文章目录
- Pre
- [1. 引言](#1. 引言)
- [2. 缓冲概念与类比](#2. 缓冲概念与类比)
- [3. Java I/O 中的缓冲实现](#3. Java I/O 中的缓冲实现)
-
- [3.1 FileReader vs BufferedReader:装饰者模式设计](#3.1 FileReader vs BufferedReader:装饰者模式设计)
- [3.2 BufferedInputStream 源码剖析](#3.2 BufferedInputStream 源码剖析)
-
- [3.2.1 缓冲区大小的权衡与默认值](#3.2.1 缓冲区大小的权衡与默认值)
- [4. 异步日志中的缓冲:Logback 异步日志原理与配置要点](#4. 异步日志中的缓冲:Logback 异步日志原理与配置要点)
-
- [4.1 Logback 异步日志原理](#4.1 Logback 异步日志原理)
- [4.2 核心配置示例](#4.2 核心配置示例)
-
- [4.2.1 三个关键参数](#4.2.1 三个关键参数)
- [5. 缓冲区设计思路---同步 vs 异步](#5. 缓冲区设计思路—同步 vs 异步)
-
- [5.1 同步缓冲](#5.1 同步缓冲)
- [5.2 异步缓冲](#5.2 异步缓冲)
- [6. Kafka 生产者缓冲示例](#6. Kafka 生产者缓冲示例)
-
- [6.1 Kafka 生产者缓冲原理](#6.1 Kafka 生产者缓冲原理)
- [6.2 缓冲区丢数据风险](#6.2 缓冲区丢数据风险)
- [6.3 缓冲区过载与业务可用性](#6.3 缓冲区过载与业务可用性)
- [7. 其他缓冲场景与示例](#7. 其他缓冲场景与示例)
- [8. 注意事项与异常场景](#8. 注意事项与异常场景)
- [9. 小结](#9. 小结)

Pre
- 引言:重温缓冲本质与设计动机;
- 缓冲概念与类比:蓄水池与生产线示例;
- Java I/O 中的缓冲实现:
3.1 FileReader vs BufferedReader,装饰者模式设计;
3.2 BufferedInputStream 源码剖析(fill() 逻辑与缓冲区扩容);
3.3 缓冲区大小的权衡与默认值(8KB); - 异步日志中的缓冲:Logback 异步日志原理与配置要点(queueSize、maxFlushTime、discardingThreshold);
- 缓冲区设计思路---同步 vs 异步:
5.1 同步缓冲:单线程或方法内批量触发策略;
5.2 异步缓冲:生产者策略(抛弃/阻塞/异常)与多线程消费者的同步问题; - Kafka 生产者缓冲示例:batch.size、linger.ms 如何影响消息丢失与可用性;
- 其他缓冲场景与示例:StringBuilder/StringBuffer、操作系统网络缓冲、数据库 Buffer Pool、ID 生成器缓存;
- 注意事项与异常场景:缓冲区数据丢失风险、预写日志与 WAL 简述;
- 小结:缓冲区优化的收益与权衡;
1. 引言
在 性能优化 - 理论篇:性能优化的七类技术手段 中,已经初步了解"复用优化"领域下的两大子方向:缓存(Cache) 与 缓冲(Buffer)。
