【AGI】Qwen3混合推理模型微调数据集
-
- [(1)OpenMathReasoning 数据集(AIMO-2)](#(1)OpenMathReasoning 数据集(AIMO-2))
- [(2)FineTome-100k 数据集(Maxime Labonne)](#(2)FineTome-100k 数据集(Maxime Labonne))
搭建好基础环境后,开始准备Qwen3混合推理模型微调数据集。围绕Qwen3模型的高效微调,为了确保其仍然保留混合推理能力,我们可以考虑在微调数据集中加入如普通对话数据集FineTome(https://huggingface.co/datasets/mlabonne/FineTome-100k),以及带有推理字段的数学类数据集OpenMathReasoning(https://huggingface.co/datasets/unsloth/OpenMathReasoning-mini),并围绕这两个数据集进行拼接,从而在确保能提升模型的数学能力的同时,保留非推理的功能。同时还需要在持续微调训练过程中不断调整COT数学数据集和普通文本问答数据集之间的配比,以确保模型能够在提升数学能力的同时,保留混合推理的性能。
(1)OpenMathReasoning 数据集(AIMO-2)
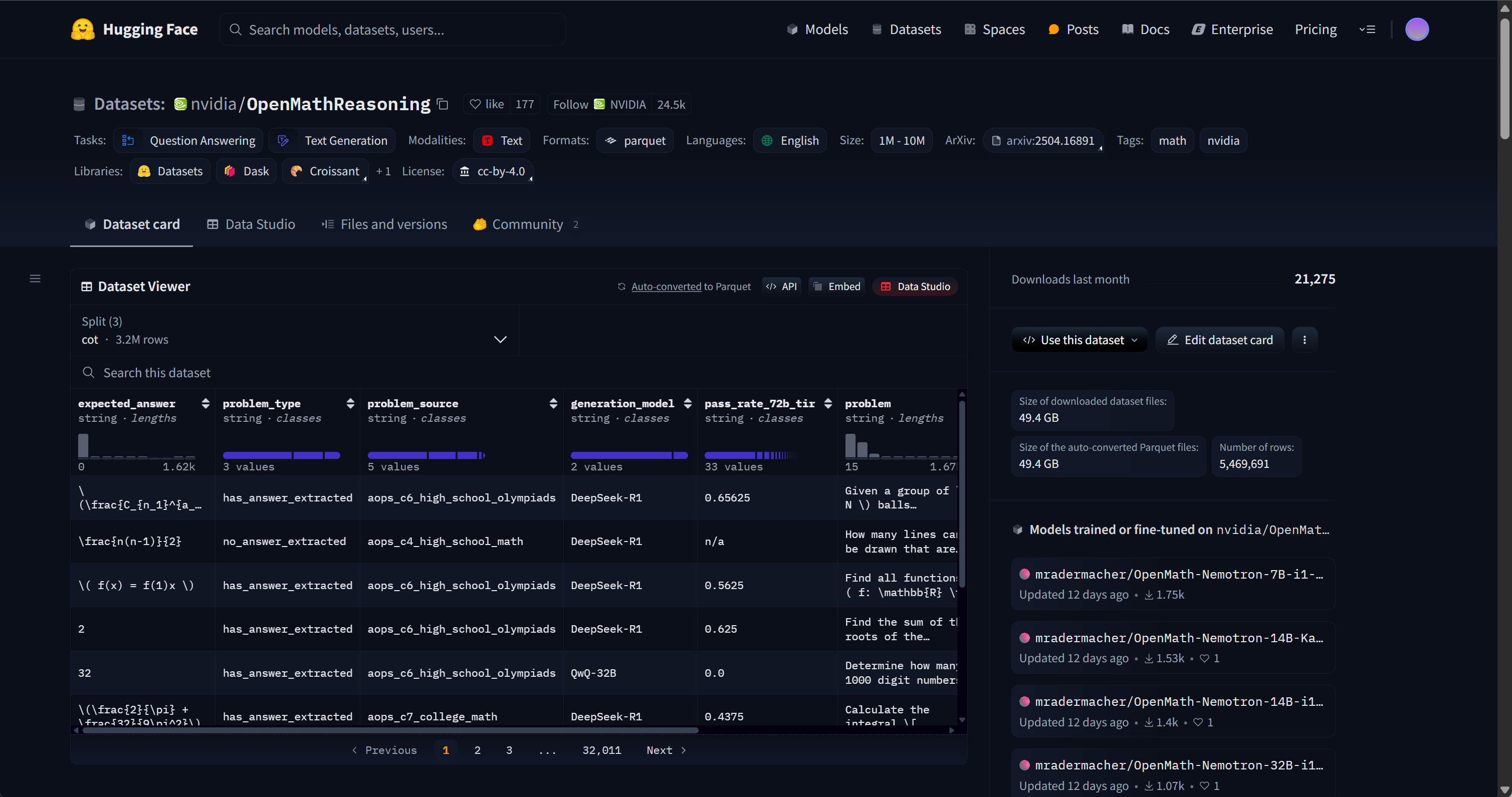
数据集介绍: OpenMathReasoning 是为 AI Mathematical Olympiad - Progress Prize 2(AIMO-2)竞赛开发的高质量数学推理数据集。该数据集包含:
- 540,000 道独特的高质量数学问题,涵盖代数、组合、几何和数论等领域;
- 3,200,000 条详细的长推理解答;
- 1,700,000 条工具集成推理(Tool-Integrated Reasoning)解答,结合了代码执行与推理过程;
