这里分享一篇文章《Large Language Diffusion Models》,来自人民大学高领人工智能学院,一篇尝试改变传统自回归范(预测下一个token) LLM 架构,探索扩散模型在 LLM 上的作用,通过随机掩码-预测逆向思维,让模型学会全局思考。
论文地址:https://arxiv.org/pdf/2502.09992
代码地址:https://github.com/ML-GSAI/LLaDA & https://huggingface.co/GSAI-ML/LLaDA-8B-Base/blob/main/modeling_llada.py
文章目录
- [1. 背景](#1. 背景)
- [2. 方法](#2. 方法)
-
- [2.1 概率建模公式(负对数似然近似替代)](#2.1 概率建模公式(负对数似然近似替代))
-
- [2.1.1 训练过程的数学建模](#2.1.1 训练过程的数学建模)
- [2.1.2 示例](#2.1.2 示例)
- [2.2 预训练](#2.2 预训练)
- [2.3 监督微调 SFT](#2.3 监督微调 SFT)
- [2.4 推理](#2.4 推理)
-
- [2.4.1 采样流程](#2.4.1 采样流程)
- [2.4.2 评估流程](#2.4.2 评估流程)
- [3. 实验](#3. 实验)
-
- [3.1 语言任务上可扩展性](#3.1 语言任务上可扩展性)
- [3.2 Benchmark 结果](#3.2 Benchmark 结果)
-
- [3.2.1 预训练阶段](#3.2.1 预训练阶段)
- [3.2.2 后训练阶段](#3.2.2 后训练阶段)
- [3.3 反向推理与分析](#3.3 反向推理与分析)
- [3.4 case study](#3.4 case study)
1. 背景
近年来,大语言模型(Large Language Models,LLMs)在人工智能领域取得了显著的成功,极大地推动了自然语言处理任务的进展。当前主流的大语言模型,例如GPT系列和LLaMA系列,主要基于自回归模型(Autoregressive Models,ARMs),即逐步预测下一个词汇,以最大化真实数据的对数似然(最大似然估计,MLE):
max θ E p data ( x ) log p θ ( x ) ⟺ min θ KL ( p data ( x ) ∣ ∣ p θ ( x ) ) \max_\theta \mathbb{E}{p{\text{data}}(x)}\\log p_\\theta(x) \quad \Longleftrightarrow \quad \min_\theta \text{KL}(p_{\text{data}}(x)||p_\theta(x)) θmaxEpdata(x)logpθ(x)⟺θminKL(pdata(x)∣∣pθ(x))
上述公式展示了生成式建模(generative modeling)的基本原理 :一方面,我们可以通过最大化真实数据在模型下的对数概率来优化模型 ;另一方面,这个过程也等价于最小化真实数据分布与模型分布之间的KL散度 。然而,自回归模型虽然取得了广泛的应用和优异的表现,却面临着一些本质性的问题,例如逐词生成的方式造成计算开销大,并且在某些逆序任务(例如反向生成文本)上表现不佳。
因此,本文提出了一个重要的问题:**自回归模型真的是实现大语言模型强大能力的唯一途径吗?**基于此,作者受扩散模型(Diffusion Models)在视觉领域巨大成功的启发,提出了非自回归的掩码扩散语言模型(Large Language Diffusion with mAsking, LLaDA)。这种模型以扩散模型的思想,通过随机掩盖并逐步还原文本序列,从而构建出一种全新的、具有双向依赖性的语言建模方式。本文的主要动机,就是探索扩散模型这种全新范式能否成功地替代或补充自回归模型,从而推动语言模型研究向更宽广的方向发展。
效果对比:
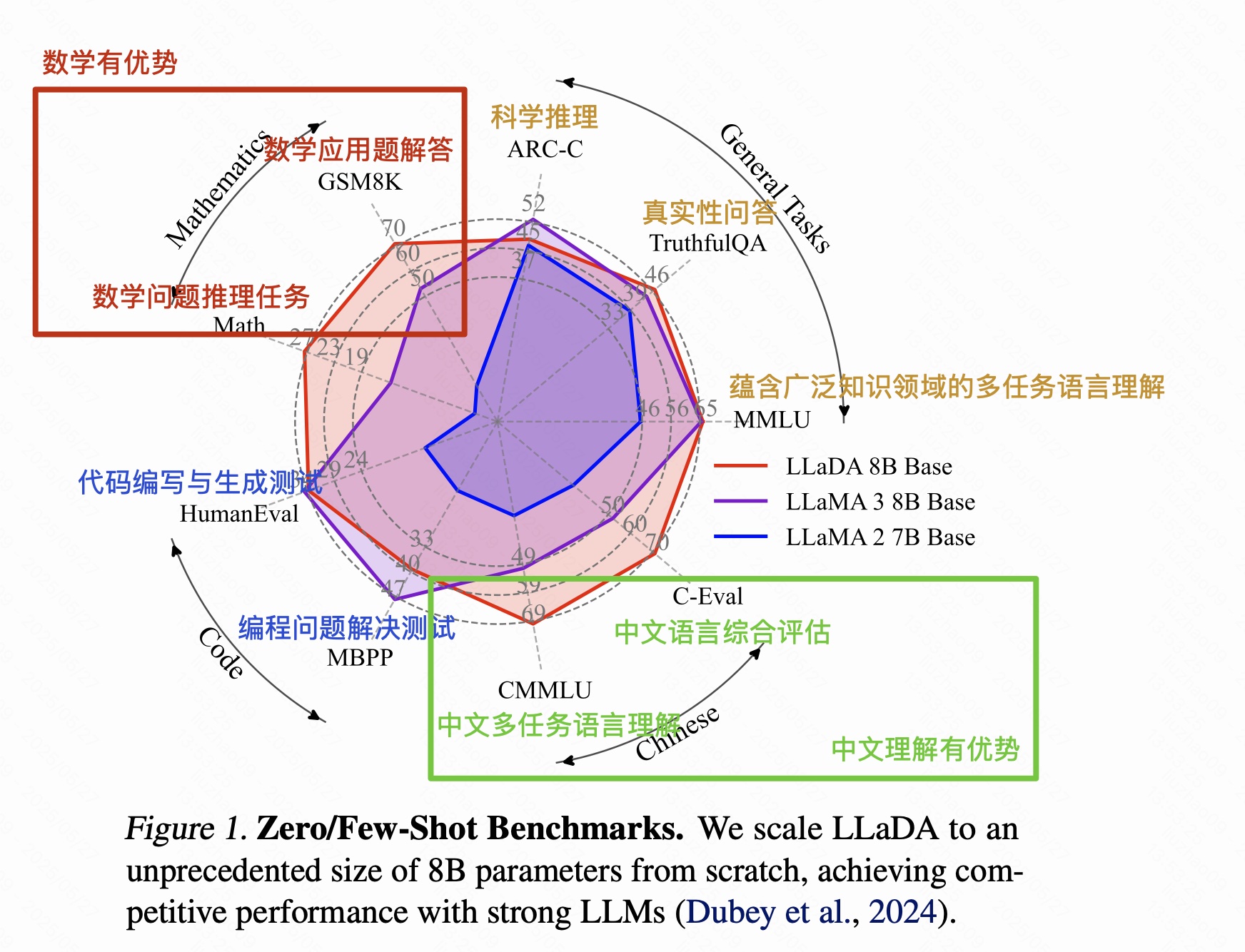
图1看出:LLaDA和LLaMA 3在不同任务上各有所长,但整体水平接近。这说明LLaDA作为一种新的非自回归扩散模型,已经具有与当前主流自回归模型同等水平的能力。
2. 方法
2.1 概率建模公式(负对数似然近似替代)
在上文的框架下,传统的自回归模型采用如下形式建模文本概率分布:
p θ ( x ) = p θ ( x 1 ) ∏ i = 2 L p θ ( x i ∣ x 1 , ... , x i − 1 ) p_\theta(x) = p_\theta(x^1) \prod_{i=2}^{L} p_\theta(x^i | x^1, \dots, x^{i-1}) pθ(x)=pθ(x1)i=2∏Lpθ(xi∣x1,...,xi−1)
其中, x x x 表示一个长度为 L L L 的文本序列, x i x^i xi 是该序列中的第 i i i 个词。该公式体现的是"逐词生成"(next-token prediction)的思想,即每次根据之前的所有词来预测下一个词。
它背后的损失函数是"最大似然"的负对数损失 ,即:
L ARM ( θ ) = − ∑ i = 1 L log p θ ( x i ∣ x 1 , ... , x i − 1 ) \mathcal{L}{\text{ARM}}(\theta) = -\sum{i=1}^{L} \log p_\theta(x^i \mid x^1, \dots, x^{i-1}) LARM(θ)=−i=1∑Llogpθ(xi∣x1,...,xi−1)