接下来我们聚焦于"缓冲"这一个技术手段,深入理解它在 Java 语言与中间件中的各类应用场景,以及在设计时需要注意的权衡与异常处理。
为什么要用缓冲?
- 设备之间速度差异:CPU/内存读写速度≪磁盘或网络 I/O;
- 频繁、小量的随机 I/O 会导致寻道或上下文切换开销巨大;
- 缓冲通过在内存中聚合数据,批量顺序写/读,显著提高吞吐。
接下来,将从概念、源码、配置与设计思路几个维度展开,对"缓冲"有一个系统化的认识。
2. 缓冲概念与类比
缓冲(Buffer)最本质的作用,是将"生产方"与"消费方"之间的不一致速度,化解为一个容量有限的"中间池"。
-
蓄水池比喻:
- 放水端(消费方):以恒定速率流出,就如程序中读取缓冲区后进行处理;
- 进水端(生产方):速率不确定,可能快也可能慢,就如磁盘或网络向缓冲写数据;
- 缓冲区(蓄水池)大小:当进水过快或消费端处理慢时,水就会在池中积累;当池满时,生产方必须等待或做其他处理。
-
包饺子流水线:
- 擀皮工序 vs 包馅工序,如果一擀一交彼此就停止,效率低;
- 加入一个盆子作为中间缓冲,擀皮不断往盆里扔,包馅者随时取用,两者最大限度保持各自节奏。
从宏观而言,Java 的堆本身也可视作一个"对象缓冲区"------应用线程在其中不断分配对象,而垃圾回收线程(GC)则以另一种节奏"消费"这些对象。
对比于"缓存(Cache)",缓冲侧重于写(或读)过程中的批量与顺序,让慢速设备前端获得"可持续的小幅流量"。
3. Java I/O 中的缓冲实现
在 Java 中,缓冲最常见的应用场景就是文件与网络 I/O。底层设备(如磁盘、Socket)本身速度较慢,而 Java I/O 通过装饰者模式,将原始流包装为"带缓冲的流",让单次 read()/write() 调用变为"先读/写到内存缓冲区,再批量交给底层设备"。
3.1 FileReader vs BufferedReader:装饰者模式设计
-
FileReader :直接从磁盘逐个字符读取,一次
read()需要:- 操作系统触发文件系统寻道,读取一个字节到内核缓冲;
- 再从内核缓冲拷贝到用户空间;
- 返回给应用。
由于每调用一次
read()都要重复上述步骤,效率极低。 -
BufferedReader :以
Reader reader = new BufferedReader(new FileReader(path))方式包装后:- 在首次
read()时,会一次性将后续buffer.length个字节(默认 8KB)读入 Java 堆内存中的 byte\[\] buffer; - 之后的多次调用
read(),只需从内存buffer中读取字符,直到pos >= count,才触发下次fill(); - 大多数情况下,减少了对磁盘和内核空间的多次交互。
这种添加功能而不修改原类代码的模式,就是装饰者(Decorator)模式。
