一、MVCC机制
概念: MVCC(Multi-Version Concurrency Control,多版本并发控制 )是数据库系统中用于提升并发性能的核心机制,通过维护数据的多个历史版本,实现读写操作的无阻塞并发执行。其核心思想是以空间换时间,避免传统锁机制导致的性能瓶颈。
1、核心原理:数据多版本与快照隔离
-
版本链(Version Chain)
- 每行数据包含两个隐藏字段(以InnoDB为例)
DB_TRX_ID:记录最近修改该行的事务ID。DB_ROLL_PTR:指向Undo Log中该行历史版本的指针。
- 数据每次修改时,旧版本存入Undo Log,新版本通过
DB_ROLL_PTR形成单向链表(链首为最新版本)
- 每行数据包含两个隐藏字段(以InnoDB为例)
-
快照读(Snapshot Read)
- 普通
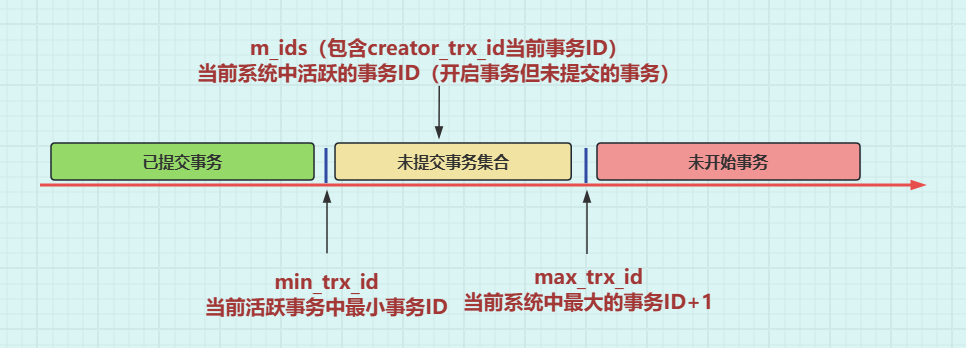
SELECT操作读取事务开始时的数据快照,而非最新数据 - Read View(可见性视图) :事务启动时生成,包含
- 活跃事务ID列表 (
m_ids):未提交的事务集合。 - 高低水位线 :
min_trx_id(最小活跃事务ID)、max_trx_id(下一个待分配事务ID)。
- 活跃事务ID列表 (
- 可见性规则 :
- 若数据版本的
DB_TRX_ID < min_trx_id→ 可见(已提交)。 - 若
DB_TRX_ID在m_ids中 → 不可见(未提交)。 - 其他情况沿版本链回溯旧版本
- 若数据版本的
- 普通
2、实现机制与隔离级别支持
Undo Log的核心作用
- 存储数据旧版本,支撑版本链回溯。
- INSERT:仅记录主键,回滚时删除。
- UPDATE/DELETE:记录完整行或变更字段旧值,用于回滚和MVCC
隔离级别的实现差异
