高效微调简述
一、微调与RAG的区别:

针对成本和性价比选择RAG或微调,那他们适用的范围和区别要提前了解;

形象的描述预训练、微调、提示工程、Agents:

微调流程:
数据保密那就是私域微调,否则就可以线上微调
二、Frozen Fine-tuning(冻结微调)
只更新模型的输出层或顶层权重,其他层权重冻结也叫顶层微调
三、Layer-wise-Fine-tuning(逐层微调)
更新顶层权重后逐层解冻调整下一层,效果好但算法复杂
四、Dyamic Fine-tuning (动态微调)
在微调过程中动态调整lr、batchsize等超参,优化模型性能,效果好操作难度大
五、提示词微调方向:
专注于优化模型的输入提示词,而非直接调整模型结构,通过改进输入提升输出质量,追求更通用方案;
5.1 Prefix-tining(前缀微调)
模型权重冻结,在每一层加一个神经网络引导这一层对特定任务进行指导性输出和权重倾斜计算;
eg:要求模型生成一个描述图片的句子,给输入增加一个前缀向量"比如这是一辆家用小轿车",那么引导模型生成前缀向量方向的图片描述;
5.2 Prompt tuning(提示微调)
设计优化输入提示引导模型生成方向,只在输入层增加embedding前缀,使用固定一种或多种提示词;当用户输入其中一种完成相同的提示词,会让模型输出的效果更稳定;
5.3 P-tuning:
采用"连续提示embedding+离散提示"组合,比如加上"这是一辆车,车包括轮子、座位发动机等";
在大模型效果很好,但在参数量小的模型效果差;
5.4 P-tuning v2:
在所有transformer层进行向量化嵌入,针对初始化策略进行优化,减少对初始化权重输出比重,方便进行自我调整;
六、外部引入方向:
6.1 Adapter Tuning(适配器微调)
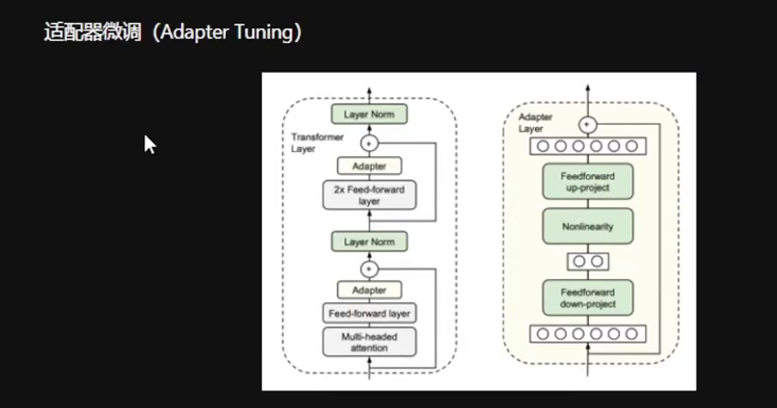
定义:通过在预训练模型中各层插入适配器模块(Adapters)实现对特定任务适应,不更新模型权重
how:每个模型少量参数,低维-高维互相映射,使得模型更高效处理数据;包含残差结构保证原始输入信息不受损失; Adapter可以大模型不同层插入多个实例,针对不同场景进行微调,实现模型灵活适应性和多功能性;
6.2 Low-Rank Adaptation(低秩矩阵微调Lora)
LoRA的核心思想是将预训练模型的权重矩阵分解成两个低秩矩阵的乘积。通过冻结原矩阵+两个低秩矩阵乘积来适应新任务;
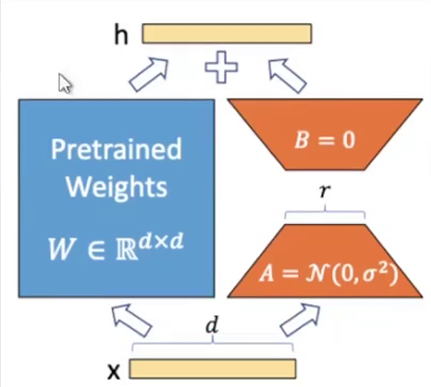
LoRA的核心思想是将预训练模型的权重矩阵分解成两个低秩矩阵的乘积。通过冻结原矩阵+两个低秩矩阵乘积来适应新任务;