javapublic class Demo { public int readWithoutBuffer(String path) throws IOException { int result = 0; try (Reader reader = new FileReader(path)) { int value; while ((value = reader.read()) != -1) { result += value; } } return result; } public int readWithBuffer(String path) throws IOException { int result = 0; try (Reader reader = new BufferedReader(new FileReader(path))) { int value; while ((value = reader.read()) != -1) { result += value; } } return result; } }- 如果将两段代码用 JMH 对比测试,后者在绝大多数文件大小与硬件环境下,都能以数倍乃至十数倍的速度胜出(未考虑 OS page cache)。
- 在首次
3.2 BufferedInputStream 源码剖析
以 BufferedInputStream 为例,下面我们重点关注它的 read() 与 fill() 实现,理解缓冲区如何管理数据。
java
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos)
? pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
buf = nbuf;
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}-
pos与count:pos:当前缓冲区已经消费到的位置索引;count:缓冲区中实际可用字节数(读取自底层 InputStream)。
-
当
pos >= count时,调用fill():- 无 mark 逻辑 :如果未在流上调用过
mark(),则直接pos = 0,丢弃旧缓冲区内容; - 有 mark 逻辑 :如果调用过
mark()并且buffer尚未超过marklimit,会先将buffer[markpos, pos)部分拷贝到buffer[0, sz),保留标记区域;否则当buffer大小接近marklimit,会放弃缓存并重置markpos = -1。 - 缓冲区扩容 :若
buffer.length < marklimit且pos >= buffer.length,则按pos*2或marklimit的大小扩容,以承载更多数据(最大不超过MAX_BUFFER_SIZE)。
- 无 mark 逻辑 :如果未在流上调用过
-
从底层流读取数据:
- 调用
getInIfOpen().read(buffer, pos, buffer.length - pos),一次性将尽量多的数据填入buffer[pos, buffer.length); - 读取后把
count = pos + n,表示新的缓冲区可读取字节数。 - 随后
read()方法从内存buffer中依次提供单字节给调用者。
- 调用
这样,绝大多数 reader.read() 调用都不会触发一次真正的磁盘或网络 I/O,而是走内存读取,直到缓冲耗尽才会调用一次底层的 read(...)。
