目录
- [1. Introduction of Deep Learning](#1. Introduction of Deep Learning)
-
- [1.1. Neural Network - A Set of Function](#1.1. Neural Network - A Set of Function)
- [1.2. Learning Target - Define the goodness of a function](#1.2. Learning Target - Define the goodness of a function)
- [1.3. Learn! - Pick the best function](#1.3. Learn! - Pick the best function)
-
- [Local minima](#Local minima)
- Backpropagation
- [2. Tips for Training Deep Neural Network](#2. Tips for Training Deep Neural Network)
- [3. Variant of Neural Network](#3. Variant of Neural Network)
- [4. Next Wave](#4. Next Wave)
对一天搞懂深度学习--李宏毅教程分享内容做读书笔记,对深度学习中的神经网络进行介绍
1. Introduction of Deep Learning
深度常用于语音识别、手写文字识别、围棋、对话等多个领域。
深度学习的目标是构建一个模型,这个模型就是Network就是指神经网络,深度学习就是构建这个模型的过程。构建这个模型的过程只有三步:
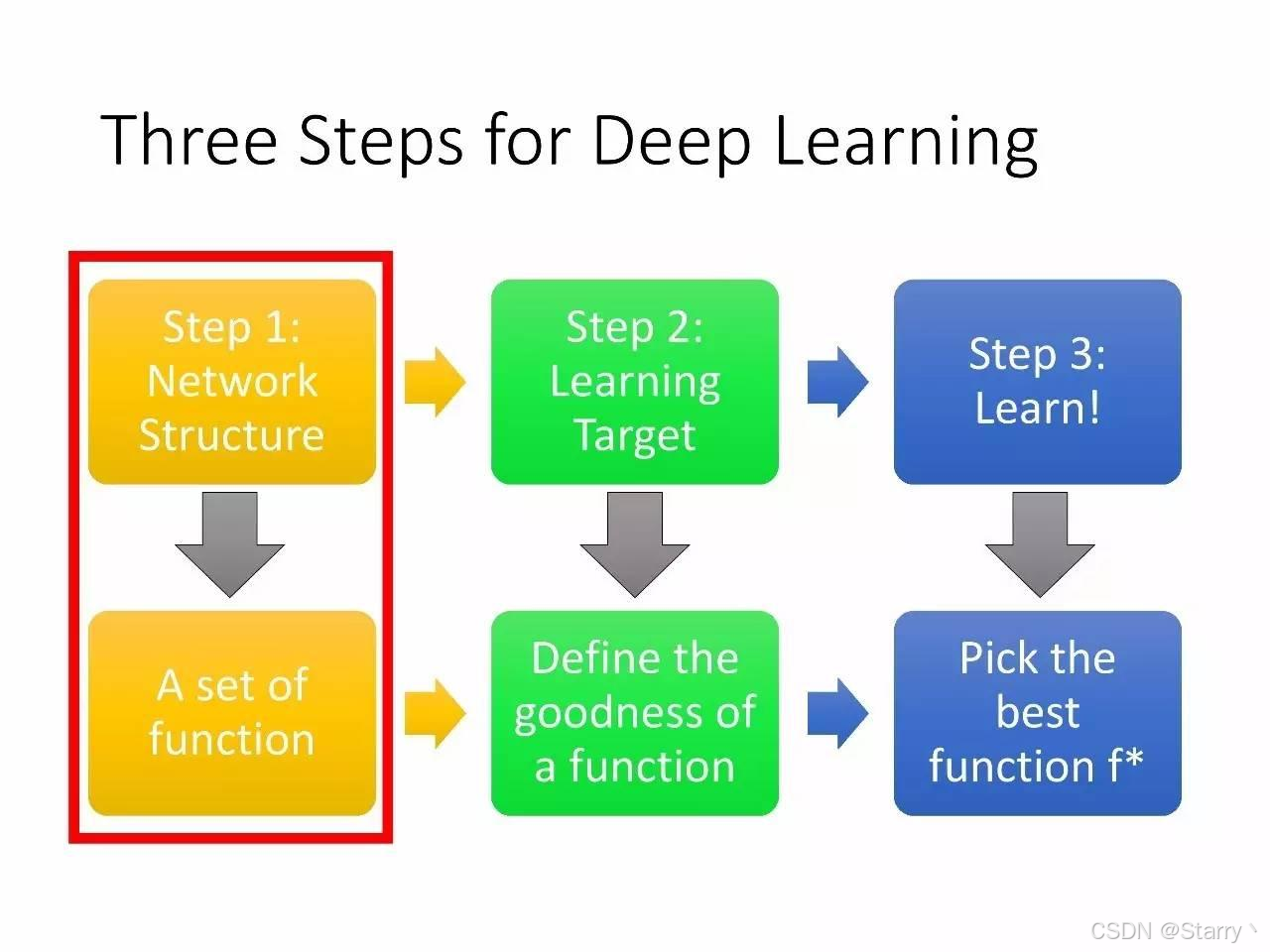
1.1. Neural Network - A Set of Function
首先介绍这个模型(神经网络)是什么样子的。
先介绍神经元,Neuron也是一种函数,如下所示
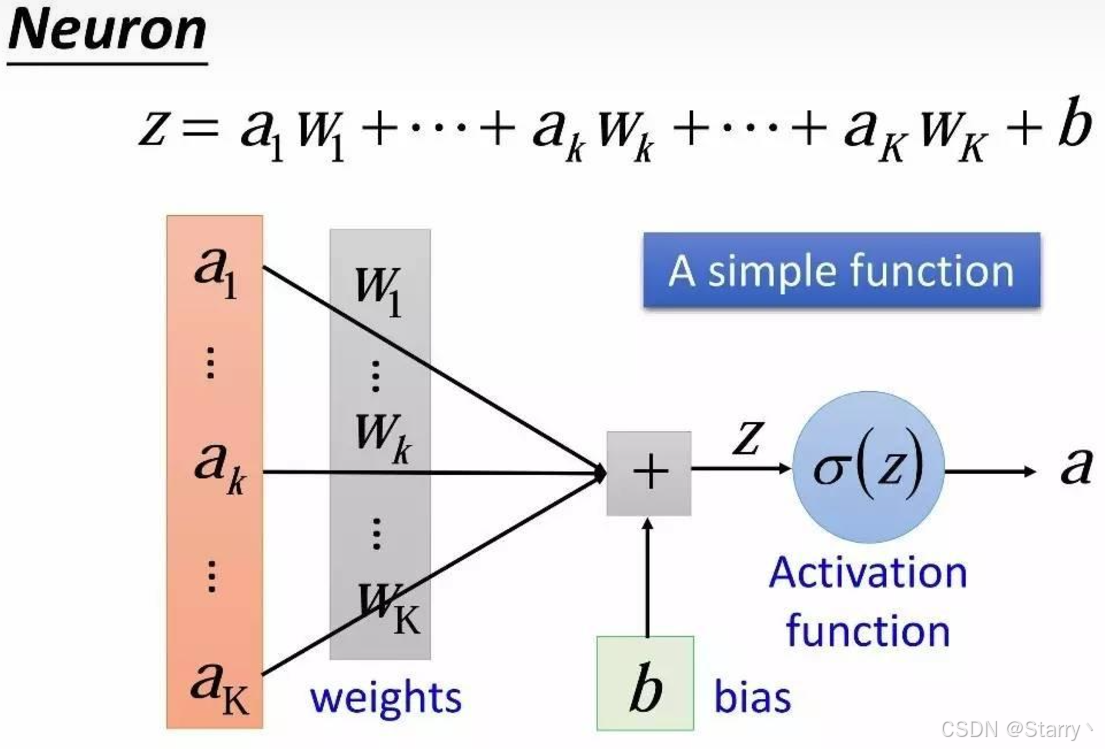
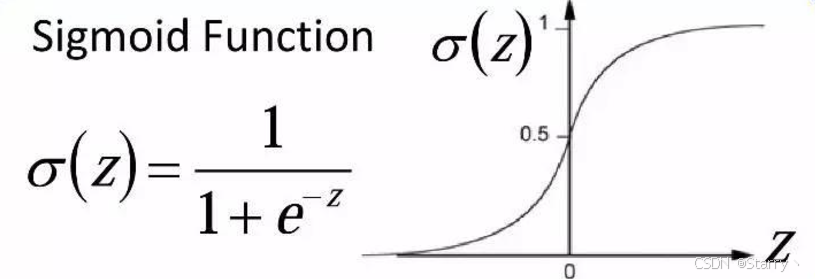
其中激活函数Activation Function为Sigmoid:
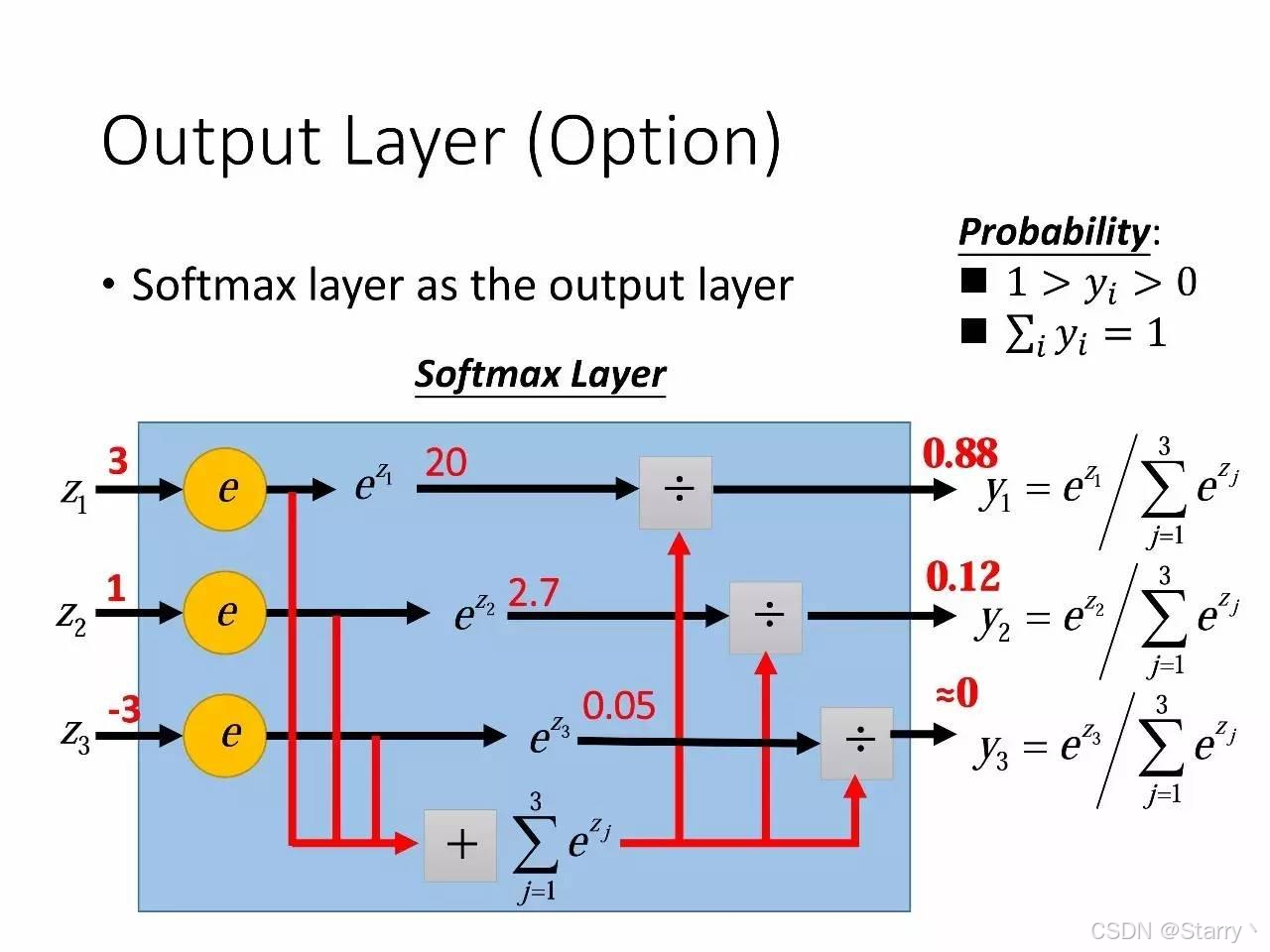
由多个神经元相互全连接即为全连接的反向网络Fully Connect Feedforward Network,由多层Layers组成(不同模型Layers不同),如下图所示
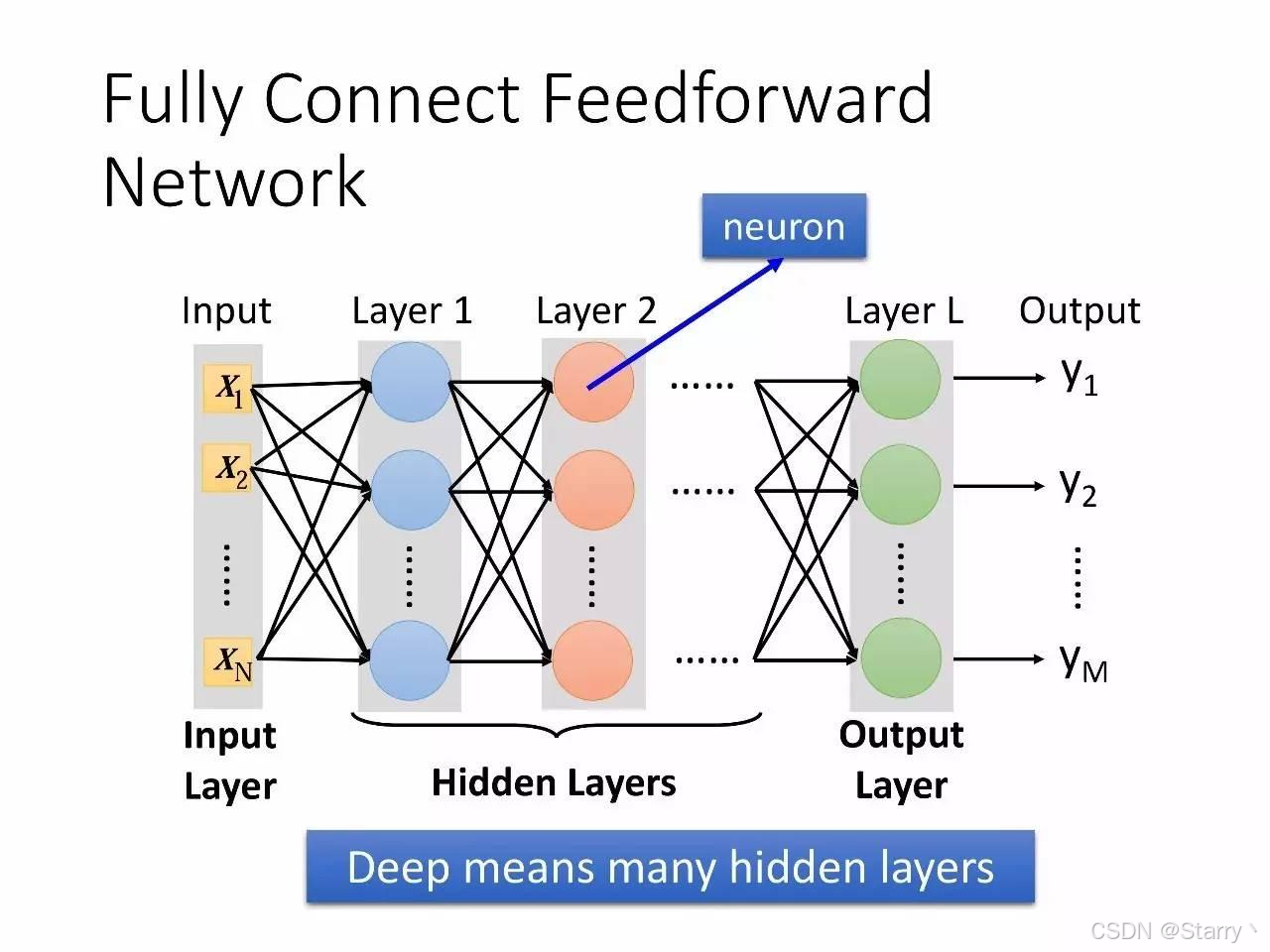
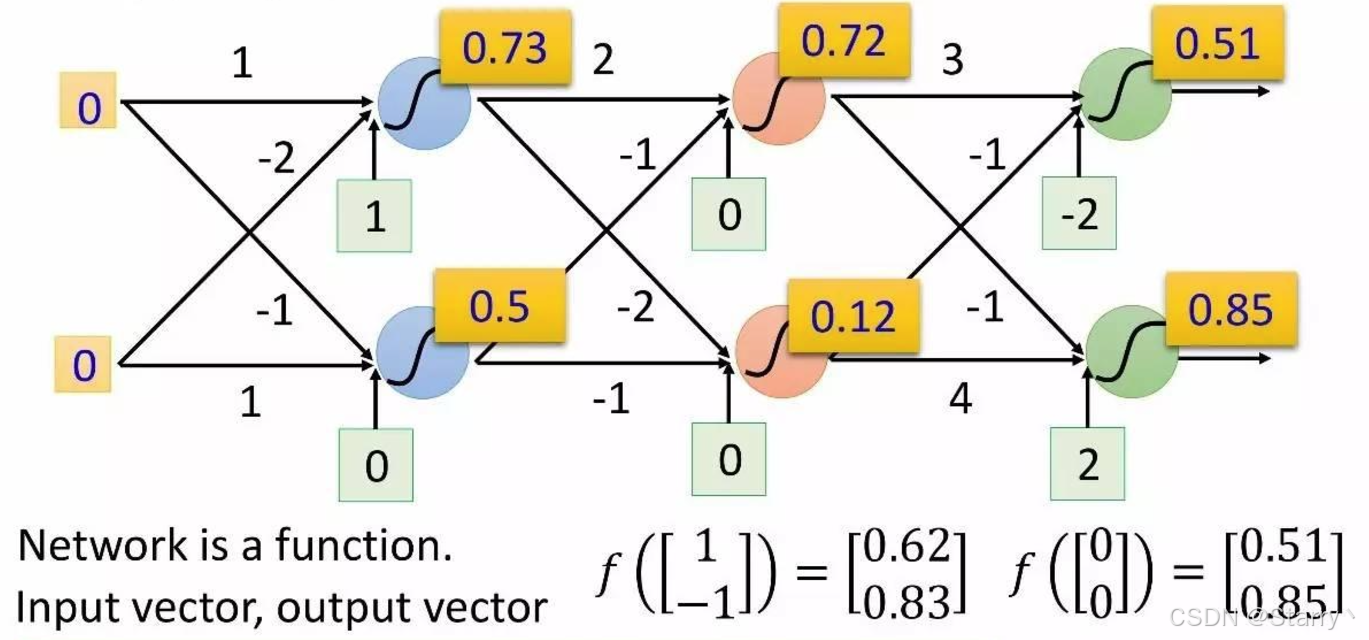
记作 { y 1 , . . . y M } = f ( { x 1 , . . . , x N } ) \{y_1,...y_M\}=f(\{x_1,...,x_N\}) {y1,...yM}=f({x1,...,xN})
最终的输出使用softmax激活函数进行归一化,用于将每种输出转换为概率分布
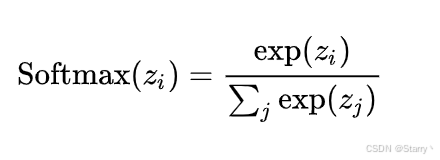
最终得到
神经网络本质就是一种函数关系,不同的input vector可得到不同的output vector
1.2. Learning Target - Define the goodness of a function