这就是自回归语言模型的训练目标,也叫做:
- 语言建模损失(language modeling loss)
- 或者叫做负对数似然(NLL)损失
这种方法已经在各种任务中展现出优异性能,但也带来了一些限制,例如生成过程严格单向、计算开销大、不适用于反向推理等场景。
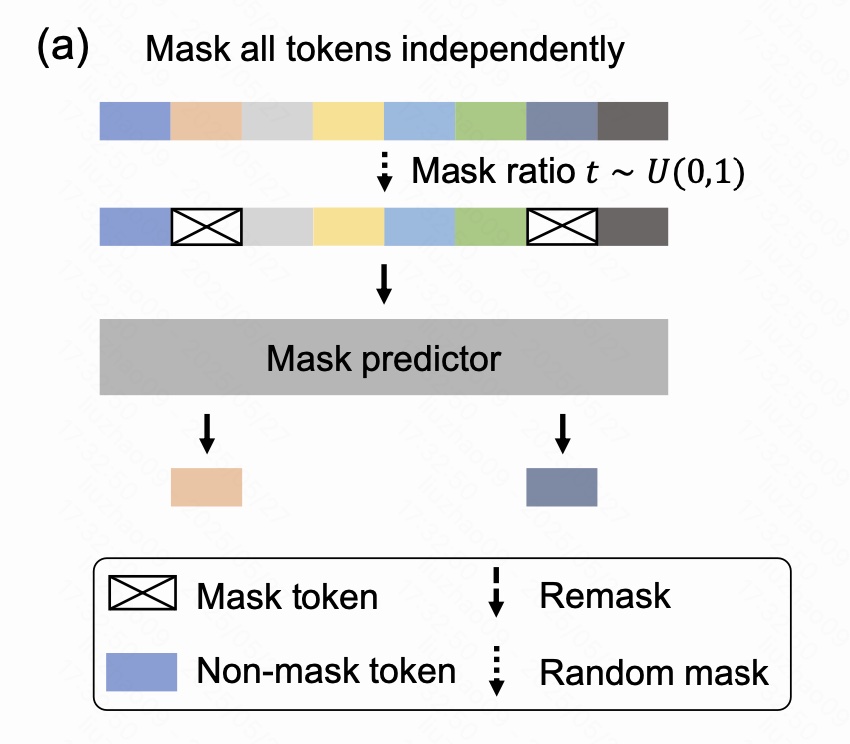
为了克服这些局限性,本文提出了全新的扩散语言模型 LLaDA(Large Language Diffusion with mAsking),采用了不同于ARM的生成建模方式。具体来说,LLaDA通过引入**前向掩码过程(forward process)与反向预测过程(reverse process)**来构建模型分布。
-
前向过程 从真实文本 x 0 x_0 x0 出发,逐步地随机掩盖序列中的词,直到时间 t = 1 t=1 t=1 时所有词都被掩盖。任意时刻 t ∈ ( 0 , 1 ) t\in(0,1) t∈(0,1),模型得到的序列 x t x_t xt 是部分被掩盖的,每个词以概率 t t t 被替换为掩码(M),以概率 1 − t 1-t 1−t 保持原样。
-
反向过程 则训练一个参数化模型 p θ ( ⋅ ∣ x t ) p_\theta(\cdot|x_t) pθ(⋅∣xt),用于在已知部分词的情况下恢复被掩盖的词。整个模型的训练目标是最小化仅基于掩盖词的交叉熵损失函数:
L ( θ ) = − E t , x 0 , x t 1 t ∑ i = 1 L 1 \[ x t i = M log p θ ( x 0 i ∣ x t ) ] \mathcal{L}(\theta) = -\mathbb{E}{t, x_0, x_t} \left \\frac{1}{t} \\sum_{i=1}\^{L} \\mathbb{1}\[x\^i_t = \\text{M} \log p\theta(x^i_0 | x_t) \right] L(θ)=−Et,x0,xtt1i=1∑L1\[xti=Mlogpθ(x0i∣xt)]
其中:
- x 0 x_0 x0 是原始文本;
- x t x_t xt 是前向掩码过程后的部分掩码序列;
- 1 x t i = M \mathbb{1}x\^i_t = \\text{M} 1xti=M 是指示函数,仅在词 x i x^i xi 被掩盖时为1,用于控制只对掩盖词计算损失;
- 1 t \frac{1}{t} t1 是一个归一化因子,用于平衡不同掩码比例的影响。
通过优化该损失函数,模型学习如何恢复原始序列,从而建立起 p θ ( x 0 ) p_\theta(x_0) pθ(x0) 的建模能力。
值得注意的是,这个训练目标是原始数据对数似然 的一个上界(upper bound) ,即:
− E p data ( x 0 ) log p θ ( x 0 ) ≤ L ( θ ) -\mathbb{E}{p{\text{data}}(x_0)}\\log p_\\theta(x_0) \leq \mathcal{L}(\theta) −Epdata(x0)logpθ(x0)≤L(θ)
因此,它为语言建模提供了一个有理论保障的、端到端可优化的目标函数。
此外,LLaDA 与传统的 BERT 风格掩码语言模型(MLM)的一个关键区别在于:LLaDA使用的是动态掩码比例 ,即在训练时掩码比率 t ∼ Uniform ( 0 , 1 ) t \sim \text{Uniform}(0, 1) t∼Uniform(0,1),而非固定比例。这种设计在大模型训练中具有重要意义,因为它能模拟从极少掩码到完全掩码的多种情形,提升模型的鲁棒性和泛化能力。
2.1.1 训练过程的数学建模
要让 LLaDA 既能并行预测、又遵循最大似然框架,作者把 掩码扩散 描述为一个从"无掩码文本"逐步演化到"全掩码文本"的 前向过程 ,再配以与之可逆的 反向恢复过程。
(1)前向掩码过程 forward process
给定干净文本 x 0 x_0 x0,在连续时间 t ∈ 0 , 1 t\in0,1 t∈0,1 上定义随机变量 x t {x_t} xt。 t = 0 t=0 t=0 时 x t = x 0 x_t=x_0 xt=x0; t = 1 t=1 t=1 时所有词都被替换成掩码符号 M \text{M} M。对每个时刻 t t t,掩码操作在 token 维度上完全独立(joint 概率是各 token 概率的乘积),条件分布写成:
q t ∣ 0 ( x t ∣ x 0 ) = ∏ i = 1 L q t ∣ 0 ( x t i ∣ x 0 i ) , q_{t\lvert0}(x_t\mid x_0)\;=\;\prod_{i=1}^{L} q_{t\lvert0}(x_t^i\mid x_0^i), qt∣0(xt∣x0)=i=1∏Lqt∣0(xti∣x0i),
其中:
q t ∣ 0 ( x t i ∣ x 0 i ) = { 1 − t , x t i = x 0 i , t , x t i = M . q_{t\lvert0}(x_t^i\mid x_0^i)\;=\; \begin{cases} 1-t,&x_t^i=x_0^i,\\4pt t,&x_t^i=\text{M}. \end{cases} qt∣0(xti∣x0i)={1−t,t,xti=x0i,xti=M.