3.2.1 缓冲区大小的权衡与默认值
-
为什么不一次性把整个文件都读到缓冲?
- 缓冲区太小时,需要频繁地调用
fill(),失去缓冲效果; - 缓冲区太大,单次
fill()就涉及大量内存分配并可能导致垃圾回收压力; - 默认缓冲区大小一般为 8192 字节(8KB),是工业界常见的折中值,既能减少单次
fill()带来的系统调用开销,又不会占用过多堆内存。
- 缓冲区太小时,需要频繁地调用
-
调整缓冲区大小的思路:
- 对于小文件或小 HTTP 响应,可将缓冲区设置为 4KB 或更小,减少内存消耗;
- 对于大文件复制、视频流处理等场景,可适当增大为 32KB 或 64KB,以减少 I/O 调用频率;
- 但文件过大时,缓存整个文件到内存会导致 OOM,因此需结合实际业务与可用堆内存大小,谨慎配置。
4. 异步日志中的缓冲:Logback 异步日志原理与配置要点
在高并发服务中,同步日志会成为性能瓶颈:
- 每次调用
logger.info(...)都要先拼接日志消息,再调用底层 I/O 将文本写入磁盘; - 如果并发量大,业务线程在等待磁盘 I/O 完成时被阻塞,整体延迟显著增加;
- 即便日志输出到控制台,也会占用 CPU 时间来格式化。这时可以引入"异步日志"来解耦业务线程与磁盘写入。
4.1 Logback 异步日志原理
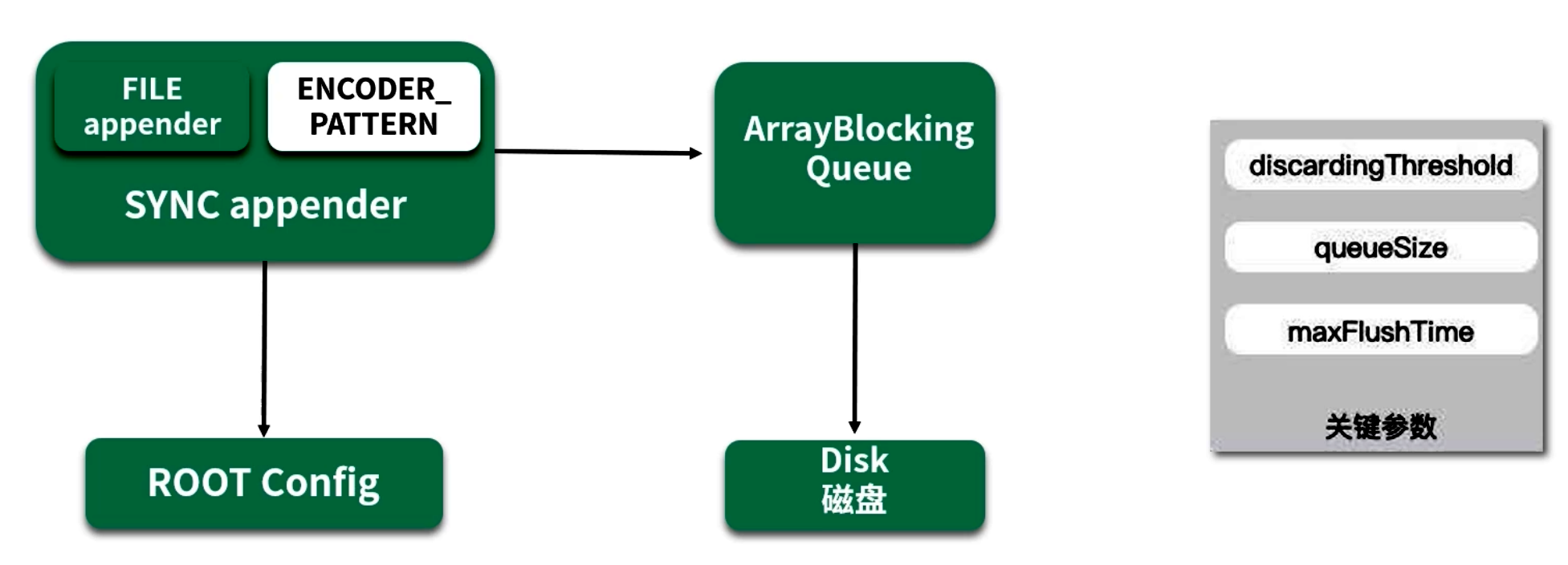
Logback 的异步日志基于 AsyncAppender,其核心思路:
- 业务线程(生产者) :调用
logger时,只需将待写入的日志事件先放入内存中的阻塞队列(ArrayBlockingQueue); - 异步 Worker 线程(消费者) :在后台单线程循环不断地从队列
poll()日志事件,然后批量地将它们写入磁盘。
这样,业务线程仅关心向缓冲队列"放入"日志,I/O 写入由独立线程异步完成。
4.2 核心配置示例
在 logback.xml 中添加如下内容:
xml
<!-- 定义一个 FileAppender,负责将日志写入磁盘 -->
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>app.log</file>
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 定义一个 AsyncAppender,将日志事件缓冲到队列 -->
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<!-- 当队列中的事件数量达到 discardingThreshold 时,可以丢弃低级别日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 队列大小:最多容纳 512 条事件 -->
<queueSize>512</queueSize>
<!-- 指定要异步包装的目标 appender -->
<appender-ref ref="FILE"/>
</appender>
<root level="INFO">
<!-- 使用异步日志器 -->