知道模型的样子之后,深度学习的目标是找到神经网络中最合适的weights和bias。
怎么定义最合适?最合适的意思是,这个模型的输出是我们想要的理想输出。所以,使用已经标记好的训练数据喂给模型,模型的输出应该是我们的理想期望值。
例如,手写识别场景下,输入左图,期望输出应该是y2为最大值(表示模型的预期输出是2),使用softmax激活函数则期望输出为 y ^ = 0 , 1 , 0 , . . . , 0 \hat{y}=0,1,0,...,0 y^=0,1,0,...,0
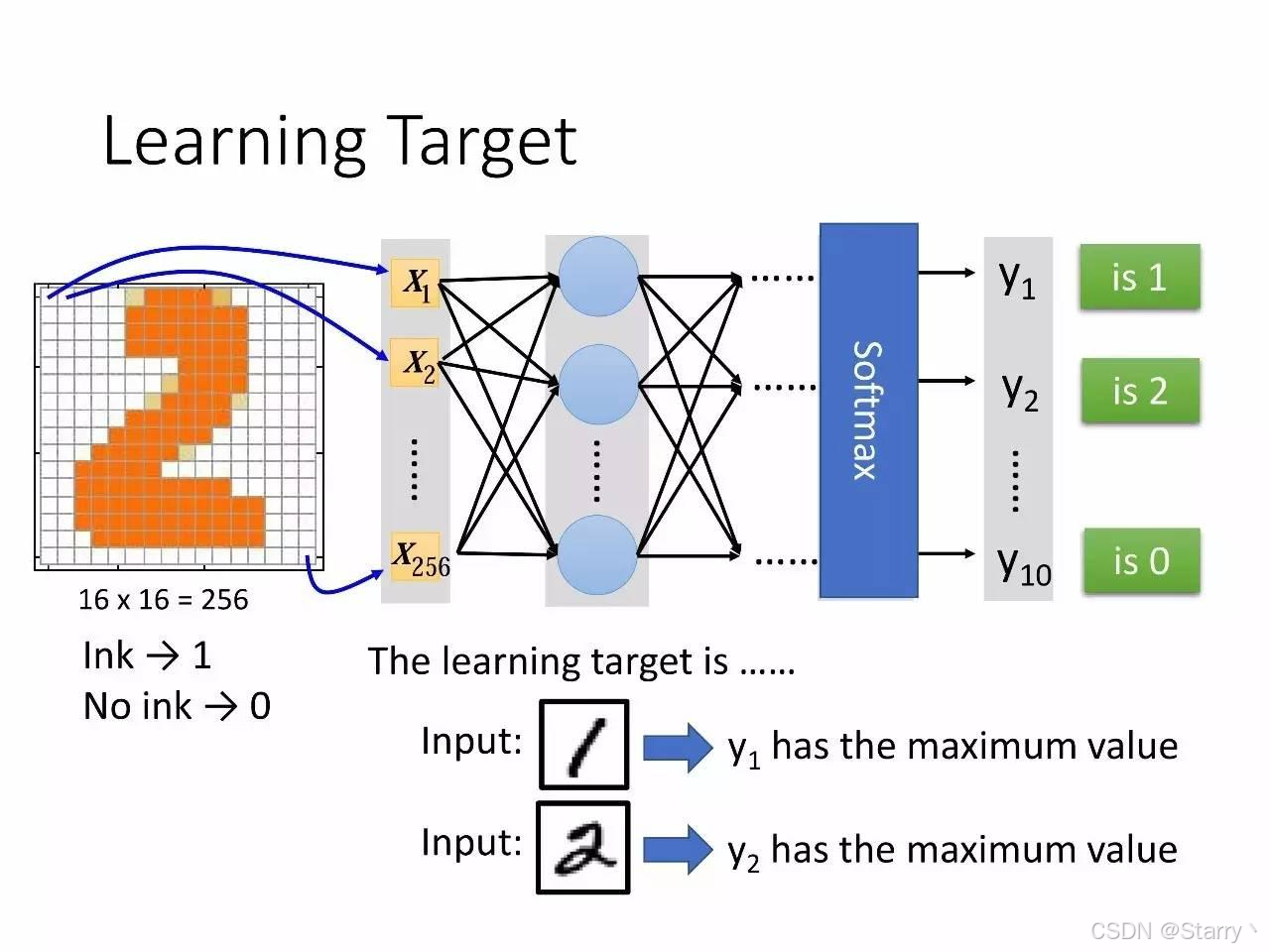
所以,模型应该适应我们的训练数据。即给定训练数据输入 { x ^ 1 , . . . , x ^ 256 } \{\hat{x}1,...,\hat{x}{256}\} {x^1,...,x^256},模型的输出应该最接近我们的训练数据输出 { y ^ 1 , . . . , y ^ 10 } \{\hat{y}1,...,\hat{y}{10}\} {y^1,...,y^10}。
最接近的含义就是square error最小,这个square error就叫损失函数/代价函数,如下