| 隔离级别 | MVCC行为 | 解决的并发问题 |
|---|---|---|
| 读已提交(RC) | 每次SELECT生成新Read View,能看到其他事务已提交的修改 |
脏读(❌不可重复读/幻读) |
| 可重复读(RR) | 事务启动时生成固定Read View,整个事务内数据快照一致(MySQL默认级别) | 脏读、不可重复读(❌幻读) |
| 串行化(Serializable) | 禁用MVCC,完全依赖锁机制 | 全部问题 |
⚠️ 幻读的补充解决 :RR级别下,InnoDB通过间隙锁(Gap Lock) 阻止范围内插入新行
3、MVCC与传统锁机制的对比
| 特性 | MVCC | 传统锁机制 |
|---|---|---|
| 读性能 | 极高(无锁快照读) | 较低(需共享锁阻塞写) |
| 写冲突处理 | 延迟检测(提交时校验版本) | 即时阻塞(执行时加锁) |
| 存储开销 | 较高(多版本存储) | 较低(单版本) |
| 适用场景 | 读多写少(如电商查询、报表分析) | 写密集或强一致性需求 |
二、Undo Log回滚日志
作用
-
事务回滚(原子性保证)
当事务执行失败或主动回滚(
ROLLBACK)时,Undo Log 会记录数据修改前的状态(旧值),通过反向操作(如INSERT变DELETE)将数据恢复到事务开始前的状态。如事务中执行
UPDATE更新金额后回滚,Undo Log 提供旧值恢复数据一致性。 -
实现 MVCC(隔离性支持)
通过保存数据的历史版本,Undo Log 支持非锁定读取(快照读)。其他事务读取数据时,若该数据被占用,可通过 Undo Log 获取旧版本数据,避免读写冲突。关键机制 :通过隐藏列
trx_id(事务ID)和roll_pointer(指向旧版本指针)构建版本链。
组成
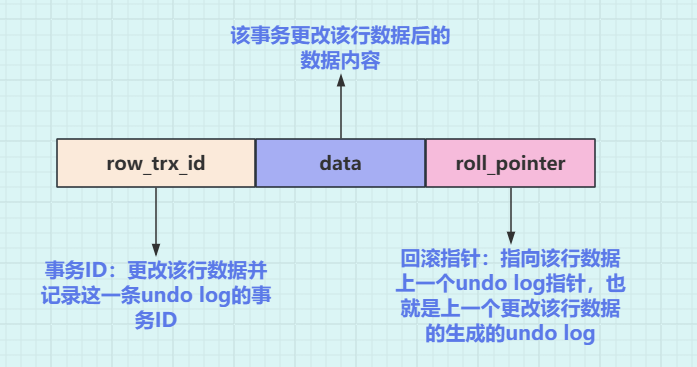
