颠覆传统!单样本熵最小化如何重塑大语言模型训练范式?
大语言模型(LLM)的训练往往依赖大量标注数据与复杂奖励设计,但最新研究发现,仅用1条无标注数据和10步优化的熵最小化(EM)方法,竟能在数学推理任务上超越传统强化学习(RL)。这一突破性成果或将改写LLM的训练规则,快来了解这场效率革命!
论文标题
One-shot Entropy Minimization
来源
arXiv:2505.20282v2 cs.CL + https://arxiv.org/abs/2505.20282
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大语言模型(LLM)的训练后优化(post-training)近年来发展迅猛,DeepSeek-R1、Kimi-K1.5和OpenAI o-series等模型展现出卓越的推理能力。然而,传统强化学习(RL)方法在应用中面临显著挑战:其不仅需要大量高质量标注数据,还需精心设计规则化奖励函数以最大化优势信号,同时防范"奖励黑客"问题。与之形成鲜明对比的是,熵最小化(EM)作为完全无监督方法,在训练效率与便捷性上具备潜在优势。本研究通过训练13,440个LLM,系统验证了EM仅用单条无标注数据和10步优化即可超越传统RL的可能性,为LLM训练后优化范式提供了全新思路。
研究问题
1. 数据效率低下:RL需数千条标注数据,而无监督方法的潜力尚未充分挖掘。
2. 训练复杂度高:RL需设计复杂奖励函数,且易出现"奖励黑客"(reward hacking)问题。
3. 收敛速度缓慢:RL通常需数千步训练,而高效优化方法亟待探索。
主要贡献
1. 单样本高效优化:提出One-shot Entropy Minimization(单样本熵最小化)方法,仅用1条无标注数据+10步优化,性能超越传统RL(如在Qwen2.5-Math-7B模型上,MATH500数据集得分提升25.8分)。
2. 理论机制创新:揭示EM与RL的核心目标一致(释放预训练模型潜力),但通过"对数几率右移"(logits shift)机制驱动模型行为,与RL的左移方向相反,更利于生成高概率正确路径。
