2025年,各种会推理的AI模型如雨后春笋般涌现,比如ChatGPT o1/o3/o4、DeepSeek r1、Gemini 2 Flash Thinking、Claude 3.7 Sonnet (Extended Thinking)。
对于工程上一些问题比如复杂的自然语言转sql,我们可能忍受模型的得到正确答案需要更多时间,但是准确度一定要高。那么我们就可以考虑用文中的方法(模型推理能力)得到更高精确度。
什么是推理能力
简单说,就是模型在回答问题时会先输出一大段推理过程,然后才给出最终答案。
下图我们分别在deepseek的官网使用不带深度思考的与带深度思考(DeepSeek-R1)的模型对北京是中国的首都吗?
可以看到当我们使用深度思考模型AI不会直接回答,而是会先来一段内心独白再去回答,这中间的内心独白就叫做推理。
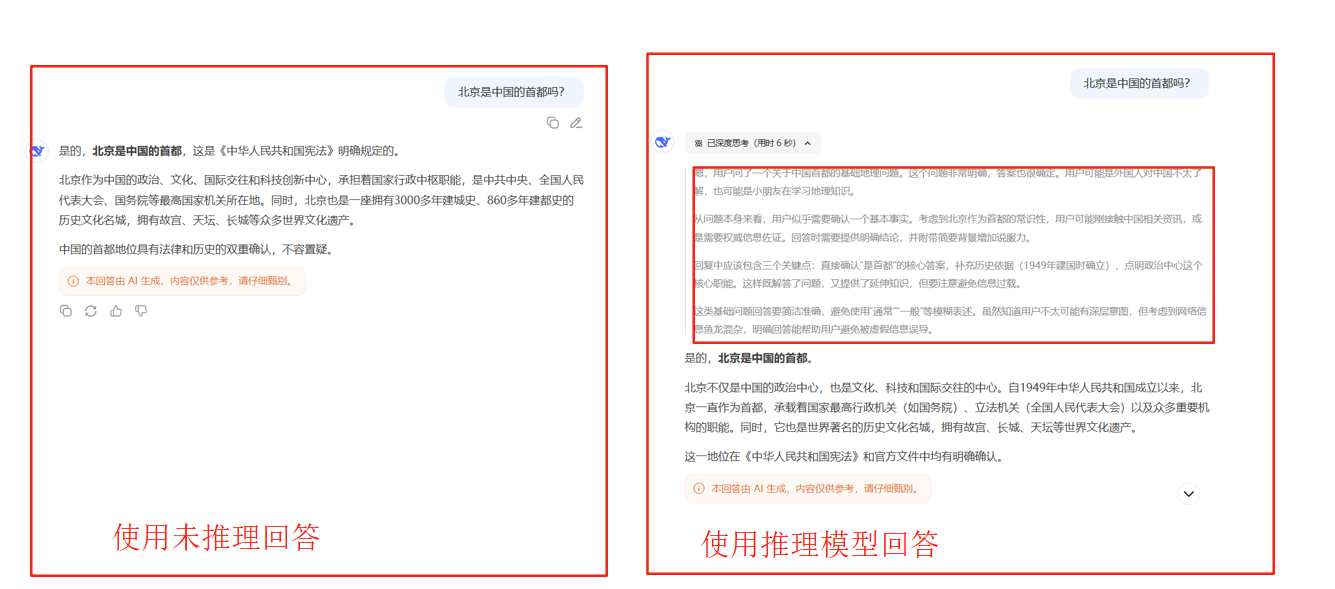
推理能力类似早先年间计算机视觉领域的可视化模型输出的过程。推理能力是某些大模型本身就存在的能力,我们能达到的推理效果是因为我们通过训练或提示词解码了这一过程。

让LLM实现推理能力的四个方法
Chain-of-Thought 提示词并不是对所有LLM都通用,比如LLama3不适用。
我们在平台上使用的DeepSeek-R1就是结合了本文提到的四种方法实现的
1. Chain-of-Thought
CoT方法是一种提示词引导,分为Short CoT和Long CoT代表性的Supervised CoT,Short CoT又可分为few-shot CoT和 zero-shot CoT。
| 类别 | 方法名称 | 实现方式 | 示例 |
|---|---|---|---|
| Short CoT | Few-shot CoT | 提供示例引导 | 给出2-3个完整的问题-思考-答案示例,然后提问 |
| Short CoT | Zero-shot CoT | 简单提示引导 | 在问题后加上"让我们一步步思考" |
| Long CoT | Supervised CoT | 详细流程指导 | 编写复杂提示词,明确指定思考流程、验证步骤、输出格式等 |
few-shot CoT是给一些范例引导模型思考,下图展示了few-shot CoT的过程。zero-shot CoT是在问题后面加上一步步来思考。
zero-shot CoT是在问题后面加上让我们一步步思考,下图展示了zero-shot CoT的过程。

Supervised CoT通过编写详细的提示词来指导模型的思考流程,下图展示了Supervised CoT的过程:


2. 多次采样
该方法核心是既然一次做不对,那就多试几次。由此引出了两类工程问题:
- 如何让模型尝试多次?(通常尝试16+次)
- 如何在多次生成的答案筛选正确答案
产生多个答案
- 问题难度决定策略 :
- 简单问题:纯串行效果最好
- 困难问题:需要并行+串行的平衡
- 中等问题:理想比例介于两者之间
- 计算预算影响 :
- 小预算:串行采样更高效
- 大预算:需要平衡分配避免过度优化
- 互补性 :
- 并行采样提供全局搜索能力
- 串行采样提供局部优化能力
- 两者结合能够充分利用测试时计算资源
1. 并行采样(Parallel Sampling)
核心思想:同时生成多个完全独立的解答
具体做法:
- 给定同一个问题,让模型独立生成N个不同的回答
- 每次生成都是从头开始,互不依赖
- 通过设置temperature > 0来引入随机性,确保每次生成的答案都不完全相同
2. 串行采样(Sequential Sampling)/ 迭代修正
核心思想:基于前一次的尝试来改进下一次的回答
具体做法:
- 先生成一个初始答案
- 将这个答案作为上下文,让模型基于此生成改进版本
- 重复这个过程,每次都在前面答案的基础上进行优化
3. 混合策略:并行+串行
