Hadoop HDFS 体系结构与文件读写流程剖析
一、HDFS 理论基础
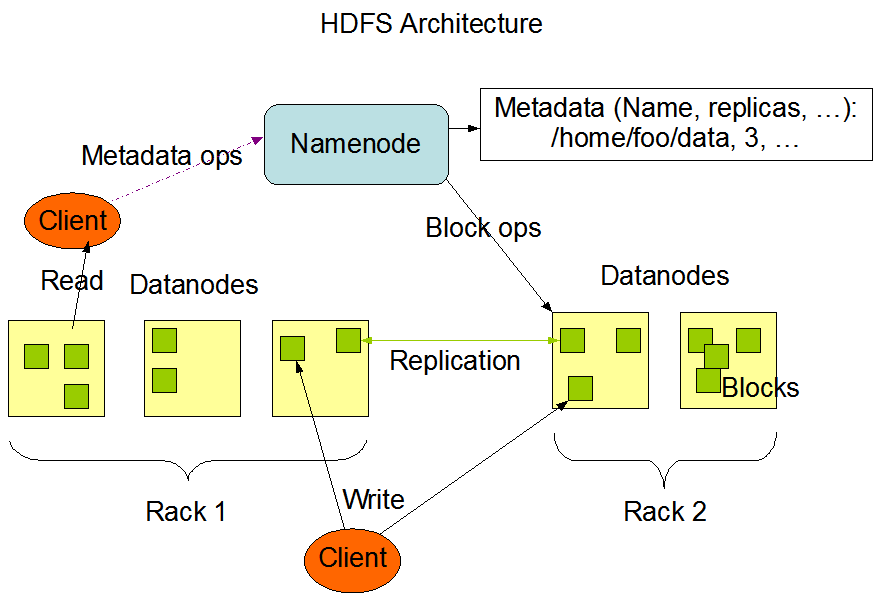
HDFS(Hadoop Distributed File System) 是 Hadoop 的分布式文件系统,专为大规模数据存储和高吞吐量访问设计,具备高容错性和可扩展性,适合部署在廉价硬件集群上。
1. 主要组件
- NameNode:负责管理文件系统的元数据(如目录结构、文件到块的映射、块副本位置等)。
- DataNode:负责实际数据块的存储、读写操作。
- Secondary NameNode:辅助 NameNode 合并编辑日志与镜像文件(fsimage),并非主备节点。
- Client:HDFS 用户,负责发起读写请求。
2. 数据存储方式
- 块(Block):HDFS 将文件切分为块(默认128MB),每块独立存储。
- 副本机制:每个数据块有多个副本(默认3份),分布在不同 DataNode 上,实现容错。
二、HDFS 读写流程
1. 写入(上传)流程
- 客户端请求上传:向 NameNode 发送创建文件请求。
- NameNode 分配资源:检查目录和文件、分配块及 DataNode 列表,登记元数据。
- 客户端写入数据块 :
- 客户端将数据切分为块,采用流水线机制依次写入 DataNode 副本。
- 每写完一个块,继续请求 NameNode 分配下一个块的 DataNode 列表。
- 写入完成通知:所有块写入完毕后,客户端通知 NameNode,NameNode 更新元数据。
纯文本流程图
text
Client
|
|--(1)请求创建文件--> NameNode
|
|<--(2)分配Block和DataNode列表---
|
|--(3)写数据块到DataNode1
|------------------------->DataNode2
|------------------------->DataNode3
|
|--(4)写完通知NameNodeMermaid 时序图
Client NameNode DataNode1 DataNode2 DataNode3 (1)请求创建文件 (2)分配Block和DataNode列表 (3)写数据块 数据复制 数据复制 (4)写完通知 Client NameNode DataNode1 DataNode2 DataNode3
2. 读取(下载)流程
- 客户端请求读取:向 NameNode 请求文件块位置信息。
- NameNode 返回位置信息:返回所有块及其 DataNode 位置。
- 客户端读取数据块:直接从 DataNode 读取数据块(可并行)。
- 数据组装:客户端将块数据按顺序组装为完整文件。
纯文本流程图
text
Client
|
|--(1)请求读取文件--> NameNode
|
|<--(2)返回Block和DataNode位置---
|
|--(3)直接从DataNode读取数据块
|
|--(4)组装为完整文件Mermaid 时序图
Client NameNode DataNode1 (1)请求读取文件 (2)返回Block和DataNode位置 (3)读取数据块 (4)组装为完整文件 Client NameNode DataNode1
三、HDFS 特点总结
- 高容错性:多副本机制,节点故障不影响数据可用性。
- 高吞吐量:适合大文件批量处理,不适合低延迟小文件操作。
- 良好扩展性:可通过增加节点轻松扩容。
- 流式数据访问:一次写入,多次读取,适合大数据分析场景。
四、Markdown 流程图说明
- 纯文本流程图:任何 Markdown 工具都能显示。
- Mermaid 语法:需支持 Mermaid 渲染的 Markdown 编辑器(如 Typora、Obsidian、语雀、Gitee、GitHub 等)才能看到图形效果。
五、参考架构图
---如需了解 HDFS 代码示例、API 使用、部署细节等,欢迎继续提问!