3. 关键因素解析:发现温度参数(temperature)是训练与推理的核心变量,EM在推理时温度趋势与RL完全相反(EM随温度升高性能下降,RL反之)。
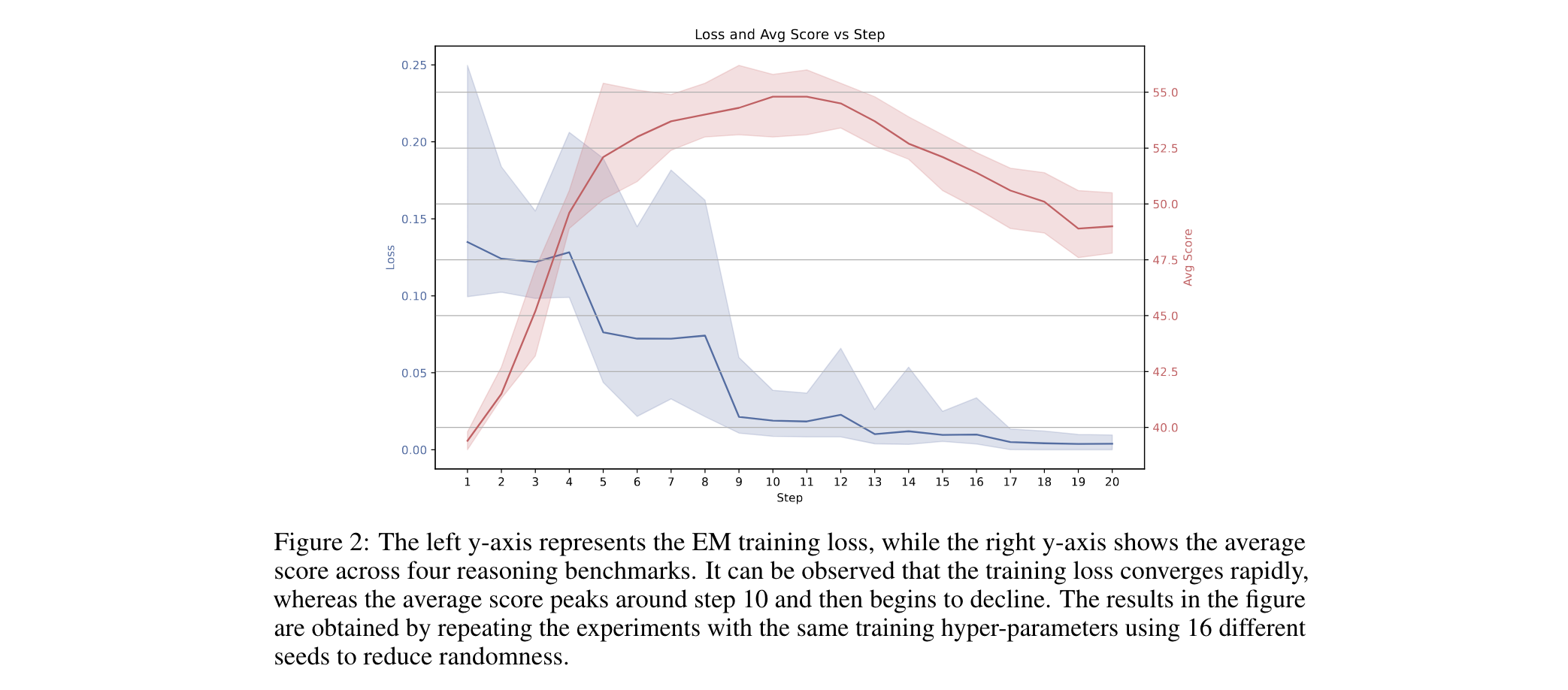
3. 范式重新定义:证明EM是"分布塑形工具"而非学习方法,其效果在10步内即可完成,后续训练 loss 下降与性能提升解耦。
方法论精要
1. 核心算法/框架
熵最小化算法:通过最小化生成token的条件熵 H t H_t Ht,迫使模型对预测更自信,仅计算生成token(非prompt部分)的熵。

数据选择策略:基于"方差筛选"选择最具不确定性的输入------计算模型在k次采样中的"pass@k准确率方差",优先选择方差最高的prompt(如NuminaMath数据集中的风力压力计算问题)。


2. 关键参数设计原理
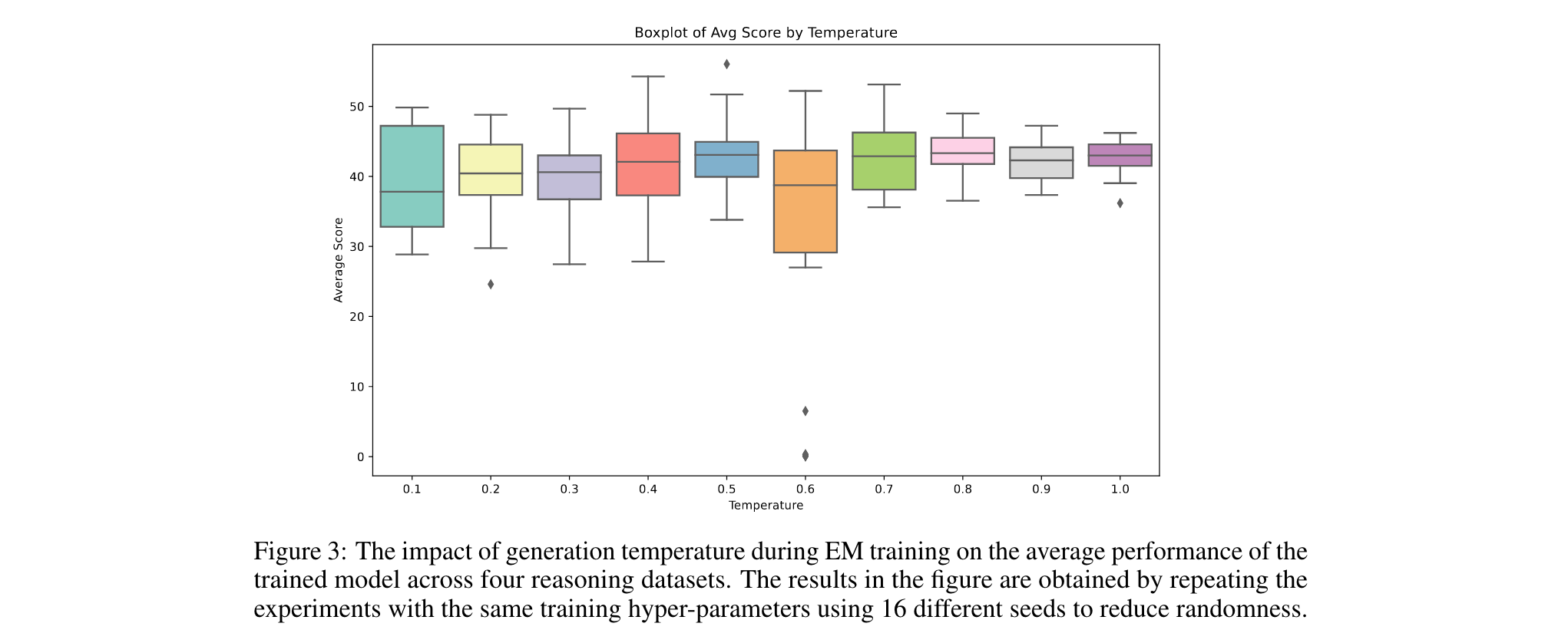
温度参数0.5:训练时温度过低会使分布过窄,过高则增加随机性,0.5时性能方差最大,易获峰值表现。
