摘要 :基于LLM的代理在越来越多的软件工程(SWE)任务中显示出有前景的能力。 然而,推进这一领域面临着两个关键挑战。 首先,高质量的训练数据稀缺,尤其是反映现实世界软件工程场景的数据,在这些场景中,代理必须与开发环境交互,执行代码并根据其行为结果调整行为。 现有的数据集要么局限于一次性的代码生成,要么包含小型的、人工策划的交互式任务集合,缺乏规模和多样性。 其次,缺乏新鲜的交互式SWE任务会影响对快速改进模型的评估,因为静态基准会因污染问题而迅速过时。 为了解决这些局限性,我们引入了一种新颖的、自动化的、可扩展的管道,以从不同的GitHub存储库中连续提取真实的交互式SWE任务。 使用这个流水线,我们构建了SWE-rebench,这是一个包含21000多个基于Python的交互式SWE任务的公共数据集,适用于大规模SWE代理的强化学习。 此外,我们使用SWE-rebench方法收集的新任务持续供应,为代理软件工程构建一个无污染的基准。我们比较了各种LLM在这个基准上的结果和SWE-bench Verified的结果,并表明一些语言模型的性能可能因污染问题而膨胀。Huggingface链接:Paper page,论文链接:2505.20411
研究背景和目的
研究背景
近年来,基于大型语言模型(LLMs)的代理在软件工程(SWE)任务中展现出令人瞩目的能力,涵盖了代码生成、调试、自动化开发流程等多个方面。随着这些能力的不断提升,研究者们开始致力于创建能够与真实代码库和开发环境交互的LLM驱动代理,通过执行动作并接收反馈来执行复杂任务。然而,这一领域的进步面临着两大关键挑战。
首先,高质量的训练数据极为稀缺。特别是那些能够反映真实世界软件工程场景的数据,在这些场景中,代理不仅需要生成代码,还必须与开发环境进行交互,执行代码,并根据执行结果调整其行为策略。现有的数据集要么仅限于一次性代码生成任务,要么包含的是小规模、人工策划的交互式任务集合,这些数据集在规模和多样性上都存在明显不足,难以支撑复杂代理的训练需求。
其次,缺乏新鲜的交互式SWE任务也制约了模型的评估效果。由于软件工程领域的快速发展,静态基准测试集很快就会因为数据污染问题而过时。新模型在训练过程中可能会接触到测试集中的数据,导致评估结果失真,无法准确反映模型的真实性能。
研究目的
为了解决上述挑战,本研究旨在开发一个新颖、自动化且可扩展的管道,用于从多样化的GitHub存储库中持续提取真实的交互式SWE任务。通过这一管道,我们构建了SWE-rebench数据集,该数据集包含超过21,000个基于Python的交互式SWE任务,特别适合用于大规模SWE代理的强化学习训练。此外,我们还利用SWE-rebench方法收集的新任务构建了一个无污染的基准测试集,以促进对LLM驱动软件工程代理的透明和公平评估。
研究方法
数据收集与预处理
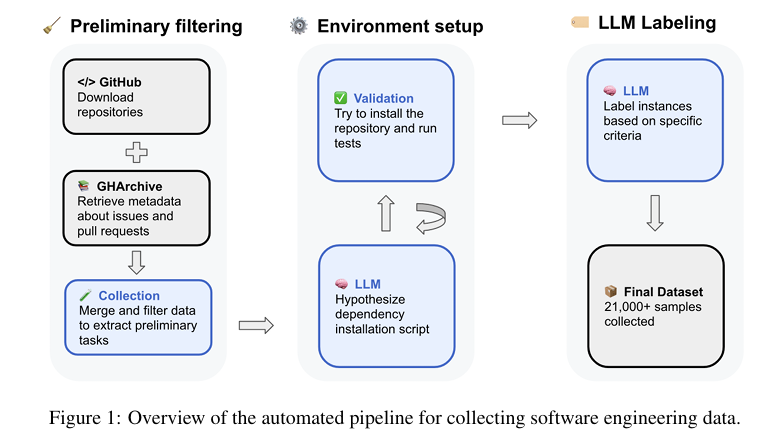
本研究从GitHub Archive和GitHub平台获取原始输入数据,涵盖超过30,000个Python代码库,重点收集与已解决问题相关的拉取请求(PRs)。通过一系列过滤条件,如问题描述长度、PR是否合并到主分支、是否包含测试修改等,我们初步筛选出约153,400个潜在的任务实例。
自动化安装指令配置
为了克服手动配置环境的局限性,我们采用了一种全自动化的方法来生成环境设置指令。具体而言,我们使用LLM扫描仓库文件,识别潜在的安装信息文件(如README.md、Dockerfile、setup.py等),并从中提取安装配方。通过多次迭代和错误日志分析,我们不断优化安装配方,确保至少有一个任务实例能够成功配置环境。
执行基础安装验证