l r = ∑ i = 1 10 ( y i − y ^ i ) 2 (1) l_r=\sum_{i=1}^{10}{(y_i-\hat{y}_i)^2} \tag{1} lr=i=1∑10(yi−y^i)2(1)
而且满足
{ y ^ 1 , . . . y ^ 10 } = f ( { w 1 , . . . , w N , b 1 , . . . , b M } , { x ^ 1 , . . . , x ^ 256 } ) (2) \{\hat{y}1,...\hat{y}{10}\}=f(\{w_1,...,w_{N},b_1,...,b_{M}\},\{\hat{x}1,...,\hat{x}{256}\}) \tag{2} {y^1,...y^10}=f({w1,...,wN,b1,...,bM},{x^1,...,x^256})(2)
例如上图损失函数就为 l = ( y 1 − 0 ) 2 + ( y 2 − 1 ) 2 + ( y 3 − 0 ) 2 + . . . + ( y 10 − 0 ) 2 l=(y_1-0)^2+(y_2-1)^2+(y_3-0)^2+...+(y_{10}-0)^2 l=(y1−0)2+(y2−1)2+(y3−0)2+...+(y10−0)2
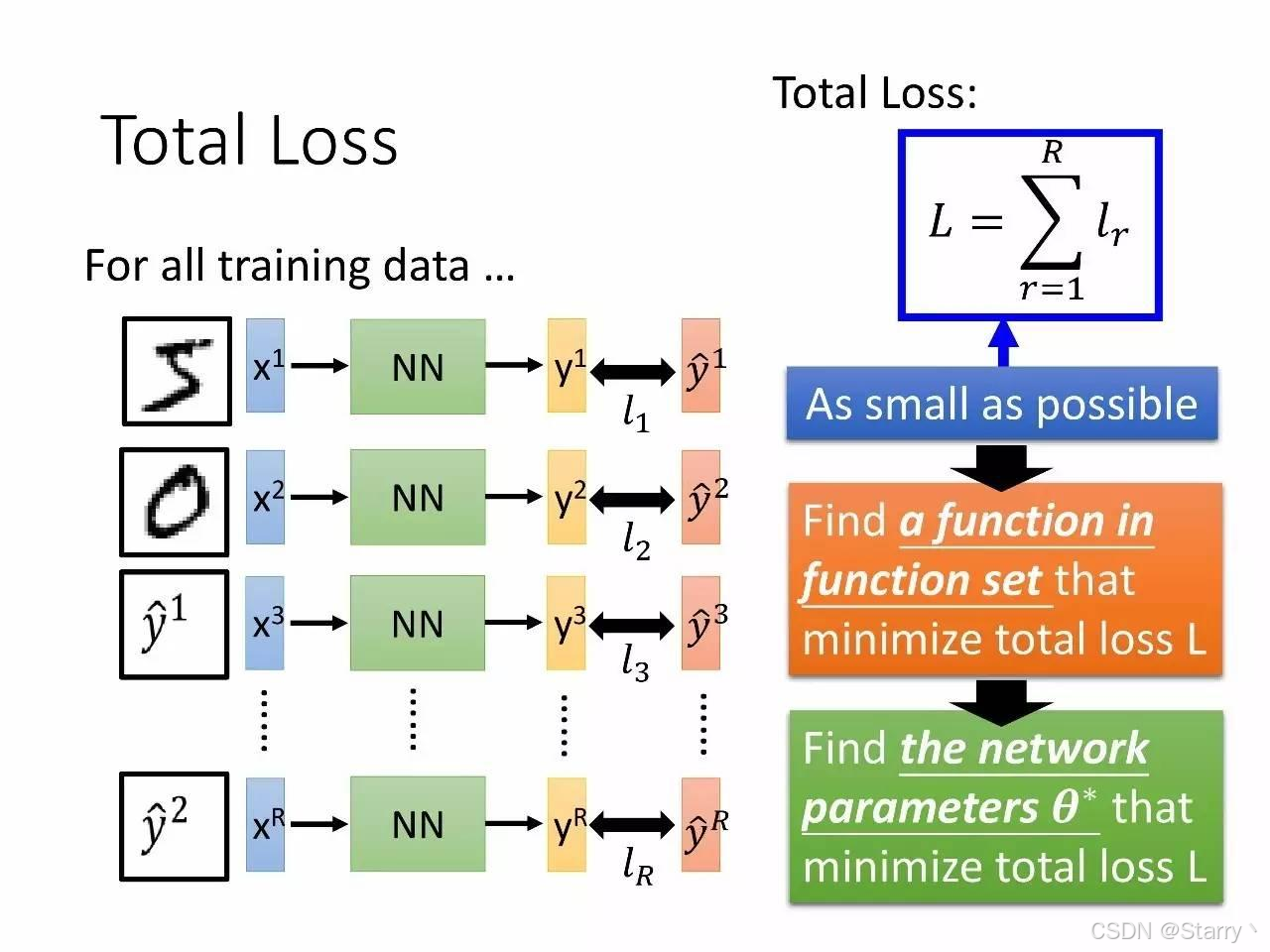
那么整个模型的损失函数如下,其中R为训练样本个数
L = ∑ r = 1 R l r (3) L=\sum_{r=1}^{R}{l_r} \tag{3} L=r=1∑Rlr(3)
所以,深度学习的终极目的是,寻找合适的 { w 1 , . . . , w N , b 1 , . . . , b M } \{w_1,...,w_{N},b_1,...,b_{M}\} {w1,...,wN,b1,...,bM}满足式(1)(2)使式(3)最小,如下图。
1.3. Learn! - Pick the best function
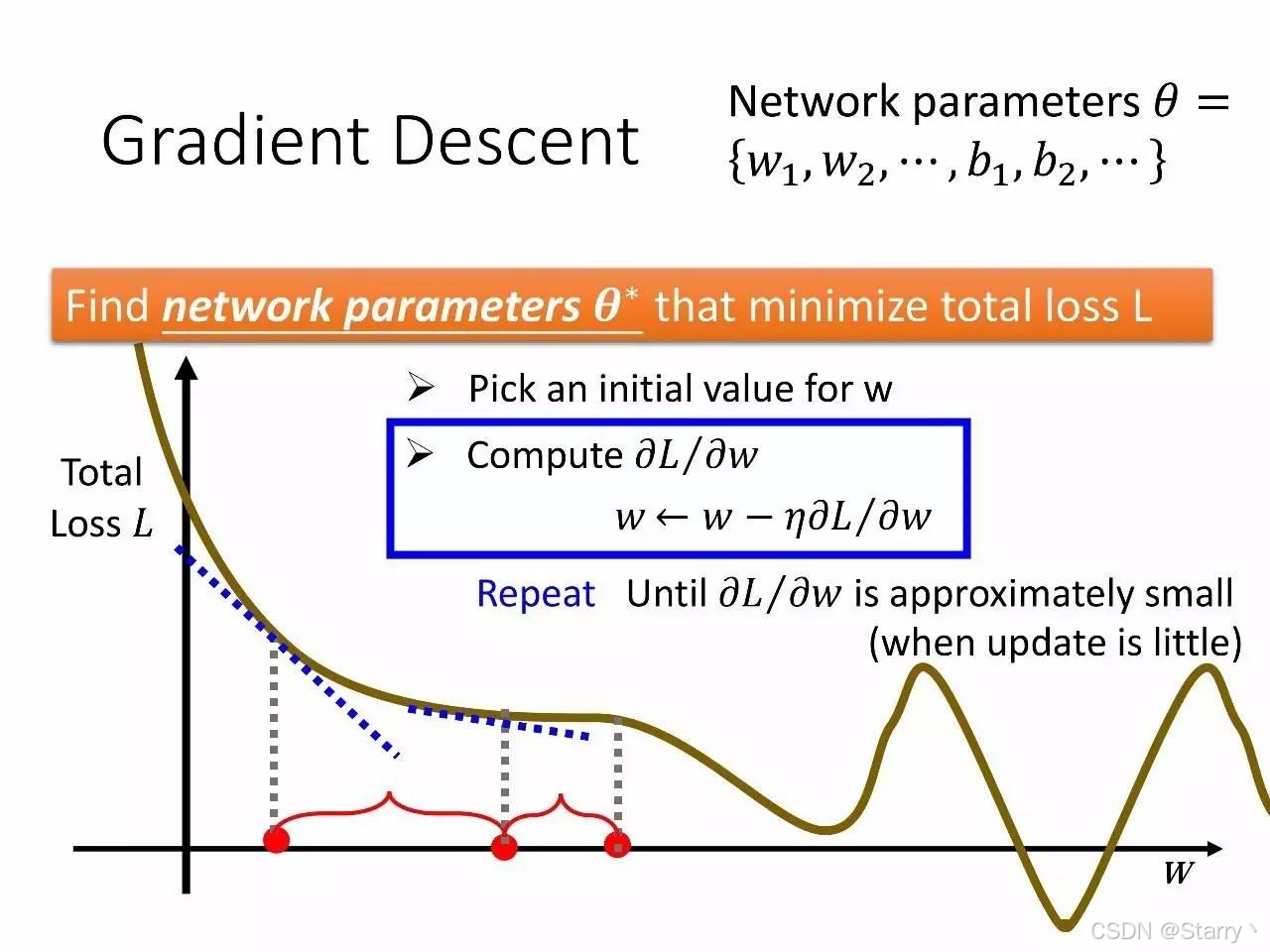
那么如何找到最优的 θ = { w 1 , . . . , w N , b 1 , . . . , b M } \theta=\{w_1,...,w_{N},b_1,...,b_{M}\} θ={w1,...,wN,b1,...,bM}使式(3)最小呢?方法就是著名的梯度下降法Gradient Descent,步骤如下。