<appender-ref ref="ASYNC"/>
</root>4.2.1 三个关键参数
-
queueSize(队列容量):- 默认值为 256;当待写入事件数量超过
queueSize时,生产者线程会根据discardingThreshold策略进行处理; - 如果设置过大,进程突然断电,队列内未落盘的日志全部丢失风险增大;
- 默认值为 256;当待写入事件数量超过
-
discardingThreshold(丢弃阈值):- 取值范围
0 <= discardingThreshold <= queueSize; - 当队列长度 ≥
discardingThreshold时,低于或等于设定级别的日志事件可被丢弃,以保护高优先级日志; - 默认值为
queueSize × 0.8,即队列达到 80% 时开始丢弃低级别日志;若设置为0,则不丢弃任何事件,但可能导致生产者阻塞或抛出异常;
- 取值范围
-
maxFlushTime(关闭时最长等待时间):- 当应用优雅关闭时,
AsyncAppender会调用worker.join(maxFlushTime),等待后台线程将剩余日志写完; - 如果等待超时,应用仍会强制退出,此时缓冲区中未落盘的日志将丢失;
- 合理设置该值(如 5 秒或 10 秒),在性能与丢失风险之间权衡。
- 当应用优雅关闭时,
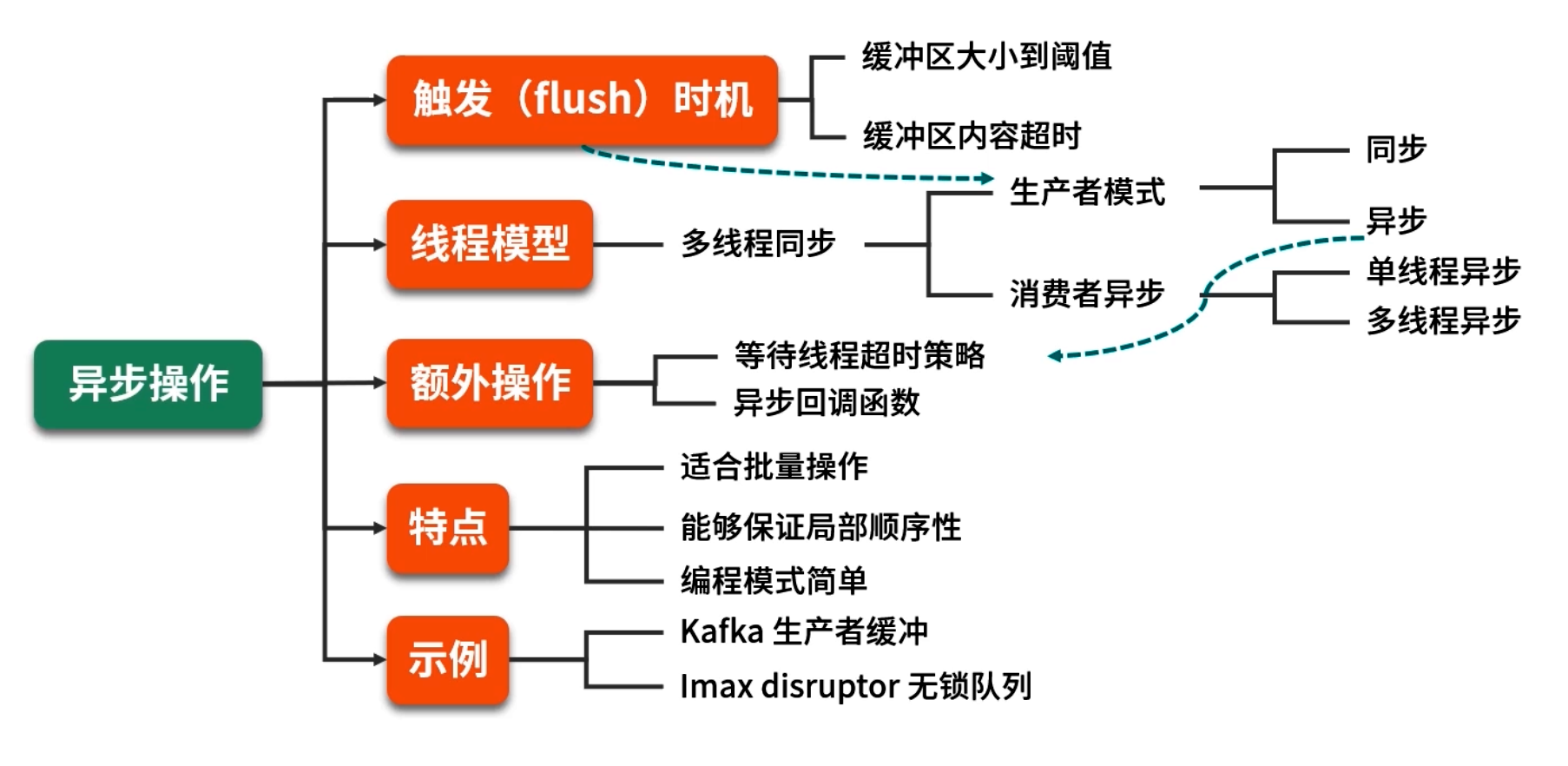
5. 缓冲区设计思路---同步 vs 异步
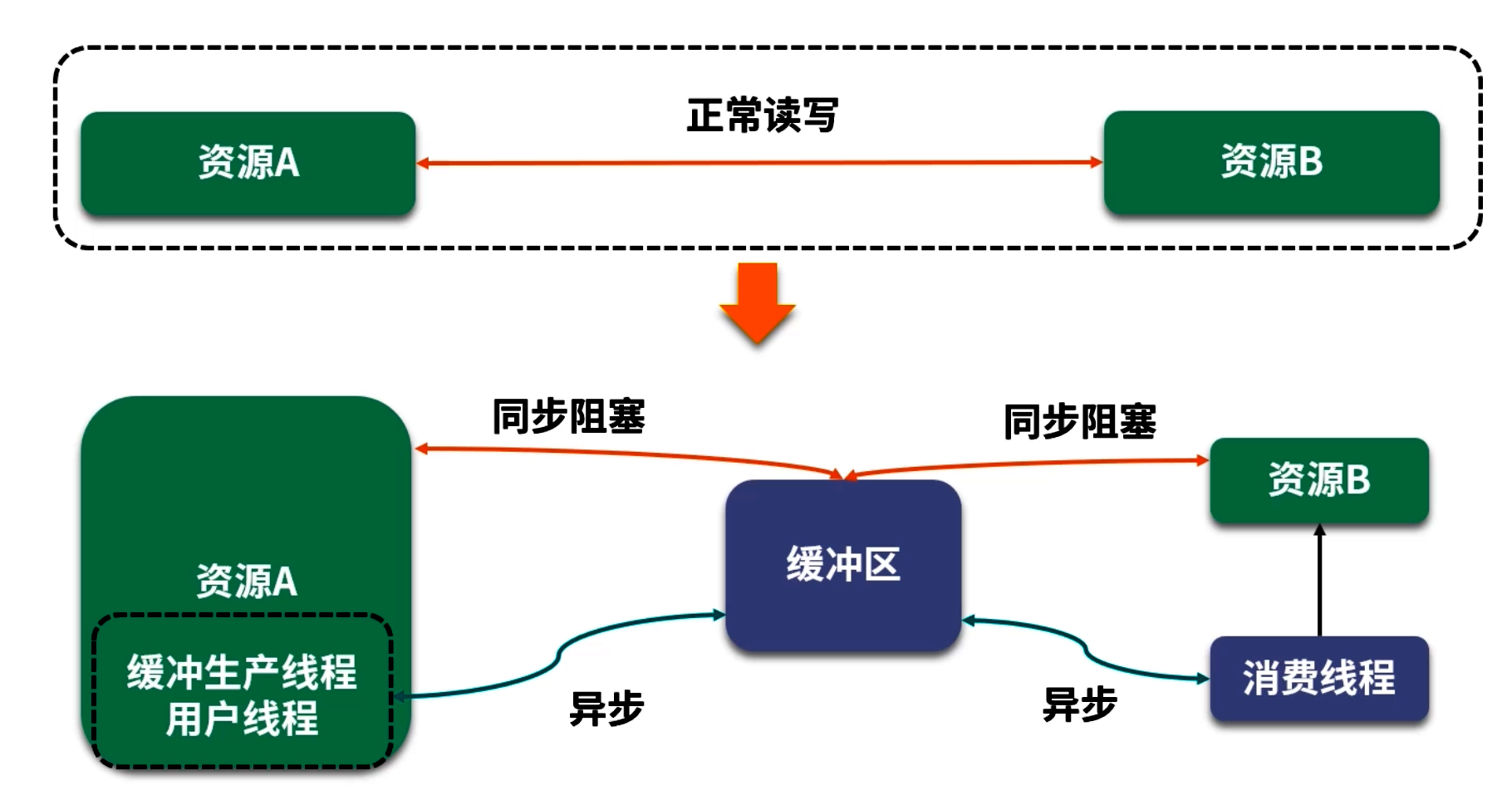
缓冲区优化常见于需要对"生产端"和"消费端"解耦的场景。但在设计时,需要考虑"同步缓冲"与"异步缓冲"两种模式,取舍点在于编程模型复杂度与性能收益。
5.1 同步缓冲
-
模型示意:
生产者 →→ [缓冲区] →→ 消费者
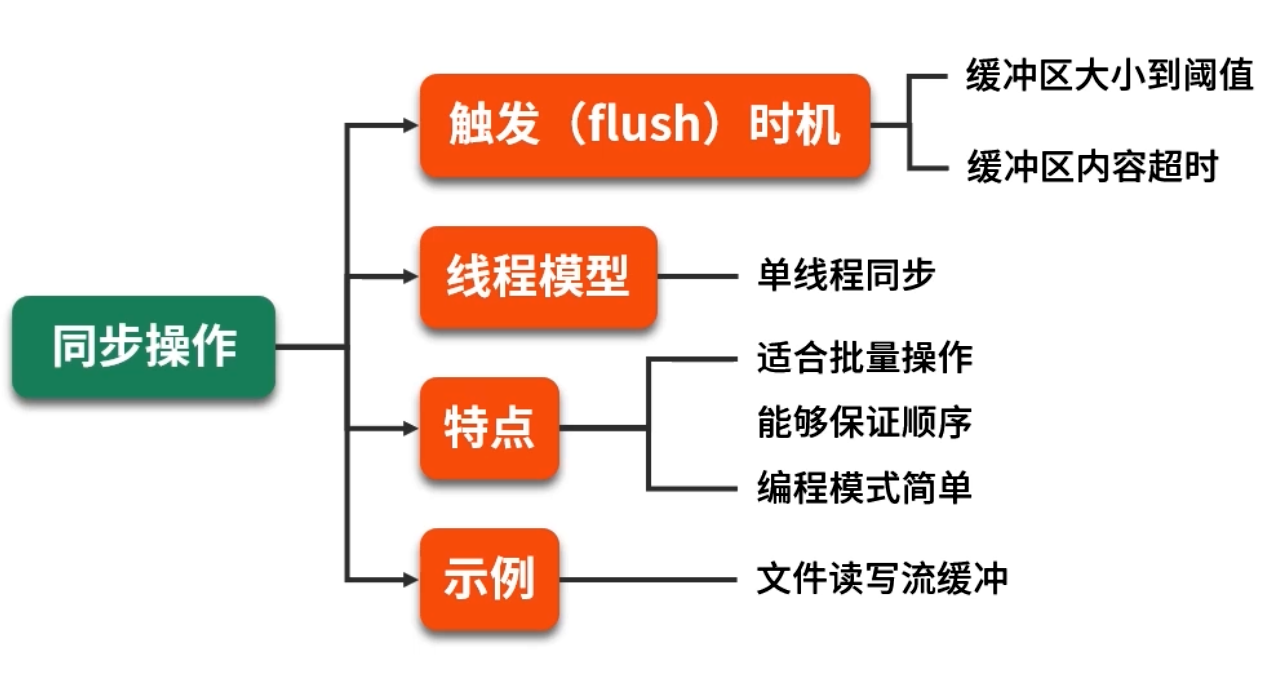
整个过程在同一个线程或调用链中执行。常见策略:
- 阈值触发写入 :当缓冲区积累元素数量 ≥
flushThreshold,或累积字节数 ≥byteThreshold时,一次性批量写入底层资源; - 定时触发写入 :如果缓冲区在
maxIdleTime内未达到flushThreshold,则定时将已有数据写出,保证高延迟数据得以及时消费;
-
优缺点:
- 优点:编程模型直观、逻辑简单,无额外线程;
- 缺点:当底层写入耗时出现波动(如突发磁盘抖动),会阻塞生产者线程,导致整体响应能力下降。
-
示例:
- 字符串拼接时使用
StringBuilder,一次性将多次append()的结果通过toString()写入磁盘; - JDBC 批量插入:在内存中将多条 SQL 语句缓存在
PreparedStatement中,达到batchSize时通过executeBatch()一次性写入数据库。
- 字符串拼接时使用
5.2 异步缓冲
-
模型示意:
生产者(线程 A) →→ [缓冲区(队列)] →→ 消费者(后台线程 B)
生产者仅负责往缓冲区写入;消费者由独立线程不断从缓冲区读取并写出。
-
生产者策略:
- 阻塞 :当队列已满,生产者调用