M denotes the mask token
也就是说,每个 token 以概率 t t t 被掩盖,以概率 1 − t 1-t 1−t 保留原样;掩盖比例随 t t t 线性递增,这与连续扩散模型中"噪声调度"完全对应。
(2)反向恢复过程 reverse process
由于前向过程是马尔可夫且逐 token 独立,它存在唯一的逆过程 q s ∣ t ( x s ∣ x t ) q_{s\lvert t}(x_s\mid x_t) qs∣t(xs∣xt) ( 0 ≤ s < t ≤ 1 0\le s<t\le1 0≤s<t≤1),同样可因子化为
q s ∣ t ( x s ∣ x t ) = ∏ i = 1 L q s ∣ t ( x s i ∣ x t ) , q_{s\lvert t}(x_s\mid x_t)\;=\;\prod_{i=1}^{L} q_{s\lvert t}(x_s^i\mid x_t), qs∣t(xs∣xt)=i=1∏Lqs∣t(xsi∣xt),
其中:
q s ∣ t ( x s i ∣ x t ) = { 1 , x t i ≠ M , x s i = x t i , s t , x t i = M = x s i , t − s t q 0 ∣ t ( x s i ∣ x t ) , x t i = M , x s i ≠ M , 0 , otherwise . q_{s\lvert t}(x_s^i\mid x_t)= \begin{cases} 1,&x_t^i\neq\text{M},\;x_s^i=x_t^i,\\4pt \dfrac{s}{t},&x_t^i=\text{M}=x_s^i,\\10pt \dfrac{t-s}{t}\;q_{0\lvert t}(x_s^i\mid x_t),&x_t^i=\text{M},\;x_s^i\neq\text{M},\\4pt 0,&\text{otherwise}. \end{cases} qs∣t(xsi∣xt)=⎩ ⎨ ⎧1,ts,tt−sq0∣t(xsi∣xt),0,xti=M,xsi=xti,xti=M=xsi,xti=M,xsi=M,otherwise.
要真正生成文本,我们只需估计 数据预测分布 q 0 ∣ t ( x s i ∣ x t ) q_{0\lvert t}(x_s^i\mid x_t) q0∣t(xsi∣xt),即"在给定当前可见上下文 x t x_t xt 的条件下,掩码位置本应是什么词"。Ou et al. (2024) https://arxiv.org/pdf/2406.03736进一步证明,这个分布可以写成时间无关的形式
q 0 ∣ t ( x s i ∣ x t ) = p data ( x 0 i ∣ x t UM ) , ∀ x t i = M , q_{0\lvert t}(x_s^i\mid x_t) =\;p_{\text{data}}\!\bigl(x_0^i \mid x_t^{\text{UM}}\bigr), \qquad \forall\,x_t^i=\text{M}, q0∣t(xsi∣xt)=pdata(x0i∣xtUM),∀xti=M,
其中 x t UM x_t^{\text{UM}} xtUM 表示 x t x_t xt 中所有 未 被掩盖的 token 集。这个结果的重要性在于:模型只需输入当前序列 x t x_t xt,不必显式知道 t t t 就能完成预测。
(3)Mask Predictor 与训练损失
基于上述结论,引入无因果 Transformer 作为 mask predictor ,记为 p θ ( , ⋅ ∣ x t ) p_\theta(,\cdot\mid x_t) pθ(,⋅∣xt),对所有掩码位同时 输出条件分布。训练时对被掩码 token 计算交叉熵,并用 1 / t 1/t 1/t 归一化不同掩码比例带来的有效样本差异:
L ( θ ) = − E t , x 0 , x t 1 t ∑ i = 1 L 1 \[ x t i = M log p θ ( x 0 i ∣ x t ) ] \mathcal{L}(\theta) =\;-\mathbb{E}{t,x_0,x_t} \!\Bigl \\frac{1}{t}\\sum_{i=1}\^{L}\\mathbf 1\[x_t\^i=\\text{M} \;\log p\theta\!\bigl(x_0^i\mid x_t\bigr) \Bigr] L(θ)=−Et,x0,xtt1i=1∑L1\[xti=Mlogpθ(x0i∣xt)]
- x 0 ∼ p data x_0\sim p_{\text{data}} x0∼pdata
- t ∼ Uniform ( 0 , 1 ) t\sim\text{Uniform}(0,1) t∼Uniform(0,1)(动态掩码率)
- x t ∼ q t ∣ 0 ( x t ∣ x 0 ) x_t\sim q_{t\lvert0}(x_t\mid x_0) xt∼qt∣0(xt∣x0)
(4)与最大似然的一致性
Ou et al. (2024) https://arxiv.org/pdf/2406.03736 证明:
− E x 0 ∼ p data log p θ ( x 0 ) ≤ L ( θ ) -\mathbb{E}{x_0\sim p{\text{data}}}\!\bigl\\log p_\\theta(x_0)\\bigr\;\;\le\;\;\mathcal{L}(\theta) −Ex0∼pdatalogpθ(x0)≤L(θ)
即 L ( θ ) \mathcal{L}(\theta) L(θ) 是真实 NLL 的上界。换言之,最小化 L \mathcal{L} L 仍然在逼近最大似然目标,因此 LLaDA 虽采用并行、双向的掩码恢复方式,依旧属于严格的生成建模框架。
(5)同 BERT-MLM 的根本区别
传统 BERT 仅用固定 15% 掩码做判别式预训练,推断阶段不能"反扩散"生成;LLaDA 掩码比例覆盖 ( 0 , 1 ] (0,1] (0,1],且训练即生成,推断时可从全掩码序列经反向过程直接采样文本。这赋予了它并行预测、双向感知、以及在逆序任务中天然优势的能力。
2.1.2 示例
如图:
假设训练语料里有一句极短的英文句子
原句( x 0 x_0 x0): I love pizza
将它拆成 3 个 token: \\bigl\[ \["I", "love", "pizza" \bigr] ](记长 L = 3 L=3 L=3)。下面演示 一次 训练迭代中,掩码扩散 + 损失计算的全过程:
① 抽样掩码比例
随机取一个掩码率 t ∼ U ( 0 , 1 ) t\sim U(0,1) t∼U(0,1),比如碰巧得到
t = 0.5 t = 0.5 t=0.5
② 前向掩码 :生成练习题 x t x_t xt
对每个 token 抛硬币(概率 t = 0.5 t=0.5 t=0.5 会被盖掉):
| 位置 i i i | 原词 x 0 i x_0^i x0i | 随机结果 | 结果写入 x t i x_t^i xti |
|---|---|---|---|
| 1 | I | 正面 | I |
| 2 | love | 反面 | M |
| 3 | pizza | 正面 | pizza |
于是 x t x_t xt 变成
残缺句 :I M pizza
③ 模型预测:mask predictor 输出条件概率
模型现在看到的输入就是 I M pizza ,它需要 同时 猜出被掩码处应该放什么词。
- 对位置 2(唯一被盖住的 token),模型输出一个词表概率分布;假设它给出
- p θ ( love ∣ x t ) = 0.8 p_\theta(\text{love}\mid x_t)=0.8 pθ(love∣xt)=0.8