- 生成式解答选择(GenSelect) 方法,用于从多个候选解答中选择最优解。
该数据集旨在推动 AI 在复杂数学推理任务中的能力提升,已被用于训练在多个数学推理基准上表现优异的模型。
- 数据集格式
OpenMathReasoning包含expected_answer 、problem 和generated_solution三个核心字段,分别代表问题答案、问题和模型思考过程。例如其中一条数据内容如下:
问题:
设有一组共 NN 个球,由 CC 种颜色组成,其中每种颜色的球的数量分别为 n 1 , n 2 , ... , n C n 1 , n 2 , ... , n C n1,n2,...,nCn_1, n_2, \ldots, n_C n1,n2,...,nCn1,n2,...,nC(满足 n 1 + n 2 + ... + n C = N n 1 + n 2 + ... + n C = N n1+n2+...+nC=Nn_1 + n_2 + \ldots + n_C = N n1+n2+...+nC=Nn1+n2+...+nC=N)。如果从中随机抽取 A A AA AA 个球(其中 A ≤ N A ≤ N A≤NA \leq N A≤NA≤N),那么抽到的球中恰好有 a 1 , a 2 , ... , a C a 1 , a 2 , ... , a C a1,a2,...,aCa_1, a_2, \ldots, a_C a1,a2,...,aCa1,a2,...,aC 个分别对应每种颜色(满足 a 1 + a 2 + ... + a C = A a 1 + a 2 + ... + a C = A a1+a2+...+aC=Aa_1 + a_2 + \ldots + a_C = A a1+a2+...+aC=Aa1+a2+...+aC=A),这种情况发生的概率是多少?