put()时会阻塞,直到有空位; - 非阻塞失败 :调用
offer(),若缓冲区已满则返回false,让上层逻辑根据返回值做重试或丢弃; - 异常抛出 :直接在
put()或自定义方法中抛出RejectedExecutionException等,通知调用方"缓冲已满"; - 回调机制:在生产者线程注册回调,当数据真正被消费后才触发,也可以用于跟踪已消费数据。
- 阻塞 :当队列已满,生产者调用
-
消费者设计:
- 启动单线程或线程池,不断从队列
poll()数据; - 处理逻辑应考虑批量拉取,以减少 I/O 写入次数,例如
drainTo(); - 若消费者处理速度不足,队列会持续积压;生产者需根据业务侧容忍值判断是否阻塞或快速失败。
- 启动单线程或线程池,不断从队列
-
多消费者与同步问题:
- 当缓冲区被多个消费者并发读写时,需要保证数据顺序或一致性;
- 可使用有序队列(如基于
BlockingQueue)或根据分区(Partition)分流; - 同时考虑多个消费者线程各自的吞吐能力与负载均衡。
6. Kafka 生产者缓冲示例
Kafka 生产者客户端的"批量发送"与"缓冲区"设计。下面以常见参数 batch.size 与 linger.ms 为例,说明缓冲区对性能与可靠性的影响。
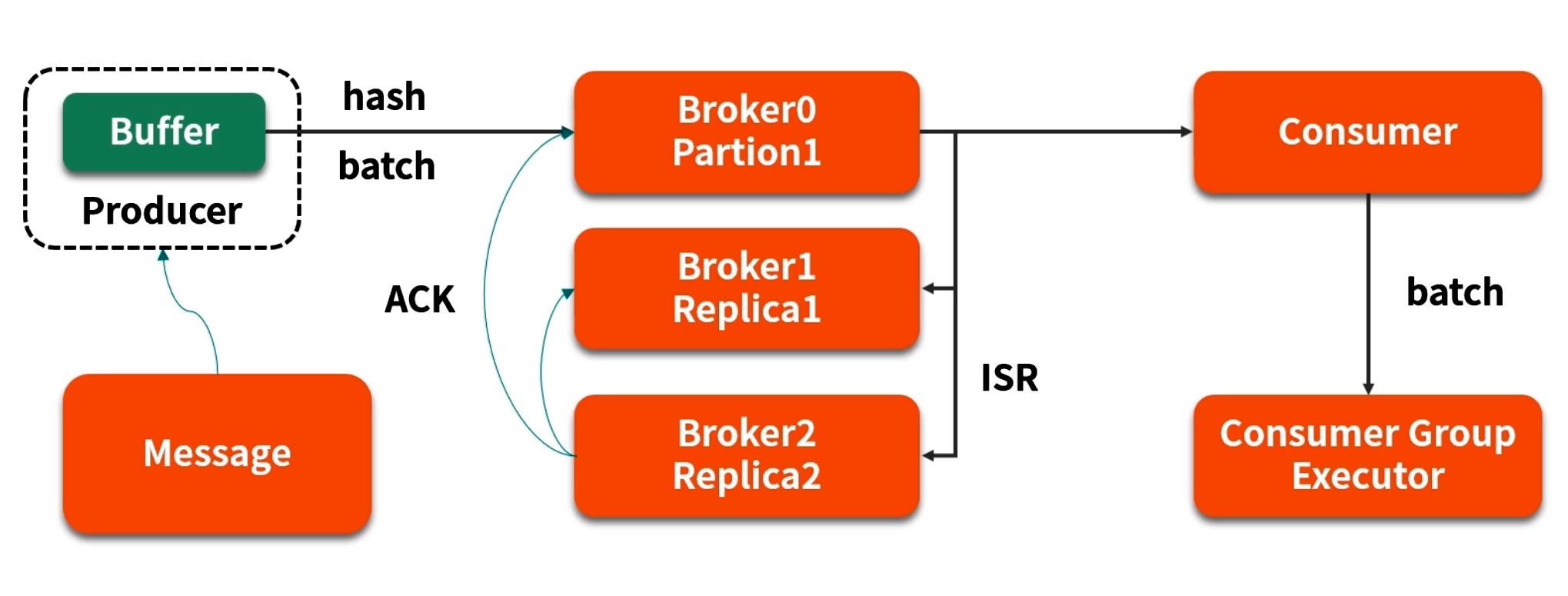
6.1 Kafka 生产者缓冲原理
- batch.size(字节):指定针对每个 partition 为单个批次消息设置的最大字节容量,默认为 16KB。当该容量被填满后,生产者立即将该 batch 发送给对应的 broker。
- linger.ms(毫秒) :指定"批次最大等待时间",即在
batch.size未被填满的情况下,生产者也会等待linger.ms后把已积累的消息强制发送,以减少每条消息都立刻网络发送带来的开销。
具体流程:
- 当调用
producer.send(record)时,Kafka 生产者客户端先把 record 序列化后放入对应 partition 的缓冲队列(内存); - 如果当前 batch 的累积字节数 ≥
batch.size,则立即触发发送; - 若
batch.size未满,且当前时间超过linger.ms,也会把已累积消息发送; - 发送出发后会异步等待 broker ACK 确认或重试。
6.2 缓冲区丢数据风险
假设生产者程序发生以下情况:
- 机器突然断电;
- JVM 进程被
kill -9杀死;
此时如果缓冲队列中仍有尚未被 send() 到 Broker 或未获 ACK 的消息,全部会丢失。默认情况下,缓冲区大小为 16KB,如果生产方业务持续产生大量消息,且 broker 短暂不可用,就会导致缓冲区快速填满。
解决方案:
- 缩小
batch.size:使得缓冲队列更频繁地发送,虽然牺牲吞吐量,但可减少丢失概率; - 降低
linger.ms:即使在低流量情况下,也会在较短等待后发送,保证消息尽快到达 broker; - 开启幂等性与 ACK 配置 :设置
enable.idempotence=true并且acks=all,让 broker 等待所有 ISR(in-sync replicas)确认后再 ACK,确保至少写入一个副本或多副本; - 生产者写入前落盘预写日志:在生产者本地先记录"即将发送的消息",待发送成功后再删除,重启后可根据预写日志补发;
