一般来说,一个经过指令格式化的数据实例包括任务描述(也称为指令)、任务输入、任务输出以及可选的示例。
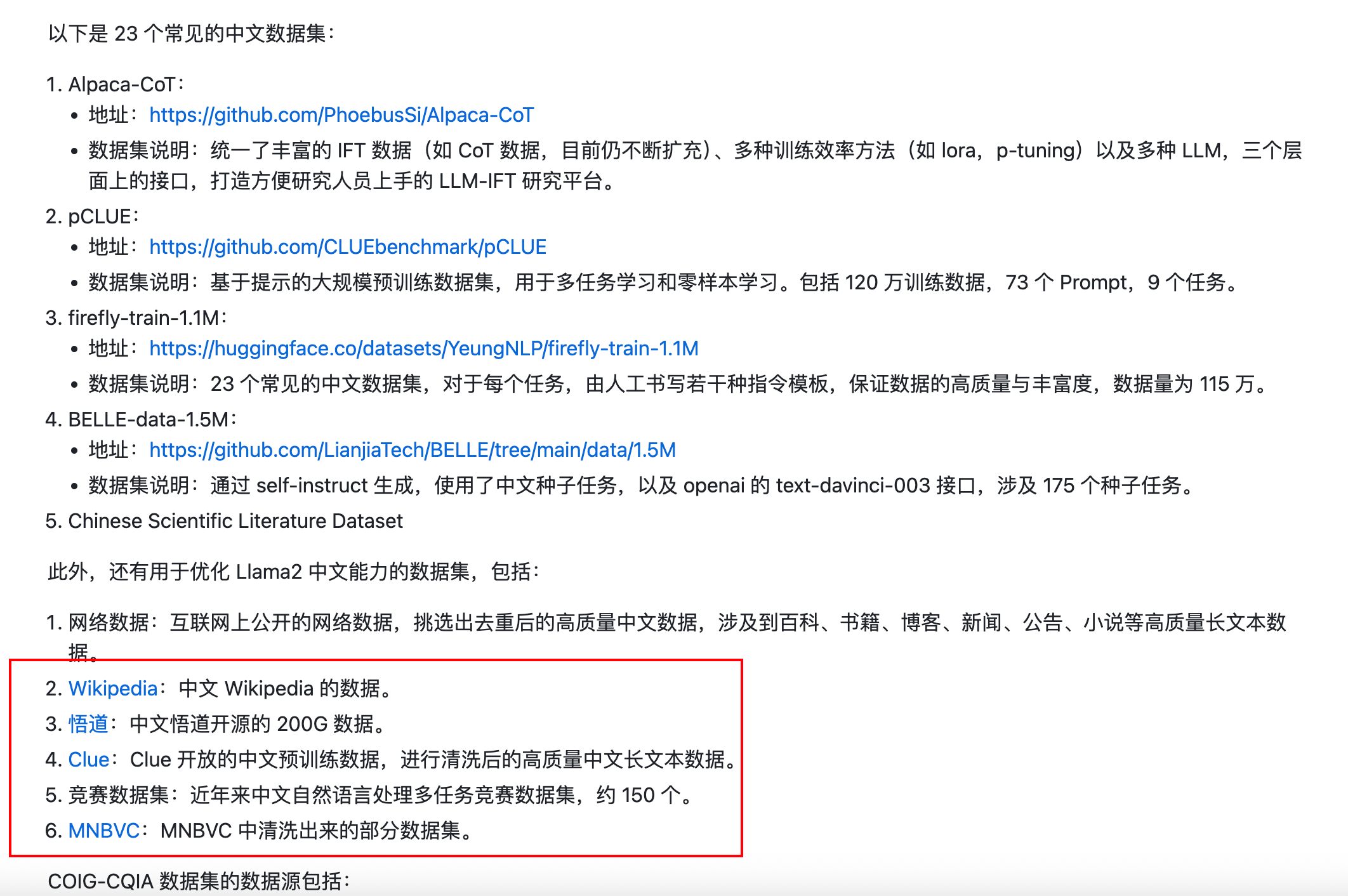
公开的数据集:https://www.waytoagi.com/zh/question/51049
1. 基于现有的NLP 任务数据集构建
学术界围绕传统NLP 任务(如机器翻译、文本摘要和文本分类等)发布了大量的开源数据集合,这些数据是非常重要的监督学习数据资源,可以用于指令数据集的构造。其实就是把原来的 NLP 任务增加指令描述,将原来的输入和输出对转化为生成任务。
例如在中英翻译任务中
输入是:"大语言模型已经成为机器学习的一个重要研究方向"
输出则是"Large language models have become one important researchdirection for machine learning"。
为了生成指令化的训练数据,一个非常关键的步骤就是为上述的"输入-输出"对数据添加任务描述信息,++请把这个中文句子翻译成英文++,于指导模型去理解任务目标以及相关信息。
javascript
{
"instruction": "请把这个中文句子翻译成英文",
"input": "大语言模型已经成为机器学习的一个重要研究方向",
"output": "Large language models have become one important researchdirection for machine learning"
}另外还能把输入输出对反过来:
Kotlin
{
"instruction": "请把这段英文翻译成中文",
"input": "Large language models have become one important researchdirection for machine learning",
"output": "大语言模型已经成为机器学习的一个重要研究方向"
}2. 基于日常对话数据构建
尽管通过指令格式化已有的NLP 数据集能够获得大量的指令数据实例,但是这些数据的多样性比较局限,与人类的真实需求也不能很好匹配。为此,研究人员开始使用用户在日常对话中的实际需求作为任务描述。
通常情况下对话数据尤其是多轮对话数据较少,大多数会采用人工标注的形式构建,开源的数据较少。而对于垂直领域的高质量对话数据就更少了,几乎只能通过人工标注构建,对于很多企业来说成本极其高。

3. 基于合成数据构建
为了减轻人工收集与标注数据的负担,研究人员进一步提出半自动化的数据合成方法。他们借助已有的高质量指令数据作为上下文学习示例输入大语言模型,进而生成大量多样化的任务描述和输入-输出数据。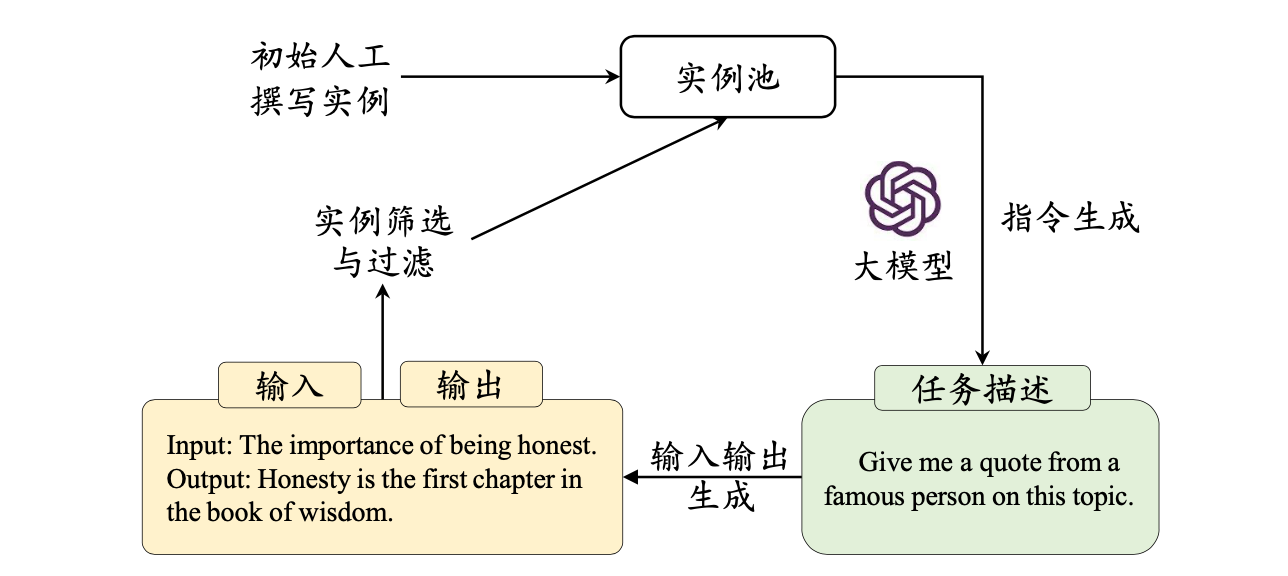