答案:
C n 1 a 1 ⋅ C n 2 a 2 ⋅ ... ⋅ C n C a C C N A \frac{C_{n_1}^{a_1}\cdot C_{n_2}^{a_2} \cdot \ldots \cdot C_{n_C}^{a_C}}{C_N^A} CNACn1a1⋅Cn2a2⋅...⋅CnCaC
思考过程:
好的,也就是说我要计算这样一个概率:从总共 N N N 个球中随机抽取 A A A 个球,其中球分为 C C C 种颜色,要求抽到的每种颜色球的数量恰好是 a 1 , a 2 , ... , a C a_1, a_2, \ldots, a_C a1,a2,...,aC。嗯,我们来想想该怎么求解这个问题。
首先,概率问题通常会涉及组合数 。概率的一般公式是:
有利情况数 ÷ 所有可能情况总数。
在本题中,"有利情况"就是指:恰好抽到 a 1 a_1 a1 个颜色1的球, a 2 a_2 a2 个颜色2的球,依此类推,一直到颜色 C C C。
而"所有可能情况"则是:从 N N N 个球中任意抽取 A A A 个球的方式,不考虑颜色分布。
我们可以这样分解这个问题:
-
从 N N N 个球中任意抽取 A A A 个球的总方式数是组合数:
C ( N , A ) = ( N A ) = N ! A ! ( N − A ) ! C(N, A) = \binom{N}{A} = \frac{N!}{A!(N - A)!} C(N,A)=(AN)=A!(N−A)!N! -
而有利情况则是:从每种颜色中选出指定数量的球。比如从 n 1 n_1 n1 个颜色1的球中选出 a 1 a_1 a1 个,从 n 2 n_2 n2 个颜色2的球中选出 a 2 a_2 a2 个,依此类推。
由于每种颜色之间的选择是相互独立的,所以所有组合方式的总数就是各个颜色组合数的乘积:
( n 1 a 1 ) × ( n 2 a 2 ) × ⋯ × ( n C a C ) \binom{n_1}{a_1} \times \binom{n_2}{a_2} \times \cdots \times \binom{n_C}{a_C} (a1n1)×(a2n2)×⋯×(aCnC)
不过,要注意前提条件必须满足:
- 每个 a i ≤ n i a_i \leq n_i ai≤ni,也就是说不能从某种颜色中选出比它实际数量更多的球;
- 同时 a 1 + a 2 + ⋯ + a C = A a_1 + a_2 + \cdots + a_C = A a1+a2+⋯+aC=A,总共抽取的球数必须正确。