- 其他所有词概率和 = 0.2
④ 交叉熵损失(公式)
训练损失:
L ( θ ) = − 1 t ⏟ = 1 0.5 = 2 ∑ i = 1 L 1 x t i = M log p θ ( x 0 i ∣ x t ) \mathcal{L}(\theta) =\;-\underbrace{\frac{1}{t}}{=\frac1{0.5}=2}\! \sum{i=1}^{L}\mathbf1x_t\^i=\\text{M} \log p_\theta(x_0^i\mid x_t) L(θ)=−=0.51=2 t1i=1∑L1xti=Mlogpθ(x0i∣xt)
- 只有第 2 个 token 被掩盖 ,指示函数 1 ⋅ \mathbf1\\cdot 1⋅ 使得其余位置不计入损失;
- 因此本轮梯度只来自一个项:
L ( θ ) = − 2 log 0.8 ≈ − 2 × ( − 0.223 ) = 0.446. \mathcal{L}(\theta)\;=\;-2\;\log 0.8 \;\approx\;-2\times (-0.223)\;=\;0.446 . L(θ)=−2log0.8≈−2×(−0.223)=0.446.
如果模型把 "love" 只给到 0.1 概率,则损失变成 − 2 log 0.1 ≈ 4.605 -2\log 0.1\approx 4.605 −2log0.1≈4.605,损失大 10 倍;
这体现了「猜得越准 ➔ log 概率越高 ➔ 损失越小」的纲要。
⑤ 为什么要除以 1 / t 1/t 1/t?
当 t t t 较小(遮得少),被评分的 token 数目也少 ;乘以 1 / t 1/t 1/t 可以让不同掩码率下,单句损失的期望量级保持一致,训练过程更平衡。
⑥ 把一次实验放到期望里
真正的 E t , x 0 , x t \mathbb E_{t,x_0,x_t} Et,x0,xt 表示:
- 随机挑句子 (不同 x 0 x_0 x0),
- 随机挑掩码率 (不同 t t t),
- 在该率下重新掩码一次 (不同 x t x_t xt)。
批量迭代后,模型等价于在 各种残缺程度 和 各种上下文情况 下,练习"把盒子里的拼图片补回去"。因为
− E log p θ ( x 0 ) ≤ L ( θ ) -\mathbb{E}\\log p_\\theta(x_0)\;\le\;\mathcal{L}(\theta) −Elogpθ(x0)≤L(θ)
每次把 L \mathcal{L} L 往下压,也就把真正的负对数似然往下压------模型整体生成能力随之提升。
一图胜千言
- 原句 → (打碎) → 残缺句
- 残缺句 + 模型 → (一起猜) → 所有盖住的词
- 交叉熵 + 1/t → 损失
- 多次重复(期望) → 优化最大似然
这样,你可以把前向分布视作"出题器",反向分布的真值视作"答案数据集",而损失函数就是给模型批改作业的评分尺------三者环环相扣。
2.2 预训练
LLaDA 的"掩码预测器"仍采用 Transformer (Vaswani, 2017)骨干,因此可以沿用大模型社区成熟的实现与工程优化;与 GPT/LLaMA 最大的结构差别是 彻底关闭因果掩码 ------ 模型在前向传播时能同时看到整句,从而一次性为所有被掩码 token 给出预测。为证明思路可扩展,作者训练了 1 B 与 8 B 两个规模的版本。
| 模块 | 设计与数值 | 备注 |
|---|---|---|
| 注意力类型 | vanilla multi-head attention(q:kv=1:1) | 不用 Grouped-Query,因反向推断无法利用 KV-cache;为保持总规模,适当缩窄 FFN 隐层宽度 |
| 词表 | 自建 tokenizer(基于 GPT-2 BPE),词表 size 略异于 LLaMA-3 8 B | 数据重新压缩后更贴合中文/代码混合语料 |