代表性工作Self-Instruct 方法仅需要使用100 多个人工撰写的实例作为初始任务池,然后随机选择数据作为示例,就可以通过提示大语言模型生成新的指令微调数据。这种半自动化的合成方法具备高效生成大规模指令微调数据的能力,从而显著降低了人工标注所需的经济成本,在实践中得到了广泛应用。
我们在企业中通常会采用人工+大模型的方式,半手工的构建高质量的 SFT 数据集。
4. 指令数据构建的提升方法
在指令微调中,指令数据的格式、数量等因素对微调后的模型性能有着重要影响。下面将从指令格式设计、扩展指令数量、指令重写与筛选等三个方面介绍如何构建高质量的指令数据集。
4.1 指令格式
指令格式 是影响大模型性能的一个重要因素。通常来说,可以直接向现有NLP 数据集的输入- 输出对上添加任务描述构建指令微调数据 ,还可以引入适当数量的实例作为上下文示例一起作为模型的输入,提升模型的实际性能,缓解模型对于指令格式的敏感性。
为了激发大模型的逐步推理能力,研究人员还尝试在指令微调数据集中**引入思维链数据**,通过这种混合指令数据微调后的模型在多种下游任务中都取得了较好的效果,包括需要多跳推理能力的任务(例如常识问答和算术推理)以及不需要多跳推理的任务。
4.2 扩展指令数量
对于NLP 任务数据集而言,FLAN-T5 研究了指令数量对于模型在未知NLP 任务上的性能影响。通过逐步将指令数量扩展至0.18M、5.55M、7.2M 以及17.26M,研究人员发现模型性能呈持续上升的趋势。然而,当指令数量达到7.2M后,模型性能的提升变得非常缓慢。
4.3 指令重写与筛选
面对众多的公开指令数据集,研究者们开始尝试使用一些重写或者筛选机制,来提高指令数据的质量或者多样性.
具体操作如下:
预先从知乎收集了多种常见主题标签(例如,"教育","体育"),然后随机选择一种并使用ChatGPT 对指令进行重写来适配到相应的主题(例如使用提示:"请帮我把以下指令重写为教育主题" ),最后进行质量筛选来获取高质量的多样性指令数据。
总之:相比于数据的数量,数据质量更加的重要。某些情况下,垂直领域的几百条高质量数据微调大模型,也能取得很好指令遵从能力。
5. 总结
总体来说,指令的质量比数量更为重要。指令微调中应该优先使用人工标注的多样性指令数据。然而,如何大规模标注符合人类需求的指令数据目前仍然缺乏规范性的指导标准(比如什么类型的数据更容易激发大模型的能力)。在实践中,可以使用ChatGPT、GPT-4 等闭源大语言模型来合成、重写、筛选现有指令,并通过数量来弥补质量和多样性上的不足。