Step 1. 通过随机化方法赋予 θ \theta θ一个初始值 θ = θ i \theta=\theta_{i} θ=θi
Step 2. 将 l l l在 θ = θ i \theta=\theta_{i} θ=θi处对 θ \theta θ的每一个参数求偏微分,得到的向量就是梯度
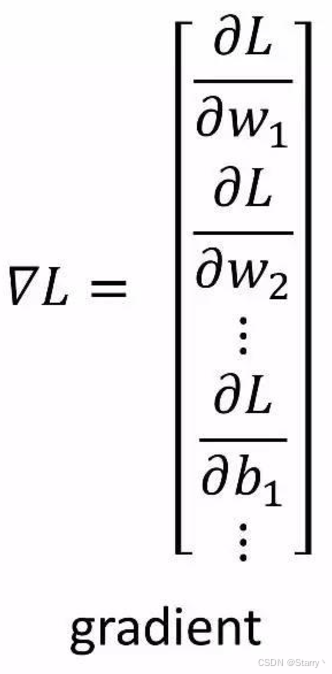
梯度的含义就是,在当前点函数上升最快的方向,所以梯度的反方向就是最快到达最小值的方向。
一个神经网络模型的参数非常多,如果直接用损失函数对每个参数作偏导,计算量巨大、梯度的维度也巨大。为了简便计算量,一般使用Backpropagation反向传播的方法计算梯度。
Step 3. 判断当前点的梯度是否足够小,即 ∇ L ∣ θ = θ i < ϵ \nabla L|{\theta=\theta{i}}<\epsilon ∇L∣θ=θi<ϵ。如果是则输出 θ = θ i \theta=\theta_{i} θ=θi得到损失函数最小的模型参数。如果否则跳转Step 4.
