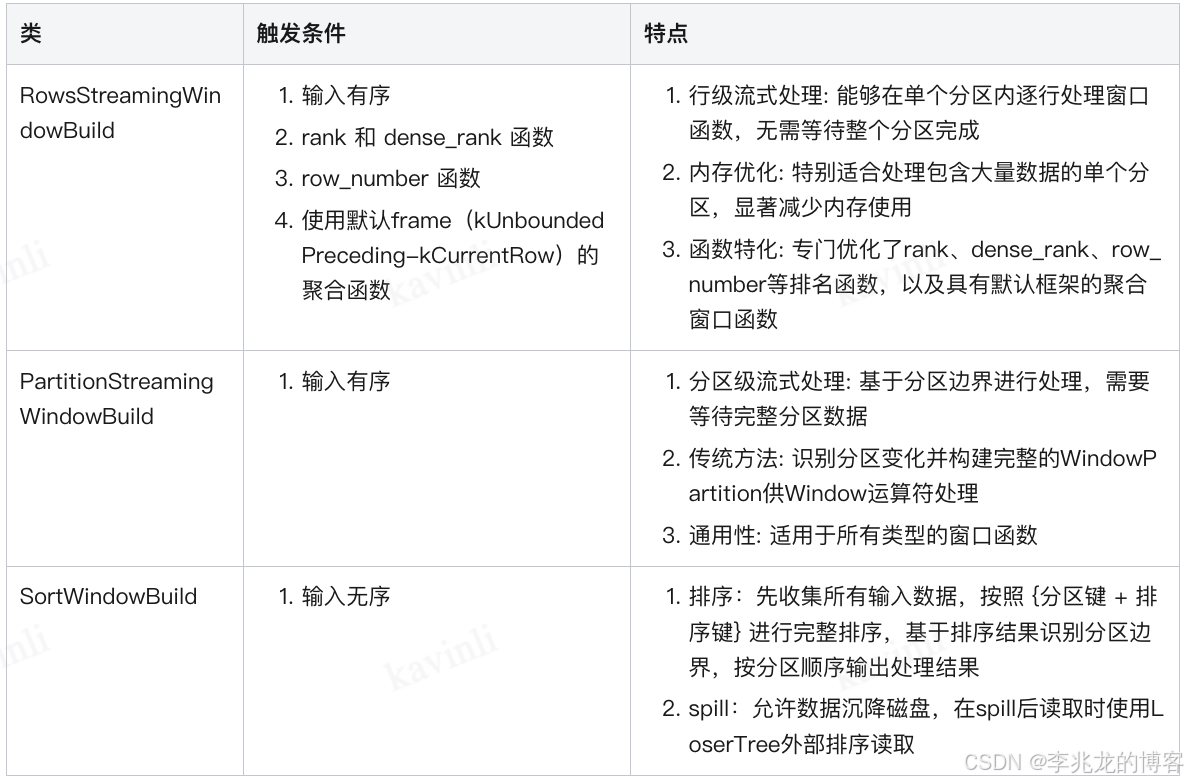
window的区间划分类有三种
TableWrite的多路流式写入
ATableWriter --> BHiveDataSink
B --> CParquetWriter
C --> DWriteFileSink
D --> ES3WriteFile/LocalFile
|
FInput Data --> A
A --> GaddInput
G --> HappendData
H --> Iwrite method
I --> JRow Group Buffer
J --> KFlush Policy Check
K --> LWrite Row Group
L --> MFooter Writing
RowGroup默认刷新大小:
- rowsInRowGroup: 1'024 * 1'024
- bytesInRowGroup: 128 * 1'024 * 1'024
Compact需要基于sortkey和文件大小在compact的过程中切分输出文件
TableWrite运算符目前无法做到,只能通过Partition和bucket来分区,这种情况在分区时采用hash来选择排序key所属的文件,而不是range,需要修改PartitionIdGenerator,实现range形式的partitionID分配。
结束语
想明白上述问题以后Compact就剩下工程问题了,需要聚焦在Compact任务的调度(分池,并发限制),与Catalog的交互,Garbage Collector的设计。