最佳策略往往是两种方法的结合
具体做法:
- 将计算预算分配给并行和串行两种采样
- 比如用一部分预算生成几个独立的起始点
- 然后从每个起始点进行串行改进
适应性分配:
- 简单问题:更多串行采样(因为初始答案通常在正确轨道上)
- 困难问题:更多并行采样(需要探索不同的解题策略)
- 中等难度:平衡分配
筛选正确答案
1. Majority Vote:群众的智慧
最直观的方法是投票机制:看哪个答案出现次数最多就选哪个。
实验数据显示了一个很有趣的现象:Majority Vote的效果提升并不是线性的。
- 前期快速上升:从1次尝试到16次,准确率提升很明显
- 中期平缓增长:从16次到64次,提升变得温和
- 后期趋于饱和:超过128次后,基本不再提升
这个曲线形状很符合直觉。想象一下,如果正确答案出现的概率是30%,那么:
- 试1次:30%概率对
- 试5次:如果正确答案出现2次以上就赢,概率大大提升
- 试50次:如果正确答案真的占30%,那肯定会胜出
但如果模型本身对某类问题就是"系统性地理解错误",那试再多次也没用------每次都会用错误的方法,只是错得稍有不同而已。
实际操作中,你需要在提示词里告诉模型把最终答案放在特定标签中(比如<answer></answer>),这样才能方便地统计各个答案的出现频率。
2. Best of N:专业裁判来评分
你可以直接再加一个模型,用提示词让模型判断它做得对不对。
更高级的做法是训练一个专门的验证器来给答案打分,然后从N个候选中选出得分最高的。这类似于建立一个机器学习模型,我们需要准备数据集,然后得到这样的模型
训练验证器的方法很巧妙:
- 准备一批有标准答案的题目
- 让语言模型生成大量不同的解答
- 根据最终答案的对错来标注:正确答案标记为1,错误答案标记为0
- 用这些数据训练验证器
这样就得到了一个"专业裁判",能够识别哪些答案更可能正确。
3. Beam Search:智能路径探索
如果说Best of N是"海选后评判",那么Beam Search就是"边走边筛选"的智能策略。它不等到最后才评判,而是在解题的每一步都进行筛选,只保留最有希望的路径继续探索。
核心思想:把解题过程看作一棵树,每一步都是树的一个分支,我们只保留最promising的几条路径继续往下走。
具体流程:
- 生成多个起始步骤:比如生成8个不同的第一步解法
- 过程验证器评分:用训练好的验证器给每个步骤打分
- 保留最优路径:只保留得分最高的4个步骤(这个4就是beam width)
- 继续扩展:从这4个步骤分别生成下一步,又得到新的候选
- 重复筛选:再次用验证器评分,保留最好的4个
- 直到完成:重复这个过程直到得到最终答案
关键组件 - 过程验证器 :
与普通验证器不同,过程验证器不需要看到完整答案就能判断当前步骤的质量。它就像一个经验丰富的老师,看到学生解题的前几步就能判断这个思路靠不靠谱。
训练过程验证器的巧妙方法:
- 从某个中间步骤开始,让原模型继续解题多次(比如20次)
- 统计从这个步骤开始最终得到正确答案的比例
- 这个比例就是该步骤的"质量分数"
- 训练验证器学会预测这个分数
比如从某个step1开始,20次尝试中有14次得到正确答案,那这个step1的质量分数就是0.7。
实际操作技巧:
请逐步解决这个数学问题
每个步骤用<step>和</step>标签包围
示例:
<step>分析:这是一个几何问题...</step>
<step>计算:根据勾股定理...</step>让模型生成到</step>就停止,这样可以精确控制每次只生成一步,然后用验证器评估这一步的质量。
3. 模仿学习(Imitation Learning)
传统的训练数据只包含问题和答案,但在这种方法中,我们的训练数据还包含了完整的推理步骤。
比如说,原来的训练数据是:
- 问题:小明有3个苹果,小红给了他2个,他现在有几个苹果?