- 使用电池或 UPS:在极端断电场景下保证机器有足够时间将缓冲持久化到磁盘。
6.3 缓冲区过载与业务可用性
当 broker 暂时不可用或网络抖动时,生产者缓冲区会不断积累消息,直至达到 buffer.memory(内存缓冲池)或达成 max.block.ms,此时默认行为是阻塞调用线程。若业务对等待较敏感,可能导致线程被长时间阻塞,最终耗尽线程池资源,从而引起整个服务不可用。
可选对策:
- 调整
max.block.ms:一旦超时则抛出TimeoutException告知调用方"消息积压,发送超时"; - 限流策略:在业务层做流控(如令牌桶),防止短时间内压入大量消息;
- 异步重试:将消息暂存在本地队列或数据库,后台线程定时重试投递;
7. 其他缓冲场景与示例
除了文件 I/O 与消息中间件,缓冲思想在常见的 Java 开发中无处不在:
-
StringBuilder / StringBuffer:
- 在 Java 中,频繁使用
String做拼接会产生大量临时对象; StringBuilder通过在内存中维护一个char[]缓冲,每次append()写入缓冲中,最后一次性toString()时整体创建一个String,显著提高拼接性能。
- 在 Java 中,频繁使用
-
操作系统网络缓冲(SO_SNDBUF / SO_RCVBUF):
- TCP Socket 在内核中会分配发送与接收缓冲区大小,可通过
socket.setSendBufferSize(...)/socket.setReceiveBufferSize(...)进行调优; - 适当增大操作系统缓冲区,可应对应用端瞬时突发流量,减少 packet drop;但过大会占用更多内核内存。
- TCP Socket 在内核中会分配发送与接收缓冲区大小,可通过
-
数据库 InnoDB Buffer Pool:
- MySQL InnoDB 存储引擎通过
innodb_buffer_pool_size配置,将数据页和索引页缓存在内存中,减少磁盘读取; - 合理将
buffer_pool_size设置为物理内存的 60%~80%,能显著提升查询和写入性能。
- MySQL InnoDB 存储引擎通过
-
ID 生成器缓存:
- 常见的全局递增 ID 生成,如 Twitter Snowflake 或数据库自增 ID,为了减少每次网络交互,往往将一段 ID(如 1000 个)一次性从数据库或中央服务拉取到本地缓冲;
- 应用只需从本地缓冲取得下一个 ID,当耗尽后再异步从中央服务拉取下一段,减少延迟。
8. 注意事项与异常场景
虽然缓冲区能带来明显性能提升,但在设计时还要考虑以下几方面的风险与权衡:
-
缓冲区数据丢失
- 突发断电、
kill -9等强制销毁进程时,缓冲区中的数据尚未落盘或未发送,全部丢失; - 对金融、订单类等对数据可靠性要求极高的系统,可通过"先写 WAL 日志再入缓冲"来保证数据不丢;
- 突发断电、
-
缓冲区内存占用与 OOM
- 大容量缓冲区占用堆内存较大,可能导致垃圾回收压力增大或堆内存不足;