学习率 2 × 10 − 5 2×10^{-5} 2×10−5:10步快速收敛的最优选择,过大易导致过自信,过小则收敛缓慢。
3. 创新性技术组合
无监督+方差筛选:无需标注数据,仅通过模型自身预测的不确定性筛选有效输入,形成"熵敏感"训练信号。
对数几率分析:EM使logits分布右偏(skewness提升至1.54),集中概率质量于正确路径,而RL导致左偏(skewness降至0.02)。
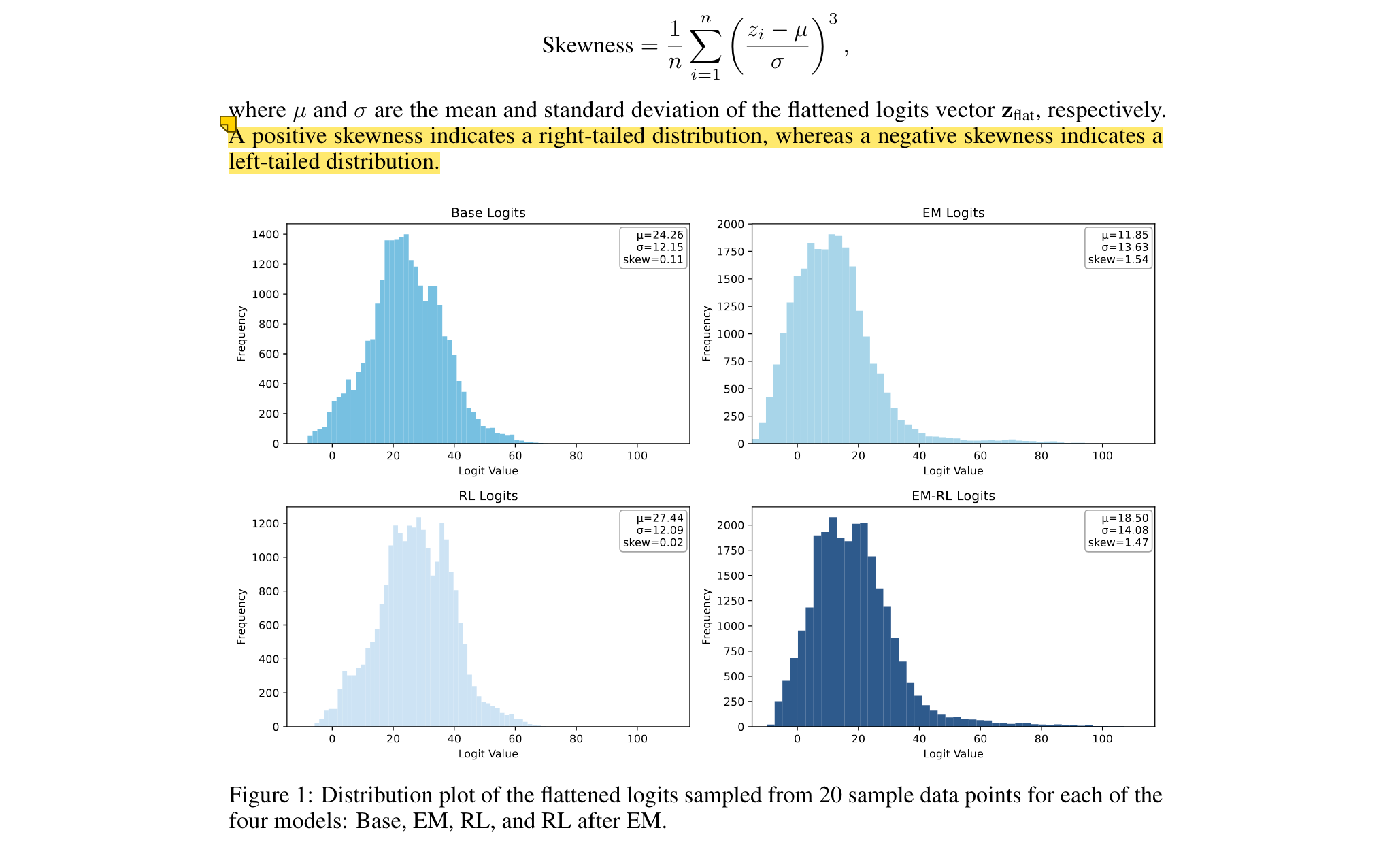
4. 实验验证方式
数据集:数学推理基准(MATH500、Minerva Math、Olympiad Bench、AMC23),以及LLaMA-3.1-8B、Qwen2.5系列等多模型测试。
基线方法:OpenReasoner-Zero、SimpleRL-Zoo、Prime-Zero等RL模型,对比其在数据量(129k-230k)与训练步数(240-4000步)上的劣势。
实验洞察
1. 性能优势