Step 4. 给定学习率/步长 μ \mu μ,对各参数 θ \theta θ进行调整,即
θ i + 1 = θ i − μ ⋅ ∇ L ∣ θ = θ i \theta_{i+1}=\theta_{i}-\mu·\nabla L|{\theta=\theta{i}} θi+1=θi−μ⋅∇L∣θ=θi
这个式子类似通过导数的方法去试最小值,当导数为正时, θ \theta θ降低、导数为负时, θ \theta θ增加,如下图所示。
Local minima
但是梯度下降法找到的一定是局部最小值,不保证找到的是全局最小值。如下图
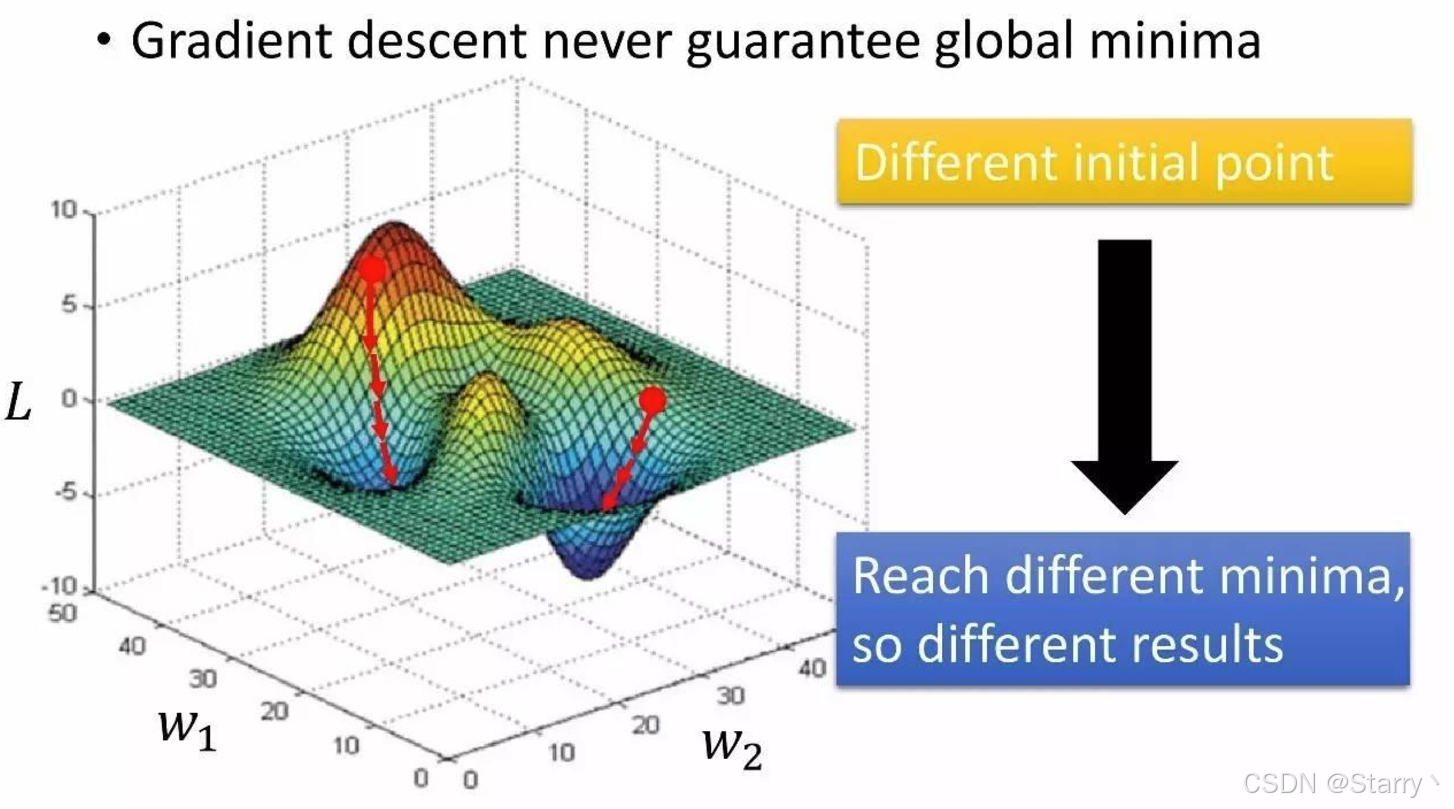
所以可以设定不同的初始值执行梯度下降,在所有的极小值中找一个在 L L L的最小值作为模型的最优参数。
Backpropagation
反向传播,一种高效计算梯度的方法。