| 训练数据 | 2.3 T token,总量≈LLaMA-2;含网页文本 + 高质量代码 + 数学推导 + 多语语料 | 爬虫后人工规则 + LLM 过滤低质片段;不同领域比例由缩尺 ARM 网格实验确定 |
| 序列长度 | 固定 4096 token | 统一 batch shape,易于流水线并行 |
| 随机变长 | 1 % 训练样本裁剪到 1--4096 的随机长度 | 提升模型对短句/长段混合的鲁棒性 |
| 掩码率采样 | t ∼ Uniform ( 0 , 1 ) t\sim\text{Uniform}(0,1) t∼Uniform(0,1)(每 batch 独立采样) | 训练时覆盖"几乎不掩→全掩"全局况 |
| 批大小 | 全局 1280(H800 GPU × 320 卡,每卡 local batch = 4) | 相当于 LLaMA-2/3 同规模设定 |
| 优化器 | AdamW (Loshchilov & Hutter, 2017),weight decay = 0.1 | 大模型默认配置 |
| 学习率调度 | Warm-up / Stable / Decay (Hu et al., 2024) | 0 → 4 × 10⁻⁴,前 2000 iter 固定 4 × 10⁻⁴,至处理 1.2 T token 降到 1 × 10⁻⁴,继续 0.8 T token 线性衰减至 1 × 10⁻⁵,收尾 0.3 T token 连续训练不中断;调度自带"先大步收敛→后期精修"节奏 |
| GPU 计算量 | 0.13 million H800 GPU-hours | 与同规模 ARM 基线近乎相同;说明"关闭 KV-cache"带来的负担被并行掩码预测抵消 |
| 实验次数 | 8 B 版本 只跑一次,无手动超参调优 | 强调"概念可行性"而非靠精调刷分 |
在 2.3 T token 上,用无因果 Transformer + 动态全覆盖掩码率 + Warmup-Stable-Decay 调度,耗时 0.13 M H800 GPU-hour 把 8 B 规模 LLaDA 预训练完成,训练成本与同级别自回归 LLM 持平,却收获了并行推断、双向依赖和逆序推理的潜在优势。

2.3 监督微调 SFT
如图:
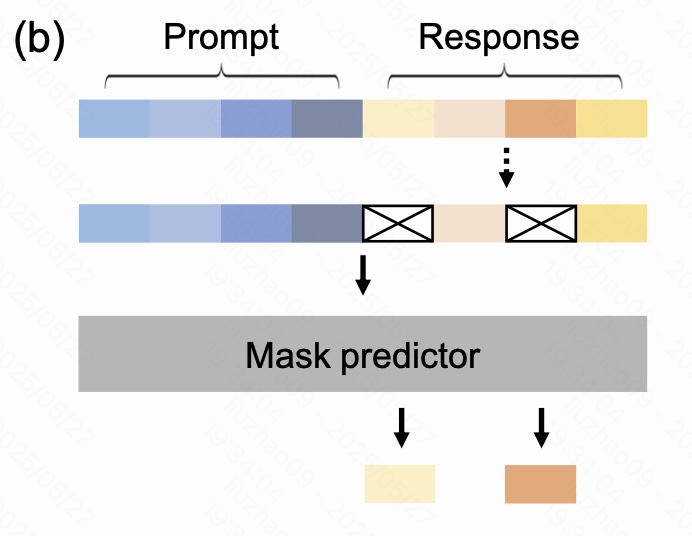
为了让 LLaDA 从纯粹的"补洞器"跃升为能够听懂指令、对答如流 的大模型,作者在预训练之后追加了一轮 监督微调。整个过程可以理解为:
给模型一对 〈Prompt p₀,参考回答 r₀〉,随机把 r₀ 里的若干 token 换成
[MASK],然后要求模型在看到完整 p₀ 的前提下,一次性把所有洞填回去。
数据与任务形式:
- 数据量:4.5 M 指令-回答对;领域覆盖代码、数学、多轮闲聊与结构化数据解析等。
- 序列拼接 :训练时直接把 p₀ 与 r₀ 级联成一条长句;为了 batch 对齐,在较短样本末尾补一个
|EOS|,训练阶段把它当普通词,推理时遇见即停止生成。 - 动态掩码 :仅对回答部分以 t ∼ U ( 0 , 1 ) t\sim\mathrm U(0,1) t∼U(0,1) 的比例独立掩码,Prompt 保持完整;掩码后得到 rₜ。
- 目标分布 :预训练学习的是 p θ ( x 0 ) p_\theta(x_0) pθ(x0);SFT 则显式拟合 条件分布 p θ ( r 0 ∣ p 0 ) p_\theta(r_0\mid p_0) pθ(r0∣p0)。
损失函数 :