如果这些条件满足,那么这种组合方式就是有效的。如果不满足,比如某个 a i > n i a_i > n_i ai>ni,则该组合数为0,概率也自然为0,这是符合逻辑的。
其实这正是一个**多项超几何分布(multivariate hypergeometric distribution)**问题。
超几何分布描述的是:从有限总体中不放回地抽取样本,得到某个类别成功次数的概率。多项超几何分布是其推广,适用于多个类别的情况,正好契合这里的"多种颜色"的设定。
该分布的概率公式就是:
P = ( n 1 a 1 ) ⋅ ( n 2 a 2 ) ⋯ ( n C a C ) ( N A ) P = \frac{\binom{n_1}{a_1} \cdot \binom{n_2}{a_2} \cdots \binom{n_C}{a_C}}{\binom{N}{A}} P=(AN)(a1n1)⋅(a2n2)⋯(aCnC)
最终结论:
当从 N N N 个球(含有 C C C 种颜色,每种颜色分别有 n 1 , n 2 , ... , n C n_1, n_2, \ldots, n_C n1,n2,...,nC 个球)中随机抽取 A A A 个球时,恰好抽中每种颜色 a 1 , a 2 , ... , a C a_1, a_2, \ldots, a_C a1,a2,...,aC 个球的概率为:
P = ∏ i = 1 C ( n i a i ) ( N A ) \boxed{ P = \frac{\prod_{i=1}^{C} \binom{n_i}{a_i}}{\binom{N}{A}} } P=(AN)∏i=1C(aini)
这个公式就是多项超几何分布的概率表达式,分子为每种颜色的有利组合方式之乘积,分母为所有可能抽取 A A A 个球的方式总数。
(2)FineTome-100k 数据集(Maxime Labonne)
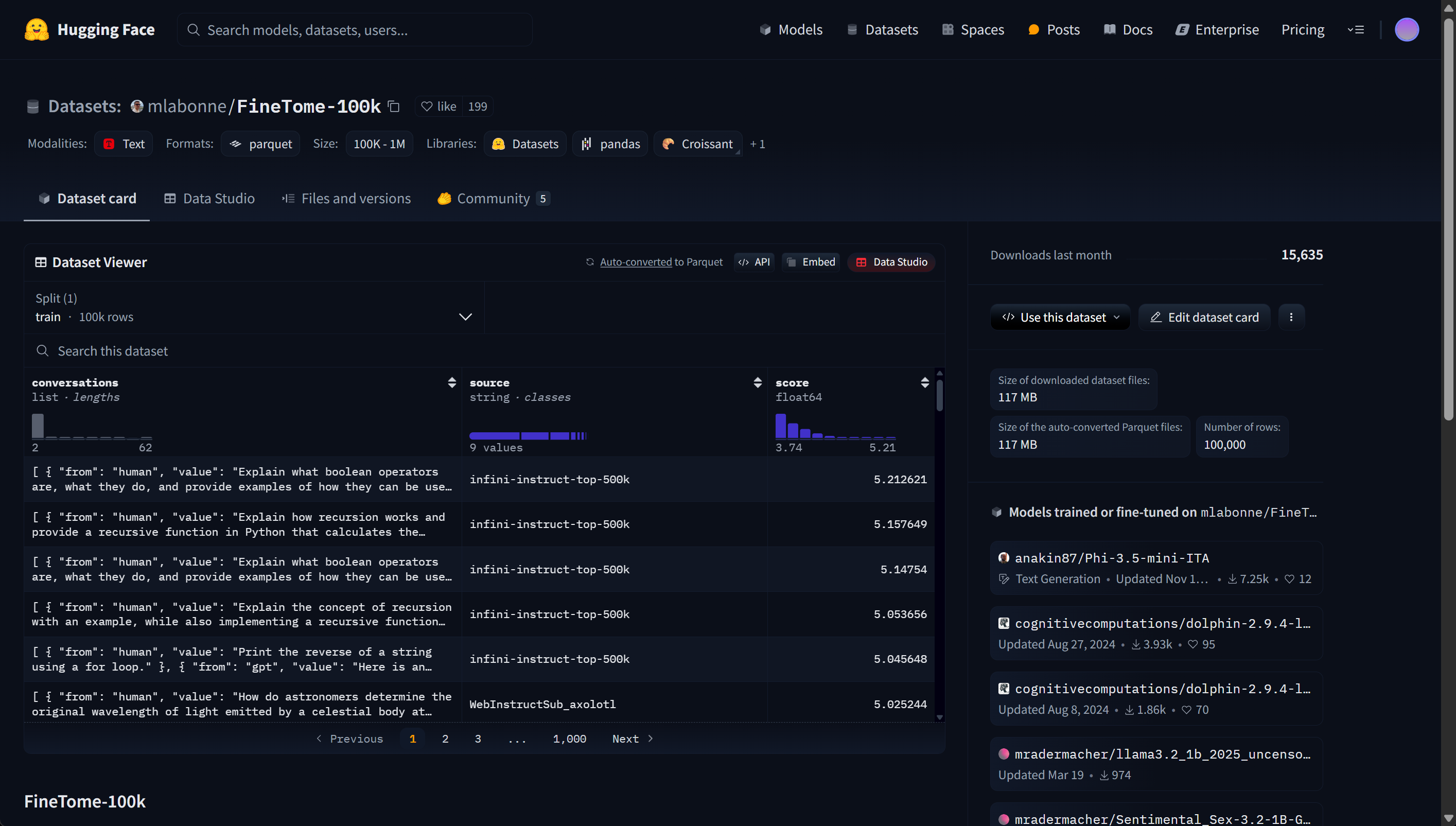
数据集简介: FineTome-100k 是由 Maxime Labonne 创建的高质量多轮对话数据集,采用 ShareGPT 风格,适用于大语言模型的微调。该数据集特点包括:
- 100,000 条多轮对话样本;
- 数据以 JSONL 格式存储,每条记录包含一个 "conversations" 字段,记录对话的完整历史;
- 对话格式类似于 ShareGPT,适合训练模型进行多轮对话;
- 可转换为 Hugging Face 通用的多轮对话格式,以适配不同的训练框架。
接下来即可上手使用Unsloth进行高效微调了。