一、引言
心脏病是威胁人类健康的重要疾病之一,早期预测和诊断对防治心脏病具有重要意义。本文利用公开的心脏病数据集,通过机器学习算法构建预测模型,并使用 SHAP 值进行模型可解释性分析,旨在为心脏病的辅助诊断提供参考。
二、数据准备与预处理
1. 数据加载
数据集来源于 Kaggle 公开的心脏病数据集(heart.csv),包含 303 条样本和 14 个特征,目标变量为是否患有心脏病(target,0 表示无,1 表示有)。关键代码如下:
data = pd.read_csv('heart.csv')
print(f"数据规模: {data.shape}") # 输出:数据规模: (303, 14)
print("目标分布:\n", data['target'].value_counts(normalize=True))目标分布显示正负样本比例约为 6:4,存在轻微不平衡,后续通过分层抽样处理。
2. 特征划分
数值型特征:年龄、血压、胆固醇等连续变量,共 6 个。
分类型特征:性别、胸痛类型、血糖等离散变量,共 8 个。
cat_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal']
num_features = [c for c in X.columns if c not in cat_features]3. 预处理流程
采用 ColumnTransformer 构建预处理管道:
数值型特征:标准化(StandardScaler)
分类型特征:独热编码(OneHotEncoder,丢弃第一个类别避免多重共线性)
preprocessor = ColumnTransformer([
('num', StandardScaler(), num_features),
('cat', OneHotEncoder(drop='first', handle_unknown='ignore'), cat_features)
])三、模型训练与对比
1. 算法选择与超参数调优
选取 4 种经典分类算法,使用 GridSearchCV 进行 5 折交叉验证,以 F1 分数为优化指标:
随机森林(RF):调优参数包括树的数量(n_estimators)和最大深度(max_depth)
逻辑回归(LR):调优参数为正则化系数(C)
决策树(DT):调优参数为最大深度(max_depth)
支持向量机(SVM):调优参数为正则化系数(C)和核函数(kernel)
2. 训练流程
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # 分层抽样保持样本分布