组成:row_trx_id 、data、 roll_pointer
**row_trx_id:**更新本行数据的事务 id
**data:**该行的数据内容
**roll_pointer:**回滚指针,指向上一个更改该行数据的事务ID
这里的内容组成并不全面,如果需要了解更全面的组成内容自行搜寻,这里只是说明这里用到的组成内容,简化后的结构如下:
三、Undo Log版本链
Undo Log版本链是MySQL InnoDB引擎实现多版本并发控制(MVCC)的核心数据结构,通过记录数据的历史版本实现非阻塞读和事务回滚。
一条 undo log 对应这行数据的一个版本,当这行数据有多个版本时,就会有多条 undo log 日志,undo log 之间通过 roll_pointer 指针连接,这样就形成了一个 undo log 版本链
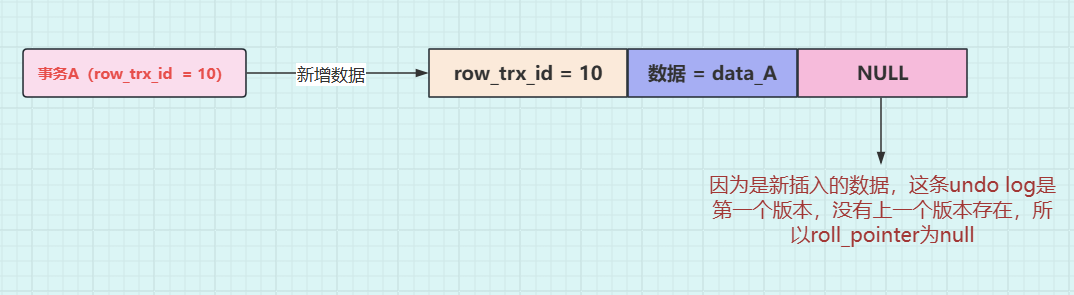
undo log版本链的形成
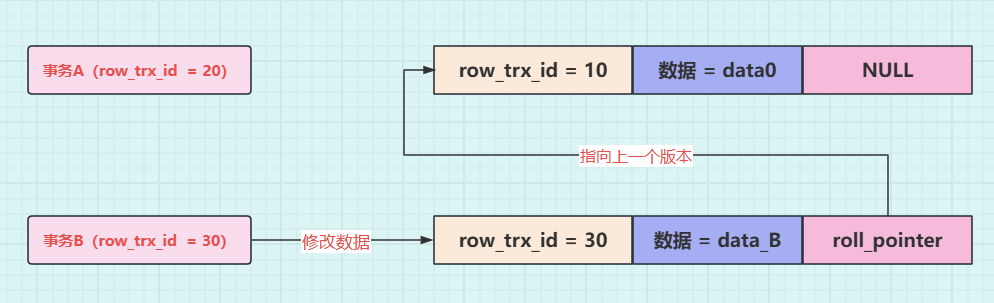
如现在有一个事务 A,它的事务 id 为 10,向表中新插入了一条数据,数据记为 data_A,那么此时对应的 undo log 应该如下图所示:
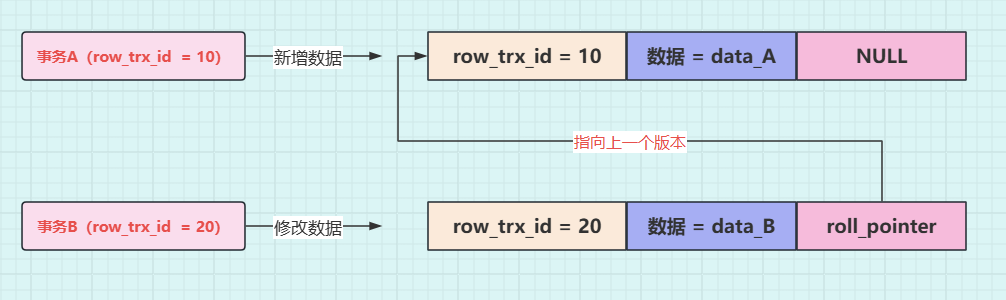
接着事务 B(trx_id=20),将这行数据的值修改为 data_B,同样也会记录一条 undo log,如下图所示,这条 undo log 的 roll_pointer 指针会指向上一个数据版本的 undo log,也就是指向事务 A 写入的那一行 undo log。
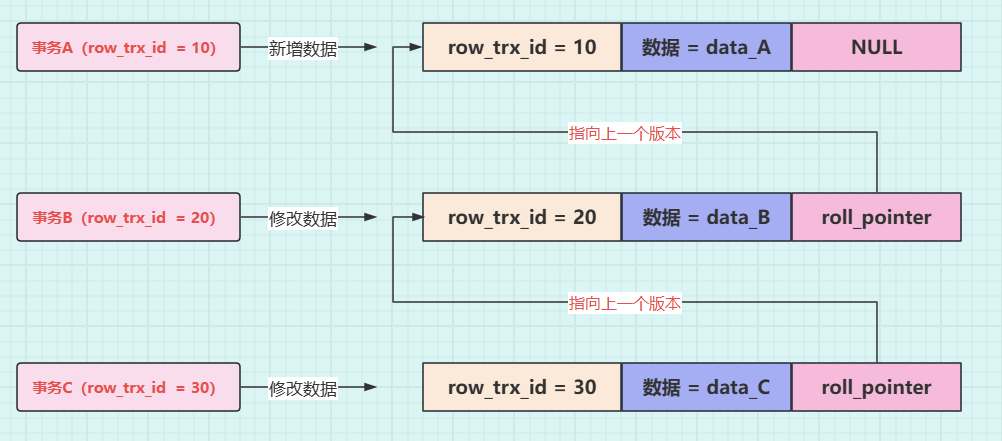
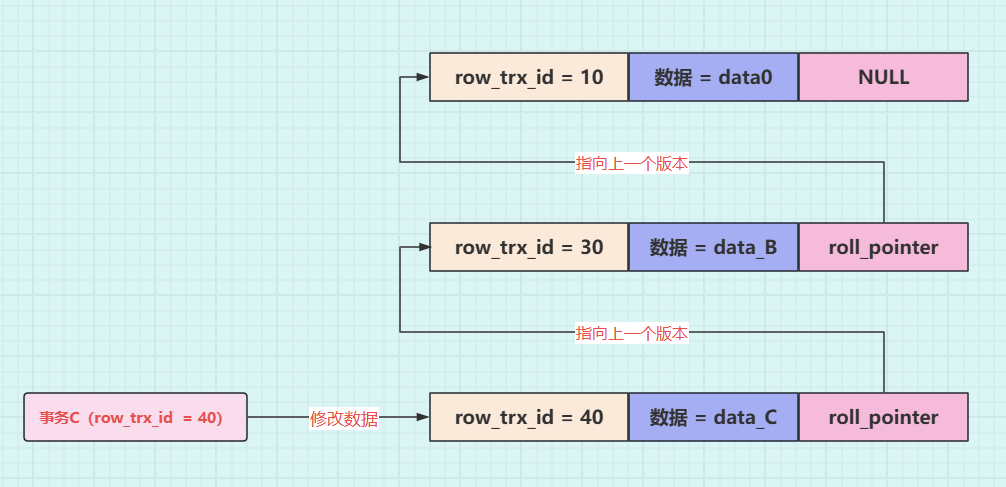