- 答案:5个
现在的训练数据变成:
- 问题:小明有3个苹果,小红给了他2个,他现在有几个苹果?
- 推理过程:小明原本有3个苹果,小红又给了他2个苹果,所以总共是3+2=5个苹果
- 答案:5个
这里遇到的最大问题是:推理过程的数据从哪里来?让人工去标注这些推理步骤实在太耗时耗力了。
聪明的解决方案是:让语言模型自己生成推理过程。市面上已经有很多强大的推理模型,比如GPT-o1、Claude等。最简单的方法就是知识蒸馏:
- 用一个强大的"老师"模型生成推理过程和答案
- 让你的"学生"模型直接学习这些数据
- 完成训练
4. 强化学习
DeepSeek团队首先创造了一个叫R1-0的模型,这是一个完全用强化学习训练出来的版本。他们以DeepSeek-V3-Base作为基础模型,用两个主要的奖励信号进行训练:
- 正确率奖励:答对问题得到正向反馈
- 格式奖励 :要求模型生成特定的思考标记(think token)
实验结果表明,这种纯粹的强化学习方法确实有效。
真正的DeepSeek-R1:复杂的混合训练流程
R1-0效果单次尝试的正确率可以接近GPT-o1,但是它有一个致命问题:生成的推理过程几乎无法阅读。
官方发布的DeepSeek-R1对R0有了更进一步提升,从而使得其推理过程能正确被阅读,且效果超过o1。
R1使用的方法其实就是融合了前面提到的四种方法。
第一步:推理数据人工标注
首先,研究团队用R1-0来生成带有推理过程的训练数据。但由于R1-0的输出质量堪忧,他们投入了大量人力去修改和改写这些推理过程。
人工标注员需要将模型生成的那些难以理解的推理过程,改写成人类可以阅读的版本。
除了改写R1-0的输出,他们还使用了CoT:
- 用少样本提示(Few-shot CoT)让其他模型生成推理数据
- 使用提示工程让模型生成更详细、包含反思和验证的答案
这一步做完后,就可以训练一个模型了。我们把这个训练好的模型称为模型A
第二步:改进的强化学习
接下来,他们对模型A进行强化学习,但这次的强化学习有所改进。除了要求高正确率,还增加了一个重要约束:语言一致性奖励。
如果模型在推理过程中始终使用同一种语言(比如全程英文或全程中文),就会获得额外奖励。这样可以避免模型在推理中频繁切换语言,提高可读性。
虽然这个约束会轻微降低模型的正确率,但研究团队认为这是值得的权衡。
第三步:扩展任务范围
有了模型B之后,训练的重点从数学和编程扩展到各种不同类型的任务。他们让模型B对各种问题生成推理过程和答案。
由于很多任务没有标准答案,他们使用DeepSeek-V3作为验证器来判断答案质量。同时,他们还设置了一些过滤规则,去除那些质量较差的推理过程,比如:
- 使用多种语言混杂的过程
- 过于冗长的推理
- 包含不必要代码的过程
第四步:大规模模仿学习(模型C)
这一步是自动化的,因此可以生成更多数据。他们收集了60万条推理数据,同时为了防止模型遗忘之前学到的知识,还加入了20万条自我输出数据(让模型学习自己之前的优质输出)。
用这80万条数据对DeepSeek-V3-Base进行模仿学习,得到模型C。
第五步:最终的强化学习
最后,对模型C进行一轮强化学习,重点提升模型的安全性和有用性,最终得到我们使用的DeepSeek-R1。