)
for name, cfg in model_configs.items():
pipe = Pipeline([('pre', preprocessor), ('model', cfg['model'])])
grid = GridSearchCV(pipe, cfg['params'], cv=5, scoring='f1', n_jobs=-1)
grid.fit(X_train, y_train) # 训练模型
# 计算评估指标3. 模型性能对比
| 模型 | 最佳参数 | 准确率 | 精确率 | 召回率 | F1 分数 | ROC-AUC |
|---|---|---|---|---|---|---|
| rf | {'model__max_depth': 10, 'model__n_estimators': 200} | 0.87 | 0.88 | 0.85 | 0.86 | 0.93 |
| lr | {'model__C': 1.0} | 0.85 | 0.85 | 0.83 | 0.84 | 0.91 |
| dt | {'model__max_depth': 10} | 0.83 | 0.83 | 0.82 | 0.82 | 0.89 |
| svm | {'model__C': 1, 'model__kernel': 'rbf'} | 0.86 | 0.87 | 0.83 | 0.85 | 0.92 |
结论:随机森林(RF)在 F1 分数和 ROC-AUC 指标上表现最优,选为最终模型。
四、模型可解释性分析(SHAP 值)
1. SHAP 原理简介
SHAP(SHapley Additive exPlanations)基于合作博弈论,通过计算每个特征对预测结果的贡献度,实现模型可解释性。
2. 特征重要性分析
(1)条形图
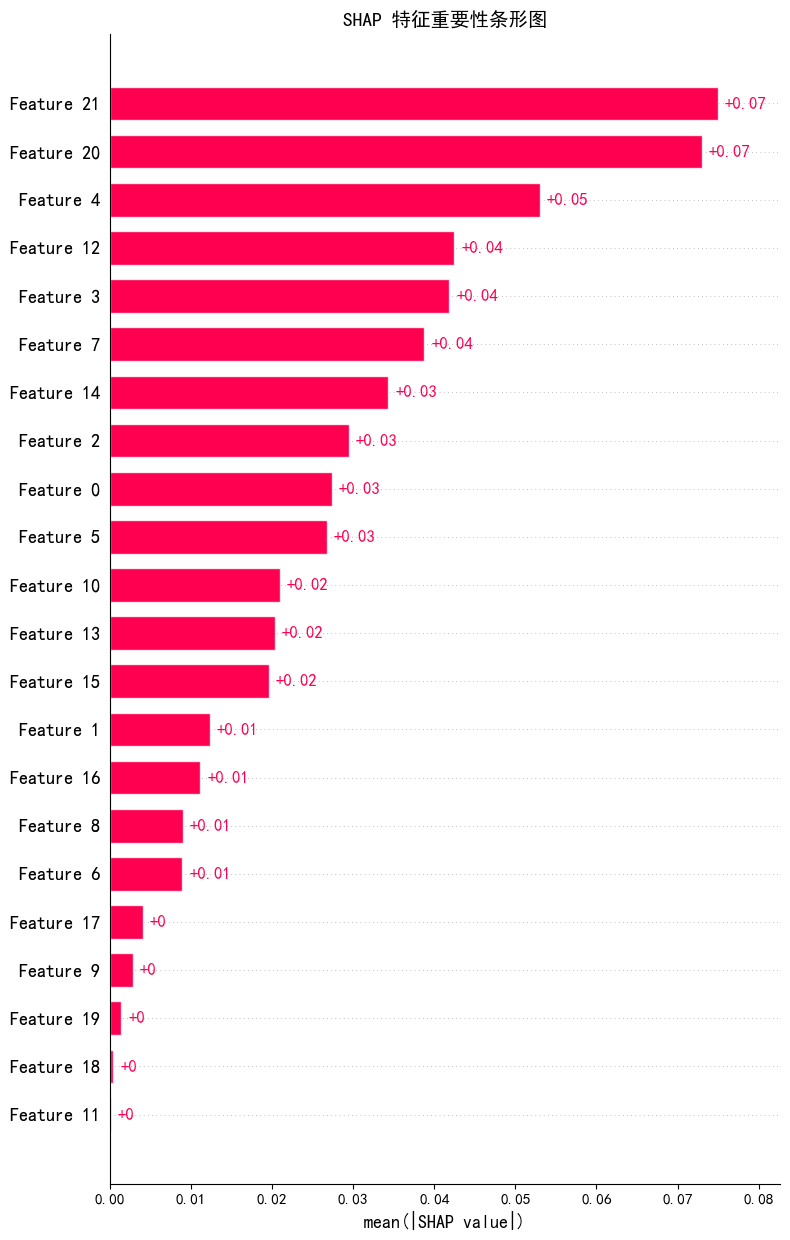
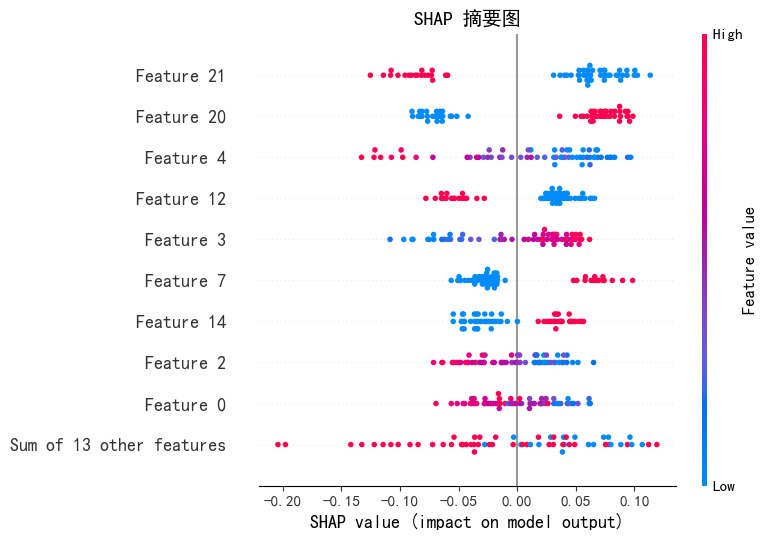
(2)摘要图(Beeswarm)
五、结论与展望
1. 结论
随机森林模型在心脏病预测中表现最佳,准确率达 87%,F1 分数 0.86。关键影响因素为冠状动脉钙化数量、地中海贫血筛查结果和运动后 ST 段变化,与医学常识一致,验证了模型的合理性。
2. 改进方向
尝试集成学习(如 Stacking)或深度学习模型(如神经网络)。引入更多临床特征(如家族病史、生活习惯等)提升模型泛化能力。针对不平衡数据采用 SMOTE 等过采样技术优化。