为了确保任务的可解决性和测试的完整性,我们对每个任务实例进行执行基础的安装验证。这一过程包括在隔离容器中安装项目依赖,执行测试,并验证测试结果是否符合预期。只有通过验证的任务实例才会被纳入最终的数据集。
自动化任务质量评估
为了进一步提升数据集的质量,我们使用LLM对每个任务实例进行自动化质量评估。评估指标包括问题清晰度、任务复杂度和测试补丁正确性。我们使用SWE-bench Verified的数据对LLM进行微调,并使用微调后的模型对每个任务实例进行预测,生成相应的质量标签。
研究结果
SWE-rebench数据集
通过上述方法,我们成功构建了SWE-rebench数据集,该数据集包含21,336个标注的任务实例,覆盖了3,468个不同的GitHub存储库。数据集已公开发布在Hugging Face Datasets上,并提供了相应的代码和评估脚本。
SWE-rebench基准测试
我们利用SWE-rebench方法收集的新任务构建了一个无污染的基准测试集,并对比了不同LLM在该基准测试集和SWE-bench Verified上的表现。结果显示,一些语言模型在SWE-bench Verified上的性能可能因数据污染问题而被高估。相比之下,SWE-rebench基准测试集提供了更准确、更可靠的评估结果。
模型性能分析
我们对多个开源和闭源LLM在SWE-rebench基准测试集上的性能进行了详细分析。结果显示,不同模型在解决复杂任务和保持一致性方面存在显著差异。例如,GPT-4.1在较晚的任务子集上性能明显下降,而LLaMa-4-Maverick则表现出较高的pass@5得分,但整体解决率相对较低。这些发现为我们深入理解不同LLM在软件工程任务中的表现提供了宝贵见解。
研究局限
自动化任务质量评估的局限性
尽管我们采用了自动化任务质量评估方法来提升数据集的质量,但这种方法仍然存在局限性。由于LLM生成的标签可能包含错误,因此数据集中可能仍存在一些描述不清或无法解决的任务实例。这些任务实例可能会对模型的训练和评估产生不利影响。
语言多样性的限制
目前,SWE-rebench数据集和基准测试集主要关注基于Python的任务实例。尽管我们的管道设计上是语言无关的,并且可以扩展到其他编程语言,但当前版本的数据集在语言多样性方面仍存在限制。这可能会限制数据集在更广泛软件工程任务中的应用。
未来研究方向
扩展数据覆盖范围和体积
未来,我们计划通过扩展数据收集方法,从更广泛的代码变更(如任意拉取请求)中提取任务实例,以显著增加数据集的体积。这将有助于进一步丰富数据集的多样性和规模,为模型训练提供更充足的资源。
改进任务过滤管道
为了提高提取任务的整体质量,我们将致力于优化过滤管道中的启发式方法。通过更精确的过滤条件,我们可以减少数据集中描述不清或无法解决的任务实例数量,从而提升数据集的整体质量。
支持新的编程语言
我们将利用核心方法论,收集其他流行编程语言(如JavaScript、Java、C++等)的项目数据集,以扩展SWE-rebench的语言和技术多样性。这将使数据集能够覆盖更广泛的软件工程任务,促进不同编程语言下模型性能的比较和评估。
保持SWE-rebench基准测试的更新
我们将持续利用新鲜任务更新SWE-rebench基准测试集,并对现有模型进行更广泛的评估。通过与社区分享详细的性能分析结果,我们将促进透明和公平的模型评估,推动软件工程领域AI技术的快速发展。
综上所述,本研究通过开发一个新颖、自动化且可扩展的管道,成功构建了SWE-rebench数据集和基准测试集,为软件工程领域AI技术的研究和发展提供了有力支持。未来,我们将继续扩展数据集的覆盖范围和体积,改进任务过滤管道,支持新的编程语言,并保持基准测试的更新,以推动该领域的持续进步。