L SFT ( θ ) = − E t , p 0 , r 0 , r t 1 t ∑ i = 1 L ′ 1 \[ r t i = M log p θ ( r 0 i ∣ p 0 , r t ) ] , \mathcal L_{\text{SFT}}(\theta)= -\;\mathbb E_{t,p_0,r_0,r_t}\! \Bigl \\frac1t\\sum_{i=1}\^{L'}\\mathbf 1\[r\^i_t=\\text M \log p_\theta\!\bigl(r^i_0 \mid p_0,r_t\bigr) \Bigr], LSFT(θ)=−Et,p0,r0,rtt1i=1∑L′1\[rti=Mlogpθ(r0i∣p0,rt)],
其中 L ′ L' L′ 为拼接后序列长度。与预训练的公式 完全同形 ,只是所有 [MASK] 全落在回答片段,因此两阶段在实现上一套代码即可。
训练细节(8 B 模型):
| 项目 | 设定 | 备注 |
|---|---|---|
| Epoch | 3 | 数据规模相对较小,三遍即可收敛 |
| 批次 | 全局 256(每 GPU 2) | 采用与预训练相同的 320×H800 设备 |
| 优化器 | AdamW,weight decay = 0.1 | 行业标配 |
| 学习率 | Warm-up → 常数 → 线性衰减0-50 iter:0→2.5 × 10⁻⁵之后保持 2.5 × 10⁻⁵最后 10 % iter 线性降至 2.5 × 10⁻⁶ | 调度风格与预训练一致,整体倍率缩小 |
| 其他 | 无任何 RL 或额外技巧;一次性跑完,不做网格调参 | 旨在验证"最朴素 SFT 即可带来显著指令遵从能力" |
与预训练完美兼容的原因:
把 p₀ ⊕ r₀ 看成"干净句" x₀ ,把 p₀ ⊕ rₜ 看成"残缺句" xₜ,就落回预训练的掩码-复原框架;因此
- 网络结构 不变,仍是"无因果掩码 Transformer";
- 随机掩码比例 依旧 t ! ∼ ! U ( 0 , 1 ) t!\sim!\mathrm U(0,1) t!∼!U(0,1);
- 梯度公式 也与预训练保持一致,只是掩码位置限定在回答端。
经过这一步,LLaDA 在保留"并行补洞、双向建模"特性的同时,获得了与自回归 LLM 相当的 指令跟随与多轮对话能力------且训练代价仅是再跑几个 GPU-小时的纯监督学习,没有额外的 RL 或复杂 Alignment。

2.4 推理
如图:
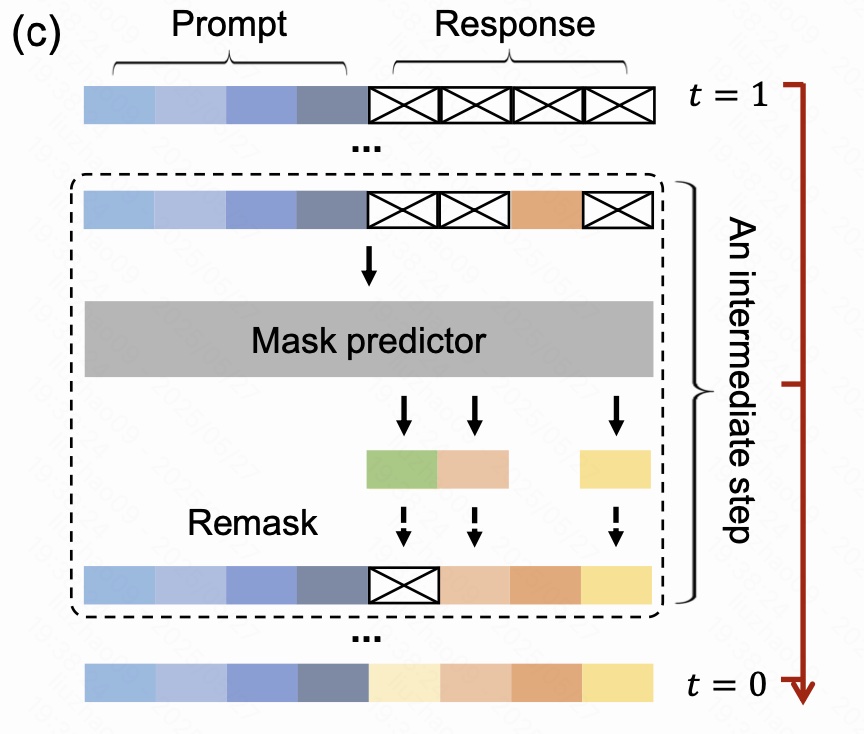
在 LLaDA 里,推理阶段既包含 采样生成 (sampling),也包含 概率评估 (likelihood evaluation)。二者都围绕「反向掩码扩散过程」展开,但关注点不同。下文结合 Fig.2 © 逐步说明。
整体思路:
- 采样 ------从 全掩码响应 出发,沿着 t = 1 → 0 t=1\to 0 t=1→0 的离散时间轴,一步步"揭开面纱"生成完整回复;
- 评估 ------给定候选回复,随机掩一部分 token,只对被掩部分计算对数概率,用得到的 上界 NLL 作为模型打分。
2.4.1 采样流程
| 步骤 | 关键动作 | 细节 / 超参数 |
|---|---|---|
| ① 初始化 | 把整段 Response 部分全部换成掩码 M \text{M} M,得到 x t = 1 x_{t=1} xt=1。Prompt 保留。 | 生成长度 L L L 是超参数(需要提前确定);若不确定可设略长于期望回复长度。 |
| ② 时间步推进 | 将连续区间 0 , 1 0,1 0,1 均匀离散成 K K K 步: t 1 = 1 > t 2 > ⋯ > t K + 1 = 0 t_1=1>t_2>\dots>t_{K+1}=0 t1=1>t2>⋯>tK+1=0。每一步都要调用一次 Mask Predictor。 | K K K(采样步数) 控制效率↔质量,可在几十到几百间调;在 3.3 分析了折中。 |