再接着,事务 C(trx_id=30),将这行数据的值修改为 data_C,对应的示意图如下。
四、ReadView机制
1、构成
当事务在开始执行的时候,会给每个事务生成一个 ReadView。这个 ReadView 会记录 4 个非常重要的属性:
- creator_trx_id: 当前事务的 id;
- m_ids: 当前系统中所有的活跃事务的 id,活跃事务指的是当前系统中开启了事务,但是还没有提交的事务;
- min_trx_id: 当前系统中,所有活跃事务中事务 id 最小的那个事务,也就是 m_id 数组中最小的事务 id;
- max_trx_id: 当前系统中事务的 id 值最大的那个事务 id 值再加 1,也就是系统中下一个要生成的事务 id。
2、场景分析
场景一:row_trx_id 小于 min_trx_id
表示这条数据是在当前事务开启之前,其他的事务就已经将该条数据修改了并提交了事务(事务的 id 值是递增的),所以当前事务能读取到。
场景二:row_trx_id 大于等于 max_trx_id
表示在当前事务开启以后,过了一段时间,系统中有新的事务开启了,并且新的事务修改了这行数据的值并提交了事务,所以当前事务肯定是不能读取到的,因此这是后面的事务修改提交的数据。
场景三:当前数据的 row_trx_id 处于 min_trx_id 和 max_trx_id 的范围之间,分两种情况:
(a)row_trx_id在 m_ids 数组中表示的是和当前事务在同一时刻开启的事务,修改了数据的值,并提交了事务,所以不能让当前事务读取到;
(b) row_trx_id不在 m_ids 数组中表示的是在当前事务开启之前,其他事务将数据修改后就已经提交了事务,所以当前事务能读取到。
案例如下:
**数据伪造:**假设表中有一条数据,它的 row_trx_id=10,roll_pointer 为 null,undo log 版本链如下:

场景:事务 A 和事务 B 并发执行,事务 A 的事务 id 为 20,事务 B 的事务 id 为 30
各个事务的ReadView情况如下:
**事务A:**m_ids=20,30,min_trx_id=20,max_trx_id=31,creator_trx_id=20
事务B:m_ids=20,30,min_trx_id=20,max_trx_id=31,creator_trx_id=30
**操作一:**事务 A(trx_id=20)去读取数据,在 undo log 版本链中,数据最新版本的事务 id 为 10,这个值小于事务 A 的 ReadView 里 min_trx_id 的值,表示这个数据的版本是事务 A 开启之前,其他事务提交的,因此事务 A 可以读取到的值是 data0。

操作二 :事务 B(trx_id=30)去修改数据,将数据修改为 data_B,先不提交事务 。虽然不提交事务,但是仍然会记录一条 undo log,因此这条数据的 undo log 的版本链就有两条记录了,新的这条 undo log 的 roll_pointer 指针会指向前一条 undo log,示意图如下。
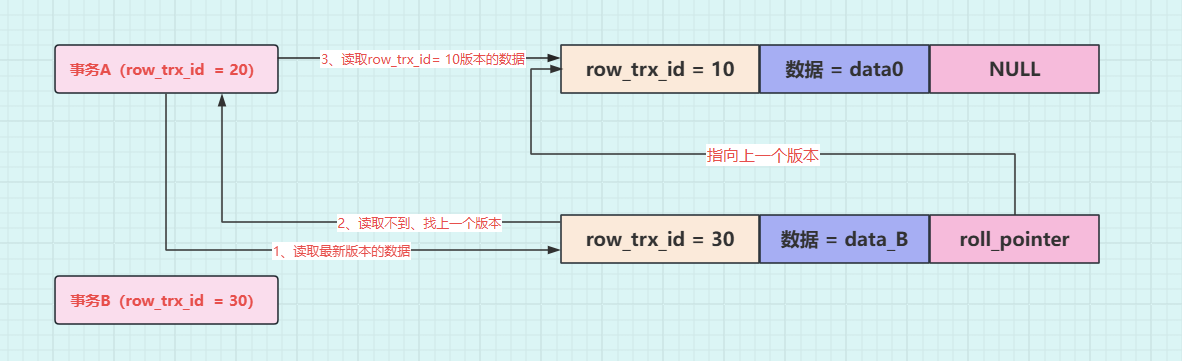
操作三: 事务 A(trx_id=20)去读取数据,在 undo log 版本链中,数据最新版本的事务 id 为 31,处于事务 A 的 ReadView 里 min_trx_id 和 max_trx_id 之间,需要判断这个数据版本的值是否在 m_ids 数组中,发现30 在 m_ids 数组中,表示这个版本的数据是和自己同一时刻启动的事务修改的,数据 data_B读取不到。需要沿着 undo log 的版本链向前找,接着会找到该行数据的上一个版本,也就是 trx_id=10 的版本,由于这个版本的数据的 trx_id=10,小于 min_trx_id 的值,因此事务 A 能读取到该版本的值,即事务 A 读取到的值是 data0。