- 需根据可用物理内存与业务吞吐量合理设置,如 8KB64KB、512MB2GB 等;
-
顺序与一致性问题
- 在多线程/多消费者场景下,若需要保证"消息顺序",必须使用单队列或分区队列;
- 对于都依赖同一缓存状态的读写,需要在并发消费者之间做好状态一致性或加锁、防重入等处理;
-
性能收益递减
- 缓冲区过小则频繁交互;过大则内存占用过高;需要在吞吐与延迟之间做折中;
- 在高并发网络场景,Socket / OS 层面也会加入多级缓冲,需要一体化考虑。
-
预写日志与数据恢复
- 常见做法是在写入缓冲前,先将关键元数据(例如 Kafka 消息 key)写到本地磁盘日志;待缓冲数据真正被提交到 broker 后,再标记该日志为成功。重启后扫描日志,补发未成功消息。
- 这种"先 WAL 后缓存"的策略会带来额外写盘开销,需要衡量业务对丢失率的容忍度。
9. 小结
系统地探讨了**缓冲(Buffer)**在 Java 语言与中间件中的典型应用:
-
缓冲本质与类比:
- 缓冲区是解耦生产者与消费者速度差异的内存"蓄水池";
- 让慢速设备接收"小而频繁" → "大而顺序" 的 I/O 请求,大幅提高吞吐。
-
Java I/O 缓冲实现:
BufferedReader/BufferedInputStream通过fill()方法一次性从底层流读入 8KB(默认)数据到内存;- 通过
pos、count指针管理缓冲区消费位置;自动扩容至marklimit,在保证性能的同时兼容mark()/reset()。
-
异步日志缓冲:
- Logback
AsyncAppender将日志事件先缓存在ArrayBlockingQueue中,后台线程异步写入磁盘; - 重要参数:
queueSize(队列容量)、discardingThreshold(丢弃阈值)、maxFlushTime(关闭时等待时间)。
- Logback
-
缓冲设计思路---同步 vs 异步:
- 同步缓冲:批量触发策略简单,但会阻塞生产者;
- 异步缓冲:解耦写入与消费,需设计生产者满载后的处理策略与多消费者同步。
-
Kafka 生产者缓冲示例:
- 通过
batch.size+linger.ms实现消息批量发送; - 缓冲区满或超时触发网络发送,带来吞吐与延迟权衡;
- 在断电或
kill -9场景下,缓冲中消息或未获 ACK 消息会丢失,可结合写盘预写日志或副本策略降低风险。
- 通过
-
其他缓冲场景:
StringBuilder/StringBuffer字符串拼接;- 操作系统 Socket 缓冲(SO_SNDBUF/SO_RCVBUF);
- 数据库 InnoDB Buffer Pool;
- ID 生成器段缓存等。
-
注意事项与异常场景:
- 缓冲区丢失风险、内存占用风险;
- 顺序一致性与并发读写冲突;
- 性能收益递减点;
- WAL/预写日志策略平衡可靠性与性能。
总之,缓冲区优化是 Java 性能优化中一项非常重要的技术手段,它既能显著提高磁盘与网络 I/O 吞吐,也带来了异步设计下的编程复杂度与故障恢复挑战。
在实际项目中,应结合业务对"数据丢失概率"与"延迟/吞吐"之间的容忍度,合理设置缓冲大小与处理策略。