- Qwen2.5-Math-7B模型:EM 1-shot使MATH500从53.0提升至78.8(+25.8),Minerva Math从11.0至35.3(+24.3),平均提升24.7分,接近Prime-Zero-7B等SOTA模型。
- 跨模型泛化:在Qwen2.5-7B-Instruct模型上,EM将平均准确率从43.12%提升至44.5%,且对弱模型(LLaMA-3.1-8B)也有29.6%→42.2%的提升。
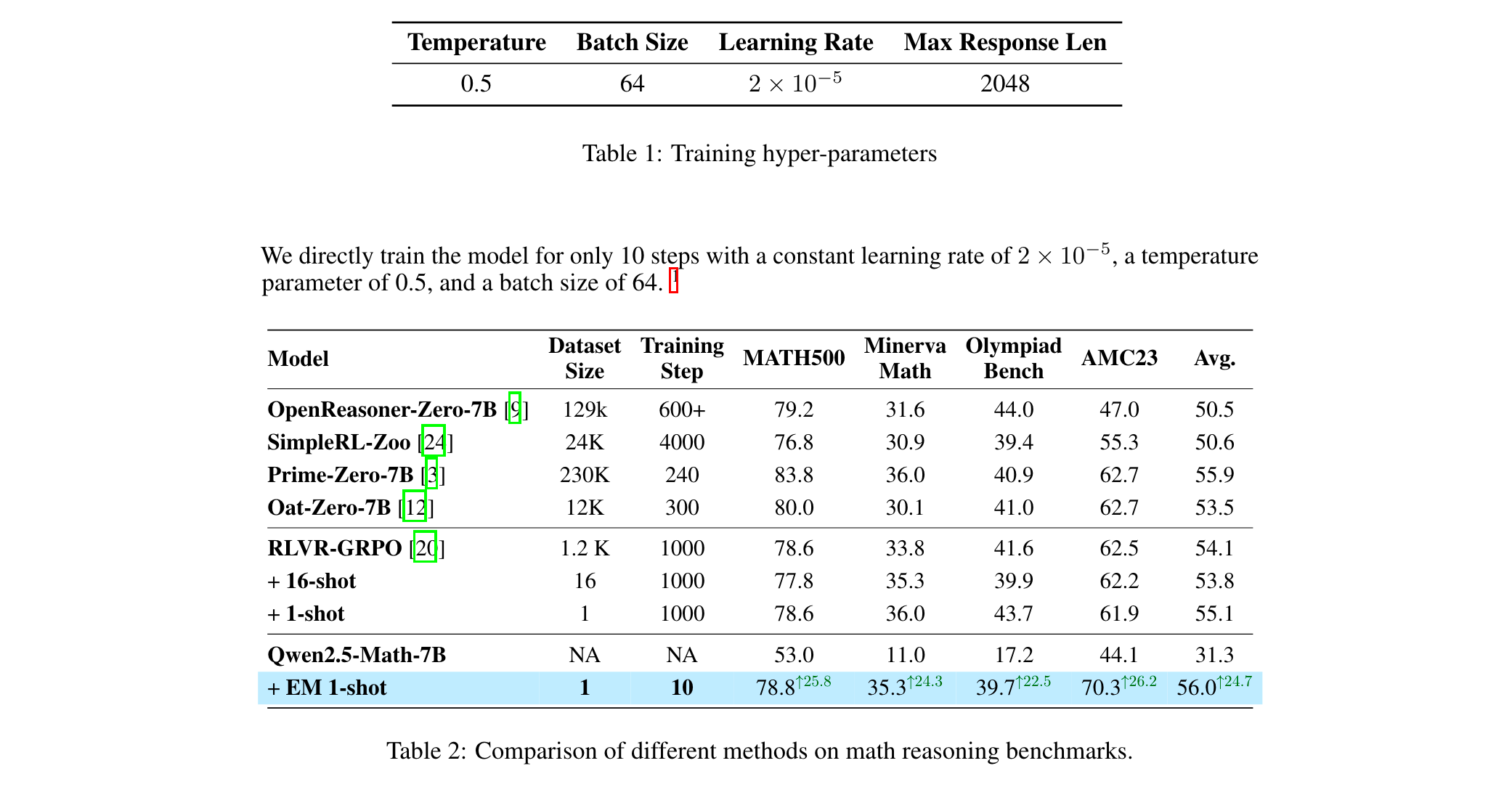
2. 效率突破
- 训练步数:仅10步收敛,较RL的数千步提升数百倍;单样本训练速度比RL快3个数量级。
- 数据效率:1条数据效果超过RL的数千条,如EM 1-shot在AMC23上得分70.3,超越SimpleRL-Zoo(24k数据+4000步)的55.3分。
3. 消融研究
- 温度影响:训练时温度0.5性能最佳,推理时温度与性能负相关(温度1.0时EM平均得分下降5%,RL上升3%)。
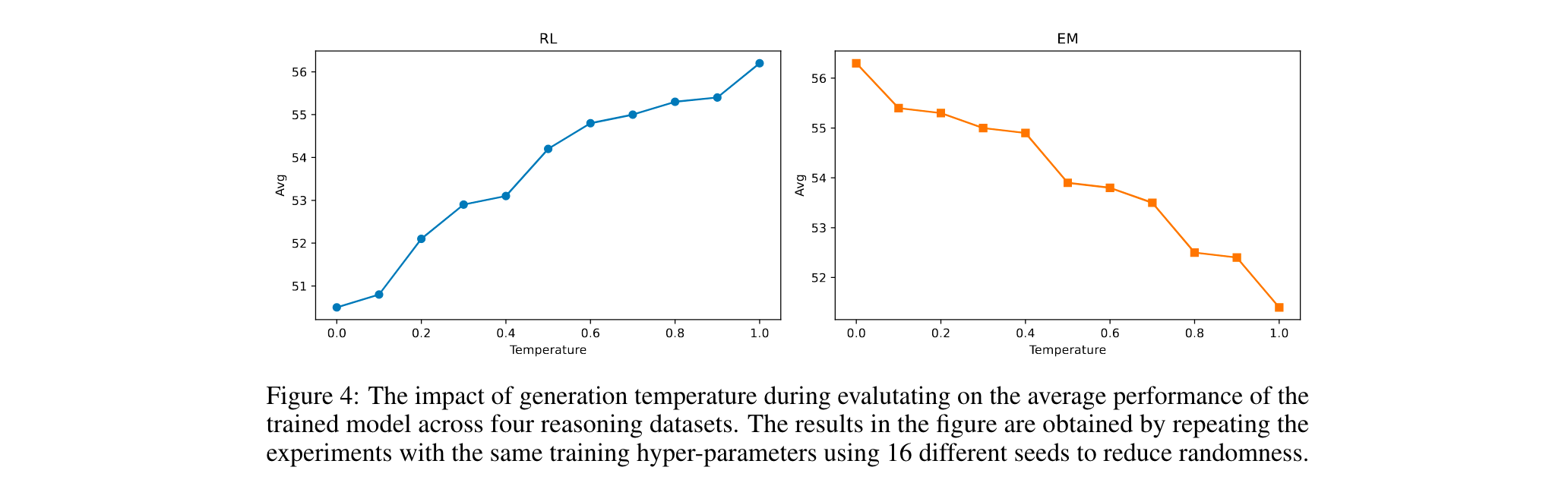