| ③ 单步更新 | 在某一步 t → s t\to s t→s( s < t s<t s<t):① 将当前序列 r t r_t rt 与 prompt p 0 p_0 p0 一起输入模型,并行预测 所有掩码位;② 依据策略 remask (重掩)掉约 s t \tfrac{s}{t} ts 的 token 得到 r s r_s rs,继续下一步。 | - 随机重掩 :理论最朴素; - 低置信度重掩 :优先保留模型最有把握的 token,可提升质量; - 半自回归重掩:SFT 后可将响应切成区块,按左→右块级生成,兼得并行与稳定。 |
| ④ 终止 | 当 t = 0 t=0 t=0 时,序列中已无掩码,返回最终生成文本。 |
直观图解
- 红色竖轴标记时间从 上 (全掩码) 流向 下 (全可见)。
- 虚线框展示一次中间步骤:预测 → 重掩。
- 彩色方块=已确认 token;黑框叉=仍为掩码。
2.4.2 评估流程
在 LLaDA 体系中,评估(likelihood 打分)流程的价值在于"量化一句已存在文本与模型内在分布的契合度" :通过把给定句子随机掩盖一部分、让掩码预测器复原并统计对数概率,我们得到一条对真实负对数似然的上界。这个分数既能在训练阶段用来监控收敛与过拟合,也能在推理阶段充当 rerank/采样后挑选最佳候选的依据;同时,它还是 RLHF、DPO 等后续对齐算法天然可用的奖励信号,并为学术比较提供统一指标(如 PPL)。换言之,采样负责**"写出文本",评估负责"打几分"**------两条流程相互独立,但后者为模型质量评估、输出选择和后续强化学习式微调提供了不可或缺的量化基础。
采样用来"写句子",评估用来"给句子打分"。论文用下公式提供了方差更低的估计:
− E l , r 0 , r l L l ∑ i = 1 L 1 \[ r l i = M log p θ ( r 0 i ∣ p 0 , r l ) ] , -\mathbb{E}{l,r_0,r_l}\!\left\\frac{L}{l}\\sum_{i=1}\^{L}\\mathbf1\[r_l\^i=\\text{M}\log p\theta(r_0^i\mid p_0,r_l)\right], −El,r0,rllLi=1∑L1\[rli=Mlogpθ(r0i∣p0,rl)],
其中
- 随机掩码 :
- 从 1 , ... , L {1,\dots,L} 1,...,L 均匀抽取长度 l l l(再次随机),
- 不放回地掩掉这些 token 得到 r l r_l rl。
- 上式含义 :只在被掩位置累积 log-prob,再乘 L l \tfrac{L}{l} lL 校正;数学上是 2.3 公式的无偏等价形式,但方差更小、更稳定。
- Classifier-free guidance:推理时可调节"创意↔忠实"权重(论文附录 A.2)。
- 关键超参数小结
| 名称 | 作用 | 典型值 / 备注 |
|---|---|---|
| K K K 采样步数 | 越多越慢但质量高 | 32 -- 256 |
| 生成长度 L L L | 初始全掩码序列长度 | 对输出长度不敏感 (§ B.4) |
| 重掩策略 | 随机 / 低置信度 / 半自回归 | 低置信度 & 半自回归在实验中更佳 |
LLaDA 的推理就是"把 BERT 做 MLM 的掩码-填空游戏,连做 K 轮,从全掩码慢慢变成完整句子;同时还能反过来用同一流程给别人的句子打分",既保留了并行生成的优势,又提供了自回归 LLM 同等级别的评分接口。

3. 实验
3.1 语言任务上可扩展性
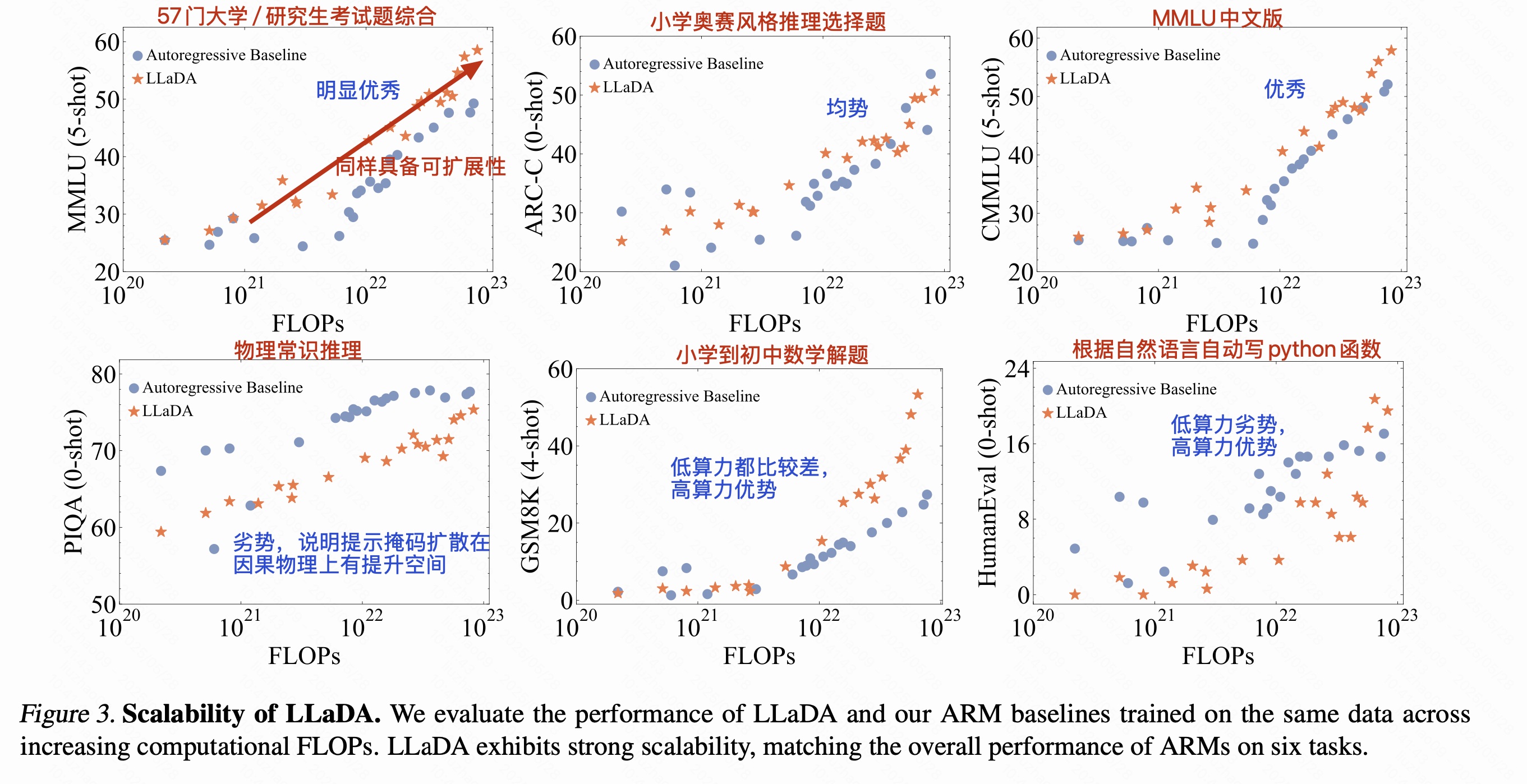
3.2 Benchmark 结果
3.2.1 预训练阶段
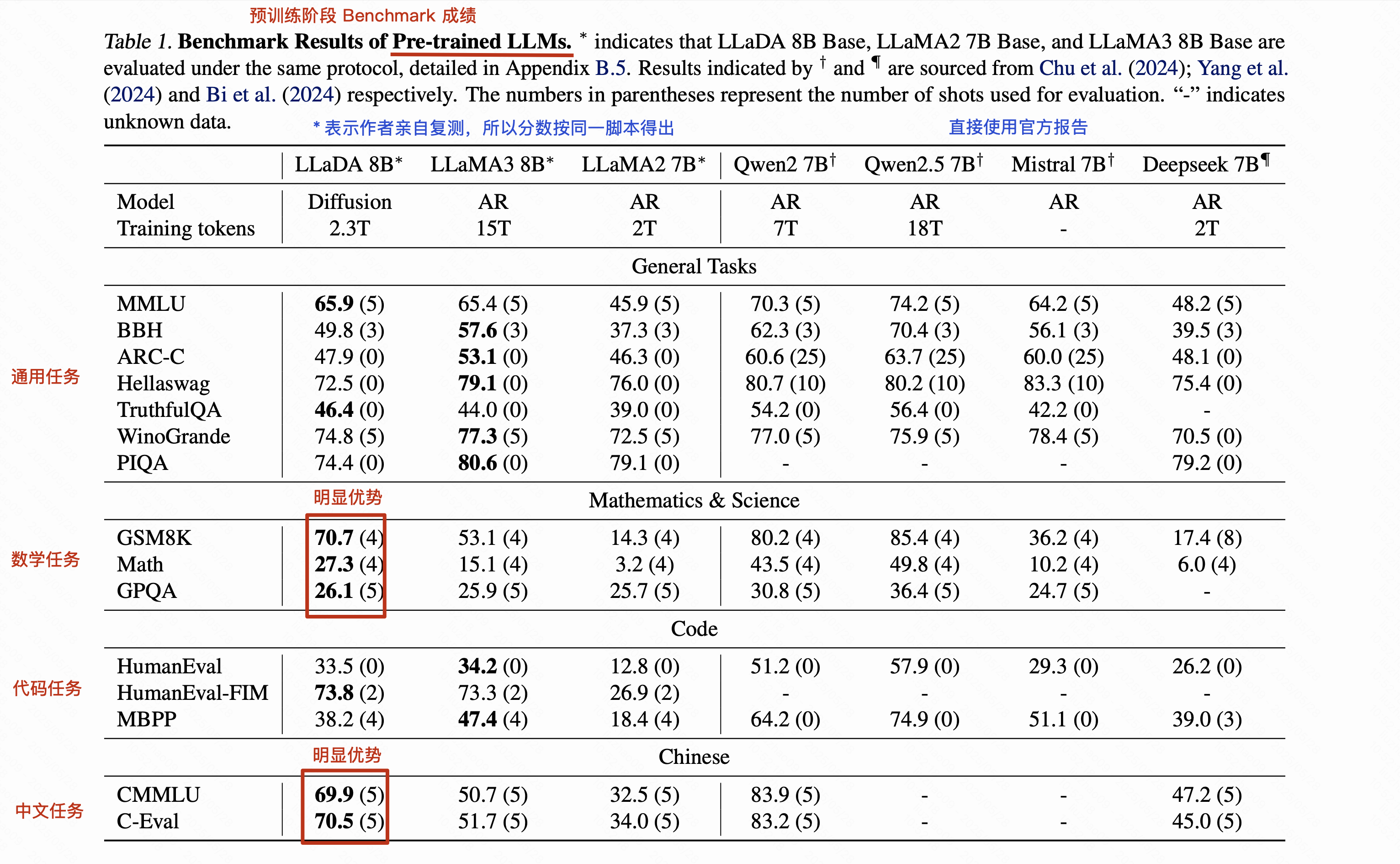
3.2.2 后训练阶段
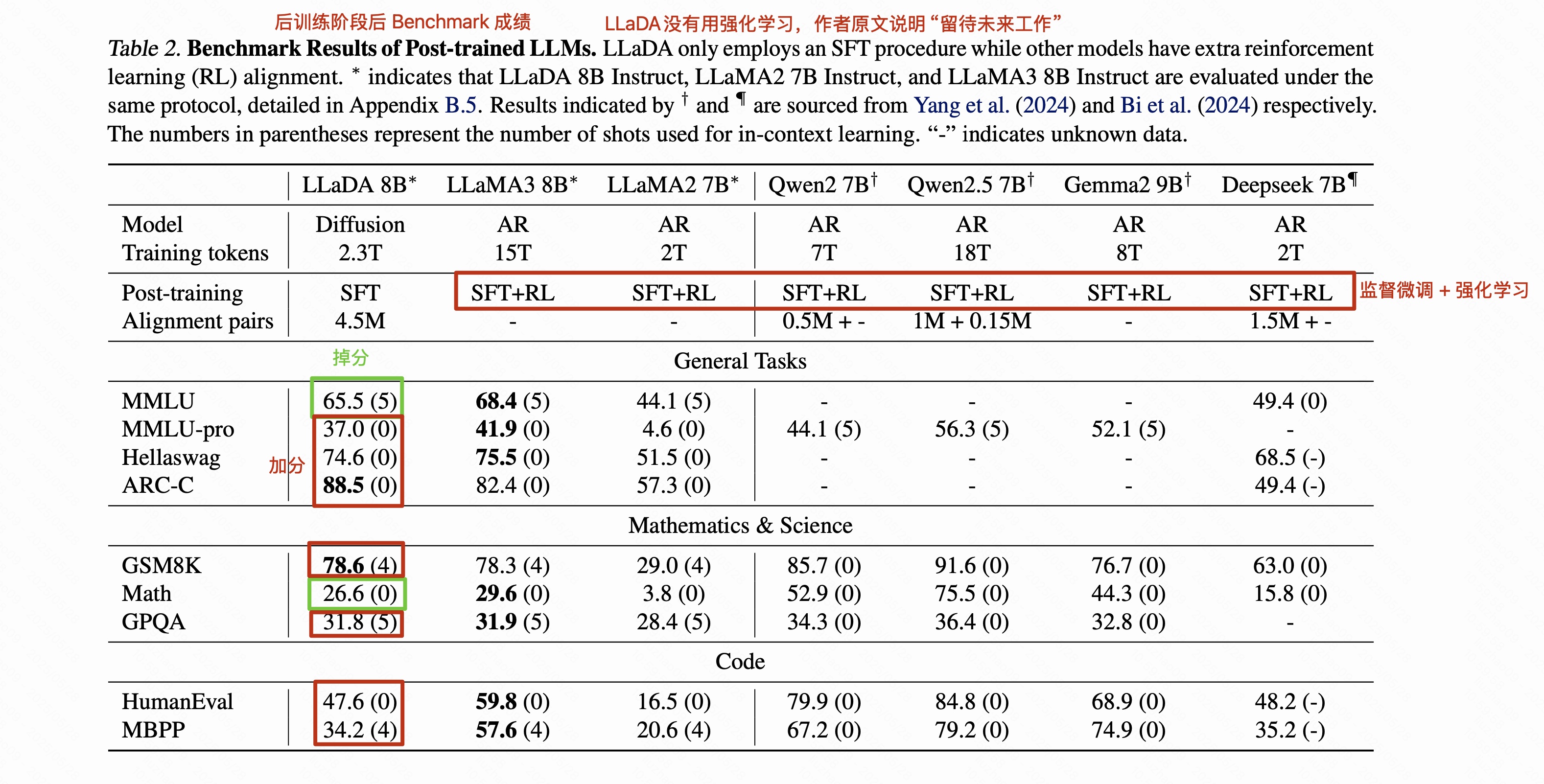
3.3 反向推理与分析
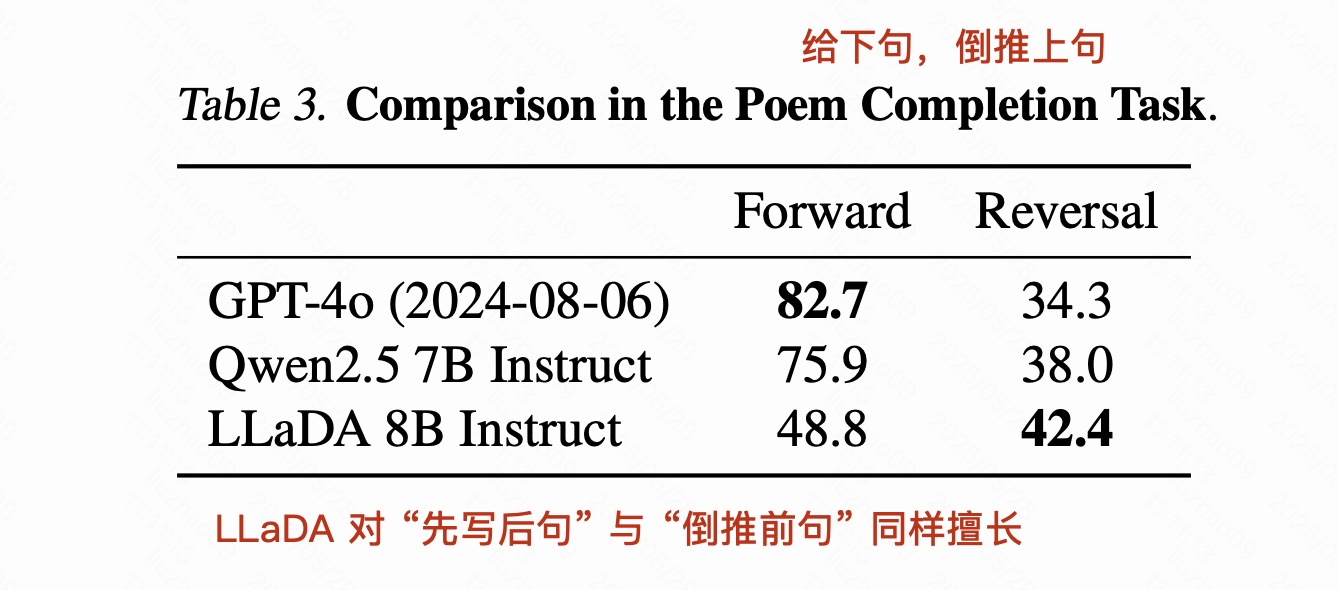
3.4 case study