操作四: 事务 B 提交事务,那么此时系统中活跃的事务就只有 id 为 20 的事务了,但不影响事务A的ReadView ,因为这个是事务开启的瞬间生成的,不会因其他事务的变动而变动。此时事务 A 去根据 undo log 版本链去读取数据时,还是不能读取最新版本的数据,只能往前找,最终还是只能读取到 data0。
**操作五:**新开事务 C,事务 id 为 40,它的 ReadView 中m_ids=20,40,min_trx_id=20,max_trx_id=41,creator_trx_id=40。事务 C(trx_id=40)将数据修改为 data_C,并提交事务。此时 undo log 版本链就变成了如下图所示:
**操作六:**事务 A(trx_id=20)去读取数据,在 undo log 版本链中,数据最新版本的事务 id 为 40,事务 A 的 ReadView 中的 max_trx_id=31,40 大于 31,该版本的数据时在事务 A 之后提交的,不能读取到的。事务 A 只能根据 roll_pointer 指针,沿着 undo log 版本向前找row_trx_id=30版本的数据,还是不能读取到,再继续往前找,最终可以读取到 trx_id=10 的版本数据,最终事务 A 只能读取到 data0。
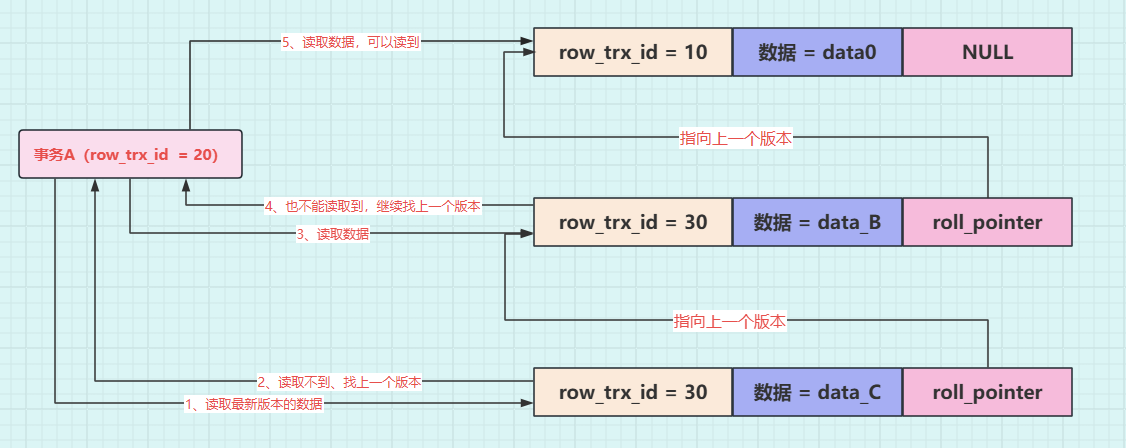
**操作七:**事务 A(trx_id=20)去修改数据,将数据修改为 data_A,那么就会记录一条 undo log,示意图如下:
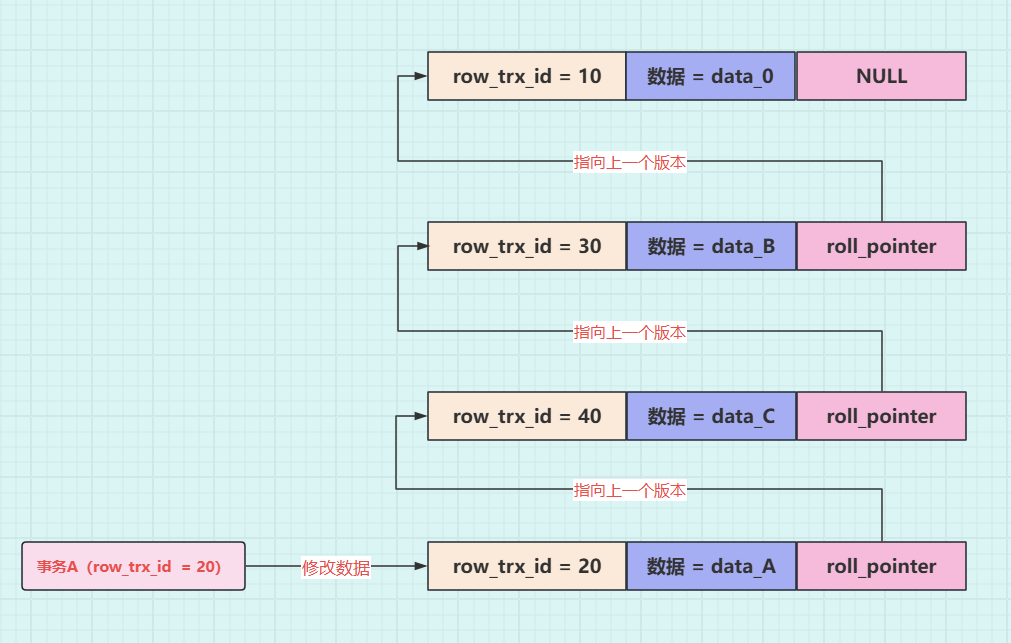