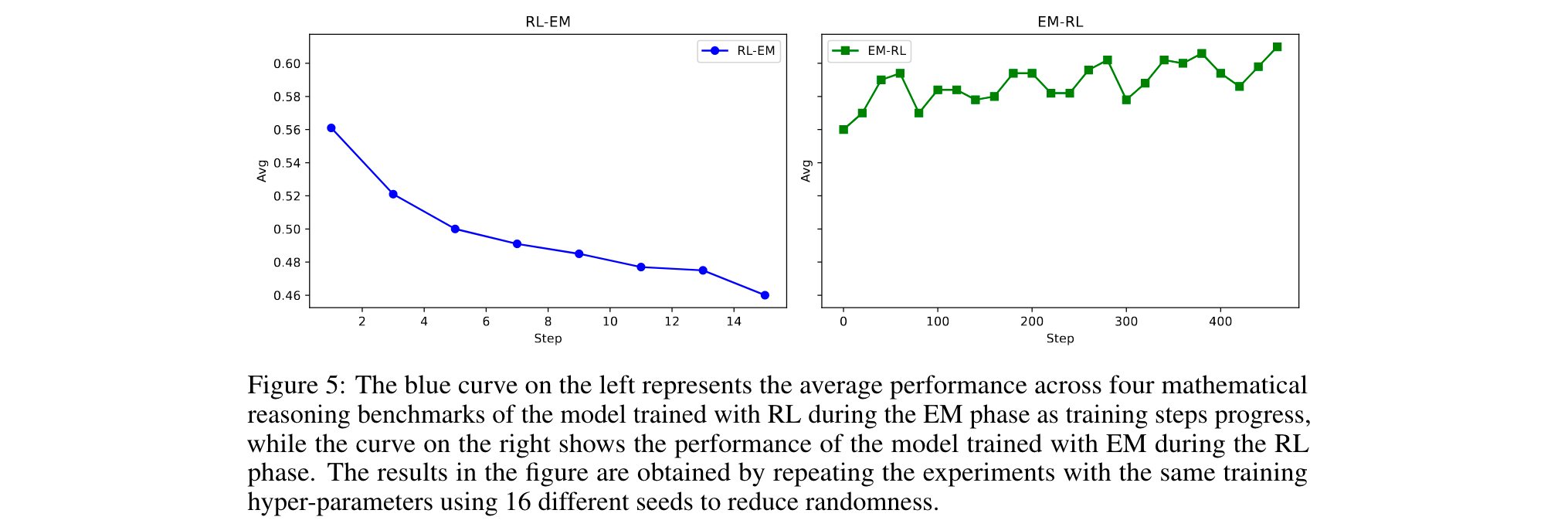
- 训练顺序:EM先于RL可提升性能(如Qwen2.5-Math-7B+EM+RL在AMC23得70.3),而RL后接EM会导致性能下降(如SimpleRL-Zoo+EM得分降低5.9分)。
Future Works
1. 稳定化训练机制开发:针对EM训练中存在的随机性问题(相同设置下不同种子得分差异可达2倍),探索自适应早停策略或正则化方法,如基于损失-性能解耦点的动态终止准则,降低温度参数敏感性,构建更鲁棒的训练框架。
2. 跨领域泛化探索:当前EM主要验证于数学推理任务,未来将拓展至对话生成、代码补全、科学文献总结等多模态场景,研究序列级熵优化(如全句语义熵)与任务特定先验融合技术,验证其作为通用分布塑形工具的普适性。
3. 混合优化范式构建:探索EM与监督微调(SFT)、RL的协同机制,例如设计"EM预塑形→SFT精调→RL校准"的流水线,或开发动态熵-奖励联合优化目标,平衡模型自信度与外部对齐要求,解决RL后接EM导致的"对齐税"问题。