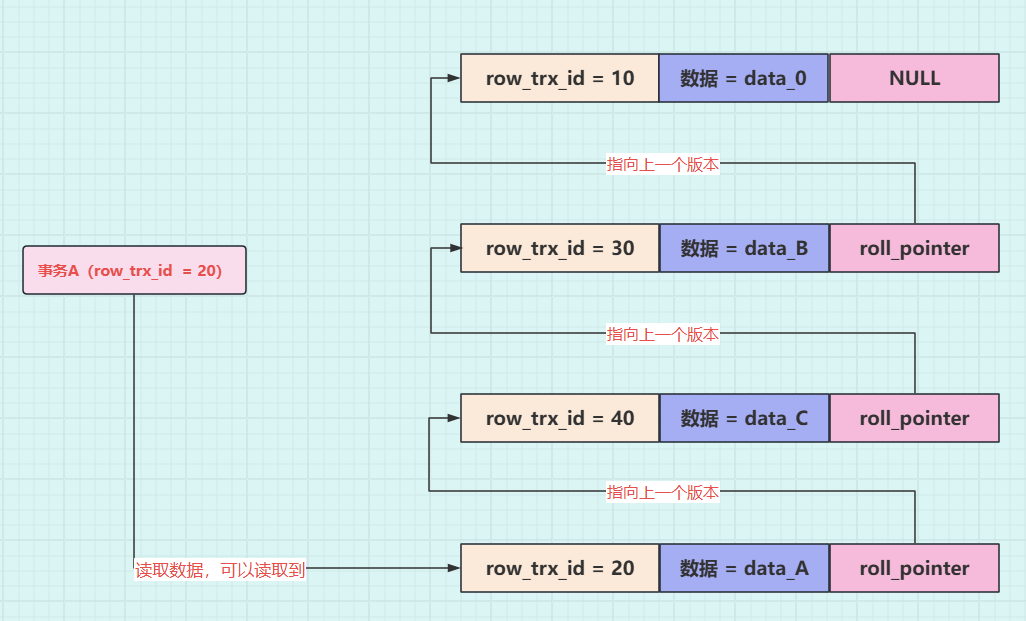
**操作八:**事务 A(trx_id=20)再去读取数据,在 undo log 版本链中,数据最新版本的事务 id 为 20,事务 A 一对比,发现该版本的事务 id 与自己的事务 id 相等,能读取到是 data_A。
五、思考题
题目:用下面的表结构和初始化语句作为试验环境,事务隔离级别是可重复读。现在,我要把所有"字段 c 和 id 值相等的行"的 c 值清零,但是却发现了一个"诡异"的、改不掉的情况。请你构造出这种情况,并说明其原理。
sql
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);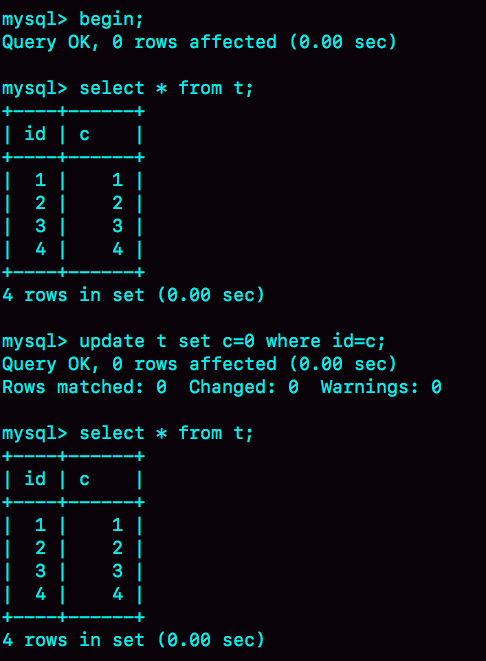
答案分析:
假设有两个事务A和B, 且A事务是更新c=0的事务; 给定条件:
1、事务A update 语句已经执行成功, 说明没有另外一个活动中的事务在执行修改条件为id in 1,2,3,4或c in 1,2,3,4, 否则update会被锁阻塞;
2,事务A再次执行查询结果却是一样, 说明什么?说明事务B把id或者c给修改了, 而且已经提交了, 导致事务A"当前读"没有匹配到对应的条件; 事务A的查询语句说明了事务B执行更新后,提交事务B一定是在事务A第一条查询语句之后执行的;
所以执行顺序应该是:
1, 事务A select * from t;
2, 事务B update t set c = c + 4; // 只要c或者id大于等于5就行; 当然这行也可以和1调换, 不影响
3, 事务B commit;
4, 事务A update t set c = 0 where id = c; // 当前读; 此时已经没有匹配的行
5, 事务A select * from t;